为可观测性设计 Schema
我们建议用户始终为日志和追踪创建自己的 Schema,原因如下
- 选择主键 - 默认 Schema 使用了针对特定访问模式优化的
ORDER BY子句。您的访问模式可能与此不符。 - 提取结构 - 用户可能希望从现有列(例如
Body列)中提取新列。这可以使用物化列(在更复杂的情况下使用物化视图)来完成。这需要 Schema 更改。 - 优化 Map - 默认 Schema 使用 Map 类型来存储属性。这些列允许存储任意元数据。虽然这是一项基本功能,因为事件的元数据通常不是预先定义的,因此无法存储在像 ClickHouse 这样的强类型数据库中,但访问 Map 键及其值不如访问普通列有效。我们通过修改 Schema 并确保最常用的 Map 键是顶层列来解决这个问题 - 请参阅 "使用 SQL 提取结构"。这需要 Schema 更改。
- 简化 Map 键访问 - 访问 Map 中的键需要更冗长的语法。用户可以使用别名来缓解这个问题。请参阅 "使用别名" 以简化查询。
- 二级索引 - 默认 Schema 使用二级索引来加速访问 Map 和加速文本查询。这些通常不是必需的,并且会产生额外的磁盘空间。可以使用它们,但应进行测试以确保它们是必需的。请参阅 "二级/数据跳过索引"。
- 使用 Codec - 如果用户了解预期的数据并有证据表明这可以提高压缩率,他们可能希望自定义列的 Codec。
我们在下面详细描述了上述每个用例。
重要提示: 尽管鼓励用户扩展和修改其 Schema 以实现最佳压缩和查询性能,但他们应尽可能遵守核心列的 OTel Schema 命名。ClickHouse Grafana 插件假定存在一些基本的 OTel 列来帮助构建查询,例如 Timestamp 和 SeverityText。日志和追踪所需的列在此处记录 [1][2] 和 此处。您可以选择更改这些列名,从而覆盖插件配置中的默认值。
使用 SQL 提取结构
无论是摄取结构化日志还是非结构化日志,用户通常都需要能够
- 从字符串 blob 中提取列。查询这些列将比在查询时使用字符串操作更快。
- 从 Map 中提取键。默认 Schema 将任意属性放入 Map 类型的列中。这种类型提供了一种无 Schema 的功能,其优点是用户在定义日志和追踪时无需预定义属性的列 - 通常,当从 Kubernetes 收集日志并希望确保 pod 标签被保留以供后续搜索时,这是不可能的。访问 Map 键及其值比查询普通 ClickHouse 列要慢。因此,通常希望将 Map 中的键提取到根表列。
考虑以下查询
假设我们希望使用结构化日志来计算哪些 URL 路径接收到最多的 POST 请求。JSON blob 存储在 Body 列中,类型为 String。此外,如果用户在收集器中启用了 json_parser,它也可能作为 `Map(String, String)` 存储在 `LogAttributes` 列中。
SELECT LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
LogAttributes: {'status':'200','log.file.name':'access-structured.log','request_protocol':'HTTP/1.1','run_time':'0','time_local':'2019-01-22 00:26:14.000','size':'30577','user_agent':'Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)','referer':'-','remote_user':'-','request_type':'GET','request_path':'/filter/27|13 ,27| 5 ,p53','remote_addr':'54.36.149.41'}
假设 LogAttributes 可用,则用于计算网站的哪些 URL 路径接收到最多 POST 请求的查询
SELECT path(LogAttributes['request_path']) AS path, count() AS c
FROM otel_logs
WHERE ((LogAttributes['request_type']) = 'POST')
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.735 sec. Processed 10.36 million rows, 4.65 GB (14.10 million rows/s., 6.32 GB/s.)
Peak memory usage: 153.71 MiB.
请注意此处 Map 语法的用法,例如 LogAttributes['request_path'],以及用于从 URL 中剥离查询参数的 path 函数。
如果用户未在收集器中启用 JSON 解析,则 LogAttributes 将为空,迫使我们使用 JSON 函数 从 String Body 中提取列。
我们通常建议用户在 ClickHouse 中对结构化日志执行 JSON 解析。我们确信 ClickHouse 是最快的 JSON 解析实现。但是,我们认识到用户可能希望将日志发送到其他来源,而不是让此逻辑驻留在 SQL 中。
SELECT path(JSONExtractString(Body, 'request_path')) AS path, count() AS c
FROM otel_logs
WHERE JSONExtractString(Body, 'request_type') = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.668 sec. Processed 10.37 million rows, 5.13 GB (15.52 million rows/s., 7.68 GB/s.)
Peak memory usage: 172.30 MiB.
现在考虑对非结构化日志执行相同的操作
SELECT Body, LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: 151.233.185.144 - - [22/Jan/2019:19:08:54 +0330] "GET /image/105/brand HTTP/1.1" 200 2653 "https://www.zanbil.ir/filter/b43,p56" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" "-"
LogAttributes: {'log.file.name':'access-unstructured.log'}
针对非结构化日志的类似查询需要通过 extractAllGroupsVertical 函数 使用正则表达式。
SELECT
path((groups[1])[2]) AS path,
count() AS c
FROM
(
SELECT extractAllGroupsVertical(Body, '(\\w+)\\s([^\\s]+)\\sHTTP/\\d\\.\\d') AS groups
FROM otel_logs
WHERE ((groups[1])[1]) = 'POST'
)
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 1.953 sec. Processed 10.37 million rows, 3.59 GB (5.31 million rows/s., 1.84 GB/s.)
解析非结构化日志的查询复杂性和成本的增加(请注意性能差异)是我们建议用户始终尽可能使用结构化日志的原因。
上述查询可以优化为利用正则表达式字典。有关更多详细信息,请参阅 使用字典。
通过将上述查询逻辑移动到插入时间,可以使用 ClickHouse 满足这两个用例。我们在下面探讨了几种方法,重点介绍了每种方法的适用情况。
用户还可以使用 OTel Collector 处理器和操作符执行处理,如 此处 所述。在大多数情况下,用户会发现 ClickHouse 比收集器的处理器资源效率更高且速度更快。在 SQL 中执行所有事件处理的主要缺点是将您的解决方案与 ClickHouse 耦合。例如,用户可能希望从 OTel 收集器(例如 S3)将处理后的日志发送到其他目标。
物化列
物化列提供了从其他列提取结构的最简单解决方案。此类列的值始终在插入时计算,并且不能在 INSERT 查询中指定。
物化列会产生额外的存储开销,因为值在插入时被提取到磁盘上的新列。
物化列支持任何 ClickHouse 表达式,并且可以利用任何分析函数进行 处理字符串(包括 正则表达式和搜索)和 URL,执行 类型转换、从 JSON 中提取值 或 数学运算。
我们建议将物化列用于基本处理。它们对于从 Map 中提取值、将其提升为根列以及执行类型转换特别有用。当在非常基本的 Schema 中或与物化视图结合使用时,它们通常最有用。考虑以下日志 Schema,其中 JSON 已被收集器提取到 LogAttributes 列
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPage` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer'])
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
可以 在此处 找到使用 JSON 函数从 String Body 中提取的等效 Schema。
我们的三个物化视图列提取请求页面、请求类型和引荐来源域。这些访问 Map 键并将函数应用于其值。我们后续的查询速度明显更快
SELECT RequestPage AS path, count() AS c
FROM otel_logs
WHERE RequestType = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.173 sec. Processed 10.37 million rows, 418.03 MB (60.07 million rows/s., 2.42 GB/s.)
Peak memory usage: 3.16 MiB.
