Python 集成 ClickHouse Connect
简介
ClickHouse Connect 是一个核心数据库驱动程序,提供与各种 Python 应用程序的互操作性。
- 主要接口是包
clickhouse_connect.driver中的Client对象。该核心包还包括用于与 ClickHouse 服务器通信的各种辅助类和实用程序函数,以及用于高级管理插入和选择查询的“上下文”实现。 clickhouse_connect.datatypes包为所有非实验性的 ClickHouse 数据类型提供了基本实现和子类。其主要功能是将 ClickHouse 数据序列化和反序列化为 ClickHouse “原生”二进制列式格式,用于实现 ClickHouse 和客户端应用程序之间最高效的传输。clickhouse_connect.cdriver包中的 Cython/C 类优化了一些最常见的序列化和反序列化,与纯 Python 相比,性能显着提高。- 包
clickhouse_connect.cc_sqlalchemy中有一个有限的 SQLAlchemy 方言,它建立在datatypes和dbi包的基础上。这种受限制的实现侧重于查询/游标功能,并且通常不支持 SQLAlchemy DDL 和 ORM 操作。(SQLAlchemy 针对 OLTP 数据库,我们建议使用更专业的工具和框架来管理面向 ClickHouse OLAP 的数据库。) - 核心驱动程序和 ClickHouse Connect SQLAlchemy 实现是将 ClickHouse 连接到 Apache Superset 的首选方法。使用
ClickHouse Connect数据库连接,或clickhousedbSQLAlchemy 方言连接字符串。
本文档是截至 beta 版本 0.8.2 的最新文档。
官方 ClickHouse Connect Python 驱动程序使用 HTTP 协议与 ClickHouse 服务器通信。它有一些优点(如更好的灵活性、HTTP 负载均衡器支持、与基于 JDBC 的工具更好的兼容性等)和缺点(如稍低的压缩和性能,以及缺乏对基于原生 TCP 协议的某些复杂功能的支持)。对于某些用例,您可以考虑使用使用基于原生 TCP 协议的 社区 Python 驱动程序 之一。
要求和兼容性
| Python | 平台¹ | ClickHouse | SQLAlchemy² | Apache Superset | |||||
|---|---|---|---|---|---|---|---|---|---|
| 2.x, <3.8 | ❌ | Linux (x86) | ✅ | <24.3³ | 🟡 | <1.3 | ❌ | <1.4 | ❌ |
| 3.8.x | ✅ | Linux (Aarch64) | ✅ | 24.3.x | ✅ | 1.3.x | ✅ | 1.4.x | ✅ |
| 3.9.x | ✅ | macOS (x86) | ✅ | 24.4-24.6³ | 🟡 | 1.4.x | ✅ | 1.5.x | ✅ |
| 3.10.x | ✅ | macOS (ARM) | ✅ | 24.7.x | ✅ | >=2.x | ❌ | 2.0.x | ✅ |
| 3.11.x | ✅ | Windows | ✅ | 24.8.x | ✅ | 2.1.x | ✅ | ||
| 3.12.x | ✅ | 24.9.x | ✅ | 3.0.x | ✅ |
¹ClickHouse Connect 已经针对列出的平台进行了显式测试。此外,未经测试的二进制 wheels(带有 C 优化)是为优秀的 `cibuildwheel`` 项目支持的所有架构构建的。最后,由于 ClickHouse Connect 也可以作为纯 Python 运行,因此源代码安装应该可以在任何最新的 Python 安装上工作。
²同样,SQLAlchemy 支持主要限于查询功能。不支持完整的 SQLAlchemy API。
³ClickHouse Connect 已经针对当前所有受支持的 ClickHouse 版本进行了测试。因为它使用 HTTP 协议,所以它也应该适用于大多数其他版本的 ClickHouse,尽管某些高级数据类型可能存在一些不兼容性。
安装
通过 pip 从 PyPI 安装 ClickHouse Connect
pip install clickhouse-connect
ClickHouse Connect 也可以从源代码安装
git cloneGitHub 仓库。- (可选)运行
pip install cython以构建并启用 C/Cython 优化 cd到项目根目录并运行pip install .
支持策略
ClickHouse Connect 目前处于 beta 阶段,仅积极支持当前的 beta 版本。在报告任何问题之前,请更新到最新版本。问题应在 GitHub 项目 中提交。ClickHouse Connect 的未来版本保证与发布时积极支持的 ClickHouse 版本兼容(通常是最近的三个 stable 版本和最近的两个 lts 版本)。
基本用法
收集您的连接详细信息
要通过 HTTP(S) 连接到 ClickHouse,您需要以下信息
-
HOST 和 PORT:通常,当使用 TLS 时端口为 8443,当不使用 TLS 时端口为 8123。
-
数据库名称:开箱即用,有一个名为
default的数据库,使用您要连接的数据库的名称。 -
用户名和密码:开箱即用,用户名是
default。使用适合您用例的用户名。
您的 ClickHouse Cloud 服务的详细信息可在 ClickHouse Cloud 控制台中找到。选择您要连接的服务,然后单击 连接
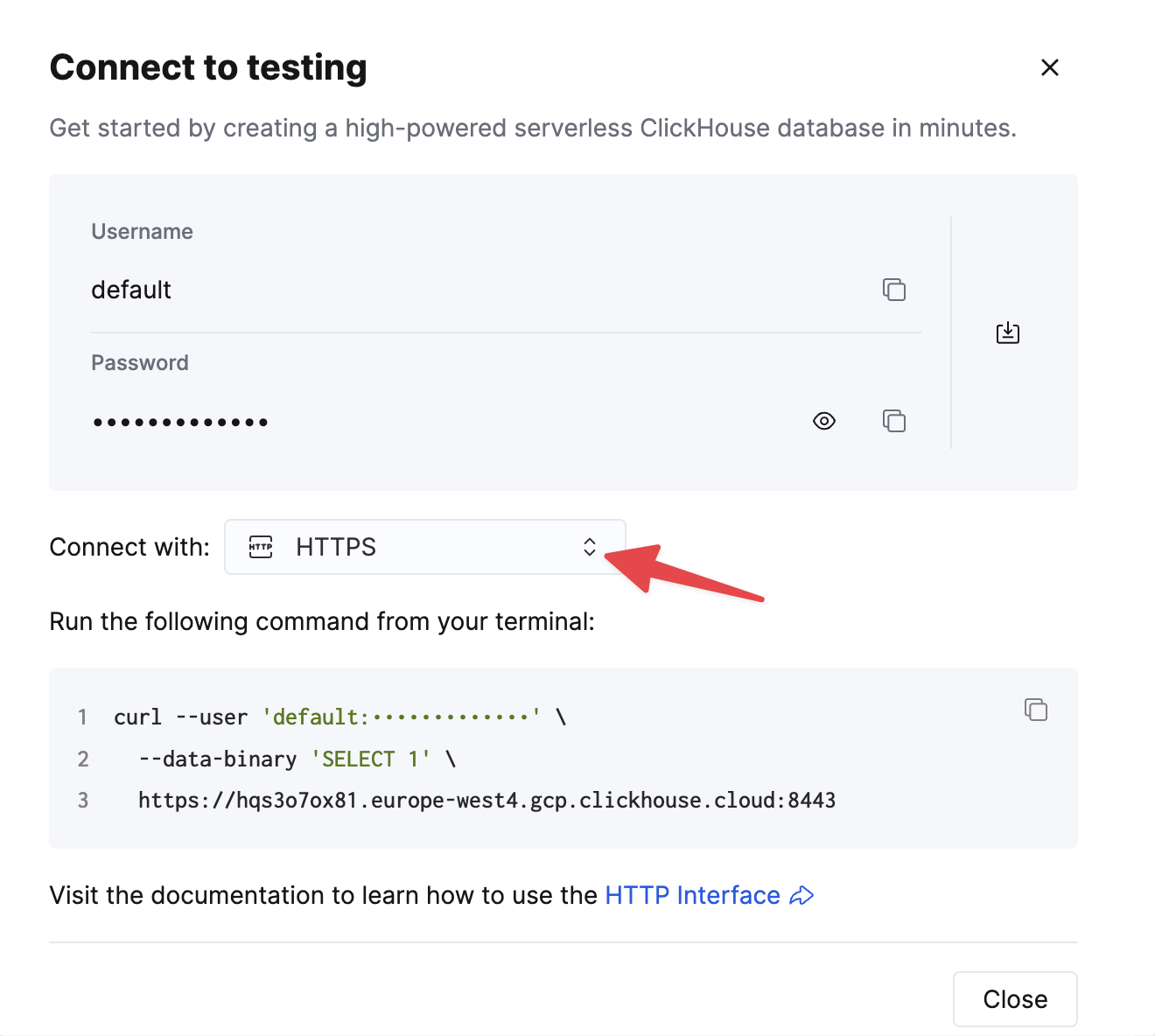
选择 HTTPS,详细信息可在示例 curl 命令中找到。
如果您使用的是自托管 ClickHouse,则连接详细信息由您的 ClickHouse 管理员设置。
建立连接
下面显示了连接到 ClickHouse 的两个示例
- 连接到 localhost 上的 ClickHouse 服务器。
- 连接到 ClickHouse Cloud 服务。
使用 ClickHouse Connect 客户端实例连接到 localhost 上的 ClickHouse 服务器:
import clickhouse_connect
client = clickhouse_connect.get_client(host='localhost', username='default', password='password')
使用 ClickHouse Connect 客户端实例连接到 ClickHouse Cloud 服务:
使用之前收集的连接详细信息。ClickHouse Cloud 服务需要 TLS,因此请使用端口 8443。
import clickhouse_connect
client = clickhouse_connect.get_client(host='HOSTNAME.clickhouse.cloud', port=8443, username='default', password='your password')
与您的数据库交互
要运行 ClickHouse SQL 命令,请使用客户端 command 方法
client.command('CREATE TABLE new_table (key UInt32, value String, metric Float64) ENGINE MergeTree ORDER BY key')
要插入批量数据,请使用客户端 insert 方法,并使用行和值的二维数组
row1 = [1000, 'String Value 1000', 5.233]
row2 = [2000, 'String Value 2000', -107.04]
data = [row1, row2]
client.insert('new_table', data, column_names=['key', 'value', 'metric'])
要使用 ClickHouse SQL 检索数据,请使用客户端 query 方法
result = client.query('SELECT max(key), avg(metric) FROM new_table')
result.result_rows
Out[13]: [(2000, -50.9035)]
ClickHouse Connect 驱动程序 API
注意: 鉴于可能的参数数量(其中大多数是可选的),建议为大多数 api 方法传递关键字参数。
此处未记录的方法不被视为 API 的一部分,可能会被删除或更改。
客户端初始化
clickhouse_connect.driver.client 类提供 Python 应用程序和 ClickHouse 数据库服务器之间的主要接口。使用 clickhouse_connect.get_client 函数获取 Client 实例,该实例接受以下参数
连接参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| interface | str | http | 必须是 http 或 https。 |
| host | str | localhost | ClickHouse 服务器的主机名或 IP 地址。如果未设置,将使用 localhost。 |
| port | int | 8123 或 8443 | ClickHouse HTTP 或 HTTPS 端口。如果未设置,则默认为 8123,或者如果 secure=True 或 interface=https,则默认为 8443。 |
| username | str | default | ClickHouse 用户名。如果未设置,将使用 default ClickHouse 用户。 |
| password | str | <空字符串> | username 的密码。 |
| database | str | None | 连接的默认数据库。如果未设置,ClickHouse Connect 将使用 username 的默认数据库。 |
