可刷新物化视图
可刷新物化视图在概念上类似于传统 OLTP 数据库中的物化视图,它存储指定查询的结果以便快速检索,并减少重复执行资源密集型查询的需求。与 ClickHouse 的增量物化视图不同,这需要定期对完整数据集执行查询 - 其结果存储在目标表中以供查询。理论上,此结果集应小于原始数据集,从而允许后续查询更快地执行。
该图表解释了可刷新物化视图的工作原理
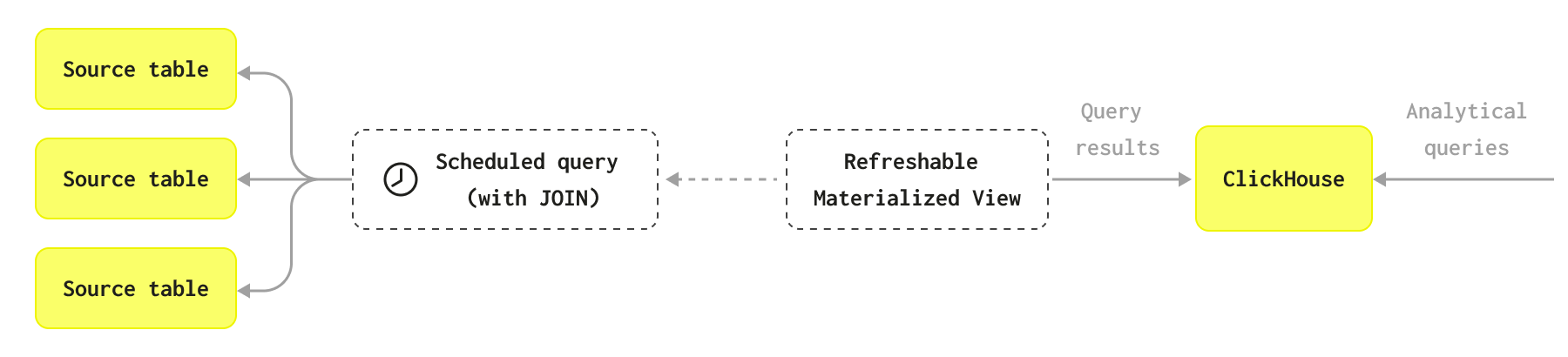
您还可以观看以下视频
何时应使用可刷新物化视图?
ClickHouse 增量物化视图非常强大,并且通常比可刷新物化视图使用的方法更具可扩展性,尤其是在需要对单个表执行聚合的情况下。通过仅计算每个数据块插入时的聚合,并在最终表中合并增量状态,查询始终只在数据的子集上执行。此方法可以扩展到 PB 级数据,并且通常是首选方法。
然而,在某些使用案例中,不需要或不适用此增量过程。某些问题要么与增量方法不兼容,要么不需要实时更新,定期重建更合适。例如,您可能希望定期对完整数据集上的视图执行完整的重新计算,因为它使用了复杂的连接,这与增量方法不兼容。
可刷新物化视图可以运行执行反规范化等任务的批处理过程。可以在可刷新物化视图之间创建依赖关系,以便一个视图依赖于另一个视图的结果,并且仅在完成后执行。这可以取代计划的工作流程或简单的 DAG,例如 dbt 作业。要了解有关如何在可刷新物化视图之间设置依赖关系的更多信息,请转到 CREATE VIEW 的 Dependencies 部分。
如何刷新可刷新物化视图?
可刷新物化视图会按照创建时定义的间隔自动刷新。例如,以下物化视图每分钟刷新一次
CREATE MATERIALIZED VIEW table_name_mv
REFRESH EVERY 1 MINUTE TO table_name AS
...
如果您想强制刷新物化视图,可以使用 SYSTEM REFRESH VIEW 子句
SYSTEM REFRESH VIEW table_name_mv;
您还可以取消、停止或启动视图。有关更多详细信息,请参阅管理可刷新物化视图文档。
可刷新物化视图上次刷新是什么时候?
要查找可刷新物化视图上次刷新时间,您可以查询 system.view_refreshes 系统表,如下所示
SELECT database, view, status,
last_success_time, last_refresh_time, next_refresh_time,
read_rows, written_rows
FROM system.view_refreshes;
┌─database─┬─view─────────────┬─status────┬───last_success_time─┬───last_refresh_time─┬───next_refresh_time─┬─read_rows─┬─written_rows─┐
│ database │ table_name_mv │ Scheduled │ 2024-11-11 12:10:00 │ 2024-11-11 12:10:00 │ 2024-11-11 12:11:00 │ 5491132 │ 817718 │
└──────────┴──────────────────┴───────────┴─────────────────────┴─────────────────────┴─────────────────────┴───────────┴──────────────┘
如何更改刷新率?