默认情况下,物化列不会在 SELECT * 中返回。这是为了保持 SELECT * 的结果始终可以使用 INSERT 插入回表的特性。可以通过设置 asterisk_include_materialized_columns=1 禁用此行为,并且可以在 Grafana 中启用(请参阅数据源配置中的 Additional Settings -> Custom Settings)。
物化视图
物化视图 提供了更强大的方法,可以将 SQL 过滤和转换应用于日志和追踪。
物化视图允许用户将计算成本从查询时间转移到插入时间。ClickHouse 物化视图只是一个触发器,它在数据块插入表时对数据块运行查询。此查询的结果被插入到第二个“目标”表中。
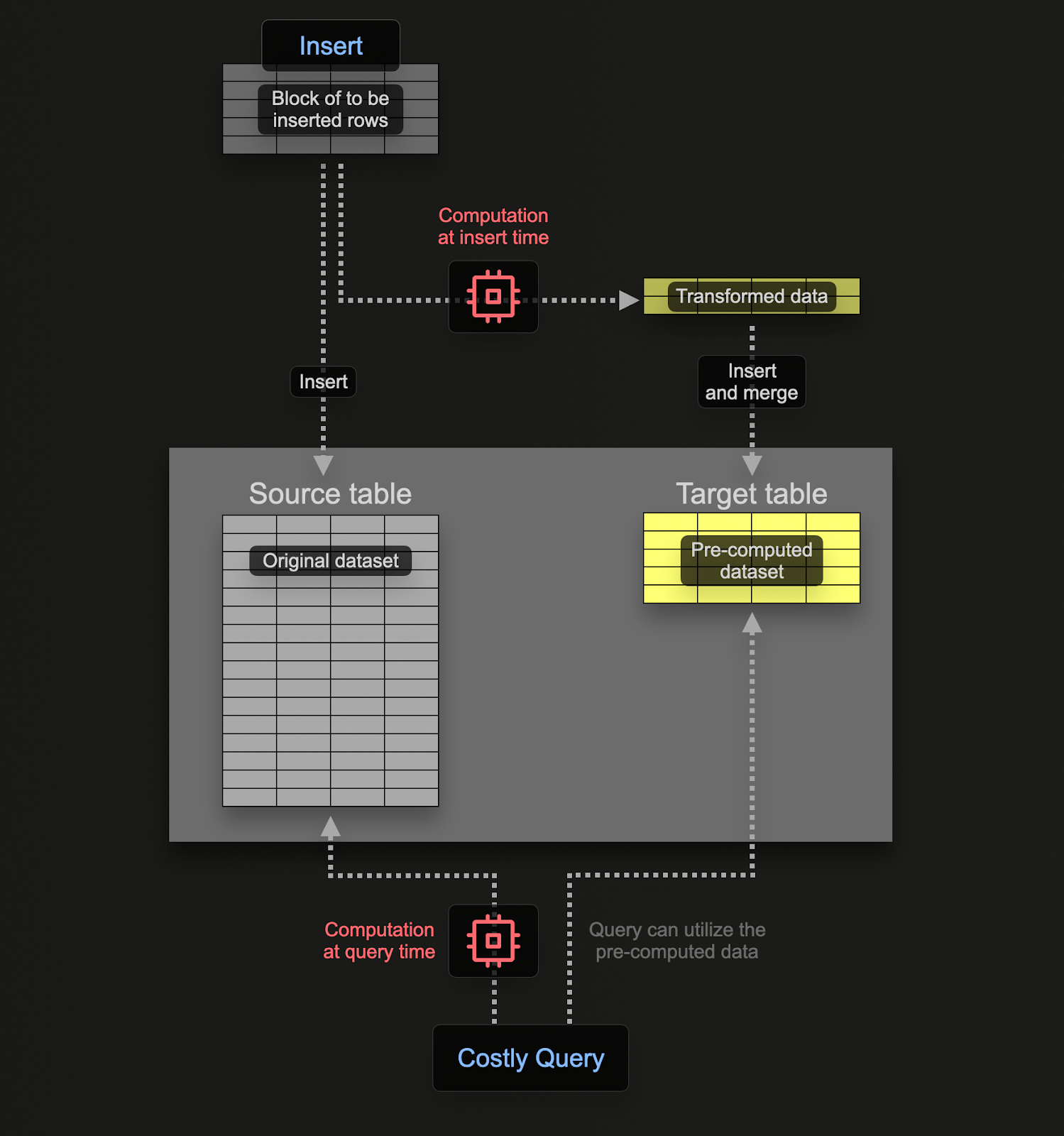
ClickHouse 中的物化视图会随着数据流入它们所基于的表而实时更新,其功能更像是持续更新的索引。相比之下,在其他数据库中,物化视图通常是必须刷新的查询的静态快照(类似于 ClickHouse 可刷新物化视图)。
与物化视图关联的查询理论上可以是任何查询,包括聚合,尽管 Joins 存在限制。对于日志和追踪所需的转换和过滤工作负载,用户可以认为任何 SELECT 语句都是可能的。
用户应记住,查询只是一个触发器,它在插入到表(源表)的行上执行,结果发送到新表(目标表)。
为了确保我们不会两次持久化数据(在源表和目标表中),我们可以将源表的表更改为 Null 表引擎,从而保留原始 Schema。我们的 OTel 收集器将继续向此表发送数据。例如,对于日志,otel_logs 表变为
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1))
) ENGINE = Null
Null 表引擎是一项强大的优化 - 可以将其视为 /dev/null。此表不会存储任何数据,但任何附加的物化视图仍将在插入的行被丢弃之前执行。
考虑以下查询。这会将我们的行转换为我们希望保留的格式,从 LogAttributes 中提取所有列(我们假设这已由收集器使用 json_parser 操作符设置),设置 SeverityText 和 SeverityNumber(基于一些简单的条件和 这些列 的定义)。在这种情况下,我们也只选择我们知道将被填充的列 - 忽略诸如 TraceId、SpanId 和 TraceFlags 等列。
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddr,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddr: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.027 sec.
我们还在上面提取了 Body 列 - 以防以后添加了未被我们的 SQL 提取的其他属性。此列在 ClickHouse 中应该可以很好地压缩,并且很少被访问,因此不会影响查询性能。最后,我们使用强制转换将 Timestamp 减少为 DateTime(以节省空间 - 请参阅 "优化类型")。
我们需要一个表来接收这些结果。下面的目标表与上述查询匹配。
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
此处选择的类型基于 "优化类型" 中讨论的优化。
请注意我们如何大幅更改了我们的 Schema。实际上,用户可能还需要保留 Trace 列以及 ResourceAttributes 列(这通常包含 Kubernetes 元数据)。Grafana 可以利用 Trace 列在日志和追踪之间提供链接功能 - 请参阅 "使用 Grafana"。
下面,我们创建一个物化视图 otel_logs_mv,它为 otel_logs 表执行上述 select,并将结果发送到 otel_logs_v2。
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
上述内容在下面可视化。
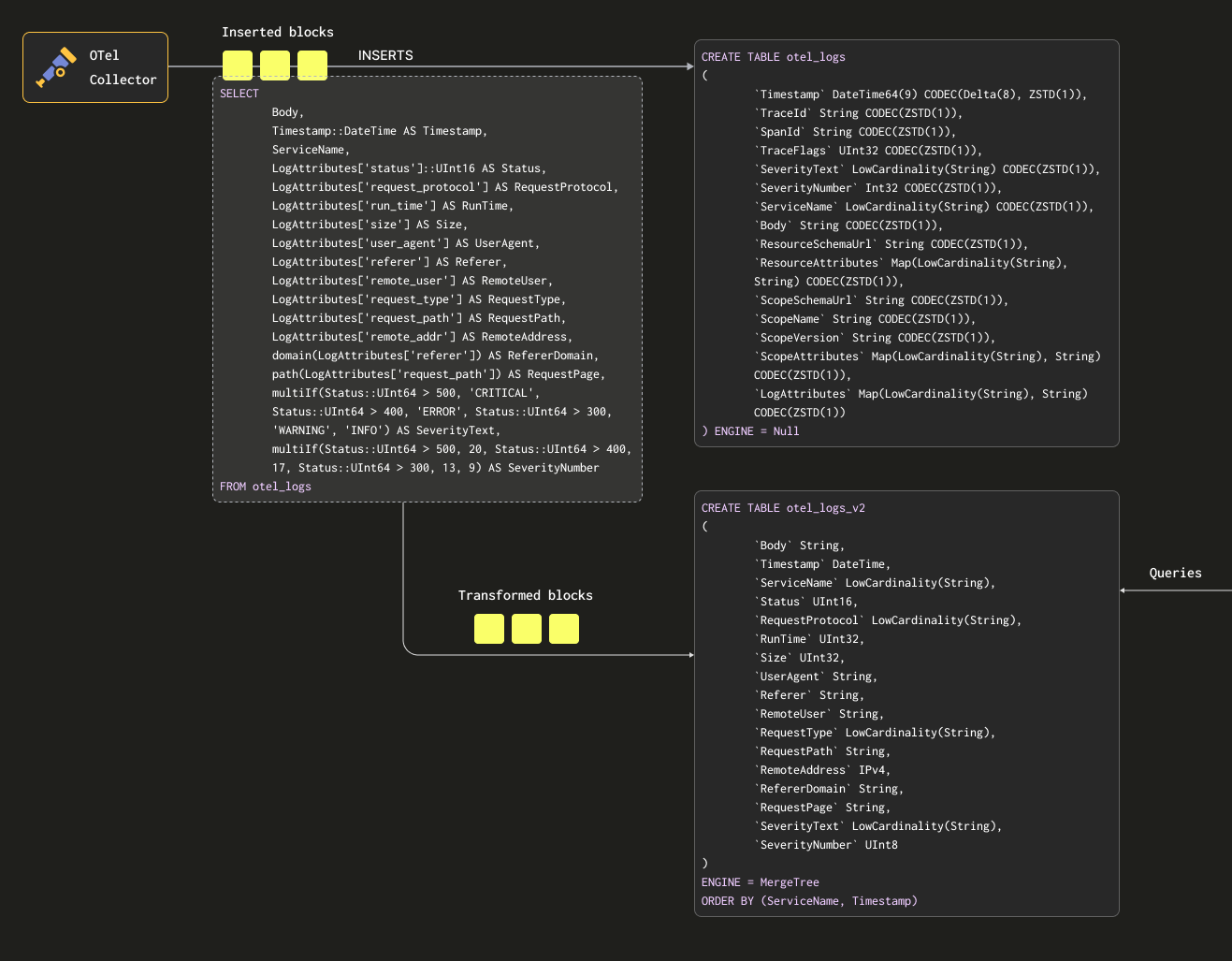
如果我们现在重新启动在 "导出到 ClickHouse" 中使用的收集器配置,数据将以我们所需的格式出现在 otel_logs_v2 中。请注意类型化的 JSON 提取函数的使用。
SELECT *
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddress: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.010 sec.