| secure | bool | False | 使用 https/TLS。这将覆盖从 interface 或 port 参数推断的值。 |
| dsn | str | None | 标准 DSN(数据源名称)格式的字符串。其他连接值(例如 host 或 user)将从此字符串中提取,除非另行设置。 |
| compress | bool 或 str | True | 为 ClickHouse HTTP 插入和查询结果启用压缩。请参阅 附加选项(压缩) |
| query_limit | int | 0(无限制) | 任何 query 响应返回的最大行数。将其设置为零以返回无限行。请注意,如果结果未流式传输,则大型查询限制可能会导致内存不足异常,因为所有结果都会一次性加载到内存中。 |
| query_retries | int | 2 | query 请求的最大重试次数。仅“可重试”的 HTTP 响应将被重试。驱动程序不会自动重试 command 或 insert 请求,以防止意外的重复请求。 |
| connect_timeout | int | 10 | HTTP 连接超时时间(秒)。 |
| send_receive_timeout | int | 300 | HTTP 连接的发送/接收超时时间(秒)。 |
| client_name | str | None | 预先添加到 HTTP User Agent 标头的 client_name。设置此项以跟踪 ClickHouse system.query_log 中的客户端查询。 |
| pool_mgr | obj | <默认 PoolManager> | 要使用的 urllib3 库 PoolManager。对于需要连接到不同主机的多个连接池的高级用例。 |
| http_proxy | str | None | HTTP 代理地址(等效于设置 HTTP_PROXY 环境变量)。 |
| https_proxy | str | None | HTTPS 代理地址(等效于设置 HTTPS_PROXY 环境变量)。 |
| apply_server_timezone | bool | True | 对时区感知查询结果使用服务器时区。请参阅 时区优先级 |
HTTPS/TLS 参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| verify | bool | True | 如果使用 HTTPS/TLS,则验证 ClickHouse 服务器 TLS/SSL 证书(主机名、过期时间等)。 |
| ca_cert | str | None | 如果 verify=True,则为证书颁发机构根目录的文件路径,用于验证 ClickHouse 服务器证书,格式为 .pem。如果 verify 为 False,则忽略。如果 ClickHouse 服务器证书是由操作系统验证的全局信任根证书,则不需要此项。 |
| client_cert | str | None | .pem 格式的 TLS 客户端证书的文件路径(用于相互 TLS 身份验证)。该文件应包含完整的证书链,包括任何中间证书。 |
| client_cert_key | str | None | 客户端证书的私钥的文件路径。如果私钥未包含在客户端证书密钥文件中,则为必填项。 |
| server_host_name | str | None | ClickHouse 服务器主机名,由其 TLS 证书的 CN 或 SNI 标识。设置此项以避免通过主机名不同的代理或隧道连接时出现 SSL 错误 |
| tls_mode | str | None | 控制高级 TLS 行为。proxy 和 strict 不调用 ClickHouse 相互 TLS 连接,但会发送客户端证书和密钥。mutual 假定 ClickHouse 相互 TLS 身份验证使用客户端证书。None/默认行为是 mutual |
设置参数
最后,get_client 的 settings 参数用于为每个客户端请求将其他 ClickHouse 设置传递到服务器。请注意,在大多数情况下,具有 readonly=1 访问权限的用户无法更改随查询发送的设置,因此 ClickHouse Connect 将在最终请求中删除此类设置并记录警告。以下设置仅适用于 ClickHouse Connect 使用的 HTTP 查询/会话,并且未作为常规 ClickHouse 设置记录。
| 设置 | 描述 |
|---|---|
| buffer_size | ClickHouse 服务器在写入 HTTP 通道之前使用的缓冲区大小(以字节为单位)。 |
| session_id | 用于关联服务器上相关查询的唯一会话 ID。临时表是必需的。 |
| compress | ClickHouse 服务器是否应压缩 POST 响应数据。此设置仅应用于“原始”查询。 |
| decompress | 是否必须解压缩发送到 ClickHouse 服务器的数据。此设置应仅用于“原始”插入。 |
| quota_key | 与此请求关联的配额密钥。请参阅 ClickHouse 服务器文档中的配额。 |
| session_check | 用于检查会话状态。 |
| session_timeout | 会话 ID 标识的会话超时且不再被视为有效之前的非活动秒数。默认为 60 秒。 |
| wait_end_of_query | 在 ClickHouse 服务器上缓冲整个响应。此设置是返回摘要信息所必需的,并且在非流式查询上自动设置。 |
有关可以随每个查询发送的其他 ClickHouse 设置,请参阅 ClickHouse 文档。
客户端创建示例
- 在没有任何参数的情况下,ClickHouse Connect 客户端将使用默认用户且没有密码连接到
localhost上的默认 HTTP 端口
import clickhouse_connect
client = clickhouse_connect.get_client()
client.server_version
Out[2]: '22.10.1.98'
- 连接到安全的 (https) 外部 ClickHouse 服务器
import clickhouse_connect
client = clickhouse_connect.get_client(host='play.clickhouse.com', secure=True, port=443, user='play', password='clickhouse')
client.command('SELECT timezone()')
Out[2]: 'Etc/UTC'
- 使用会话 ID 和其他自定义连接参数以及 ClickHouse 设置进行连接。
import clickhouse_connect
client = clickhouse_connect.get_client(host='play.clickhouse.com',
user='play',
password='clickhouse',
port=443,
session_id='example_session_1',
connect_timeout=15,
database='github',
settings={'distributed_ddl_task_timeout':300})
client.database
Out[2]: 'github'
常用方法参数
多个客户端方法使用一个或两个常用 parameters 和 settings 参数。以下描述了这些关键字参数。
Parameters 参数
ClickHouse Connect Client query* 和 command 方法接受可选的 parameters 关键字参数,用于将 Python 表达式绑定到 ClickHouse 值表达式。有两种绑定方式可用。
服务器端绑定
ClickHouse 支持大多数查询值的服务器端绑定,其中绑定值与查询分开作为 HTTP 查询参数发送。如果 ClickHouse Connect 检测到 {<name>:<datatype>} 形式的绑定表达式,它将添加相应的查询参数。对于服务器端绑定,parameters 参数应为 Python 字典。
- 使用 Python 字典、DateTime 值和字符串值的服务器端绑定
import datetime
my_date = datetime.datetime(2022, 10, 1, 15, 20, 5)
parameters = {'table': 'my_table', 'v1': my_date, 'v2': "a string with a single quote'"}
client.query('SELECT * FROM {table:Identifier} WHERE date >= {v1:DateTime} AND string ILIKE {v2:String}', parameters=parameters)
# Generates the following query on the server
# SELECT * FROM my_table WHERE date >= '2022-10-01 15:20:05' AND string ILIKE 'a string with a single quote\''
重要提示 -- (ClickHouse 服务器)仅对 SELECT 查询支持服务器端绑定。它不适用于 ALTER、DELETE、INSERT 或其他类型的查询。将来可能会更改,请参阅 https://github.com/ClickHouse/ClickHouse/issues/42092。
客户端绑定
ClickHouse Connect 还支持客户端参数绑定,这可以在生成模板化 SQL 查询时提供更大的灵活性。对于客户端绑定,parameters 参数应为字典或序列。客户端绑定使用 Python “printf”样式字符串格式进行参数替换。
请注意,与服务器端绑定不同,客户端绑定不适用于数据库标识符,例如数据库、表或列名称,因为 Python 样式格式无法区分不同类型的字符串,并且它们需要以不同的方式格式化(数据库标识符使用反引号或双引号,数据值使用单引号)。