要更改可刷新物化视图的刷新率,请使用 ALTER TABLE...MODIFY REFRESH 语法。
ALTER TABLE table_name_mv
MODIFY REFRESH EVERY 30 SECONDS;
完成后,您可以使用“可刷新物化视图上次刷新是什么时候?”查询来检查速率是否已更新
┌─database─┬─view─────────────┬─status────┬───last_success_time─┬───last_refresh_time─┬───next_refresh_time─┬─read_rows─┬─written_rows─┐
│ database │ table_name_mv │ Scheduled │ 2024-11-11 12:22:30 │ 2024-11-11 12:22:30 │ 2024-11-11 12:23:00 │ 5491132 │ 817718 │
└──────────┴──────────────────┴───────────┴─────────────────────┴─────────────────────┴─────────────────────┴───────────┴──────────────┘
使用 APPEND 添加新行
APPEND 功能允许您将新行添加到表末尾,而不是替换整个视图。
此功能的一个用途是在某个时间点捕获值的快照。例如,假设我们有一个 events 表,该表由来自 Kafka、Redpanda 或其他流数据平台的消息流填充。
SELECT *
FROM events
LIMIT 10
Query id: 7662bc39-aaf9-42bd-b6c7-bc94f2881036
┌──────────────────ts─┬─uuid─┬─count─┐
│ 2008-08-06 17:07:19 │ 0eb │ 547 │
│ 2008-08-06 17:07:19 │ 60b │ 148 │
│ 2008-08-06 17:07:19 │ 106 │ 750 │
│ 2008-08-06 17:07:19 │ 398 │ 875 │
│ 2008-08-06 17:07:19 │ ca0 │ 318 │
│ 2008-08-06 17:07:19 │ 6ba │ 105 │
│ 2008-08-06 17:07:19 │ df9 │ 422 │
│ 2008-08-06 17:07:19 │ a71 │ 991 │
│ 2008-08-06 17:07:19 │ 3a2 │ 495 │
│ 2008-08-06 17:07:19 │ 598 │ 238 │
└─────────────────────┴──────┴───────┘
此数据集在 uuid 列中有 4096 个值。我们可以编写以下查询来查找总计数最高的那些
SELECT
uuid,
sum(count) AS count
FROM events
GROUP BY ALL
ORDER BY count DESC
LIMIT 10
┌─uuid─┬───count─┐
│ c6f │ 5676468 │
│ 951 │ 5669731 │
│ 6a6 │ 5664552 │
│ b06 │ 5662036 │
│ 0ca │ 5658580 │
│ 2cd │ 5657182 │
│ 32a │ 5656475 │
│ ffe │ 5653952 │
│ f33 │ 5653783 │
│ c5b │ 5649936 │
└──────┴─────────┘
假设我们想每 10 秒捕获每个 uuid 的计数,并将其存储在一个名为 events_snapshot 的新表中。events_snapshot 的模式将如下所示
CREATE TABLE events_snapshot (
ts DateTime32,
uuid String,
count UInt64
)
ENGINE = MergeTree
ORDER BY uuid;
然后我们可以创建一个可刷新物化视图来填充此表
CREATE MATERIALIZED VIEW events_snapshot_mv
REFRESH EVERY 10 SECOND APPEND TO events_snapshot
AS SELECT
now() AS ts,
uuid,
sum(count) AS count
FROM events
GROUP BY ALL;
然后我们可以查询 events_snapshot 以获取特定 uuid 随时间的计数
SELECT *
FROM events_snapshot
WHERE uuid = 'fff'
ORDER BY ts ASC
FORMAT PrettyCompactMonoBlock
┌──────────────────ts─┬─uuid─┬───count─┐
│ 2024-10-01 16:12:56 │ fff │ 5424711 │
│ 2024-10-01 16:13:00 │ fff │ 5424711 │
│ 2024-10-01 16:13:10 │ fff │ 5424711 │
│ 2024-10-01 16:13:20 │ fff │ 5424711 │
│ 2024-10-01 16:13:30 │ fff │ 5674669 │
│ 2024-10-01 16:13:40 │ fff │ 5947912 │
│ 2024-10-01 16:13:50 │ fff │ 6203361 │
│ 2024-10-01 16:14:00 │ fff │ 6501695 │
└─────────────────────┴──────┴─────────┘
示例
现在让我们看看如何将可刷新物化视图与一些示例数据集一起使用。
Stack Overflow
反规范化数据指南展示了使用 Stack Overflow 数据集反规范化数据的各种技术。我们将数据填充到以下表中:votes、users、badges、posts 和 postlinks。
在该指南中,我们展示了如何使用以下查询将 postlinks 数据集反规范化到 posts 表上
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
然后,我们展示了如何将此数据一次性插入到 posts_with_links 表中,但在生产系统中,我们希望定期运行此操作。
posts 和 postlinks 表都可能被更新。因此,与其尝试使用增量物化视图来实现此连接,不如简单地计划以设定的间隔(例如,每小时一次)运行此查询,并将结果存储在 post_with_links 表中就足够了。
这就是可刷新物化视图的用武之地,我们可以使用以下查询创建一个