下面显示了一个等效的物化视图,它依赖于使用 JSON 函数从 Body 列中提取列。
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
JSONExtractUInt(Body, 'status') AS Status,
JSONExtractString(Body, 'request_protocol') AS RequestProtocol,
JSONExtractUInt(Body, 'run_time') AS RunTime,
JSONExtractUInt(Body, 'size') AS Size,
JSONExtractString(Body, 'user_agent') AS UserAgent,
JSONExtractString(Body, 'referer') AS Referer,
JSONExtractString(Body, 'remote_user') AS RemoteUser,
JSONExtractString(Body, 'request_type') AS RequestType,
JSONExtractString(Body, 'request_path') AS RequestPath,
JSONExtractString(Body, 'remote_addr') AS remote_addr,
domain(JSONExtractString(Body, 'referer')) AS RefererDomain,
path(JSONExtractString(Body, 'request_path')) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
注意类型
上述物化视图依赖于隐式转换 - 尤其是在使用 LogAttributes Map 的情况下。ClickHouse 通常会将提取的值透明地转换为目标表类型,从而减少所需的语法。但是,我们建议用户始终通过将视图的 SELECT 语句与使用相同 Schema 的目标表的 INSERT INTO 语句一起使用来测试其视图。这应确认类型已正确处理。应特别注意以下情况。
- 如果 Map 中不存在键,则将返回空字符串。在数值的情况下,用户需要将这些映射到适当的值。这可以使用 条件函数 来实现,例如
if(LogAttributes['status'] = ", 200, LogAttributes['status']);如果默认值可以接受,则可以使用 强制转换函数,例如toUInt8OrDefault(LogAttributes['status'] )。 - 某些类型并非总是会被转换,例如,数值的字符串表示形式不会转换为枚举值。
- 如果未找到值,JSON 提取函数会为其类型返回默认值。确保这些值有意义!
选择主键(排序键)
提取所需的列后,即可开始优化排序/主键。
可以应用一些简单的规则来帮助选择排序键。以下规则有时可能会冲突,因此请按顺序考虑这些规则。用户可以从这个过程中识别出许多键,通常 4-5 个就足够了。
- 选择与您的常用过滤器和访问模式对齐的列。如果用户通常通过按特定列(例如 pod 名称)进行过滤来开始可观测性调查,则此列将在
WHERE子句中频繁使用。优先考虑将这些列包含在您的键中,而不是那些使用频率较低的列。 - 优先选择有助于在过滤时排除总行数很大一部分的列,从而减少需要读取的数据量。服务名称和状态代码通常是不错的选择 - 在后一种情况下,仅当用户按排除大多数行的值进行过滤时才适用,例如,在大多数系统中,按 200 进行过滤将匹配大多数行,而 500 错误将对应于一个小的子集。
- 优先选择可能与表中其他列高度相关的列。这将有助于确保这些值也连续存储,从而提高压缩率。
- 可以使排序键中列的
GROUP BY和ORDER BY操作更节省内存。
在确定排序键的列子集后,必须按特定顺序声明它们。此顺序会显着影响查询中二级键列过滤的效率以及表数据文件的压缩率。一般来说,最好按基数升序排列键。这应与这样一个事实相平衡:对排序键中较晚出现的列进行过滤将不如对元组中较早出现的列进行过滤有效。平衡这些行为并考虑您的访问模式。最重要的是,测试变体。为了进一步理解排序键以及如何优化它们,我们推荐 本文。
我们建议在构建日志结构后确定排序键。不要在属性 Map 中使用键作为排序键或 JSON 提取表达式。确保您的排序键是表中的根列。
使用 Map
之前的示例显示了使用 Map 语法 map['key'] 来访问 Map(String, String) 列中的值。除了使用 Map 表示法访问嵌套键之外,专门的 ClickHouse Map 函数 也可用于过滤或选择这些列。
例如,以下查询使用 mapKeys 函数,然后使用 groupArrayDistinctArray 函数(一个组合器)来识别 LogAttributes 列中所有可用的唯一键。
SELECT groupArrayDistinctArray(mapKeys(LogAttributes))
FROM otel_logs
FORMAT Vertical
Row 1:
──────
groupArrayDistinctArray(mapKeys(LogAttributes)): ['remote_user','run_time','request_type','log.file.name','referer','request_path','status','user_agent','remote_addr','time_local','size','request_protocol']
1 row in set. Elapsed: 1.139 sec. Processed 5.63 million rows, 2.53 GB (4.94 million rows/s., 2.22 GB/s.)
Peak memory usage: 71.90 MiB.
我们不建议在 Map 列名中使用点,并且可能会弃用它的使用。请使用 _。
使用别名
查询 Map 类型比查询普通列慢 - 请参阅 "加速查询"。此外,它的语法更复杂,用户编写起来可能很麻烦。为了解决后一个问题,我们建议使用别名列。
ALIAS 列在查询时计算,并且不存储在表中。因此,不可能将值 INSERT 到此类型的列中。使用别名,我们可以引用 Map 键并简化语法,将 Map 条目透明地公开为普通列。考虑以下示例
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPath` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer']),
`RemoteAddr` IPv4 ALIAS LogAttributes['remote_addr']
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, Timestamp)
我们有几个物化列和一个 ALIAS 列 RemoteAddr,它访问 Map LogAttributes。我们现在可以通过此列查询 LogAttributes['remote_addr'] 值,从而简化我们的查询,即
SELECT RemoteAddr
FROM default.otel_logs
LIMIT 5
┌─RemoteAddr────┐
│ 54.36.149.41 │
│ 31.56.96.51 │
│ 31.56.96.51 │
│ 40.77.167.129 │
│ 91.99.72.15 │
└───────────────┘
5 rows in set. Elapsed: 0.011 sec.
此外,通过 ALTER TABLE 命令添加 ALIAS 非常简单。这些列立即可用,例如
ALTER TABLE default.otel_logs
(ADD COLUMN `Size` String ALIAS LogAttributes['size'])
SELECT Size
FROM default.otel_logs_v3
LIMIT 5
┌─Size──┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.014 sec.