- 使用 Python 字典、DateTime 值和字符串转义的示例
import datetime
my_date = datetime.datetime(2022, 10, 1, 15, 20, 5)
parameters = {'v1': my_date, 'v2': "a string with a single quote'"}
client.query('SELECT * FROM some_table WHERE date >= %(v1)s AND string ILIKE %(v2)s', parameters=parameters)
# Generates the following query:
# SELECT * FROM some_table WHERE date >= '2022-10-01 15:20:05' AND string ILIKE 'a string with a single quote\''
- 使用 Python 序列(元组)、Float64 和 IPv4Address 的示例
import ipaddress
parameters = (35200.44, ipaddress.IPv4Address(0x443d04fe))
client.query('SELECT * FROM some_table WHERE metric >= %s AND ip_address = %s', parameters=parameters)
# Generates the following query:
# SELECT * FROM some_table WHERE metric >= 35200.44 AND ip_address = '68.61.4.254''
要绑定 DateTime64 参数(具有亚秒级精度的 ClickHouse 类型),需要以下两种自定义方法之一
- 将 Python
datetime.datetime值包装在新的 DT64Param 类中,例如query = 'SELECT {p1:DateTime64(3)}' # Server side binding with dictionary
parameters={'p1': DT64Param(dt_value)}
query = 'SELECT %s as string, toDateTime64(%s,6) as dateTime' # Client side binding with list
parameters=['a string', DT64Param(datetime.now())]- 如果使用参数值字典,请将字符串
_64附加到参数名称
query = 'SELECT {p1:DateTime64(3)}, {a1:Array(DateTime(3))}' # Server side binding with dictionary
parameters={'p1_64': dt_value, 'a1_64': [dt_value1, dt_value2]} - 如果使用参数值字典,请将字符串
Settings 参数
所有关键的 ClickHouse Connect Client “insert”和“select”方法都接受可选的 settings 关键字参数,以传递 ClickHouse 服务器 用户设置 用于包含的 SQL 语句。settings 参数应为字典。每个项目都应是 ClickHouse 设置名称及其关联的值。请注意,值在作为查询参数发送到服务器时将转换为字符串。
与客户端级别设置一样,ClickHouse Connect 将删除服务器标记为 readonly=1 的任何设置,并显示关联的日志消息。仅适用于通过 ClickHouse HTTP 接口的查询的设置始终有效。这些设置在 get_client API 下进行了描述。
使用 ClickHouse 设置的示例
settings = {'merge_tree_min_rows_for_concurrent_read': 65535,
'session_id': 'session_1234',
'use_skip_indexes': False}
client.query("SELECT event_type, sum(timeout) FROM event_errors WHERE event_time > '2022-08-01'", settings=settings)
客户端 command 方法
使用 Client.command 方法将 SQL 查询发送到 ClickHouse 服务器,这些查询通常不返回数据,或者返回单个原始值或数组值,而不是完整的数据集。此方法采用以下参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| cmd | str | 必需 | 返回单个值或单行值的 ClickHouse SQL 语句。 |
| parameters | dict 或 iterable | None | 请参阅 parameters 描述。 |
| data | str 或 bytes | None | 要包含在命令中作为 POST 正文的可选数据。 |
| settings | dict | None | 请参阅 settings 描述。 |
| use_database | bool | True | 使用客户端数据库(创建客户端时指定)。False 表示该命令将使用连接用户的默认 ClickHouse 服务器数据库。 |
| external_data | ExternalData | None | 一个 ExternalData 对象,其中包含要与查询一起使用的文件或二进制数据。请参阅 高级查询(外部数据) |
- command 可用于 DDL 语句。如果 SQL “command” 不返回数据,则返回“查询摘要”字典。此字典封装了 ClickHouse X-ClickHouse-Summary 和 X-ClickHouse-Query-Id 标头,包括键/值对
written_rows、written_bytes和query_id。
client.command('CREATE TABLE test_command (col_1 String, col_2 DateTime) Engine MergeTree ORDER BY tuple()')
client.command('SHOW CREATE TABLE test_command')
Out[6]: 'CREATE TABLE default.test_command\\n(\\n `col_1` String,\\n `col_2` DateTime\\n)\\nENGINE = MergeTree\\nORDER BY tuple()\\nSETTINGS index_granularity = 8192'
- command 也可用于仅返回单行的简单查询
result = client.command('SELECT count() FROM system.tables')
result
Out[7]: 110
客户端 query 方法
Client.query 方法是从 ClickHouse 服务器检索单个“批处理”数据集的主要方法。它利用 HTTP 上的原生 ClickHouse 格式来高效传输大型数据集(最多约一百万行)。此方法采用以下参数。
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| query | str | 必需 | ClickHouse SQL SELECT 或 DESCRIBE 查询。 |
| parameters | dict 或 iterable | None | 请参阅 parameters 描述。 |
| settings | dict | None | 请参阅 settings 描述。 |
| query_formats | dict | None | 结果值的数据类型格式规范。请参阅高级用法(读取格式) |
| column_formats | dict | None | 每个列的数据类型格式。请参阅高级用法(读取格式) |
| encoding | str | None | 用于将 ClickHouse String 列编码为 Python 字符串的编码。如果未设置,Python 默认为 UTF-8。 |
| use_none | bool | True | 对 ClickHouse null 使用 Python None 类型。如果为 False,则对 ClickHouse null 使用数据类型默认值(例如 0)。注意 - 出于性能原因,NumPy/Pandas 默认为 False。 |
| column_oriented | bool | False | 将结果作为列序列而不是行序列返回。有助于将 Python 数据转换为其他面向列的数据格式。 |
| query_tz | str | None | 来自 zoneinfo 数据库的时区名称。此时区将应用于查询返回的所有 datetime 或 Pandas Timestamp 对象。 |
| column_tzs | dict | None | 列名称到时区名称的字典。与 query_tz 类似,但允许为不同的列指定不同的时区。 |
| use_extended_dtypes | bool | True | 使用 Pandas 扩展 dtypes(如 StringArray)以及 pandas.NA 和 pandas.NaT 表示 ClickHouse NULL 值。仅适用于 query_df 和 query_df_stream 方法。 |
| external_data | ExternalData | None | 一个 ExternalData 对象,其中包含要与查询一起使用的文件或二进制数据。请参阅 高级查询(外部数据) |
| context | QueryContext | None | 可重用的 QueryContext 对象可用于封装上述方法参数。请参阅 高级查询 (QueryContexts) |
QueryResult 对象
