集成 dbt 和 ClickHouse
dbt (数据构建工具) 使分析工程师能够通过简单地编写 select 语句来转换其数据仓库中的数据。dbt 处理将这些 select 语句物化为数据库中的对象,形式为表和视图 - 执行 提取、加载和转换 (ELT) 中的 T。用户可以创建一个由 SELECT 语句定义的模型。
在 dbt 中,这些模型可以交叉引用和分层,以构建更高级别的概念。连接模型所需的样板 SQL 会自动生成。此外,dbt 识别模型之间的依赖关系,并使用有向无环图 (DAG) 确保它们以适当的顺序创建。
Dbt 通过 ClickHouse 支持的插件与 ClickHouse 兼容。我们描述了使用基于公开可用的 IMDB 数据集的简单示例连接 ClickHouse 的过程。我们还强调了当前连接器的一些限制。
概念
dbt 引入了模型的概念。这被定义为一个 SQL 语句,可能连接了多个表。模型可以通过多种方式“物化”。物化表示模型 select 查询的构建策略。物化背后的代码是样板 SQL,它将您的 SELECT 查询包装在一个语句中,以便创建新关系或更新现有关系。
dbt 提供了 4 种类型的物化
- view(默认):模型在数据库中构建为视图。
- table:模型在数据库中构建为表。
- ephemeral:模型不会直接在数据库中构建,而是作为公共表表达式拉入到依赖模型中。
- incremental:模型最初物化为一个表,在后续运行中,dbt 在表中插入新行并更新已更改的行。
附加的语法和子句定义了如果其底层数据发生更改,应如何更新这些模型。dbt 通常建议从视图物化开始,直到性能成为问题。表物化通过将模型查询的结果捕获为表来提高查询时间性能,但代价是增加了存储空间。增量方法在此基础上进一步发展,允许在目标表中捕获对底层数据的后续更新。
当前插件 用于 ClickHouse 支持 view、table、ephemeral 和 incremental 物化。该插件还支持 dbt 快照 和 种子,我们将在本指南中探讨这些内容。
对于以下指南,我们假设您有一个可用的 ClickHouse 实例。
dbt 和 ClickHouse 插件的设置
dbt
对于以下示例,我们假设使用 dbt CLI。用户可能还希望考虑 dbt Cloud,它提供了一个基于 Web 的集成开发环境 (IDE),允许用户编辑和运行项目。
dbt 提供了许多 CLI 安装选项。按照 此处 描述的说明进行操作。在此阶段仅安装 dbt-core。我们建议使用 pip。
pip install dbt-core
重要提示:以下内容在 python 3.9 下测试通过。
ClickHouse 插件
安装 dbt ClickHouse 插件
pip install dbt-clickhouse
准备 ClickHouse
当对高度关系型数据进行建模时,dbt 表现出色。为了举例说明,我们提供了一个小型 IMDB 数据集,其关系模式如下。该数据集来源于 关系数据集存储库。相对于 dbt 常用的模式,这很简单,但代表了一个可管理的示例
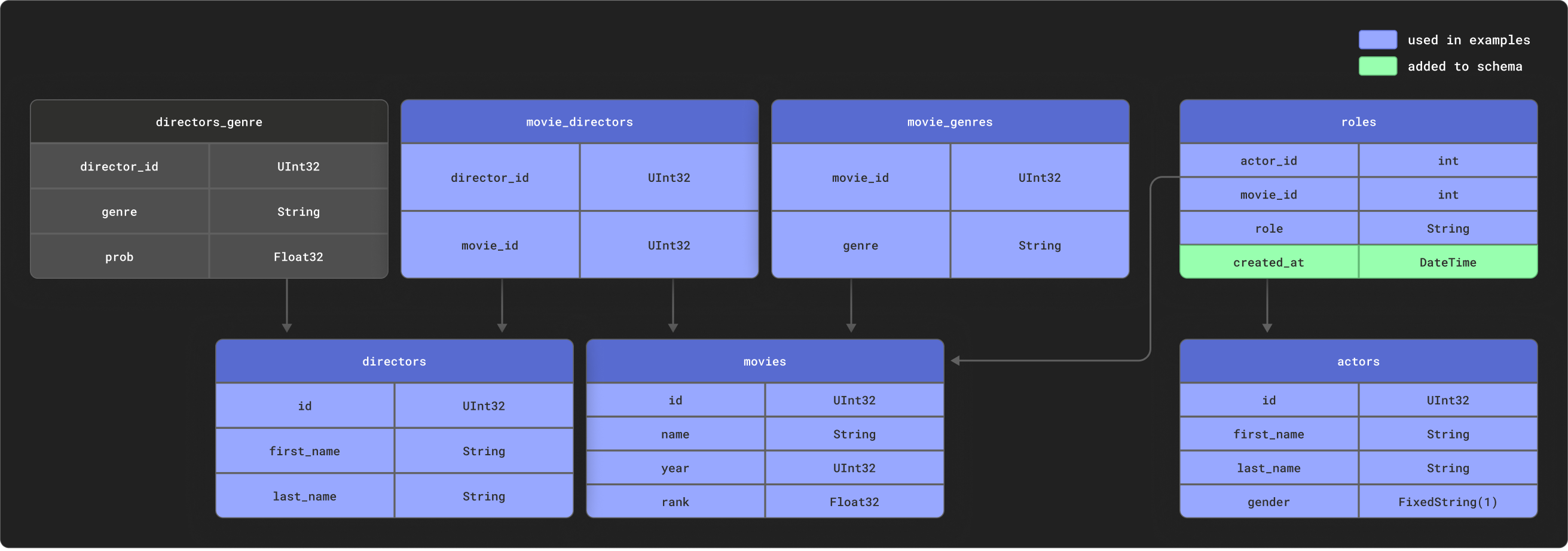
我们使用这些表的子集,如图所示。
创建以下表
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
表 roles 的列 created_at,默认值为 now()。我们稍后使用它来识别模型的增量更新 - 请参阅 增量模型。
我们使用 s3 函数从公共端点读取源数据以插入数据。运行以下命令来填充表
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
这些命令的执行时间可能会因您的带宽而异,但每个命令都应该只需几秒钟即可完成。执行以下查询以计算每个演员的摘要,按电影出场次数最多排序,并确认数据已成功加载
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
响应应如下所示
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