默认情况下,SELECT * 排除 ALIAS 列。可以通过设置 asterisk_include_alias_columns=1 禁用此行为。
优化类型
优化类型 的 通用 ClickHouse 最佳实践 适用于 ClickHouse 用例。
使用 Codec
除了类型优化外,用户在尝试优化 ClickHouse 可观测性 Schema 的压缩时,还可以遵循 Codec 的通用最佳实践。
总的来说,用户会发现 ZSTD Codec 非常适用于日志记录和追踪数据集。将压缩值从其默认值 1 增加可能会提高压缩率。但是,应该对此进行测试,因为较高的值会在插入时产生更大的 CPU 开销。通常,我们发现增加此值几乎没有收益。
此外,时间戳虽然在压缩方面受益于增量编码,但如果此列在主键/排序键中使用,则已被证明会导致查询性能下降。我们建议用户评估各自的压缩与查询性能之间的权衡。
使用字典
字典 是 ClickHouse 的一个 关键功能,它提供来自各种内部和外部 来源 的数据的内存 键值 表示,并针对超低延迟查找查询进行了优化。
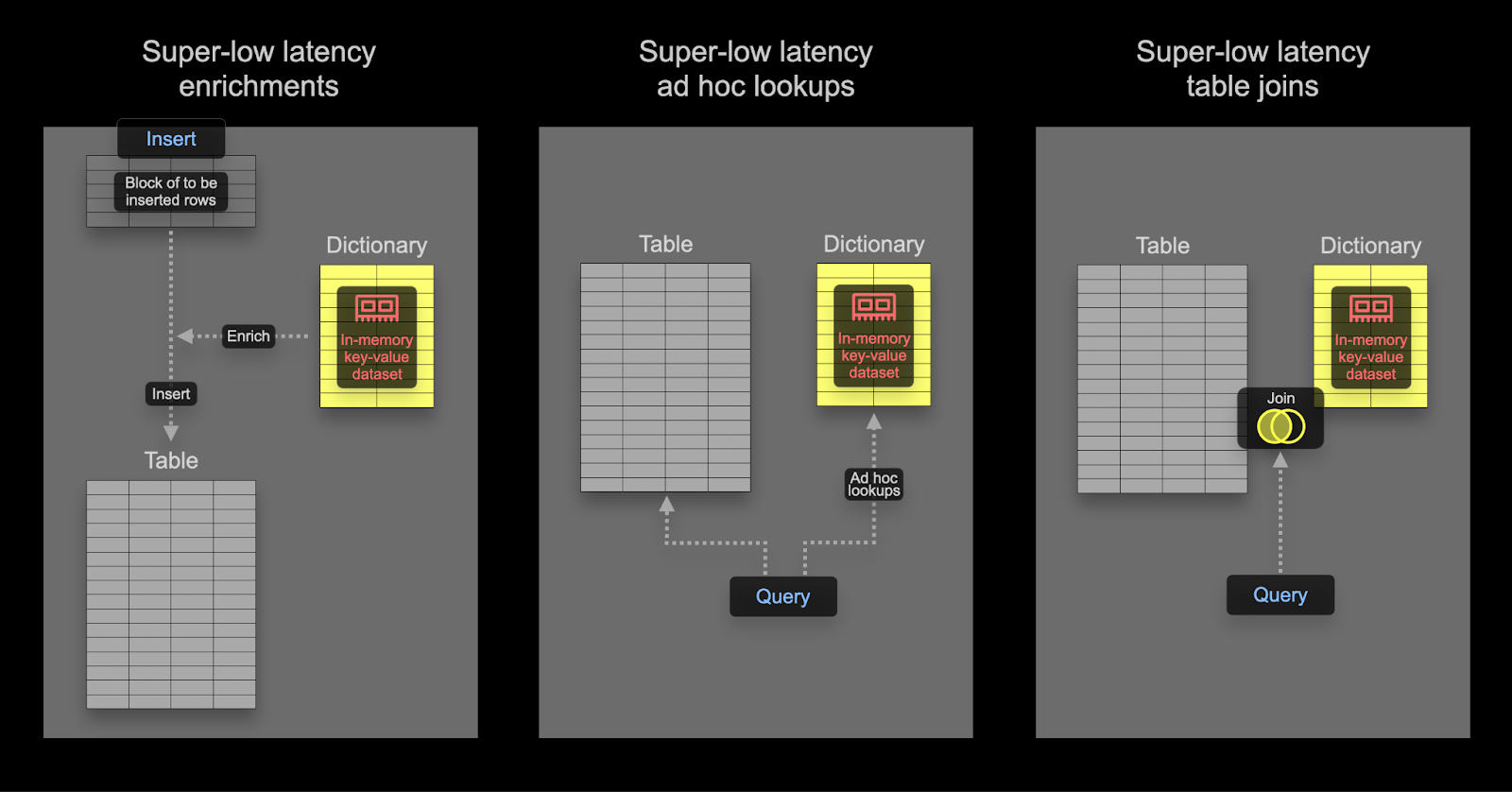
这在各种场景中都很方便,从动态丰富摄取的数据而不会减慢摄取过程,到提高一般查询的性能,JOIN 特别受益。虽然在可观测性用例中很少需要连接,但字典仍然可以方便地用于丰富目的 - 在插入和查询时都是如此。我们在下面提供了两者的示例。
对使用字典加速连接感兴趣的用户可以在 此处 找到更多详细信息。
插入时间与查询时间
字典可用于在查询时间或插入时间丰富数据集。这些方法各有优缺点。总结一下
- 插入时间 - 如果丰富值不更改并且存在于可用于填充字典的外部来源中,则这通常是合适的。在这种情况下,在插入时丰富行可以避免查询时查找字典。这会以插入性能以及额外的存储开销为代价,因为丰富的值将作为列存储。
- 查询时间 - 如果字典中的值频繁更改,则查询时查找通常更适用。这避免了在映射值更改时需要更新列(和重写数据)。这种灵活性是以查询时查找成本为代价的。如果需要查找许多行,例如在过滤器子句中使用字典查找,则此查询时间成本通常是可观的。对于结果丰富,即在
SELECT中,此开销通常不明显。
我们建议用户熟悉字典的基础知识。字典提供一个内存查找表,可以从中检索值,使用专用的 专家函数。
有关简单的丰富示例,请参阅 此处 的字典指南。下面,我们重点介绍常见的可观测性丰富任务。
使用 IP 字典
使用 IP 地址通过地理位置信息(纬度和经度值)来丰富日志和追踪数据是可观测性的常见需求。我们可以使用 ip_trie 结构化字典来实现这一点。
我们使用了公开可用的 DB-IP 城市级数据集,该数据集由 DB-IP.com 根据 CC BY 4.0 许可的条款提供。
从 readme 中,我们可以看到数据结构如下
| ip_range_start | ip_range_end | country_code | state1 | state2 | city | postcode | latitude | longitude | timezone |
鉴于这种结构,让我们首先使用 url() 表函数来查看数据
SELECT *
FROM url('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV', '\n \tip_range_start IPv4, \n \tip_range_end IPv4, \n \tcountry_code Nullable(String), \n \tstate1 Nullable(String), \n \tstate2 Nullable(String), \n \tcity Nullable(String), \n \tpostcode Nullable(String), \n \tlatitude Float64, \n \tlongitude Float64, \n \ttimezone Nullable(String)\n \t')
LIMIT 1
FORMAT Vertical
Row 1:
──────
ip_range_start: 1.0.0.0
ip_range_end: 1.0.0.255
country_code: AU
state1: Queensland
state2: ᴺᵁᴸᴸ
city: South Brisbane
postcode: ᴺᵁᴸᴸ
latitude: -27.4767
longitude: 153.017
timezone: ᴺᵁᴸᴸ
为了让我们的工作更轻松,让我们使用 URL() 表引擎创建一个 ClickHouse 表对象,其中包含我们的字段名称,并确认总行数
CREATE TABLE geoip_url(
ip_range_start IPv4,
ip_range_end IPv4,
country_code Nullable(String),
state1 Nullable(String),
state2 Nullable(String),
city Nullable(String),
postcode Nullable(String),
latitude Float64,
longitude Float64,
timezone Nullable(String)
) engine=URL('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV')
select count() from geoip_url;
┌─count()─┐
│ 3261621 │ -- 3.26 million
└─────────┘
由于我们的 ip_trie 字典要求 IP 地址范围以 CIDR 表示法表示,因此我们需要转换 ip_range_start 和 ip_range_end。
每个范围的 CIDR 可以使用以下查询简洁地计算出来
with
bitXor(ip_range_start, ip_range_end) as xor,
if(xor != 0, ceil(log2(xor)), 0) as unmatched,
32 - unmatched as cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) as cidr_address
select
ip_range_start,
ip_range_end,
concat(toString(cidr_address),'/',toString(cidr_suffix)) as cidr
from
geoip_url
limit 4;
┌─ip_range_start─┬─ip_range_end─┬─cidr───────┐
│ 1.0.0.0 │ 1.0.0.255 │ 1.0.0.0/24 │
│ 1.0.1.0 │ 1.0.3.255 │ 1.0.0.0/22 │
│ 1.0.4.0 │ 1.0.7.255 │ 1.0.4.0/22 │
│ 1.0.8.0 │ 1.0.15.255 │ 1.0.8.0/21 │
└────────────────┴──────────────┴────────────┘
4 rows in set. Elapsed: 0.259 sec.