基本的 query 方法返回一个 QueryResult 对象,其中包含以下公共属性
result_rows-- 以行序列形式返回的数据矩阵,其中每个行元素都是一个列值序列。result_columns-- 以列序列形式返回的数据矩阵,其中每个列元素都是该列的行值序列column_names-- 表示result_set中列名称的字符串元组column_types-- 表示result_columns中每列的 ClickHouse 数据类型的 ClickHouseType 实例元组query_id-- ClickHouse query_id(用于在system.query_log表中检查查询)summary--X-ClickHouse-SummaryHTTP 响应标头返回的任何数据first_item-- 用于将响应的第一行作为字典(键是列名称)检索的便捷属性first_row-- 用于返回结果第一行的便捷属性column_block_stream-- 列式格式的查询结果生成器。不应直接引用此属性(请参见下文)。row_block_stream-- 行式格式的查询结果生成器。不应直接引用此属性(请参见下文)。rows_stream-- 查询结果生成器,每次调用生成一行。不应直接引用此属性(请参见下文)。summary-- 如command方法下所述,ClickHouse 返回的摘要信息字典
*_stream 属性返回一个 Python 上下文,可用作返回数据的迭代器。它们应仅使用 Client *_stream 方法间接访问。
流式查询结果(使用 StreamContext 对象)的完整详细信息在 高级查询(流式查询) 中概述。
使用 NumPy、Pandas 或 Arrow 使用查询结果
主 query 方法有三个专用版本
query_np-- 此版本返回 NumPy 数组而不是 ClickHouse Connect QueryResult。query_df-- 此版本返回 Pandas Dataframe 而不是 ClickHouse Connect QueryResult。query_arrow-- 此版本返回 PyArrow Table。它直接使用 ClickHouseArrow格式,因此它仅接受与主query method相同的三个参数:query、parameters和settings。此外,还有一个额外的参数use_strings,它确定 Arrow Table 是否会将 ClickHouse String 类型呈现为字符串(如果为 True)或字节(如果为 False)。
客户端流式查询方法
ClickHouse Connect Client 提供了多种方法来检索作为流(实现为 Python 生成器)的数据
query_column_block_stream-- 使用本机 Python 对象以块的形式返回作为列序列的查询数据query_row_block_stream-- 使用本机 Python 对象以块的形式返回作为行块的查询数据query_rows_stream-- 使用本机 Python 对象以序列行的形式返回查询数据query_np_stream-- 将每个 ClickHouse 查询数据块作为 NumPy 数组返回query_df_stream-- 将每个 ClickHouse 数据块作为 Pandas Dataframe 返回query_arrow_stream-- 以 PyArrow RecordBlocks 形式返回查询数据
这些方法中的每一种都返回一个 ContextStream 对象,该对象必须通过 with 语句打开才能开始使用流。有关详细信息和示例,请参阅 高级查询(流式查询)。
客户端 insert 方法
对于将多个记录插入 ClickHouse 的常见用例,有 Client.insert 方法。它接受以下参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| table | str | 必需 | 要插入的 ClickHouse 表。允许使用完整的表名(包括数据库)。 |
| data | 序列的序列 | 必需 | 要插入的数据矩阵,可以是行序列(每个行序列都是列值序列),也可以是列序列(每个列序列都是行值序列)。 |
| column_names | str 或 str 序列 | '*' | 数据矩阵的 column_names 列表。如果使用“*”代替,ClickHouse Connect 将执行“预查询”以检索表的所有列名称。 |
| database | str | '' | 插入的目标数据库。如果未指定,将假定为客户端的数据库。 |
| column_types | ClickHouseType 序列 | None | ClickHouseType 实例列表。如果未指定 column_types 或 column_type_names,ClickHouse Connect 将执行“预查询”以检索表的所有列类型。 |
| column_type_names | ClickHouse 类型名称序列 | None | ClickHouse 数据类型名称列表。如果未指定 column_types 或 column_type_names,ClickHouse Connect 将执行“预查询”以检索表的所有列类型。 |
| column_oriented | bool | False | 如果为 True,则假定 data 参数是列序列(并且不需要“透视”来插入数据)。否则,data 被解释为行序列。 |
| settings | dict | None | 请参阅 settings 描述。 |
| insert_context | InsertContext | None | 可重用的 InsertContext 对象可用于封装上述方法参数。请参阅 高级插入 (InsertContexts) |
此方法返回一个“查询摘要”字典,如“command”方法下所述。如果插入因任何原因失败,将引发异常。
主 insert 方法有两个专用版本
insert_df-- 此方法的第二个参数不是 Python 序列的序列data参数,而是需要一个df参数,该参数必须是 Pandas Dataframe 实例。ClickHouse Connect 自动将 Dataframe 处理为面向列的数据源,因此不需要或不提供column_oriented参数。insert_arrow-- 此方法不是 Python 序列的序列data参数,而是需要一个arrow_table。ClickHouse Connect 将 Arrow 表未经修改地传递到 ClickHouse 服务器进行处理,因此除了table和arrow_table之外,只有database和settings参数可用。
注意: NumPy 数组是有效的序列的序列,可以用作主 insert 方法的 data 参数,因此不需要专用方法。
文件插入
clickhouse_connect.driver.tools 包括 insert_file 方法,该方法允许直接从文件系统将数据插入到现有的 ClickHouse 表中。解析委托给 ClickHouse 服务器。insert_file 接受以下参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| client | Client | 必需 | 用于执行插入的 driver.Client |
| table | str | 必需 | 要插入的 ClickHouse 表。允许使用完整的表名(包括数据库)。 |
| file_path | str | 必需 | 数据文件的本机文件系统路径 |
| fmt | str | CSV, CSVWithNames | 文件的 ClickHouse 输入格式。如果未提供 column_names,则假定为 CSVWithNames |
| column_names | str 序列 | None | 数据文件中的 column_names 列表。对于包含列名称的格式,不是必需的 |
| database | str | None | 表的数据库。如果表是完全限定的,则忽略。如果未指定,插入将使用客户端数据库 |
| settings | dict | None | 请参阅 settings 描述。 |
| compression | str | None | 用于 Content-Encoding HTTP 标头的已识别 ClickHouse 压缩类型(zstd、lz4、gzip) |
对于数据不一致或日期/时间值格式不寻常的文件,此方法可识别适用于数据导入的设置(例如 input_format_allow_errors_num 和 input_format_allow_errors_num)。
import clickhouse_connect
from clickhouse_connect.driver.tools import insert_file
client = clickhouse_connect.get_client()
insert_file(client, 'example_table', 'my_data.csv',
settings={'input_format_allow_errors_ratio': .2,
'input_format_allow_errors_num': 5})
将查询结果另存为文件
您可以使用 raw_stream 方法直接从 ClickHouse 将文件流式传输到本地文件系统。例如,如果您想将查询结果保存到 CSV 文件,可以使用以下代码片段
import clickhouse_connect
if __name__ == '__main__':
client = clickhouse_connect.get_client()
query = 'SELECT number, toString(number) AS number_as_str FROM system.numbers LIMIT 5'
fmt = 'CSVWithNames' # or CSV, or CSVWithNamesAndTypes, or TabSeparated, etc.