在后面的指南中,我们将把此查询转换为模型 - 在 ClickHouse 中将其物化为 dbt 视图和表。
连接到 ClickHouse
-
创建一个 dbt 项目。在本例中,我们以我们的
imdb源命名。当出现提示时,选择clickhouse作为数据库源。clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile -
cd进入您的项目文件夹cd imdb -
此时,您将需要您选择的文本编辑器。在下面的示例中,我们使用流行的 VS Code。打开 IMDB 目录,您应该看到 yml 和 sql 文件的集合
-
更新您的
dbt_project.yml文件以指定我们的第一个模型 -actor_summary并将 profile 设置为clickhouse_imdb。

-
接下来,我们需要为 dbt 提供 ClickHouse 实例的连接详细信息。将以下内容添加到您的
~/.dbt/profiles.yml。clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: False注意需要修改用户和密码。 此处 记录了其他可用设置。
-
从 IMDB 目录,执行
dbt debug命令以确认 dbt 是否能够连接到 ClickHouse。clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!确认响应包括
Connection test: [OK connection ok],表明连接成功。
创建简单的视图物化
当使用视图物化时,模型在每次运行时都通过 ClickHouse 中的 CREATE VIEW AS 语句重建为视图。这不需要任何额外的数据存储,但查询速度会比表物化慢。
-
从
imdb文件夹中,删除目录models/exampleclickhouse-user@clickhouse:~/imdb$ rm -rf models/example -
在
models文件夹中的actors中创建一个新文件。这里我们创建每个文件代表一个演员模型clickhouse-user@clickhouse:~/imdb$ mkdir models/actors -
在
models/actors文件夹中创建文件schema.yml和actor_summary.sql。clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.yml文件
schema.yml定义了我们的表。这些表随后将在宏中可用。编辑models/actors/schema.yml以包含此内容version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directorsactors_summary.sql文件定义了我们的实际模型。请注意,在 config 函数中,我们还请求将模型物化为 ClickHouse 中的视图。我们的表从schema.yml文件中通过函数source引用,例如source('imdb', 'movies')引用imdb数据库中的movies表。编辑models/actors/actors_summary.sql以包含此内容{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary请注意我们如何在最终的 actor_summary 中包含
updated_at列。我们稍后将其用于增量物化。 -
从
imdb目录执行命令dbt run。clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1 -
dbt 将按请求将模型表示为 ClickHouse 中的视图。我们现在可以直接查询此视图。此视图将在
imdb_dbt数据库中创建 - 这由文件~/.dbt/profiles.yml中clickhouse_imdbprofile 下的 schema 参数确定。SHOW DATABASES;+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---created by dbt!