上面的查询中有很多内容。对于那些感兴趣的人,请阅读这篇优秀的解释。否则,请接受以上计算 IP 范围的 CIDR。
为了我们的目的,我们只需要 IP 范围、国家代码和坐标,因此让我们创建一个新表并插入我们的 Geo IP 数据
CREATE TABLE geoip
(
`cidr` String,
`latitude` Float64,
`longitude` Float64,
`country_code` String
)
ENGINE = MergeTree
ORDER BY cidr
INSERT INTO geoip
WITH
bitXor(ip_range_start, ip_range_end) as xor,
if(xor != 0, ceil(log2(xor)), 0) as unmatched,
32 - unmatched as cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) as cidr_address
SELECT
concat(toString(cidr_address),'/',toString(cidr_suffix)) as cidr,
latitude,
longitude,
country_code
FROM geoip_url
为了在 ClickHouse 中执行低延迟 IP 查找,我们将利用字典来存储我们的 Geo IP 数据的键 -> 属性映射(内存中)。ClickHouse 提供了 ip_trie 字典结构,将我们的网络前缀(CIDR 块)映射到坐标和国家代码。以下查询指定了一个字典,使用此布局和上面的表作为源。
CREATE DICTIONARY ip_trie (
cidr String,
latitude Float64,
longitude Float64,
country_code String
)
primary key cidr
source(clickhouse(table 'geoip'))
layout(ip_trie)
lifetime(3600);
我们可以从字典中选择行并确认此数据集可用于查找
SELECT * FROM ip_trie LIMIT 3
┌─cidr───────┬─latitude─┬─longitude─┬─country_code─┐
│ 1.0.0.0/22 │ 26.0998 │ 119.297 │ CN │
│ 1.0.0.0/24 │ -27.4767 │ 153.017 │ AU │
│ 1.0.4.0/22 │ -38.0267 │ 145.301 │ AU │
└────────────┴──────────┴───────────┴──────────────┘
3 rows in set. Elapsed: 4.662 sec.
ClickHouse 中的字典会根据底层表数据和上面使用的 lifetime 子句定期刷新。要更新我们的 Geo IP 字典以反映 DB-IP 数据集中的最新更改,我们只需要将数据从 geoip_url 远程表重新插入到我们的 geoip 表中,并应用转换。
现在我们已经将 Geo IP 数据加载到我们的 ip_trie 字典中(方便地也命名为 ip_trie),我们可以使用它进行 IP 地理位置定位。这可以使用 dictGet() 函数 来完成,如下所示
SELECT dictGet('ip_trie', ('country_code', 'latitude', 'longitude'), CAST('85.242.48.167', 'IPv4')) AS ip_details
┌─ip_details──────────────┐
│ ('PT',38.7944,-9.34284) │
└─────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
请注意这里的检索速度。这允许我们丰富日志。在本例中,我们选择执行查询时富化。
回到我们原始的日志数据集,我们可以使用上述方法按国家/地区聚合我们的日志。以下假设我们使用早期物化视图产生的 schema,该 schema 具有提取的 RemoteAddress 列。
SELECT dictGet('ip_trie', 'country_code', tuple(RemoteAddress)) AS country,
formatReadableQuantity(count()) AS num_requests
FROM default.otel_logs_v2
WHERE country != ''
GROUP BY country
ORDER BY count() DESC
LIMIT 5
┌─country─┬─num_requests────┐
│ IR │ 7.36 million │
│ US │ 1.67 million │
│ AE │ 526.74 thousand │
│ DE │ 159.35 thousand │
│ FR │ 109.82 thousand │
└─────────┴─────────────────┘
5 rows in set. Elapsed: 0.140 sec. Processed 20.73 million rows, 82.92 MB (147.79 million rows/s., 591.16 MB/s.)
Peak memory usage: 1.16 MiB.
由于 IP 到地理位置的映射可能会发生变化,用户可能想知道请求在发出时源自何处 - 而不是同一地址当前的地理位置。因此,索引时富化在这里可能是首选。这可以使用物化列来完成,如下所示,或在物化视图的选择中完成
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Country` String MATERIALIZED dictGet('ip_trie', 'country_code', tuple(RemoteAddress)),
`Latitude` Float32 MATERIALIZED dictGet('ip_trie', 'latitude', tuple(RemoteAddress)),
`Longitude` Float32 MATERIALIZED dictGet('ip_trie', 'longitude', tuple(RemoteAddress))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
用户可能希望 IP 富化字典根据新数据定期更新。这可以使用字典的 LIFETIME 子句来实现,这将导致字典从底层表定期重新加载。要更新底层表,请参阅“可刷新物化视图”。
上述国家/地区和坐标提供了超出按国家/地区分组和筛选的可视化功能。有关灵感,请参阅“可视化地理数据”。
使用 Regex 字典(User Agent 解析)
解析 user agent 字符串 是一个经典的正则表达式问题,也是基于日志和追踪的数据集中常见的需求。ClickHouse 提供了使用正则表达式树字典高效解析 user agent 的功能。
正则表达式树字典在 ClickHouse 开源版本中使用 YAMLRegExpTree 字典源类型定义,该类型提供包含正则表达式树的 YAML 文件的路径。如果您希望提供自己的正则表达式字典,可以在此处找到有关所需结构的详细信息。下面我们重点介绍使用 uap-core 进行 user-agent 解析,并为支持的 CSV 格式加载我们的字典。此方法与 OSS 和 ClickHouse Cloud 兼容。
创建以下 Memory 表。这些表保存我们用于解析设备、浏览器和操作系统的正则表达式。
CREATE TABLE regexp_os
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_browser
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_device
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
这些表可以使用 url 表函数从以下公开托管的 CSV 文件中填充
INSERT INTO regexp_os SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_os.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_device SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_device.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_browser SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_browser.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
在我们填充了内存表之后,我们可以加载我们的正则表达式字典。请注意,我们需要将键值指定为列 - 这些将是我们从 user agent 中提取的属性。
CREATE DICTIONARY regexp_os_dict
(
regexp String,
os_replacement String default 'Other',
os_v1_replacement String default '0',
os_v2_replacement String default '0',
os_v3_replacement String default '0',
os_v4_replacement String default '0'
)
PRIMARY KEY regexp
SOURCE(CLICKHOUSE(TABLE 'regexp_os'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(REGEXP_TREE);
CREATE DICTIONARY regexp_device_dict
(
regexp String,
device_replacement String default 'Other',
brand_replacement String,
model_replacement String
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_device'))
LIFETIME(0)
LAYOUT(regexp_tree);
CREATE DICTIONARY regexp_browser_dict
(
regexp String,
family_replacement String default 'Other',
v1_replacement String default '0',
v2_replacement String default '0'
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_browser'))
LIFETIME(0)
LAYOUT(regexp_tree);
加载这些字典后,我们可以提供一个示例 user-agent 并测试我们新的字典提取功能
WITH 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:127.0) Gecko/20100101 Firefox/127.0' AS user_agent
SELECT
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), user_agent) AS device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), user_agent) AS browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), user_agent) AS os
┌─device────────────────┬─browser───────────────┬─os─────────────────────────┐
│ ('Mac','Apple','Mac') │ ('Firefox','127','0') │ ('Mac OS X','10','15','0') │
└───────────────────────┴───────────────────────┴────────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