stream = client.raw_stream(query=query, fmt=fmt)
with open("output.csv", "wb") as f:
for chunk in stream:
f.write(chunk)
上面的代码生成一个 output.csv 文件,其内容如下
"number","number_as_str"
0,"0"
1,"1"
2,"2"
3,"3"
4,"4"
同样,您可以以 TabSeparated 和其他格式保存数据。有关所有可用格式选项的概述,请参阅 输入和输出数据格式。
原始 API
对于不需要在 ClickHouse 数据与本机或第三方数据类型和结构之间进行转换的用例,ClickHouse Connect 客户端提供了两种直接使用 ClickHouse 连接的方法。
客户端 raw_query 方法
Client.raw_query 方法允许使用客户端连接直接使用 ClickHouse HTTP 查询接口。返回值是未处理的 bytes 对象。它提供了一个方便的包装器,使用最小的接口进行参数绑定、错误处理、重试和设置管理
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| query | str | 必需 | 任何有效的 ClickHouse 查询 |
| parameters | dict 或 iterable | None | 请参阅 parameters 描述。 |
| settings | dict | None | 请参阅 settings 描述。 |
| fmt | str | None | 结果字节的 ClickHouse 输出格式。(如果未指定,ClickHouse 使用 TSV) |
| use_database | bool | True | 对查询上下文使用 clickhouse-connect Client 分配的数据库 |
| external_data | ExternalData | None | 一个 ExternalData 对象,其中包含要与查询一起使用的文件或二进制数据。请参阅 高级查询(外部数据) |
调用者有责任处理生成的 bytes 对象。请注意,Client.query_arrow 只是围绕此方法的一个薄包装器,它使用了 ClickHouse Arrow 输出格式。
客户端 raw_stream 方法
Client.raw_stream 方法具有与 raw_query 方法相同的 API,但返回一个 io.IOBase 对象,该对象可用作 bytes 对象的生成器/流源。它当前由 query_arrow_stream 方法使用。
客户端 raw_insert 方法
Client.raw_insert 方法允许使用客户端连接直接插入 bytes 对象或 bytes 对象生成器。因为它不处理插入有效负载,所以性能非常高。该方法提供了指定设置和插入格式的选项
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| table | str | 必需 | 简单表名或数据库限定表名 |
| column_names | Sequence[str] | None | 插入块的列名称。如果 fmt 参数不包含名称,则为必需项 |
| insert_block | str、bytes、Generator[bytes]、BinaryIO | 必需 | 要插入的数据。字符串将使用客户端编码进行编码。 |
| settings | dict | None | 请参阅 settings 描述。 |
| fmt | str | None | insert_block 字节的 ClickHouse 输入格式。(如果未指定,ClickHouse 使用 TSV) |
调用者有责任确保 insert_block 采用指定的格式并使用指定的压缩方法。ClickHouse Connect 将这些原始插入用于文件上传和 PyArrow Tables,并将解析委托给 ClickHouse 服务器。
实用程序类和函数
以下类和函数也被视为“公共” clickhouse-connect API 的一部分,并且与上面记录的类和方法一样,在次要版本之间保持稳定。对这些类和函数的重大更改只会发生在次要(而不是补丁)版本中,并且将在至少一个次要版本中以已弃用状态提供。
异常
所有自定义异常(包括 DB API 2.0 规范中定义的异常)都在 clickhouse_connect.driver.exceptions 模块中定义。驱动程序实际检测到的异常将使用这些类型之一。
Clickhouse SQL 实用程序
clickhouse_connect.driver.binding 模块中的函数和 DT64Param 类可用于正确构建和转义 ClickHouse SQL 查询。同样,clickhouse_connect.driver.parser 模块中的函数可用于解析 ClickHouse 数据类型名称。
多线程、多进程和异步/事件驱动的用例
ClickHouse Connect 在多线程、多进程和事件循环驱动/异步应用程序中运行良好。所有查询和插入处理都在单个线程中进行,因此操作通常是线程安全的。(在较低级别并行处理某些操作可能是未来的增强功能,以克服单线程的性能损失,但即使在这种情况下,也将保持线程安全)。
由于每个执行查询或插入都会在其自己的 QueryContext 或 InsertContext 对象中维护状态,因此这些辅助对象不是线程安全的,不应在多个处理流之间共享。请参阅以下各节中有关上下文对象的其他讨论。
此外,在同时具有两个或多个“正在进行中”的查询和/或插入的应用程序中,还需要牢记另外两个注意事项。第一个是与查询/插入关联的 ClickHouse “会话”,第二个是 ClickHouse Connect Client 实例使用的 HTTP 连接池。
AsyncClient 包装器
自 0.7.16 起,ClickHouse Connect 在常规 Client 上提供了一个异步包装器,以便可以在 asyncio 环境中使用客户端。
要获取 AsyncClient 的实例,可以使用 get_async_client 工厂函数,该函数接受与标准 get_client 相同的参数
import asyncio
import clickhouse_connect
async def main():
client = await clickhouse_connect.get_async_client()
result = await client.query("SELECT name FROM system.databases LIMIT 1")
print(result.result_rows)
asyncio.run(main())
AsyncClient 具有与标准 Client 相同的方法,但参数也相同,但它们在适用时是协程。在内部,Client 中执行 I/O 操作的这些方法包装在 run_in_executor 调用中。
当使用 AsyncClient 包装器时,多线程性能将会提高,因为在等待 I/O 操作完成时,执行线程和 GIL 将被释放。
注意:与常规 Client 不同,AsyncClient 默认情况下强制 autogenerate_session_id 为 False。
另请参阅:run_async 示例。
管理 ClickHouse 会话 ID
每个 ClickHouse 查询都发生在 ClickHouse “会话”的上下文中。会话当前用于两个目的
默认情况下,使用 ClickHouse Connect Client 实例执行的每个查询都使用相同的会话 ID,以启用此会话功能。也就是说,当使用单个 ClickHouse 客户端时,SET 语句和临时表按预期工作。但是,按照设计,ClickHouse 服务器不允许在同一会话中并发查询。因此,对于将执行并发查询的 ClickHouse Connect 应用程序,有两种选择。
- 为每个执行线程(线程、进程或事件处理程序)创建一个单独的
Client实例,该实例将具有自己的会话 ID。这通常是最佳方法,因为它为每个客户端保留了会话状态。 - 为每个查询使用唯一的会话 ID。这避免了在不需要临时表或共享会话设置的情况下出现并发会话问题。(共享设置也可以在创建客户端时提供,但这些设置随每个请求一起发送,并且不与会话关联)。可以将唯一的 session_id 添加到每个请求的
settings字典中,或者您可以禁用autogenerate_session_id通用设置
from clickhouse_connect import common
common.set_setting('autogenerate_session_id', False) # This should always be set before creating a client
client = clickhouse_connect.get_client(host='somehost.com', user='dbuser', password=1234)
在这种情况下,ClickHouse Connect 将不发送任何会话 ID,并且 ClickHouse 服务器将生成一个随机会话 ID。同样,临时表和会话级别设置将不可用。
自定义 HTTP 连接池
ClickHouse Connect 使用 urllib3 连接池来处理与服务器的底层 HTTP 连接。默认情况下,所有客户端实例共享同一个连接池,这对于大多数用例来说都足够了。此默认池为应用程序使用的每个 ClickHouse 服务器维护最多 8 个 HTTP Keep Alive 连接。
对于大型多线程应用程序,单独的连接池可能更合适。自定义连接池可以作为 pool_mgr 关键字参数提供给主 clickhouse_connect.get_client 函数
import clickhouse_connect
from clickhouse_connect.driver import httputil
big_pool_mgr = httputil.get_pool_manager(maxsize=16, num_pools=12)
client1 = clickhouse_connect.get_client(pool_mgr=big_pool_mgr)
client2 = clickhouse_connect.get_client(pool_mgr=big_pool_mgr)
如上面的示例所示,客户端可以共享一个池管理器,也可以为每个客户端创建一个单独的池管理器。有关创建 PoolManager 时可用的选项的更多详细信息,请参阅 urllib3 文档。
使用 ClickHouse Connect 查询数据:高级用法
QueryContexts
ClickHouse Connect 在 QueryContext 中执行标准查询。QueryContext 包含用于构建针对 ClickHouse 数据库的查询的关键结构,以及用于将结果处理为 QueryResult 或其他响应数据结构的配置。这包括查询本身、参数、设置、读取格式和其他属性。