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
该视图将立即执行,并在之后每小时按配置执行,以确保反映对源表的更新。重要的是,当查询重新运行时,结果集将以原子方式透明地更新。
此处的语法与增量物化视图相同,只是我们包含了一个 REFRESH 子句
IMDb
在dbt 和 ClickHouse 集成指南中,我们使用以下表填充了 IMDb 数据集:actors、directors、genres、movie_directors、movies 和 roles。
然后,我们可以编写以下查询,用于计算每个演员的摘要,并按电影出场次数最多排序。
SELECT
id, any(actor_name) AS name, uniqExact(movie_id) AS movies,
round(avg(rank), 2) AS avg_rank, uniqExact(genre) AS genres,
uniqExact(director_name) AS directors, max(created_at) AS updated_at
FROM (
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id, imdb.movies.rank AS rank, genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY movies DESC
LIMIT 5;
┌─────id─┬─name─────────┬─num_movies─┬───────────avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884792542982515 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605094212635 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034230202023 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342420755093 │ 16 │ 157 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴──────────────┴────────────┴────────────────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.393 sec. Processed 5.45 million rows, 86.82 MB (13.87 million rows/s., 221.01 MB/s.)
Peak memory usage: 1.38 GiB.
返回结果不需要太长时间,但假设我们希望它更快且计算成本更低。假设此数据集也会不断更新 - 电影不断上映,新的演员和导演也不断涌现。
现在是使用可刷新物化视图的时候了,所以我们首先为结果创建一个目标表
CREATE TABLE imdb.actor_summary
(
`id` UInt32,
`name` String,
`num_movies` UInt16,
`avg_rank` Float32,
`unique_genres` UInt16,
`uniq_directors` UInt16,
`updated_at` DateTime
)
ENGINE = MergeTree
ORDER BY num_movies
现在我们可以定义视图了
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC;
该视图将立即执行,并在之后每分钟按配置执行,以确保反映对源表的更新。我们之前获取演员摘要的查询在语法上变得更简单,速度也明显更快!
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
┌─────id─┬─name─────────┬─num_movies─┬──avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 356804 │ Bud Osborne │ 544 │ 1.9575342 │ 16 │ 157 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴──────────────┴────────────┴───────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.007 sec.
假设我们在源数据中添加了一个新演员“Clicky McClickHouse”,他碰巧出演了很多电影!
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910;
不到 60 秒后,我们的目标表就会更新,以反映 Clicky 演艺生涯的丰硕成果
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5;
┌─────id─┬─name────────────────┬─num_movies─┬──avg_rank─┬─unique_genres─┬─uniq_directors─┬──────────updated_at─┐
│ 845466 │ Clicky McClickHouse │ 910 │ 1.4687939 │ 21 │ 662 │ 2024-11-11 12:53:51 │
│ 45332 │ Mel Blanc │ 909 │ 5.7884793 │ 19 │ 148 │ 2024-11-11 12:01:35 │
│ 621468 │ Bess Flowers │ 672 │ 5.540605 │ 20 │ 301 │ 2024-11-11 12:01:35 │
│ 283127 │ Tom London │ 549 │ 2.8057034 │ 18 │ 208 │ 2024-11-11 12:01:35 │
│ 41669 │ Adoor Bhasi │ 544 │ 0 │ 4 │ 121 │ 2024-11-11 12:01:35 │
└────────┴─────────────────────┴────────────┴───────────┴───────────────┴────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.006 sec.