鉴于围绕 user agent 的规则很少更改,字典只需要在响应新的浏览器、操作系统和设备时进行更新,因此在插入时执行此提取是有意义的。
我们可以使用物化列或物化视图来执行此工作。下面我们修改了之前使用的物化视图
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2
AS SELECT
Body,
CAST(Timestamp, 'DateTime') AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(CAST(Status, 'UInt64') > 500, 'CRITICAL', CAST(Status, 'UInt64') > 400, 'ERROR', CAST(Status, 'UInt64') > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(CAST(Status, 'UInt64') > 500, 20, CAST(Status, 'UInt64') > 400, 17, CAST(Status, 'UInt64') > 300, 13, 9) AS SeverityNumber,
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), UserAgent) AS Device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), UserAgent) AS Browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), UserAgent) AS Os
FROM otel_logs
这需要我们修改目标表 otel_logs_v2 的 schema
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt8,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`remote_addr` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Device` Tuple(device_replacement LowCardinality(String), brand_replacement LowCardinality(String), model_replacement LowCardinality(String)),
`Browser` Tuple(family_replacement LowCardinality(String), v1_replacement LowCardinality(String), v2_replacement LowCardinality(String)),
`Os` Tuple(os_replacement LowCardinality(String), os_v1_replacement LowCardinality(String), os_v2_replacement LowCardinality(String), os_v3_replacement LowCardinality(String))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp, Status)
在重启收集器并根据先前记录的步骤摄取结构化日志后,我们可以查询我们新提取的 Device、Browser 和 Os 列。
SELECT Device, Browser, Os
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Device: ('Spider','Spider','Desktop')
Browser: ('AhrefsBot','6','1')
Os: ('Other','0','0','0')
请注意,这些 user agent 列使用了元组。对于层级结构事先已知的复杂结构,建议使用元组。子列提供与常规列相同的性能(与 Map 键不同),同时允许异构类型。
进一步阅读
有关字典的更多示例和详细信息,我们建议阅读以下文章
加速查询
ClickHouse 支持多种加速查询性能的技术。只有在选择合适的 primary/ordering key 以优化最常用的访问模式并最大化压缩之后,才应考虑以下事项。这通常会对性能产生最大的影响,而付出的努力最少。
使用物化视图(增量)进行聚合
在前面的章节中,我们探讨了如何使用物化视图进行数据转换和过滤。然而,物化视图也可以用于在插入时预先计算聚合并将结果存储起来。此结果可以使用后续插入的结果进行更新,从而有效地允许在插入时预先计算聚合。
这里的核心思想是,结果通常是原始数据的较小表示形式(在聚合的情况下,是部分草图)。当与从目标表中读取结果的更简单查询结合使用时,查询时间将比在原始数据上执行相同计算更快。
考虑以下查询,其中我们使用结构化日志计算每小时的总流量
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.666 sec. Processed 10.37 million rows, 4.73 GB (15.56 million rows/s., 7.10 GB/s.)
Peak memory usage: 1.40 MiB.
我们可以想象这可能是用户使用 Grafana 绘制的常见折线图。诚然,此查询非常快 - 数据集只有 1000 万行,而 ClickHouse 速度很快!但是,如果我们将此扩展到数十亿和数万亿行,我们理想情况下希望保持这种查询性能。
如果我们使用 otel_logs_v2 表,此查询速度将提高 10 倍,该表来自我们早期的物化视图,该视图从 LogAttributes map 中提取 size 键。我们此处仅出于说明目的使用原始数据,如果这是一个常见查询,我们建议使用早期的视图。
如果我们想使用物化视图在插入时计算此值,我们需要一个表来接收结果。此表每小时应仅保留 1 行。如果收到现有小时的更新,则其他列应合并到现有小时的行中。为了实现增量状态的这种合并,必须为其他列存储部分状态。
这需要在 ClickHouse 中使用特殊的引擎类型:SummingMergeTree。这将所有具有相同 ordering key 的行替换为一行,该行包含数字列的求和值。以下表将合并任何具有相同日期的行,并对任何数值列求和。
CREATE TABLE bytes_per_hour
(
`Hour` DateTime,
`TotalBytes` UInt64
)
ENGINE = SummingMergeTree
ORDER BY Hour
为了演示我们的物化视图,假设我们的 bytes_per_hour 表为空且尚未接收任何数据。我们的物化视图对插入到 otel_logs 中的数据执行上述 SELECT(这将针对配置大小的块执行),结果发送到 bytes_per_hour。语法如下所示
CREATE MATERIALIZED VIEW bytes_per_hour_mv TO bytes_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
此处的 TO 子句是关键,表示结果将发送到哪里,即 bytes_per_hour。
如果我们重启 OTel Collector 并重新发送日志,则 bytes_per_hour 表将使用上述查询结果增量填充。完成后,我们可以确认 bytes_per_hour 的大小 - 我们应该每小时有 1 行
SELECT count()
FROM bytes_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.039 sec.
通过存储查询结果,我们有效地将此处的行数从 1000 万(在 otel_logs 中)减少到 113 行。这里的关键是,如果新日志插入到 otel_logs 表中,则新值将发送到 bytes_per_hour 的各自小时,它们将在后台自动异步合并 - 通过每小时仅保留一行,bytes_per_hour 将始终保持小巧且最新。
由于行的合并是异步的,因此当用户查询时,每小时可能会有多行。为了确保在查询时合并任何未完成的行,我们有两种选择
- 在表名称上使用
FINAL修饰符(我们在上面的计数查询中使用了它)。 - 按最终表中使用的 ordering key(即 Timestamp)聚合,并对指标求和。
通常,第二种选择更有效且更灵活(该表可以用于其他用途),但对于某些查询,第一种选择可能更简单。我们在下面展示了这两种方法
SELECT
Hour,
sum(TotalBytes) AS TotalBytes
FROM bytes_per_hour
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.008 sec.
SELECT
Hour,
TotalBytes
FROM bytes_per_hour
FINAL
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.005 sec.
这使我们的查询速度从 0.6 秒提高到 0.008 秒 - 提高了 75 倍以上!
在具有更复杂查询的更大数据集上,这些节省可能会更大。有关示例,请参见此处。
更复杂的示例
上面的示例使用 SummingMergeTree 聚合每小时的简单计数。超出简单求和的统计信息需要不同的目标表引擎:AggregatingMergeTree。
假设我们希望计算每天唯一 IP 地址(或唯一用户)的数量。为此的查询是
SELECT toStartOfHour(Timestamp) AS Hour, uniq(LogAttributes['remote_addr']) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
…
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.667 sec. Processed 10.37 million rows, 4.73 GB (15.53 million rows/s., 7.09 GB/s.)
为了持久化基数计数以进行增量更新,需要 AggregatingMergeTree。
CREATE TABLE unique_visitors_per_hour
(
`Hour` DateTime,
`UniqueUsers` AggregateFunction(uniq, IPv4)
)
ENGINE = AggregatingMergeTree
ORDER BY Hour
为了确保 ClickHouse 知道将存储聚合状态,我们将 UniqueUsers 列定义为 AggregateFunction 类型,指定部分状态的函数源 (uniq) 和源列的类型 (IPv4)。与 SummingMergeTree 类似,具有相同 ORDER BY 键值的行将被合并(在上面的示例中为 Hour)。
关联的物化视图使用较早的查询
CREATE MATERIALIZED VIEW unique_visitors_per_hour_mv TO unique_visitors_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
uniqState(LogAttributes['remote_addr']::IPv4) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
请注意我们如何在聚合函数的末尾附加后缀 State。这确保返回函数的聚合状态而不是最终结果。这将包含其他信息,以允许此部分状态与其他状态合并。
通过重启 Collector 重新加载数据后,我们可以确认 unique_visitors_per_hour 表中有 113 行可用。
SELECT count()
FROM unique_visitors_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.009 sec.
我们的最终查询需要为我们的函数使用 Merge 后缀(因为列存储部分聚合状态)
SELECT Hour, uniqMerge(UniqueUsers) AS UniqueUsers
FROM unique_visitors_per_hour
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.027 sec.