|information_schema|
|system |
+------------------+查询此视图,我们可以使用更简单的语法复制我们之前的查询结果
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
创建表物化
在前面的示例中,我们的模型被物化为视图。虽然这可能为某些查询提供足够的性能,但更复杂的 SELECT 或频繁执行的查询可能最好物化为表。此物化对于 BI 工具将查询的模型很有用,以确保用户获得更快的体验。这有效地使查询结果存储为新表,并具有相关的存储开销 - 实际上,执行了 INSERT TO SELECT。请注意,此表每次都会重建,即它不是增量的。因此,大型结果集可能会导致较长的执行时间 - 请参阅 dbt 限制。
-
修改文件
actors_summary.sql,使materialized参数设置为table。请注意ORDER BY是如何定义的,并注意我们使用了MergeTree表引擎{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }} -
从
imdb目录执行命令dbt run。此执行可能需要更长的时间才能执行 - 在大多数机器上大约 10 秒。clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1 -
确认表
imdb_dbt.actor_summary的创建SHOW CREATE TABLE imdb_dbt.actor_summary;您应该看到具有适当数据类型的表
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
|SETTINGS index_granularity = 8192
+---------------------------------------- -
确认此表的结果与之前的响应一致。请注意,现在模型是一个表,响应时间有了明显的改善
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+随意对此模型发出其他查询。例如,哪些演员出演了排名最高的电影,且出场次数超过 5 次?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
创建增量物化
之前的示例创建了一个表来物化模型。对于每次 dbt 执行,此表都将重建。对于较大的结果集或复杂的转换,这可能是不可行的且成本极高。为了解决此挑战并缩短构建时间,dbt 提供了增量物化。这允许 dbt 自上次执行以来将记录插入或更新到表中,使其适用于事件样式数据。在幕后,将创建一个临时表,其中包含所有更新的记录,然后将所有未触及的记录以及更新的记录都插入到新的目标表中。这导致大型结果集与表模型类似的 限制。
为了克服大型数据集的这些限制,该插件支持“inserts_only”模式,其中所有更新都插入到目标表中,而无需创建临时表(下面有更多介绍)。
为了说明此示例,我们将添加演员“Clicky McClickHouse”,他将出演惊人的 910 部电影 - 确保他出演的电影甚至超过了 梅尔·布兰科。
-
首先,我们将我们的模型修改为增量类型。此添加需要
- unique_key - 为了确保插件可以唯一标识行,我们必须提供一个 unique_key - 在本例中,查询中的
