将对象存储与 ClickHouse Cloud 集成
对象存储 ClickPipes 提供了一种简单而弹性的方式,用于将数据从 Amazon S3 和 Google Cloud Storage 摄取到 ClickHouse Cloud 中。一次性和连续摄取均受支持,并具有精确一次语义。
前提条件
您已熟悉 ClickPipes 简介。
创建您的第一个 ClickPipe
- 在云控制台中,选择左侧菜单上的“数据源”按钮,然后单击“设置 ClickPipe”
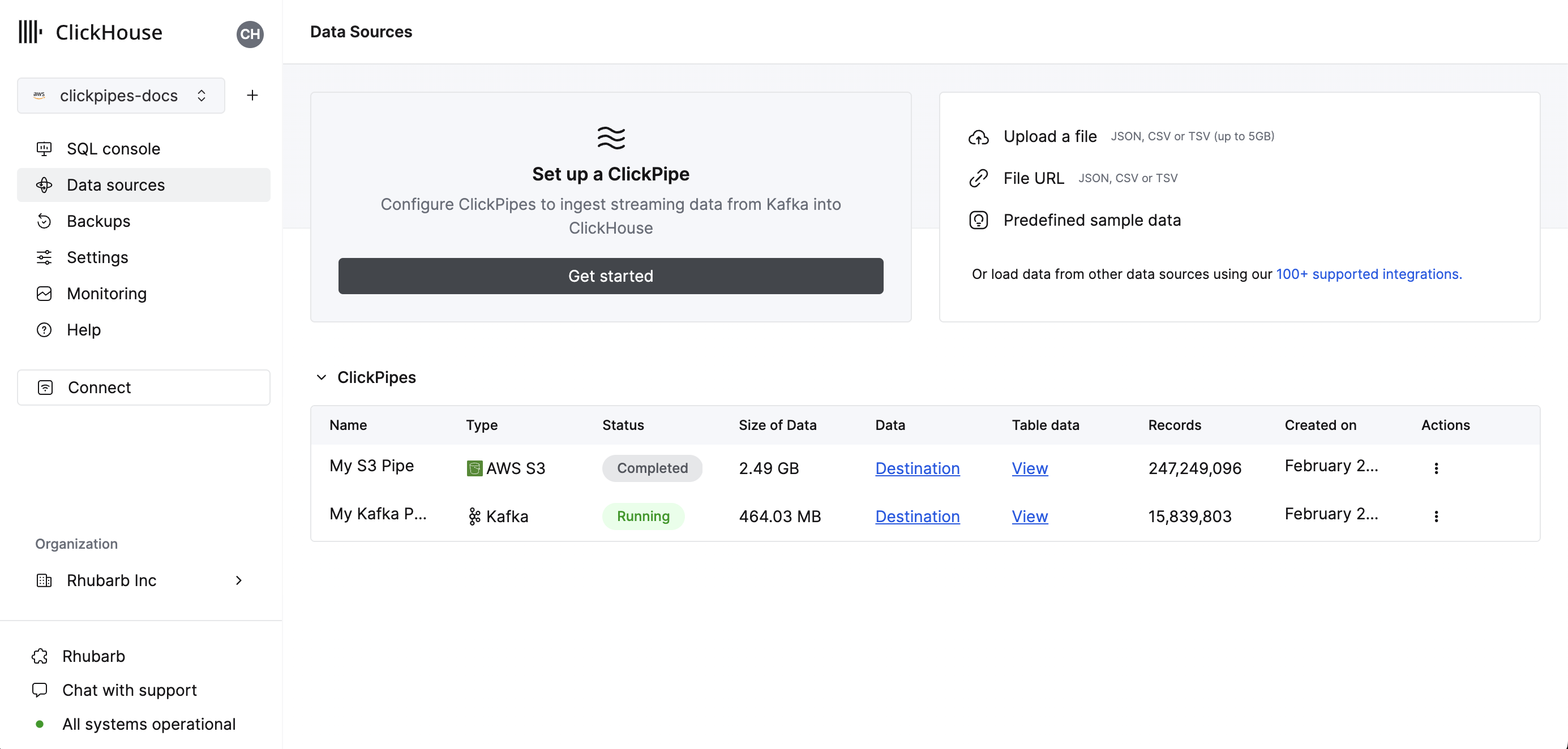
- 选择您的数据源。

- 填写表单,提供您的 ClickPipe 的名称、描述(可选)、IAM 角色或凭据以及存储桶 URL。您可以使用类似 bash 的通配符指定多个文件。有关更多信息,请参阅有关在路径中使用通配符的文档。
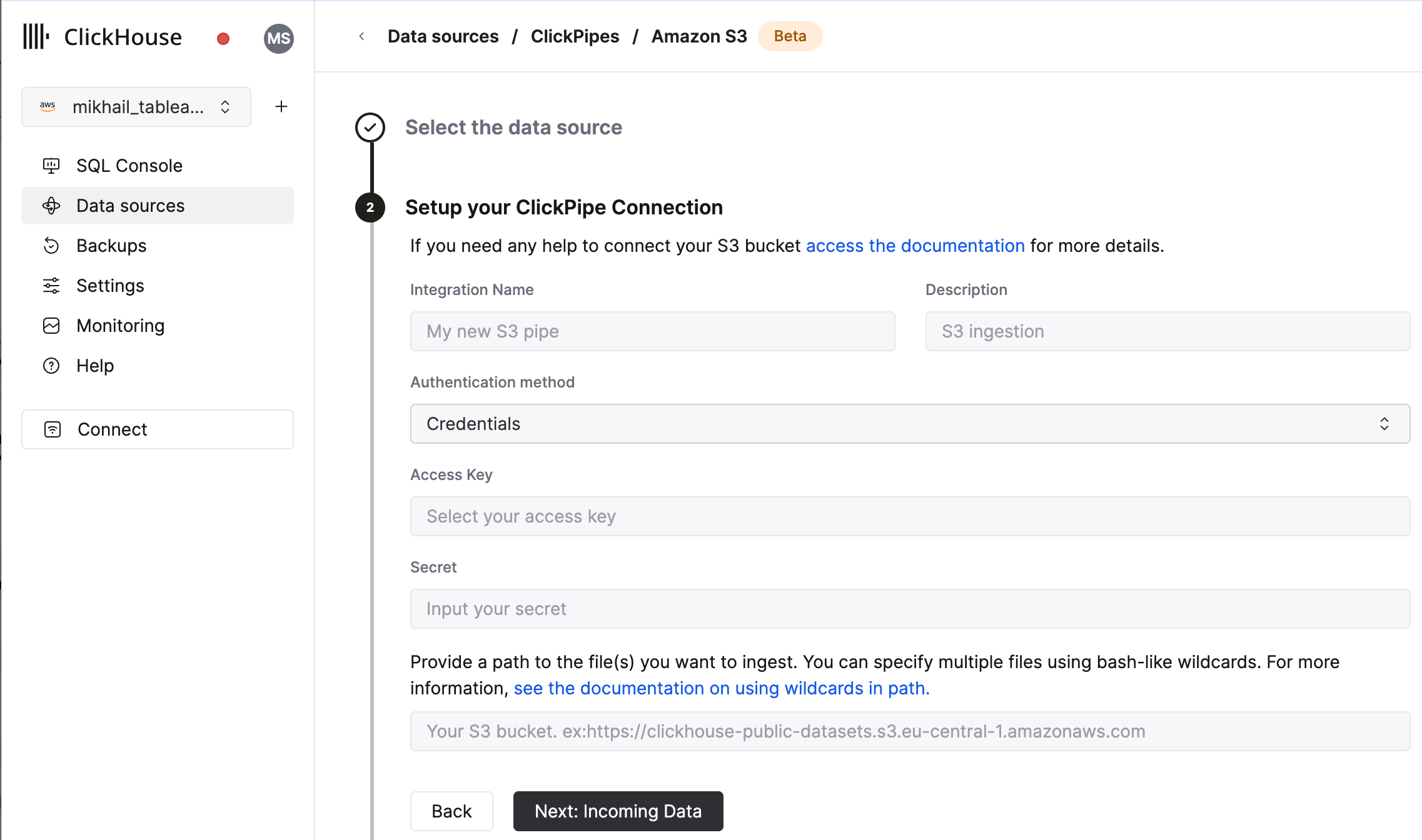
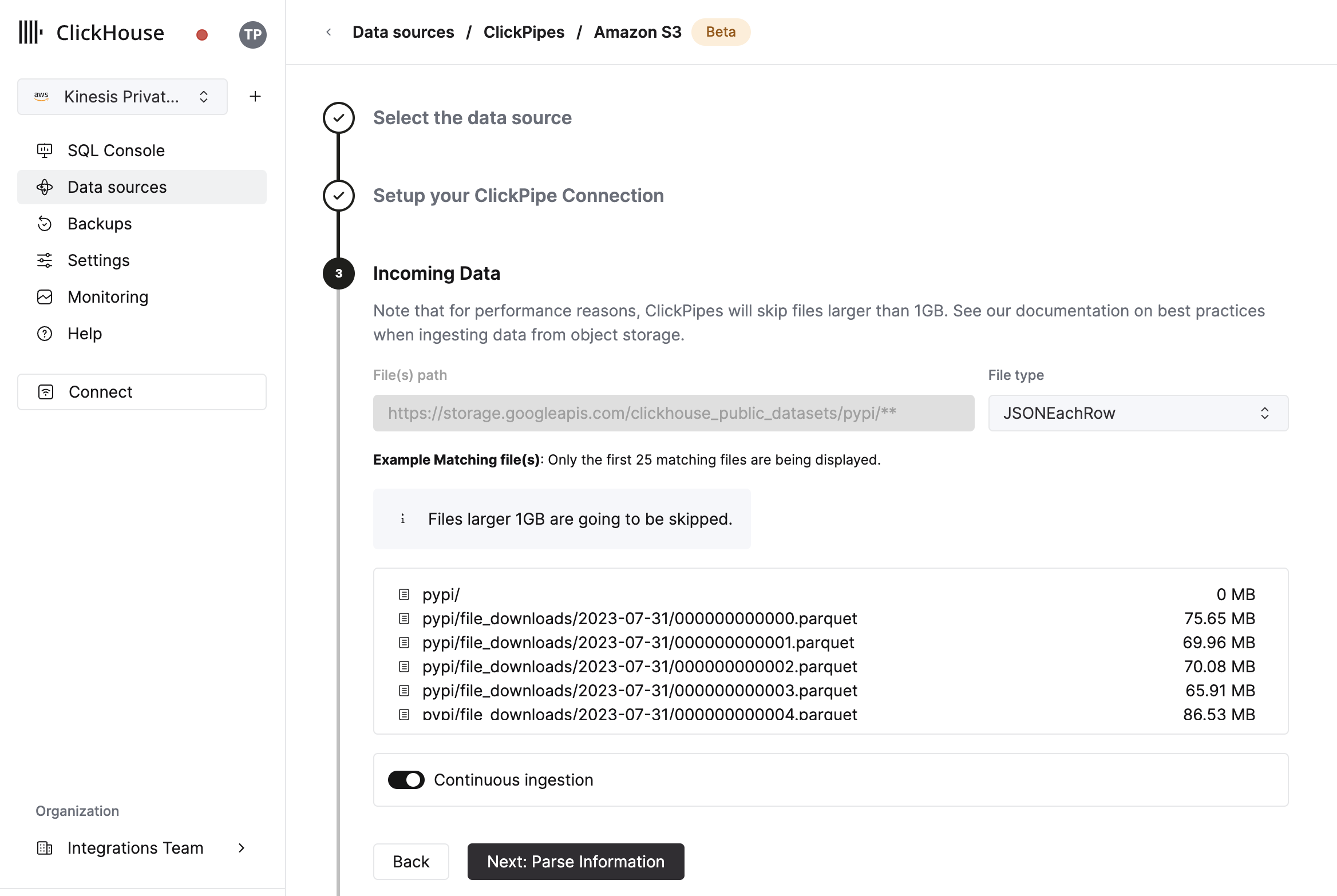