请注意,我们在此处使用 GROUP BY 而不是使用 FINAL。
使用物化视图(增量)进行快速查找
用户在选择 ClickHouse ordering key 时应考虑其访问模式,其中包含在筛选和聚合子句中经常使用的列。这在可观测性用例中可能具有限制性,在可观测性用例中,用户具有更多样化的访问模式,这些模式无法封装在单个列集中。这在默认 OTel schema 中内置的示例中得到了最好的说明。考虑 traces 的默认 schema
CREATE TABLE otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
此 schema 针对按 ServiceName、SpanName 和 Timestamp 进行筛选进行了优化。在 tracing 中,用户还需要能够按特定的 TraceId 进行查找并检索关联 trace 的 span。虽然这在 ordering key 中存在,但其在末尾的位置意味着筛选效率不会很高,并且可能意味着在检索单个 trace 时需要扫描大量数据。
OTel collector 还安装了一个物化视图和关联的表来解决此挑战。表和视图如下所示
CREATE TABLE otel_traces_trace_id_ts
(
`TraceId` String CODEC(ZSTD(1)),
`Start` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`End` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.01) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (TraceId, toUnixTimestamp(Start))
CREATE MATERIALIZED VIEW otel_traces_trace_id_ts_mv TO otel_traces_trace_id_ts
(
`TraceId` String,
`Start` DateTime64(9),
`End` DateTime64(9)
)
AS SELECT
TraceId,
min(Timestamp) AS Start,
max(Timestamp) AS End
FROM otel_traces
WHERE TraceId != ''
GROUP BY TraceId
该视图有效地确保表 otel_traces_trace_id_ts 具有 trace 的最小和最大时间戳。此表按 TraceId 排序,允许有效检索这些时间戳。这些时间戳范围反过来可以在查询主 otel_traces 表时使用。更具体地说,当按 id 检索 trace 时,Grafana 使用以下查询
WITH 'ae9226c78d1d360601e6383928e4d22d' AS trace_id,
(
SELECT min(Start)
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_start,
(
SELECT max(End) + 1
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_end
SELECT
TraceId AS traceID,
SpanId AS spanID,
ParentSpanId AS parentSpanID,
ServiceName AS serviceName,
SpanName AS operationName,
Timestamp AS startTime,
Duration * 0.000001 AS duration,
arrayMap(key -> map('key', key, 'value', SpanAttributes[key]), mapKeys(SpanAttributes)) AS tags,
arrayMap(key -> map('key', key, 'value', ResourceAttributes[key]), mapKeys(ResourceAttributes)) AS serviceTags
FROM otel_traces
WHERE (traceID = trace_id) AND (startTime >= trace_start) AND (startTime <= trace_end)
LIMIT 1000
此处的 CTE 标识 trace id ae9226c78d1d360601e6383928e4d22d 的最小和最大时间戳,然后使用它来筛选主 otel_traces 以查找其关联的 span。
相同的方法可以应用于类似的访问模式。我们在数据建模此处中探讨了一个类似的示例。
使用 Projections
ClickHouse projections 允许用户为表指定多个 ORDER BY 子句。
在前面的章节中,我们探讨了如何在 ClickHouse 中使用物化视图来预先计算聚合、转换行和优化针对不同访问模式的可观测性查询。
我们提供了一个示例,其中物化视图将行发送到目标表,该目标表的 ordering key 与接收插入的原始表不同,以便优化按 trace id 进行查找。
Projections 可以用于解决相同的问题,允许用户优化对不属于 primary key 的列的查询。
从理论上讲,此功能可用于为表提供多个 ordering key,但有一个明显的缺点:数据重复。具体来说,数据需要按照主 primary key 的顺序以及为每个 projection 指定的顺序写入。这将减慢插入速度并消耗更多磁盘空间。
Projections 提供与物化视图相同的许多功能,但应谨慎使用,后者通常是首选。用户应了解缺点以及何时适用。例如,虽然 projections 可以用于预先计算聚合,但我们建议用户为此使用物化视图。
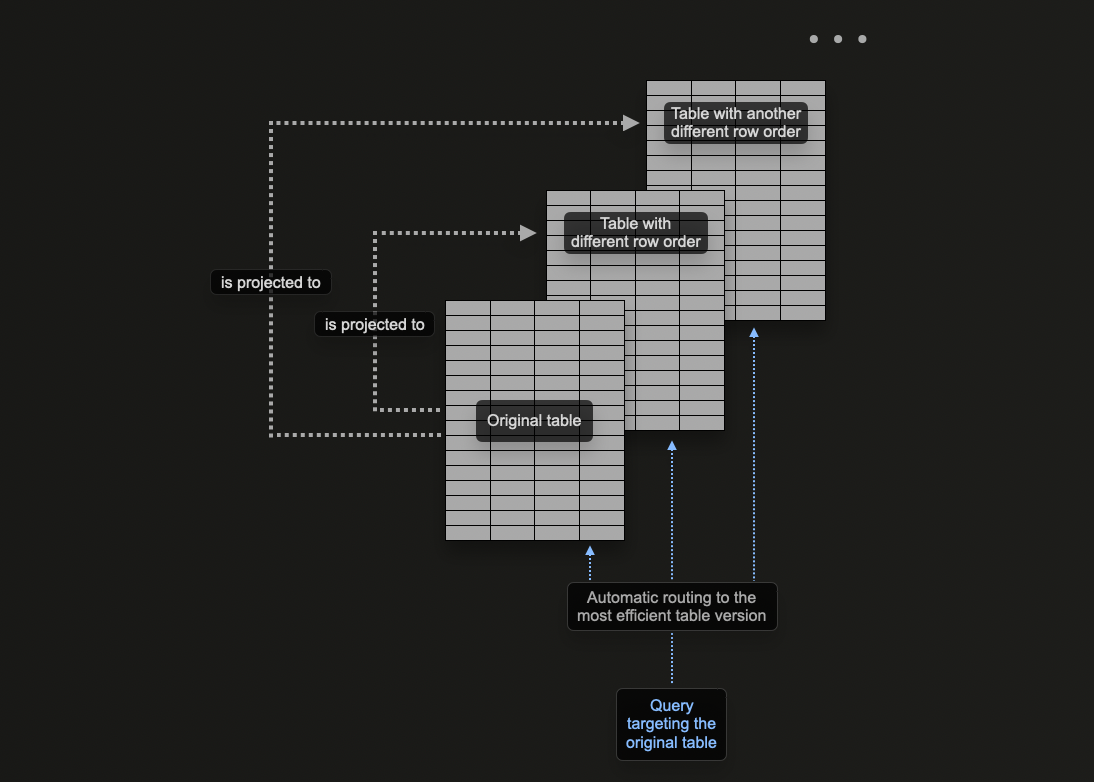
考虑以下查询,该查询按 500 个错误代码筛选我们的 otel_logs_v2 表。这可能是日志记录的常见访问模式,用户希望按错误代码进行筛选
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
Ok.
0 rows in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 685.32 MB (58.66 million rows/s., 3.88 GB/s.)
Peak memory usage: 56.54 MiB.
我们在此处不使用 FORMAT Null 打印结果。这强制读取所有结果但不返回,从而防止由于 LIMIT 而提前终止查询。这只是为了显示扫描所有 1000 万行所花费的时间。
上面的查询需要使用我们选择的 ordering key (ServiceName, Timestamp) 进行线性扫描。虽然我们可以将 Status 添加到 ordering key 的末尾,从而提高上述查询的性能,但我们也可以添加 projection。
ALTER TABLE otel_logs_v2 (
ADD PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent ORDER BY Status
)
)
ALTER TABLE otel_logs_v2 MATERIALIZE PROJECTION status
请注意,我们必须首先创建 projection,然后物化它。后一个命令会导致数据以两种不同的顺序在磁盘上存储两次。projection 也可以在创建数据时定义,如下所示,并且将在数据插入时自动维护。
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
ORDER BY Status
)
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
重要的是,如果 projection 是通过 ALTER 创建的,则当发出 MATERIALIZE PROJECTION 命令时,其创建是异步的。用户可以使用以下查询确认此操作的进度,等待 is_done=1。
SELECT parts_to_do, is_done, latest_fail_reason
FROM system.mutations
WHERE (`table` = 'otel_logs_v2') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
│ 0 │ 1 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.008 sec.