id字段就足够了。这确保了我们的物化表中不会有重复的行。有关唯一性约束的更多详细信息,请参阅此处。 - 增量过滤器 - 我们还需要告诉 dbt 它应该如何识别哪些行在增量运行中发生了更改。这通过提供 delta 表达式来实现。通常,这涉及事件数据的时间戳;因此我们的 updated_at 时间戳字段。此列默认为插入行时的时间戳值 now(),允许识别新角色。此外,我们需要识别添加新演员的另一种情况。使用
{{this}}变量来表示现有的物化表,这给了我们表达式where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})。我们将此嵌入到{% if is_incremental() %}条件中,确保它仅在增量运行时使用,而不是在首次构建表时使用。有关为增量模型过滤行的更多详细信息,请参阅 dbt 文档中的此讨论。
按如下方式更新文件
actor_summary.sql{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}请注意,我们的模型只会响应对
roles和actors表的更新和添加。为了响应所有表,建议用户将此模型拆分为多个子模型 - 每个子模型都有自己的增量标准。这些模型可以反过来被引用和连接。有关交叉引用模型的更多详细信息,请参阅 此处。 - unique_key - 为了确保插件可以唯一标识行,我们必须提供一个 unique_key - 在本例中,查询中的
-
执行
dbt run并确认结果表的結果clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+ -
我们现在将向我们的模型添加数据以说明增量更新。将我们的演员“Clicky McClickHouse”添加到
actors表中INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M'); -
让“Clicky”出演 910 部随机电影
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000; -
通过查询底层源表并绕过任何 dbt 模型来确认他现在确实是出场次数最多的演员
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+ -
执行
dbt run并确认我们的模型已更新并与上述结果匹配clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
内部原理
我们可以通过查询 ClickHouse 的查询日志来识别为实现上述增量更新而执行的语句。
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
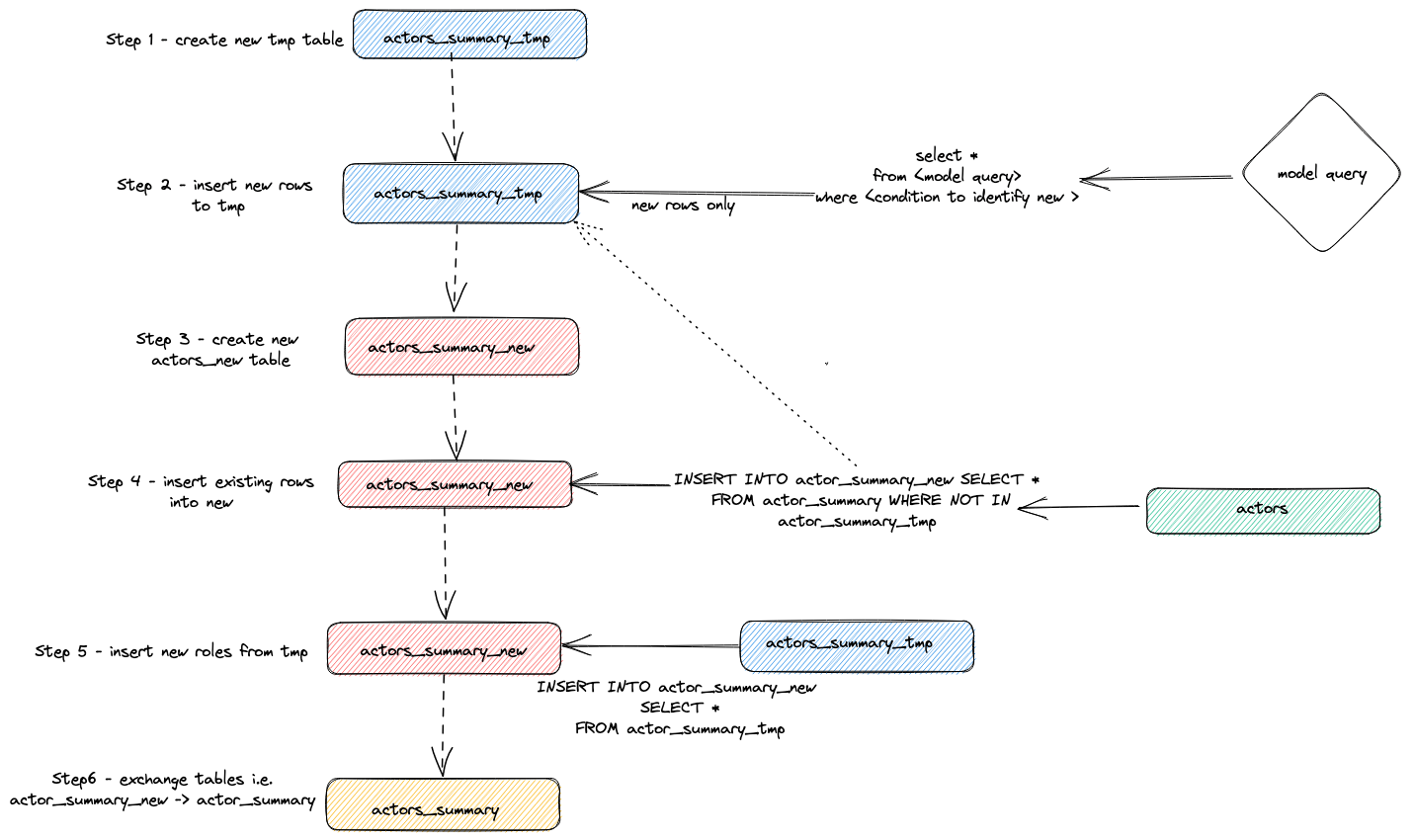
将上述查询调整到执行期间。我们将结果检查留给用户,但重点介绍插件用于执行增量更新的总体策略
- 插件创建一个临时表
actor_sumary__dbt_tmp。已更改的行被流式传输到此表中。 - 创建一个新表
actor_summary_new。旧表中的行又从旧表流式传输到新表,并检查以确保行 ID 不存在于临时表中。这有效地处理了更新和重复项。 - 临时表的结果被流式传输到新的
actor_summary表中 - 最后,通过
EXCHANGE TABLES语句将新表与旧版本原子地交换。旧表和临时表依次被删除。
这在下面可视化