- UI 将显示指定存储桶中的文件列表。选择您的数据格式(我们目前支持 ClickHouse 格式的子集),以及是否要启用连续摄取 更多详情如下。
- 在下一步中,您可以选择是将数据摄取到新的 ClickHouse 表中,还是重用现有表。按照屏幕上的说明修改您的表名、架构和设置。您可以在顶部的示例表中看到更改的实时预览。
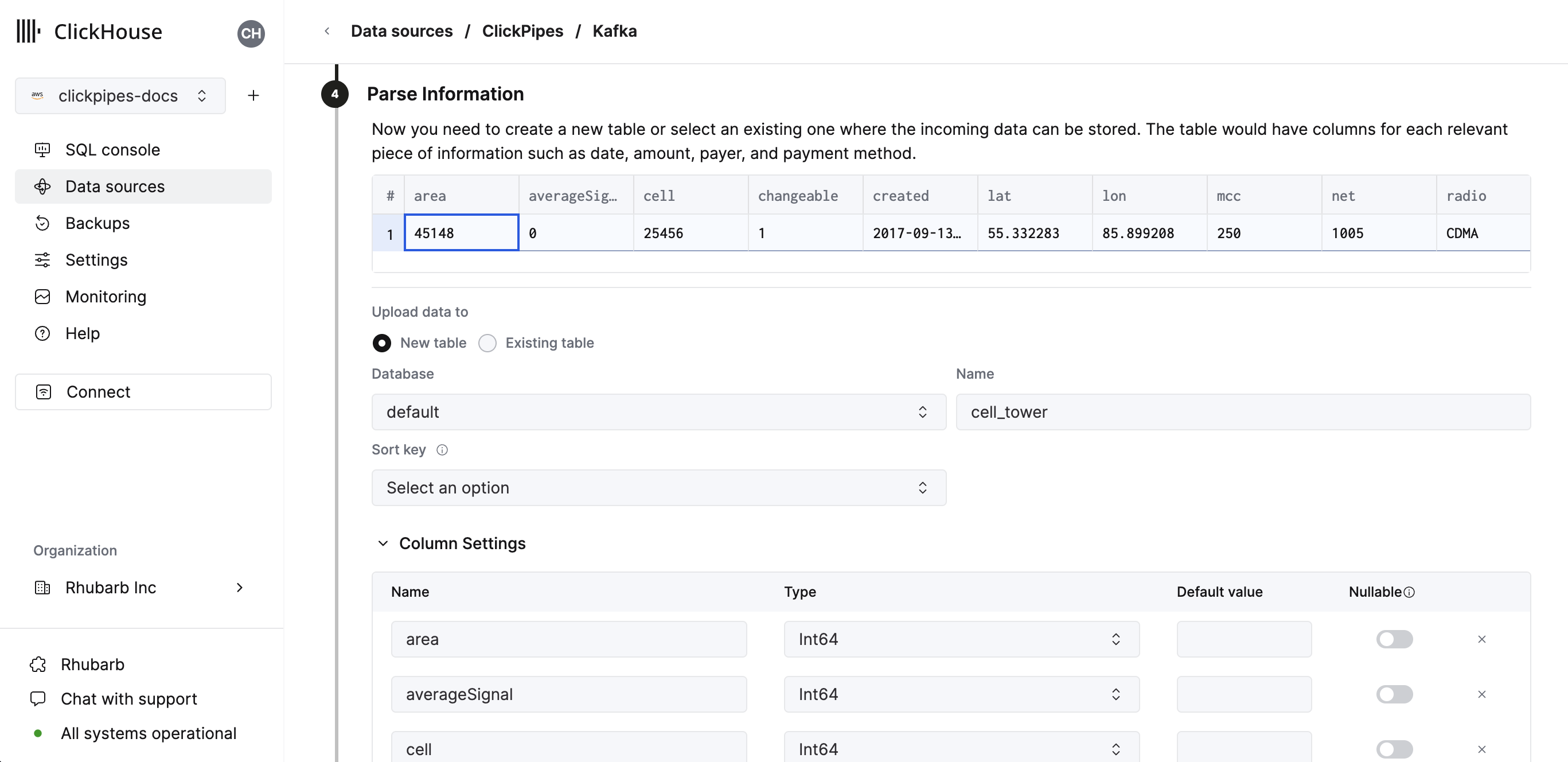
您还可以使用提供的控件自定义高级设置
- 或者,您可以决定将数据摄取到现有的 ClickHouse 表中。在这种情况下,UI 将允许您将源中的字段映射到所选目标表中的 ClickHouse 字段。
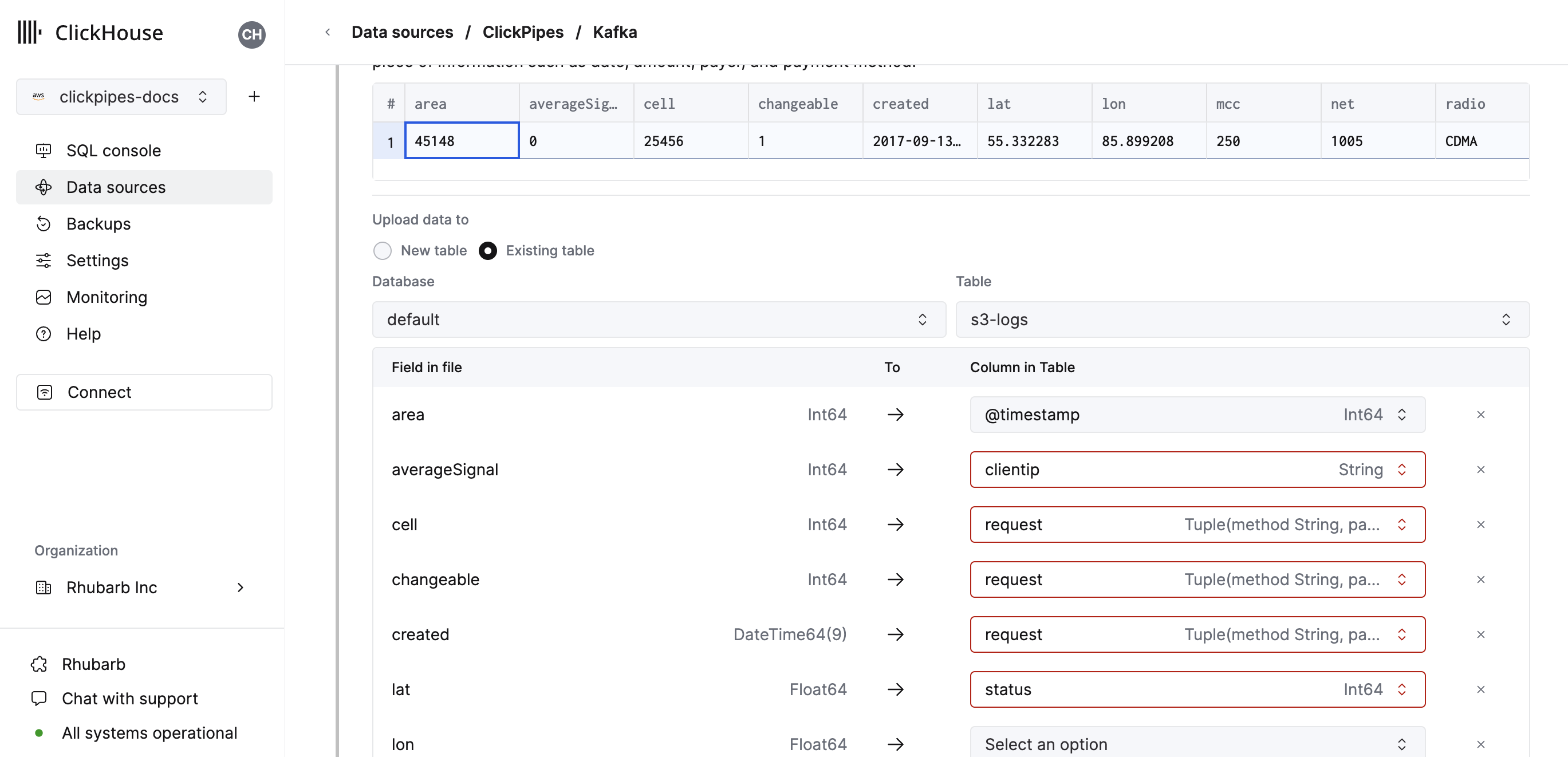
您还可以将 虚拟列(如 _path 或 _size)映射到字段。
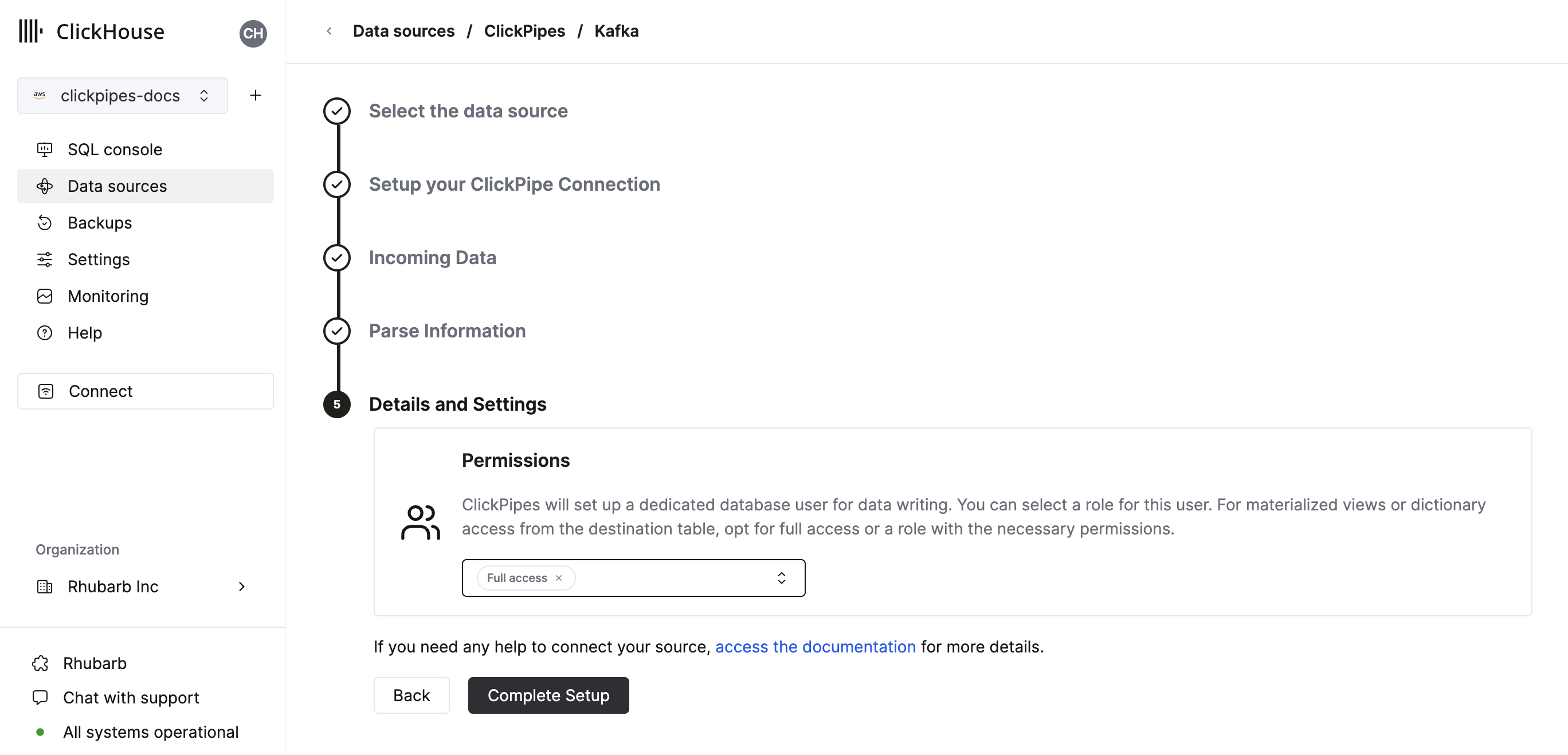
- 最后,您可以为内部 ClickPipes 用户配置权限。