如果我们重复上面的查询,我们可以看到性能得到了显着提高,但代价是额外的存储空间(有关如何衡量这一点,请参阅“衡量表大小和压缩”)。
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
0 rows in set. Elapsed: 0.031 sec. Processed 51.42 thousand rows, 22.85 MB (1.65 million rows/s., 734.63 MB/s.)
Peak memory usage: 27.85 MiB.
在上面的示例中,我们在 projection 中指定了早期查询中使用的列。这意味着只有这些指定的列将作为 projection 的一部分存储在磁盘上,并按 Status 排序。或者,如果我们在此处使用 SELECT *,则将存储所有列。虽然这将允许更多查询(使用任何列子集)从 projection 中受益,但会产生额外的存储空间。有关衡量磁盘空间和压缩的信息,请参阅“衡量表大小和压缩”。
二级/数据跳过索引
无论在 ClickHouse 中如何优化 primary key,某些查询都不可避免地需要全表扫描。虽然可以使用物化视图(以及某些查询的 projections)来缓解这种情况,但这需要额外的维护,并且用户需要了解它们的可用性,以确保它们得到利用。虽然传统的关系数据库使用二级索引来解决此问题,但这些索引在像 ClickHouse 这样的列式数据库中无效。相反,ClickHouse 使用“Skip”索引,这可以通过允许数据库跳过没有匹配值的大数据块来显着提高查询性能。
默认 OTel schema 使用二级索引来尝试加速对 map 访问的访问。虽然我们发现这些索引通常无效,并且不建议将它们复制到您的自定义 schema 中,但跳过索引仍然可能有用。
用户在尝试应用二级索引之前,应阅读并理解二级索引指南。
一般来说,当 primary key 和目标非 primary 列/表达式之间存在强相关性,并且用户正在查找稀有值(即那些没有在许多 granules 中出现的值)时,它们是有效的。
用于文本搜索的 Bloom 过滤器
对于可观测性查询,当用户需要执行文本搜索时,二级索引可能很有用。具体来说,ngram 和基于令牌的 bloom 过滤器索引 ngrambf_v1 和 tokenbf_v1 可用于加速对 String 列使用运算符 LIKE、IN 和 hasToken 的搜索。重要的是,基于令牌的索引使用非字母数字字符作为分隔符生成令牌。这意味着在查询时只能匹配令牌(或整个单词)。为了更精细的匹配,可以使用N-gram bloom 过滤器。这会将字符串拆分为指定大小的 n-gram,从而允许子词匹配。
为了评估将生成并因此匹配的令牌,可以使用 tokens 函数
SELECT tokens('https://www.zanbil.ir/m/filter/b113')
┌─tokens────────────────────────────────────────────┐
│ ['https','www','zanbil','ir','m','filter','b113'] │
└───────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
ngram 函数提供类似的功能,其中 ngram 大小可以指定为第二个参数
SELECT ngrams('https://www.zanbil.ir/m/filter/b113', 3)
┌─ngrams('https://www.zanbil.ir/m/filter/b113', 3)────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['htt','ttp','tps','ps:','s:/','://','//w','/ww','www','ww.','w.z','.za','zan','anb','nbi','bil','il.','l.i','.ir','ir/','r/m','/m/','m/f','/fi','fil','ilt','lte','ter','er/','r/b','/b1','b11','113'] │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
ClickHouse 还对倒排索引作为二级索引提供实验性支持。我们目前不建议将这些用于日志数据集,但预计它们将在生产就绪时取代基于令牌的 bloom 过滤器。
对于此示例的目的,我们使用结构化日志数据集。假设我们希望计算 Referer 列包含 ultra 的日志数。
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 114514 │
└─────────┘
1 row in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 908.49 MB (58.57 million rows/s., 5.13 GB/s.)
这里我们需要匹配 ngram 大小为 3 的 ngram。因此,我们创建一个 ngrambf_v1 索引。
CREATE TABLE otel_logs_bloom
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
INDEX idx_span_attr_value Referer TYPE ngrambf_v1(3, 10000, 3, 7) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (Timestamp)
索引 ngrambf_v1(3, 10000, 3, 7) 在这里采用四个参数。最后一个参数(值 7)表示种子。其他参数表示 ngram 大小 (3)、值 m(过滤器大小)和哈希函数数 k (7)。k 和 m 需要调整,并将基于唯一 ngram/令牌的数量以及过滤器导致真阴性的概率 - 从而确认值不存在于 granule 中。我们建议使用这些函数来帮助确定这些值。
如果调整正确,这里的加速可能会非常显着
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 182 │
└─────────┘
1 row in set. Elapsed: 0.077 sec. Processed 4.22 million rows, 375.29 MB (54.81 million rows/s., 4.87 GB/s.)
Peak memory usage: 129.60 KiB.
以上仅用于说明目的。我们建议用户在插入时从日志中提取结构,而不是尝试使用基于令牌的 bloom 过滤器来优化文本搜索。但是,在某些情况下,用户具有堆栈追踪或其他大型字符串,由于结构不太确定,文本搜索可能很有用。
关于使用 bloom 过滤器的一些一般准则
bloom 的目标是过滤 granules,从而避免需要加载列的所有值并执行线性扫描。EXPLAIN 子句与参数 indexes=1 一起使用,可用于标识已跳过的 granules 的数量。考虑下面原始表 otel_logs_v2 和带有 ngram bloom 过滤器的表 otel_logs_bloom 的响应。
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_v2) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 9/9 │
│ Granules: 1278/1278 │
└────────────────────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.016 sec.
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_bloom) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 8/8 │
│ Granules: 1276/1276 │
│ Skip │
│ Name: idx_span_attr_value │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 8/8 │
│ Granules: 517/1276 │
└────────────────────────────────────────────────────────────────────┘
bloom 过滤器通常只有在小于列本身时才会更快。如果它更大,那么性能提升可能可以忽略不计。使用以下查询将过滤器的大小与列的大小进行比较
SELECT
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (`table` = 'otel_logs_bloom') AND (name = 'Referer')
GROUP BY name
ORDER BY sum(data_compressed_bytes) DESC
┌─name────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ Referer │ 56.16 MiB │ 789.21 MiB │ 14.05 │
└─────────┴─────────────────┴───────────────────┴───────┘
1 row in set. Elapsed: 0.018 sec.
SELECT
`table`,
formatReadableSize(data_compressed_bytes) AS compressed_size,
formatReadableSize(data_uncompressed_bytes) AS uncompressed_size
FROM system.data_skipping_indices
WHERE `table` = 'otel_logs_bloom'
┌─table───────────┬─compressed_size─┬─uncompressed_size─┐
│ otel_logs_bloom │ 12.03 MiB │ 12.17 MiB │
└─────────────────┴─────────────────┴───────────────────┘
1 row in set. Elapsed: 0.004 sec.
在上面的示例中,我们可以看到二级 bloom 过滤器索引为 12MB - 比列本身的压缩大小 56MB 小近 5 倍。
Bloom 过滤器可能需要大量调整。我们建议遵循此处的注释,这些注释可能有助于识别最佳设置。Bloom 过滤器在插入和合并时也可能很昂贵。用户应在将 bloom 过滤器添加到生产环境之前评估对插入性能的影响。
有关二级跳过索引的更多详细信息,请参见此处。
从 Map 中提取
Map 类型在 OTel schema 中很普遍。此类型要求值和键具有相同的类型 - 足以满足 Kubernetes 标签等元数据。请注意,当查询 Map 类型的子键时,将加载整个父列。如果 map 具有许多键,则可能会导致严重的查询性能损失,因为与键作为列存在相比,需要从磁盘读取更多数据。
如果您经常查询特定键,请考虑将其移动到根目录中自己的专用列中。这通常是在响应常见访问模式以及部署之后发生的任务,并且可能在生产之前难以预测。有关如何在部署后修改 schema 的信息,请参阅“管理 schema 更改”。
衡量表大小和压缩
ClickHouse 用于可观测性的主要原因之一是压缩。
除了显着降低存储成本外,磁盘上更少的数据意味着更少的 I/O 和更快的查询和插入。相对于 CPU 而言,I/O 的减少将超过任何压缩算法的开销。因此,在确保 ClickHouse 查询速度快时,首先应关注提高数据压缩率。
有关衡量压缩的详细信息,请参见此处。