此策略在非常大的模型上可能会遇到挑战。有关更多详细信息,请参阅 限制。
追加策略(inserts-only 模式)
为了克服增量模型中大型数据集的限制,该插件使用了 dbt 配置参数 incremental_strategy。可以将其设置为值 append。设置后,更新的行将直接插入到目标表(也称为 imdb_dbt.actor_summary),并且不创建临时表。注意:仅追加模式要求您的数据是不可变的,或者重复项是可以接受的。如果您想要一个支持更改行的增量表模型,请不要使用此模式!
为了说明此模式,我们将添加另一个新演员并使用 incremental_strategy='append' 重新执行 dbt run。
-
在 actor_summary.sql 中配置仅追加模式
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }} -
让我们添加另一位著名演员 - Danny DeBito
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M'); -
让 Danny 出演 920 部随机电影。
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000; -
执行 dbt run 并确认 Danny 已添加到 actor-summary 表中
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
请注意,与插入“Clicky”相比,此增量快了多少。
再次检查 query_log 表,揭示了 2 次增量运行之间的差异
insert into imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
select *
from actor_summary
-- this filter will only be applied on an incremental run
where id > (select max(id) from imdb_dbt.actor_summary) or updated_at > (select max(updated_at) from imdb_dbt.actor_summary)
在此运行中,只有新行直接添加到 imdb_dbt.actor_summary 表,并且不涉及表创建。
Delete+Insert 模式(实验性)
从历史上看,ClickHouse 对更新和删除的支持有限,形式为异步 Mutations。这些操作可能会非常占用 IO,通常应避免使用。
ClickHouse 22.8 引入了 轻量级删除。这些目前是实验性的,但提供了一种性能更高的删除数据方式。
可以通过 incremental_strategy 参数为模型配置此模式,即
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
此策略直接在目标模型的表上运行,因此如果在操作期间出现问题,增量模型中的数据很可能处于无效状态 - 没有原子更新。
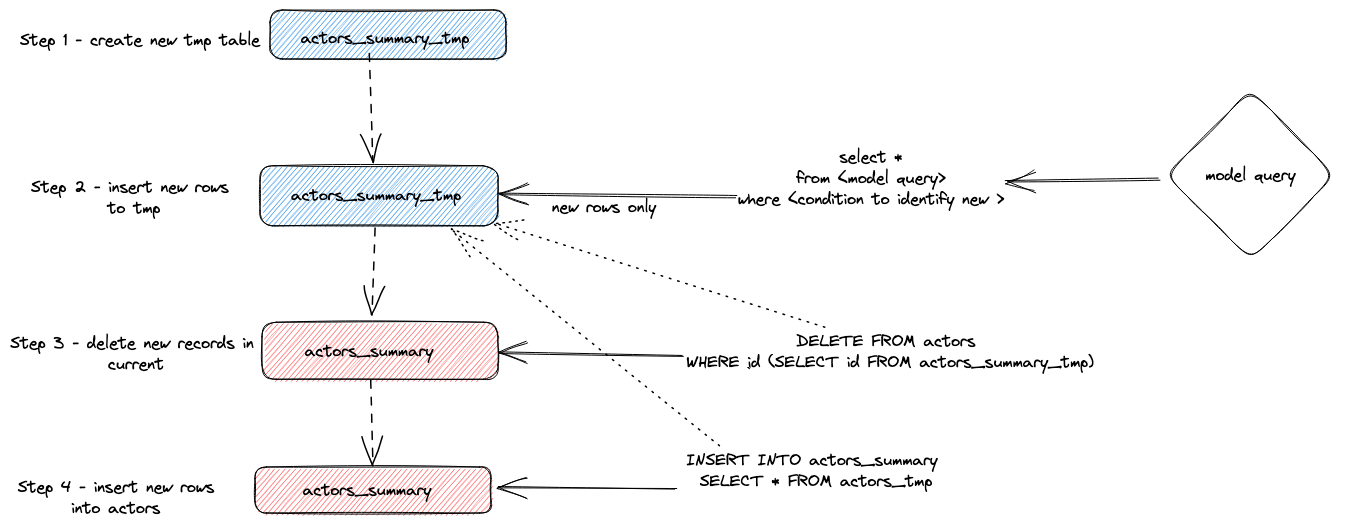
总而言之,此方法
- 插件创建一个临时表
actor_sumary__dbt_tmp。已更改的行被流式传输到此表中。 - 对当前的
actor_summary表发出DELETE。从actor_sumary__dbt_tmp中按 ID 删除行 - 使用
INSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp将actor_sumary__dbt_tmp中的行插入到actor_summary中。
此过程如下所示
insert_overwrite 模式(实验性)
执行以下步骤
- 创建与增量模型关系具有相同结构的暂存(临时)表:
CREATE TABLE {staging} AS {target}。 - 仅将新记录(由 SELECT 生成)插入到暂存表中。
- 仅将新分区(暂存表中存在的)替换到目标表中。
此方法具有以下优点
- 它比默认策略更快,因为它不复制整个表。
- 它比其他策略更安全,因为它在 INSERT 操作成功完成之前不会修改原始表:如果发生中间故障,原始表不会被修改。
- 它实现了“分区不可变性”数据工程最佳实践。这简化了增量和并行数据处理、回滚等。
insert_overwrite 功能尚未在多节点设置上进行测试。
有关此功能实现的详细信息,请查看引入此功能的 PR。
创建快照
dbt 快照允许记录可变模型随时间的变化。这反过来允许对模型进行时间点查询,分析师可以在其中“回顾过去”查看模型的先前状态。这是通过使用type-2 缓慢变化维度实现的,其中“起始日期”和“结束日期”列记录行的有效时间。ClickHouse 插件支持此功能,并在下面进行演示。
此示例假定您已完成创建增量表模型。确保您的 actor_summary.sql 未设置 inserts_only=True。您的 models/actor_summary.sql 应如下所示
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
-
在 snapshots 目录中创建一个文件
actor_summary。touch snapshots/actor_summary.sql -
使用以下内容更新 actor_summary.sql 文件的内容
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
关于此内容的一些观察
- select 查询定义了您希望随时间快照的结果。函数 ref 用于引用我们先前创建的 actor_summary 模型。
- 我们需要一个时间戳列来指示记录更改。我们的 updated_at 列(请参阅创建增量表模型)可以在此处使用。参数 strategy 指示我们使用时间戳来表示更新,参数 updated_at 指定要使用的列。如果您的模型中不存在此列,您也可以使用check 策略。这效率明显较低,并且需要用户指定要比较的列列表。dbt 比较这些列的当前值和历史值,记录任何更改(或在相同时不执行任何操作)。
-
运行命令
dbt snapshot。clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
请注意,如何在快照数据库(由 target_schema 参数确定)中创建了表 actor_summary_snapshot。
-
对该数据进行抽样,您将看到 dbt 如何包含列 dbt_valid_from 和 dbt_valid_to。后者值设置为 null。后续运行将更新此值。
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+ -
让我们的最喜欢的演员 Clicky McClickHouse 在另外 10 部电影中出现。