权限: ClickPipes 将创建一个专用用户,用于将数据写入目标表。您可以使用自定义角色或预定义角色之一为该内部用户选择角色
完全访问权限:具有对集群的完全访问权限。如果您将物化视图或字典与目标表一起使用,则需要此权限。仅限目标表:仅对目标表具有INSERT权限。
- 通过单击“完成设置”,系统将注册您的 ClickPipe,您将能够在摘要表中看到它。

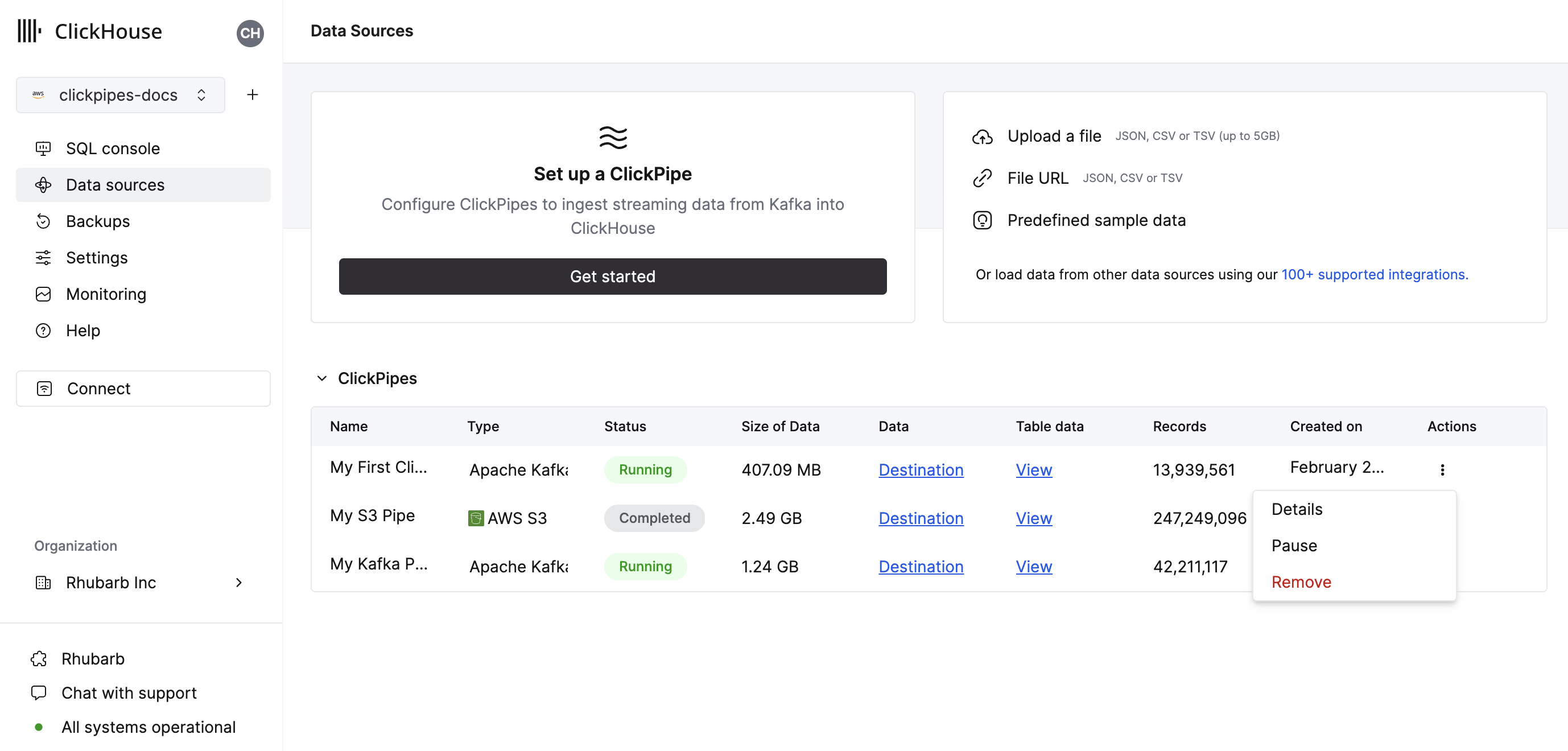
摘要表提供控件,用于显示来自源或 ClickHouse 中目标表的示例数据
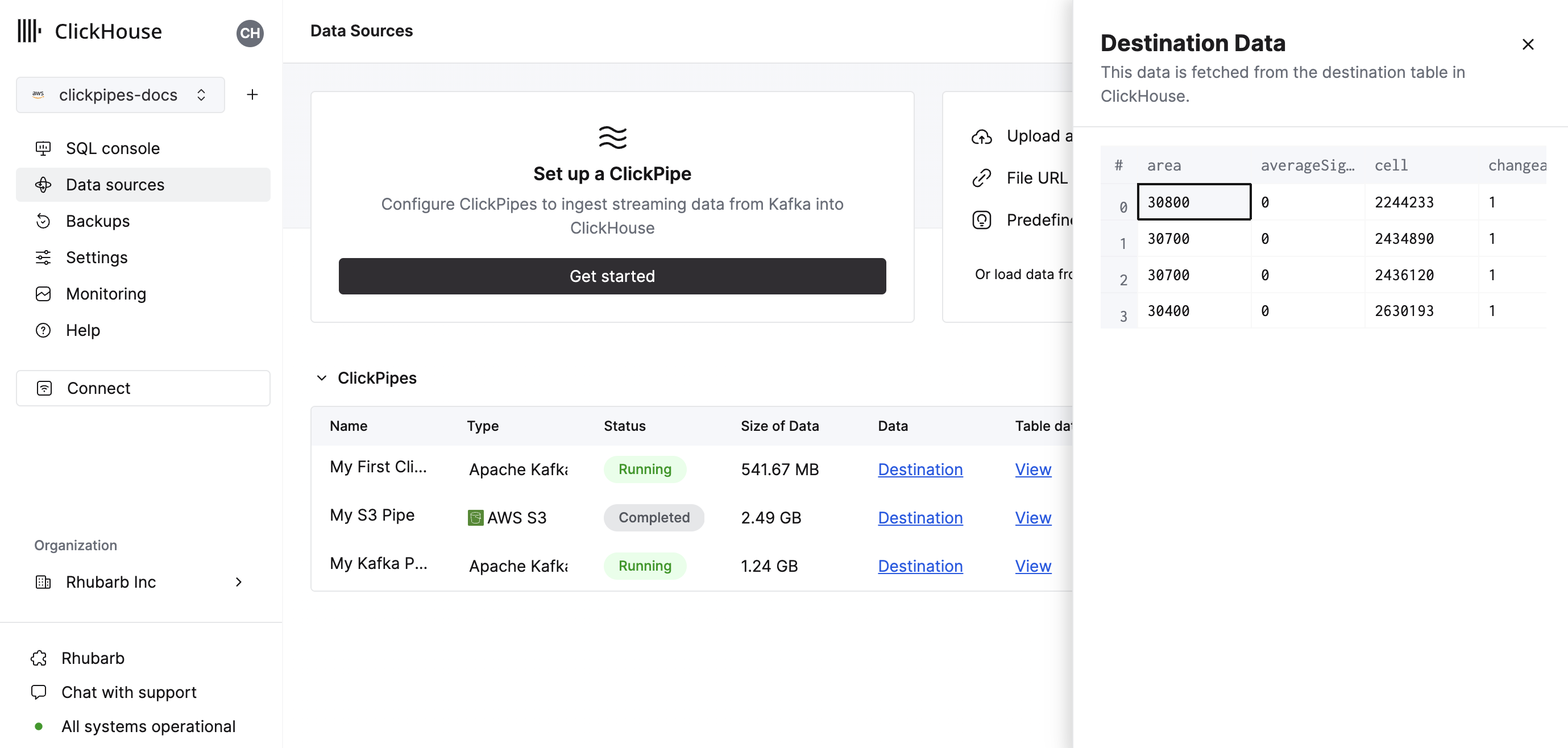
以及用于删除 ClickPipe 和显示摄取作业摘要的控件。
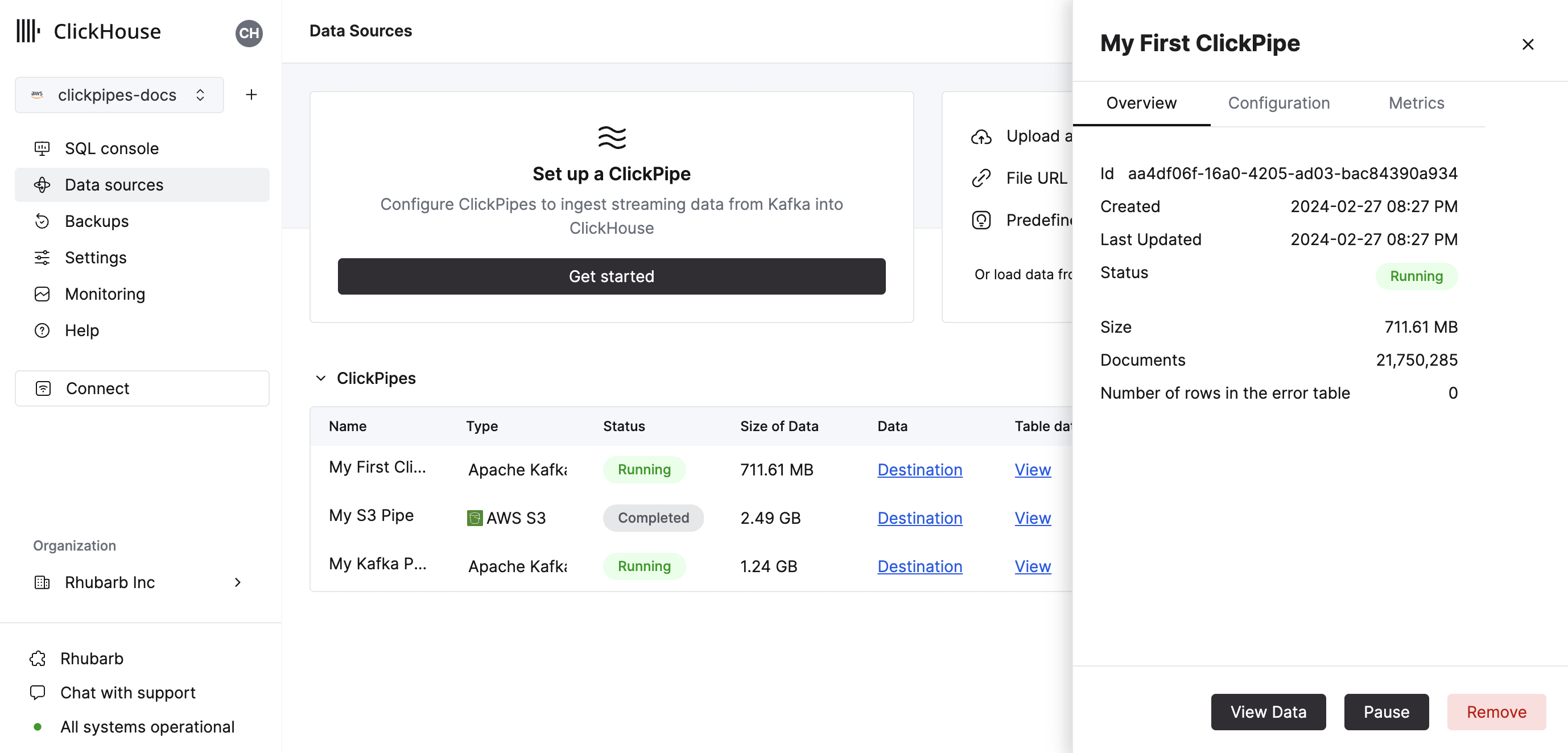
- 恭喜! 您已成功设置了您的第一个 ClickPipe。如果这是一个流式 ClickPipe,它将持续运行,从您的远程数据源实时摄取数据。否则,它将批量摄取并完成。