可以使用客户端 create_query_context 方法获取 QueryContext。此方法采用与核心查询方法相同的参数。然后,可以将此查询上下文作为 context 关键字参数传递给 query、query_df 或 query_np 方法,而不是这些方法的任何或所有其他参数。请注意,为方法调用指定的其他参数将覆盖 QueryContext 的任何属性。
QueryContext 最清晰的用例是使用不同的绑定参数值发送相同的查询。可以通过调用 QueryContext.set_parameters 方法并使用字典来更新所有参数值,或者可以通过调用 QueryContext.set_parameter 并使用所需的 key、value 对来更新任何单个值。
client.create_query_context(query='SELECT value1, value2 FROM data_table WHERE key = {k:Int32}',
parameters={'k': 2},
column_oriented=True)
result = client.query(context=qc)
assert result.result_set[1][0] == 'second_value2'
qc.set_parameter('k', 1)
result = test_client.query(context=qc)
assert result.result_set[1][0] == 'first_value2'
请注意,QueryContexts 不是线程安全的,但可以通过调用 QueryContext.updated_copy 方法在多线程环境中获取副本。
流式查询
数据块
ClickHouse Connect 处理来自主 query 方法的所有数据,作为从 ClickHouse 服务器接收的块流。这些块以自定义“Native”格式传输到 ClickHouse 和从 ClickHouse 传输。 “块”只是二进制数据的列序列,其中每列包含指定数据类型的相等数量的数据值。(作为列式数据库,ClickHouse 以类似的形式存储此数据。)从查询返回的块的大小受两个用户设置控制,这两个用户设置可以在多个级别(用户配置文件、用户、会话或查询)设置。它们是
- max_block_size -- 块大小(以行数为单位)的限制。默认为 65536。
- preferred_block_size_bytes -- 块大小(以字节为单位)的软限制。默认为 1,000,0000。
无论 preferred_block_size_setting 如何,每个块的行数永远不会超过 max_block_size 行。根据查询的类型,返回的实际块可以是任何大小。例如,对覆盖多个分片的分布式表的查询可能包含直接从每个分片检索的较小块。
当使用 Client query_*_stream 方法之一时,结果会按块返回。ClickHouse Connect 一次只加载一个块。这允许处理大量数据,而无需将所有大型结果集加载到内存中。请注意,应用程序应准备好处理任意数量的块,并且无法控制每个块的确切大小。
用于缓慢处理的 HTTP 数据缓冲区
由于 HTTP 协议的限制,如果块的处理速度明显慢于 ClickHouse 服务器流式传输数据的速度,则 ClickHouse 服务器将关闭连接,从而导致在处理线程中引发异常。可以通过增加 HTTP 流式传输缓冲区(默认为 10 兆字节)的缓冲区大小来缓解这种情况,方法是使用通用 http_buffer_size 设置。如果应用程序有足够的可用内存,则较大的 http_buffer_size 值在这种情况下应该没问题。如果使用 lz4 或 zstd 压缩,则缓冲区中的数据将被压缩,因此使用这些压缩类型将增加可用的总缓冲区。
StreamContexts
每个 query_*_stream 方法(如 query_row_block_stream)都返回一个 ClickHouse StreamContext 对象,这是一个组合的 Python 上下文/生成器。这是基本用法
with client.query_row_block_stream('SELECT pickup, dropoff, pickup_longitude, pickup_latitude FROM taxi_trips') as stream:
for block in stream:
for row in block:
<do something with each row of Python trip data>
请注意,尝试在没有 with 语句的情况下使用 StreamContext 将引发错误。Python 上下文的使用确保即使并非所有数据都被使用,和/或在处理期间引发异常,流(在本例中为流式 HTTP 响应)也将被正确关闭。此外,StreamContexts 只能使用一次来使用流。在 StreamContext 退出后尝试使用它将产生 StreamClosedError。
您可以使用 StreamContext 的 source 属性来访问父 QueryResult 对象,其中包括列名称和类型。
流类型
query_column_block_stream 方法将块作为列数据序列返回,这些列数据以本机 Python 数据类型存储。使用上面的 taxi_trips 查询,返回的数据将是一个列表,其中列表的每个元素都是另一个列表(或元组),其中包含关联列的所有数据。因此,block[0] 将是一个元组,其中只包含字符串。面向列的格式最常用于对列中所有值执行聚合操作,例如计算总票价。
query_row_block_stream 方法将块作为行序列返回,就像传统的关联数据库一样。对于出租车行程,返回的数据将是一个列表,其中列表的每个元素都是另一个列表,表示一行数据。因此,block[0] 将包含第一个出租车行程的所有字段(按顺序),block[1] 将包含第二个出租车行程中所有字段的行,依此类推。面向行的结果通常用于显示或转换过程。
query_row_stream 是一种便捷方法,在迭代流时会自动移动到下一个块。否则,它与 query_row_block_stream 相同。
query_np_stream 方法将每个块作为二维 NumPy 数组返回。在内部,NumPy 数组(通常)存储为列,因此不需要不同的行或列方法。NumPy 数组的“形状”将表示为(列,行)。NumPy 库提供了许多操作 NumPy 数组的方法。请注意,如果查询中的所有列共享相同的 NumPy dtype,则返回的 NumPy 数组也将只有一个 dtype,并且可以在不实际更改其内部结构的情况下进行重塑/旋转。
query_df_stream 方法将每个 ClickHouse 数据块作为二维 Pandas Dataframe 返回。这是一个示例,显示 StreamContext 对象可以用作延迟上下文(但仅一次)。
最后,query_arrow_stream 方法将 ClickHouse ArrowStream 格式的结果作为 StreamContext 中包装的 pyarrow.ipc.RecordBatchStreamReader 返回。流的每次迭代都返回 PyArrow RecordBlock。
df_stream = client.query_df_stream('SELECT * FROM hits')
column_names = df_stream.source.column_names
with df_stream:
for df in df_stream:
<do something with the pandas DataFrame>
读取格式
读取格式控制从客户端 query、query_np 和 query_df 方法返回的值的数据类型。(raw_query 和 query_arrow 不修改来自 ClickHouse 的传入数据,因此格式控制不适用。)例如,如果 UUID 的读取格式从默认 native 格式更改为替代 string 格式,则 UUID 列的 ClickHouse 查询将作为字符串值(使用标准 8-4-4-4-12 RFC 1422 格式)而不是 Python UUID 对象返回。
任何格式化函数的“数据类型”参数都可以包含通配符。格式是单个小写字符串。
读取格式可以在多个级别设置
- 全局设置,使用
clickhouse_connect.datatypes.format包中定义的方法。这将控制所有查询的配置数据类型的格式。
from clickhouse_connect.datatypes.format import set_read_format
# Return both IPv6 and IPv4 values as strings
set_read_format('IPv*', 'string')
# Return all Date types as the underlying epoch second or epoch day
set_read_format('Date*', 'int')
- 对于整个查询,使用可选的
query_formats字典参数。在这种情况下,指定数据类型(或子列)的任何列(或子列)都将使用配置的格式。
# Return any UUID column as a string
client.query('SELECT user_id, user_uuid, device_uuid from users', query_formats={'UUID': 'string'})
- 对于特定列中的值,使用可选的
column_formats字典参数。键是 ClickHouse 返回的列名,数据列的格式或 ClickHouse 类型名称的二级“format”字典以及查询格式的值。此二级字典可用于嵌套列类型,例如 Tuples 或 Maps。
# Return IPv6 values in the `dev_address` column as strings
client.query('SELECT device_id, dev_address, gw_address from devices', column_formats={'dev_address':'string'})
读取格式选项(Python 类型)
| ClickHouse 类型 | 本机 Python 类型 | 读取格式 | 注释 |
|---|---|---|---|
| Int[8-64], UInt[8-32] | int | - | |
| UInt64 | int | signed | Superset 当前不处理大型无符号 UInt64 值 |
| [U]Int[128,256] | int | string | Pandas 和 NumPy int 值最大为 64 位,因此这些可以作为字符串返回 |
| Float32 | float | - | 所有 Python 浮点数在内部都是 64 位的 |
| Float64 | float | - | |