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10; -
从
imdb目录重新运行 dbt run 命令。这将更新增量模型。完成后,运行 dbt snapshot 以捕获更改。clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1 -
如果我们现在查询我们的快照,请注意 Clicky McClickHouse 有 2 行。我们之前的条目现在有一个 dbt_valid_to 值。我们的新值记录在 dbt_valid_from 列中,dbt_valid_to 值为 null。如果我们有新行,这些行也会附加到快照中。
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
有关 dbt 快照的更多详细信息,请参阅此处。
使用 Seeds
dbt 提供了从 CSV 文件加载数据的能力。此功能不适合加载大型数据库导出,更适合用于通常用于代码表和字典的小文件,例如,将国家/地区代码映射到国家/地区名称。对于一个简单的示例,我们使用 seed 功能生成然后上传一个类型代码列表。
-
我们从我们现有的数据集生成一个类型代码列表。从 dbt 目录,使用
clickhouse-client创建一个文件seeds/genre_codes.csvclickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csv -
执行
dbt seed命令。这将在我们的数据库imdb_dbt(由我们的 schema 配置定义)中创建一个新表genre_codes,其中包含来自我们的 csv 文件的行。clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1 -
确认这些已加载
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+=
局限性
当前用于 dbt 的 ClickHouse 插件有一些用户应注意的局限性
- 该插件当前使用
INSERT TO SELECT将模型物化为表。这实际上意味着数据重复。非常大的数据集 (PB) 可能会导致极长的运行时间,从而使某些模型不可行。旨在最大限度地减少任何查询返回的行数,尽可能利用 GROUP BY。首选汇总数据的模型,而不是那些在保持源行数的同时仅执行转换的模型。 - 要使用分布式表来表示模型,用户必须在每个节点上手动创建底层复制表。分布式表可以反过来在这些表之上创建。插件不管理集群创建。
- 当 dbt 在数据库中创建关系(表/视图)时,它通常将其创建为:
{{ database }}.{{ schema }}.{{ table/view id }}。ClickHouse 没有 schema 的概念。因此,插件使用{{schema}}.{{ table/view id }},其中schema是 ClickHouse 数据库。
更多信息
之前的指南仅触及了 dbt 功能的表面。建议用户阅读优秀的dbt 文档。
插件的其他配置在此处描述。
Fivetran
dbt-clickhouse 连接器也可用于 Fivetran 转换,允许直接在 Fivetran 平台中使用 dbt 进行无缝集成和转换。
相关内容
- 博客 & 网络研讨会:ClickHouse 和 dbt - 来自社区的礼物