支持的数据源
| 名称 | 徽标 | 类型 | 状态 | 描述 |
|---|---|---|---|---|
| Amazon S3 | 对象存储 | Beta | 配置 ClickPipes 以从对象存储中摄取大量数据。 | |
| Google Cloud Storage | 对象存储 | Beta | 配置 ClickPipes 以从对象存储中摄取大量数据。 |
更多连接器将添加到 ClickPipes,您可以通过联系我们了解更多信息。
支持的数据格式
支持的格式有
精确一次语义
在摄取大型数据集时,可能会发生各种类型的故障,这可能会导致部分插入或重复数据。对象存储 ClickPipes 具有针对插入失败的弹性,并提供精确一次语义。这是通过使用临时“暂存”表来实现的。数据首先插入到暂存表中。如果此插入出现问题,则可以截断暂存表,并可以从干净状态重试插入。仅当插入完成并成功后,暂存表中的分区才会移动到目标表。要阅读有关此策略的更多信息,请查看此博客文章。
视图支持
也支持目标表上的物化视图。ClickPipes 不仅会为目标表创建暂存表,还会为任何依赖的物化视图创建暂存表。
我们不会为非物化视图创建暂存表。这意味着,如果您的目标表具有一个或多个下游物化视图,则这些物化视图应避免通过视图从目标表选择数据。否则,您可能会发现物化视图中缺少数据。
扩展
对象存储 ClickPipes 根据 配置的垂直自动缩放设置 确定的最小 ClickHouse 服务大小进行扩展。ClickPipe 的大小在创建管道时确定。随后对 ClickHouse 服务设置的更改不会影响 ClickPipe 的大小。
为了提高大型摄取作业的吞吐量,我们建议在创建 ClickPipe 之前扩展 ClickHouse 服务。
限制
- 对目标表、其物化视图(包括级联物化视图)或物化视图的目标表的任何更改都不会被管道自动拾取,并可能导致错误。您必须停止管道,进行必要的修改,然后重新启动管道,才能拾取更改,并避免因重试而导致的错误和重复数据。
- 对支持的视图类型存在限制。请阅读有关精确一次语义和视图支持的部分以获取更多信息。