| Decimal | decimal.Decimal | - | |
| String | string | bytes | ClickHouse String 列没有固有的编码,因此也用于可变长度的二进制数据 |
| FixedString | bytes | string | FixedStrings 是固定大小的字节数组,但有时被视为 Python 字符串 |
| Enum[8,16] | string | string, int | Python 枚举不接受空字符串,因此所有枚举都呈现为字符串或基础 int 值。 |
| Date | datetime.date | int | ClickHouse 将日期存储为自 1970 年 1 月 1 日以来的天数。此值可以作为 int 使用 |
| Date32 | datetime.date | int | 与 Date 相同,但适用于更广泛的日期范围 |
| DateTime | datetime.datetime | int | ClickHouse 以纪元秒为单位存储 DateTime。此值可以作为 int 使用 |
| DateTime64 | datetime.datetime | int | Python datetime.datetime 仅限于微秒级精度。原始的 64 位 int 值可用 |
| IPv4 | ipaddress.IPv4Address | string | IP 地址可以作为字符串读取,并且格式正确的字符串可以作为 IP 地址插入 |
| IPv6 | ipaddress.IPv6Address | string | IP 地址可以作为字符串读取,并且格式正确的字符串可以作为 IP 地址插入 |
| Tuple(元组) | dict(字典)或 tuple(元组) | tuple(元组), json | 命名元组默认作为字典返回。命名元组也可以作为 JSON 字符串返回 |
| Map(映射) | dict | - | |
| Nested(嵌套) | Sequence[dict](字典序列) | - | |
| UUID | uuid.UUID | string | UUID 可以作为符合 RFC 4122 格式的字符串读取 |
| JSON | dict | string | 默认返回 Python 字典。string 格式将返回 JSON 字符串 |
| Variant(变体) | object(对象) | - | 返回与值为其存储的 ClickHouse 数据类型匹配的 Python 类型 |
| Dynamic(动态) | object(对象) | - | 返回与值为其存储的 ClickHouse 数据类型匹配的 Python 类型 |
外部数据
ClickHouse 查询可以接受任何 ClickHouse 格式的外部数据。此二进制数据与查询字符串一起发送,用于处理数据。外部数据功能的详细信息请参阅此处。客户端 query* 方法接受可选的 external_data 参数来利用此功能。external_data 参数的值应为 clickhouse_connect.driver.external.ExternalData 对象。该对象的构造函数接受以下参数
| 名称 | 类型 | 描述 |
|---|---|---|
| file_path | str | 本地系统路径上要从中读取外部数据的文件路径。file_path 或 data 是必需的 |
| file_name(文件名) | str | 外部数据“文件”的名称。如果未提供,将从 file_path 确定(不带扩展名) |
| data | bytes | 二进制形式的外部数据(而不是从文件读取)。data 或 file_path 是必需的 |
| fmt | str | 数据的 ClickHouse 输入格式。默认为 TSV |
| types(类型) | str 或 seq of str(字符串或字符串序列) | 外部数据中列数据类型的列表。如果为字符串,类型应以逗号分隔。types 或 structure 是必需的 |
| structure(结构) | str 或 seq of str(字符串或字符串序列) | 数据中列名 + 数据类型的列表(请参阅示例)。structure 或 types 是必需的 |
| mime_type(MIME 类型) | str | 文件数据的可选 MIME 类型。目前 ClickHouse 忽略此 HTTP 子标头 |
要发送带有包含“movie”数据的外部 CSV 文件的查询,并将该数据与 ClickHouse 服务器上已存在的 directors 表结合
import clickhouse_connect
from clickhouse_connect.driver.external import ExternalData
client = clickhouse_connect.get_client()
ext_data = ExternalData(file_path='/data/movies.csv',
fmt='CSV',
structure=['movie String', 'year UInt16', 'rating Decimal32(3)', 'director String'])
result = client.query('SELECT name, avg(rating) FROM directors INNER JOIN movies ON directors.name = movies.director GROUP BY directors.name',
external_data=ext_data).result_rows
可以使用 add_file 方法将其他外部数据文件添加到初始 ExternalData 对象,该方法接受与构造函数相同的参数。对于 HTTP,所有外部数据都作为 multi-part/form-data 文件上传的一部分传输。
时区
有多种机制可以将时区应用于 ClickHouse DateTime 和 DateTime64 值。在内部,ClickHouse 服务器始终将任何 DateTime 或 DateTime64 对象存储为表示自 epoch(1970-01-01 00:00:00 UTC 时间)以来的秒数的时区无关数字。对于 DateTime64 值,表示可以是自 epoch 以来的毫秒、微秒或纳秒,具体取决于精度。因此,任何时区信息的应用始终发生在客户端。请注意,这涉及有意义的额外计算,因此在对性能至关重要的应用程序中,建议将 DateTime 类型视为 epoch 时间戳,除非用于用户显示和转换(例如,Pandas Timestamps 始终是表示 epoch 纳秒的 64 位整数,以提高性能)。
在查询中使用时区感知数据类型时 - 特别是 Python datetime.datetime 对象 -- clickhouse-connect 使用以下优先级规则应用客户端时区
- 如果为查询指定了查询方法参数
client_tzs,则应用特定的列时区 - 如果 ClickHouse 列具有时区元数据(即,它是 DateTime64(3, 'America/Denver') 之类的类型),则应用 ClickHouse 列时区。(请注意,在 ClickHouse 版本 23.2 之前的 DateTime 列的 clickhouse-connect 无法使用此时区元数据)
- 如果为查询指定了查询方法参数
query_tz,则应用“查询时区”。 - 如果时区设置应用于查询或会话,则应用该时区。(此功能尚未在 ClickHouse 服务器中发布)
- 最后,如果客户端
apply_server_timezone参数已设置为 True(默认值),则应用 ClickHouse 服务器时区。
请注意,如果根据这些规则应用的时区是 UTC,则 clickhouse-connect 将始终返回时区无关的 Python datetime.datetime 对象。然后,应用程序代码可以根据需要将其他时区信息添加到此时区无关对象。
使用 ClickHouse Connect 插入数据:高级用法
InsertContexts(插入上下文)
ClickHouse Connect 在 InsertContext(插入上下文)中执行所有插入。InsertContext 包括作为参数发送给客户端 insert 方法的所有值。此外,当最初构造 InsertContext 时,ClickHouse Connect 会检索高效 Native 格式插入所需的插入列的数据类型。通过为多个插入重用 InsertContext,可以避免此“预查询”,并且可以更快、更高效地执行插入。
可以使用客户端 create_insert_context 方法获取 InsertContext。该方法接受与 insert 函数相同的参数。请注意,对于重用,只能修改 InsertContext 的 data 属性。这与其为相同表的重复插入新数据提供可重用对象的预期目的相一致。
test_data = [[1, 'v1', 'v2'], [2, 'v3', 'v4']]
ic = test_client.create_insert_context(table='test_table', data='test_data')
client.insert(context=ic)
assert client.command('SELECT count() FROM test_table') == 2
new_data = [[3, 'v5', 'v6'], [4, 'v7', 'v8']]
ic.data = new_data
client.insert(context=ic)
qr = test_client.query('SELECT * FROM test_table ORDER BY key DESC')
assert qr.row_count == 4
assert qr[0][0] == 4
InsertContexts 包括在插入过程中更新的可变状态,因此它们不是线程安全的。
写入格式
写入格式目前仅为有限数量的类型实现。在大多数情况下,ClickHouse Connect 将尝试通过检查第一个(非空)数据值的类型来自动确定列的正确写入格式。例如,如果插入到 DateTime 列中,并且该列的第一个插入值是 Python 整数,则 ClickHouse Connect 将直接插入整数值,并假设它实际上是 epoch 秒。
在大多数情况下,无需覆盖数据类型的写入格式,但可以使用 clickhouse_connect.datatypes.format 包中的关联方法在全球级别执行此操作。
写入格式选项
| ClickHouse 类型 | 本机 Python 类型 | 写入格式 | 注释 |
|---|---|---|---|
| Int[8-64], UInt[8-32] | int | - | |
| UInt64 | int | ||
| [U]Int[128,256] | int | ||
| Float32 | float | ||
| Float64 | float | ||
| Decimal | decimal.Decimal | ||
| String | string | ||
| FixedString | bytes | string | 如果作为字符串插入,则额外的字节将设置为零 |
| Enum[8,16] | string | ||
| Date | datetime.date | int | ClickHouse 将日期存储为自 01/01/1970 以来的天数。int 类型将被假定为此“epoch date”值 |
| Date32 | datetime.date | int | 与 Date 相同,但适用于更广泛的日期范围 |
| DateTime | datetime.datetime | int | ClickHouse 将 DateTime 存储为 epoch 秒。int 类型将被假定为此“epoch second”值 |
| DateTime64 | datetime.datetime | int | Python datetime.datetime 仅限于微秒级精度。原始的 64 位 int 值可用 |
| IPv4 | ipaddress.IPv4Address | string | 格式正确的字符串可以作为 IPv4 地址插入 |
| IPv6 | ipaddress.IPv6Address | string | 格式正确的字符串可以作为 IPv6 地址插入 |
| Tuple(元组) | dict(字典)或 tuple(元组) | ||
| Map(映射) | dict | ||
| Nested(嵌套) | Sequence[dict](字典序列) | ||
| UUID | uuid.UUID | string | 格式正确的字符串可以作为 ClickHouse UUID 插入 |
| JSON/Object('json') | dict | string | 字典或 JSON 字符串都可以插入到 JSON 列中(请注意,Object('json') 已弃用) |
| Variant(变体) | object(对象) | 目前,所有变体都作为字符串插入,并由 ClickHouse 服务器解析 | |
| Dynamic(动态) | object(对象) | 警告 - 目前,任何插入到 Dynamic 列中的数据都将持久化为 ClickHouse String |
其他选项
ClickHouse Connect 为高级用例提供了许多其他选项
全局设置
有一些设置可以全局控制 ClickHouse Connect 的行为。它们可以从顶层 common 包访问
from clickhouse_connect import common
common.set_setting('autogenerate_session_id', False)
common.get_setting('invalid_setting_action')
'drop'
这些通用设置 autogenerate_session_id、product_name 和 readonly 始终应在使用 clickhouse_connect.get_client 方法创建客户端之前修改。在创建客户端后更改这些设置不会影响现有客户端的行为。
目前定义了十个全局设置
| 设置名称 | 默认值 | 选项 | 描述 |
|---|---|---|---|
| autogenerate_session_id(自动生成会话 ID) | True | True, False(真,假) | 为每个客户端会话自动生成新的 UUID(1) 会话 ID(如果未提供)。如果未提供会话 ID(在客户端或查询级别),ClickHouse 将为每个查询生成随机内部 ID |
| invalid_setting_action(无效设置操作) | 'error'(“错误”) | 'drop', 'send', 'error'(“丢弃”,“发送”,“错误”) | 当提供无效或只读设置时(对于客户端会话或查询)要采取的操作。如果为 drop,则将忽略该设置;如果为 send,则将该设置发送到 ClickHouse;如果为 error,则将引发客户端 ProgrammingError |
| dict_parameter_format(字典参数格式) | 'json' | 'json', 'map' | 这控制参数化查询是将 Python 字典转换为 JSON 还是 ClickHouse Map 语法。json 应用于插入到 JSON 列中,map 应用于 ClickHouse Map 列 |
| product_name(产品名称) | 一个字符串,与查询一起传递到 clickhouse,用于跟踪使用 ClickHouse Connect 的应用程序。应采用 <产品名称;&gl/<产品版本> 的形式 | ||
| max_connection_age(最大连接生存时间) | 600 | HTTP Keep Alive 连接保持打开/重用的最大秒数。这可以防止针对负载均衡器/代理后面的单个 ClickHouse 节点集中连接。默认为 10 分钟。 | |
| readonly(只读) | 0 | 0, 1 | 对于 19.17 之前的版本,隐含的“read_only”ClickHouse 设置。可以设置为匹配 ClickHouse “read_only”值,以便允许与非常旧的 ClickHouse 版本一起操作 |
| use_protocol_version(使用协议版本) | True | True, False(真,假) | 使用客户端协议版本。DateTime 时区列需要此设置,但与当前版本的 chproxy 不兼容 |
| max_error_size(最大错误大小) | 1024 | 客户端错误消息中将返回的最大字符数。使用 0 作为此设置以获取完整的 ClickHouse 错误消息。默认为 1024 个字符。 | |
| send_os_user(发送操作系统用户) | True | True, False(真,假) | 在发送到 ClickHouse 的客户端信息中包含检测到的操作系统用户(HTTP User-Agent 字符串) |
| http_buffer_size(HTTP 缓冲区大小) | 10MB | 用于 HTTP 流式查询的“内存中”缓冲区的大小(以字节为单位) |
压缩
ClickHouse Connect 支持 lz4、zstd、brotli 和 gzip 压缩,用于查询结果和插入。始终记住,使用压缩通常需要在网络带宽/传输速度与 CPU 使用率(客户端和服务器端)之间进行权衡。
要接收压缩数据,必须将 ClickHouse 服务器 enable_http_compression 设置为 1,或者用户必须有权在“每个查询”的基础上更改设置。
压缩由调用 clickhouse_connect.get_client 工厂方法时的 compress 参数控制。默认情况下,compress 设置为 True,这将触发默认压缩设置。对于使用 query、query_np 和 query_df 客户端方法执行的查询,ClickHouse Connect 将添加 Accept-Encoding 标头,其中包含 lz4、zstd、br(brotli,如果安装了 brotli 库)、gzip 和 deflate 编码到使用 query 客户端方法执行的查询(以及间接地,query_np 和 query_df。(对于大多数请求,ClickHouse 服务器将返回 zstd 压缩的有效负载。)对于插入,默认情况下,ClickHouse Connect 将使用 lz4 压缩压缩插入块,并发送 Content-Encoding: lz4 HTTP 标头。
get_client compress 参数也可以设置为特定的压缩方法,即 lz4、zstd、br 或 gzip 之一。然后,该方法将用于插入和查询结果(如果 ClickHouse 服务器支持)。所需的 zstd 和 lz4 压缩库现在默认随 ClickHouse Connect 一起安装。如果指定了 br/brotli,则必须单独安装 brotli 库。
请注意,raw* 客户端方法不使用客户端配置指定的压缩。
我们也不建议使用 gzip 压缩,因为它在压缩和解压缩数据方面都明显慢于替代方案。
HTTP 代理支持
ClickHouse Connect 使用 urllib3 库添加了基本的 HTTP 代理支持。它识别标准 HTTP_PROXY 和 HTTPS_PROXY 环境变量。请注意,使用这些环境变量将应用于使用 clickhouse_connect.get_client 方法创建的任何客户端。或者,要配置每个客户端,可以使用 http_proxy 或 https_proxy 参数来调用 get_client 方法。有关 HTTP 代理支持实现的详细信息,请参阅 urllib3 文档。
要使用 Socks 代理,可以将 urllib3 SOCKSProxyManager 作为 pool_mgr 参数发送到 get_client。请注意,这将需要直接安装 PySocks 库,或者使用 urllib3 依赖项的 [socks] 选项。
“旧” JSON 数据类型
实验性的 Object(或 Object('json'))数据类型已弃用,应避免在生产环境中使用。ClickHouse Connect 继续为该数据类型提供有限的支持,以实现向后兼容性。请注意,此支持不包括预期将“顶层”或“父”JSON 值作为字典或等效项返回的查询,并且此类查询将导致异常。
“新” Variant/Dynamic/JSON 数据类型(实验性功能)
从 0.8.0 版本开始,clickhouse-connect 为新的(也是实验性的)ClickHouse 类型 Variant、Dynamic 和 JSON 提供了实验性支持。
使用说明
- JSON 数据可以作为 Python 字典或包含 JSON 对象
{}的 JSON 字符串插入。不支持其他形式的 JSON 数据 - 使用这些类型的子列/路径的查询将返回子列的类型。
- 有关其他使用说明,请参阅主要的 ClickHouse 文档
已知限制:
- 必须在 ClickHouse 设置中启用每种类型,然后才能使用。
- “新” JSON 类型从 ClickHouse 24.8 版本开始可用
- 由于内部格式更改,
clickhouse-connect仅与 ClickHouse 24.7 版本开始的 Variant 类型兼容 - 返回的 JSON 对象将仅返回
max_dynamic_paths数量的元素(默认为 1024)。这将在未来的版本中修复。 - 插入到
Dynamic列中的数据将始终是 Python 值的 String 表示形式。一旦 https://github.com/ClickHouse/ClickHouse/issues/70395 得到修复,这将在未来的版本中修复。 - 新类型的实现尚未在 C 代码中进行优化,因此性能可能比更简单、更成熟的数据类型稍慢。