- 角色身份验证不适用于部署到 GCP 或 Azure 的 ClickHouse Cloud 实例的 S3 ClickPipes。它仅适用于 AWS ClickHouse Cloud 实例。
- ClickPipes 将仅尝试摄取大小为 10GB 或更小的对象。如果文件大于 10GB,则错误将附加到 ClickPipes 专用错误表中。
- S3/GCS ClickPipes 不与 S3 表函数 共享列表语法。
?— 替换任何单个字符*— 替换任意数量的任何字符,除了 /,包括空字符串**— 替换任意数量的任何字符,包括 /,包括空字符串
连续摄取
ClickPipes 支持从 S3 和 GCS 进行连续摄取。启用后,ClickPipes 将持续从指定的路径摄取数据,它将每 30 秒轮询一次新文件。但是,新文件在词法上必须大于上次摄取的文件,这意味着它们的命名方式必须定义摄取顺序。例如,名为 file1、file2、file3 等的文件将按顺序摄取。如果添加了一个名为 file0 的新文件,ClickPipes 将不会摄取它,因为它在词法上不大于上次摄取的文件。
存档表
ClickPipes 将在您的目标表旁边创建一个表,后缀为 s3_clickpipe_<clickpipe_id>_archive。此表将包含 ClickPipe 已摄取的所有文件的列表。此表用于在摄取期间跟踪文件,并且可用于验证文件是否已被摄取。存档表的 TTL 为 7 天。
这些表将无法使用 ClickHouse Cloud SQL 控制台查看,您需要通过外部客户端使用 HTTPS 或 Native 连接来读取它们。
身份验证
S3
您可以访问公共存储桶而无需任何配置,对于受保护的存储桶,您可以使用 IAM 凭据 或 IAM 角色。您可以参考本指南,了解访问数据所需的权限。
GCS
与 S3 类似,您可以访问公共存储桶而无需任何配置,对于受保护的存储桶,您可以使用 HMAC 密钥 来代替 AWS IAM 凭据。您可以阅读 Google Cloud 的本指南,了解 如何设置此类密钥。
GCS 的服务帐户不受直接支持。使用非公共存储桶进行身份验证时,必须使用 HMAC (IAM) 凭据。附加到 HMAC 凭据的服务帐户权限应为 storage.objects.list 和 storage.objects.get。
F.A.Q.
- ClickPipes 是否支持以
gs://为前缀的 GCS 存储桶?
否。出于互操作性原因,我们要求您将 gs:// 存储桶前缀替换为 https://storage.googleapis.com/。
- GCS 公共存储桶需要哪些权限?
allUsers 需要适当的角色分配。必须在存储桶级别授予 roles/storage.objectViewer 角色。此角色提供 storage.objects.list 权限,该权限允许 ClickPipes 列出存储桶中的所有对象,这是载入和摄取所必需的。此角色还包括 storage.objects.get 权限,该权限是读取或下载存储桶中的单个对象所必需的。有关更多信息,请参阅:Google Cloud 访问控制。