Schema 设计
理解有效的 schema 设计是优化 ClickHouse 性能的关键,它包含权衡的选择,最佳方法取决于所服务的查询以及数据更新频率、延迟要求和数据量等因素。本指南概述了 schema 设计最佳实践和数据建模技术,以优化 ClickHouse 性能。
Stack Overflow 数据集
在本指南的示例中,我们使用 Stack Overflow 数据集的子集。它包含 2008 年 4 月至 2024 年 4 月 Stack Overflow 上发生的每篇文章、投票、用户、评论和徽章。此数据以 Parquet 格式提供,schema 如下,位于 S3 存储桶 s3://datasets-documentation/stackoverflow/parquet/ 下
指示的主键和关系不是通过约束强制执行的(Parquet 是文件而不是表格式),仅指示数据如何关联以及它拥有的唯一键。
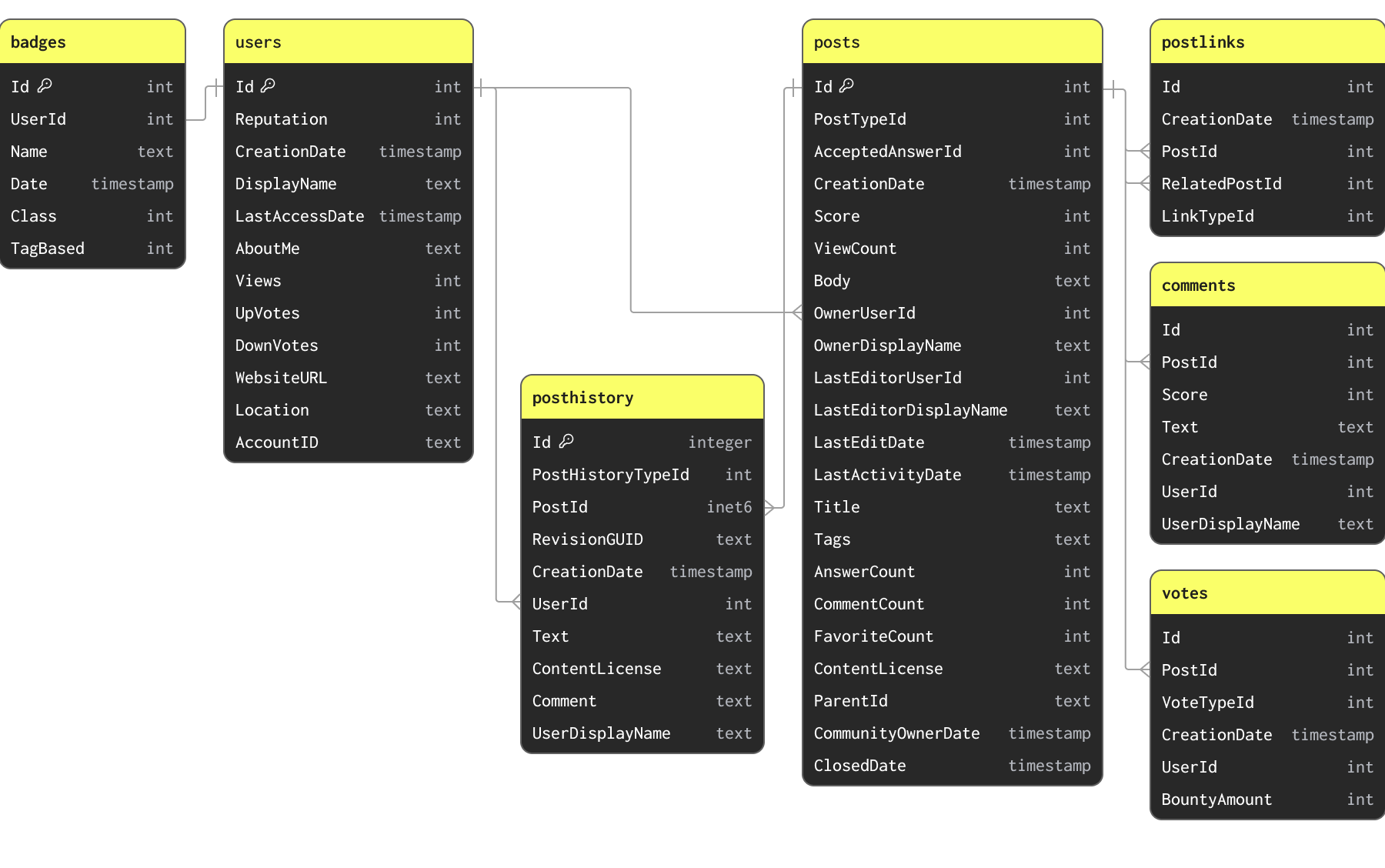
Stack Overflow 数据集包含许多相关表。在任何数据建模任务中,我们建议用户首先关注加载主表。这不一定是最大的表,而是您期望接收最多分析查询的表。这将使您熟悉主要的 ClickHouse 概念和类型,如果来自主要的 OLTP 背景,这一点尤其重要。随着添加更多表以充分利用 ClickHouse 功能并获得最佳性能,此表可能需要重新建模。
为了本指南的目的,上述 schema 不是最优的。
建立初始 schema
由于 posts 表将是大多数分析查询的目标,因此我们专注于为此表建立 schema。此数据在公共 S3 存储桶 s3://datasets-documentation/stackoverflow/parquet/posts/*.parquet 中提供,每年一个文件。
以 Parquet 格式从 S3 加载数据是加载数据到 ClickHouse 最常见和首选的方式。 ClickHouse 针对处理 Parquet 进行了优化,并且可能每秒从 S3 读取和插入数千万行。
ClickHouse 提供 schema 推断功能,以自动识别数据集的类型。所有数据格式(包括 Parquet)都支持此功能。我们可以利用此功能通过 s3 表函数和DESCRIBE 命令来识别数据的 ClickHouse 类型。请注意,下面我们使用 glob 模式 *.parquet 读取 stackoverflow/parquet/posts 文件夹中的所有文件。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
SETTINGS describe_compact_output = 1
┌─name──────────────────┬─type───────────────────────────┐
│ Id │ Nullable(Int64) │
│ PostTypeId │ Nullable(Int64) │
│ AcceptedAnswerId │ Nullable(Int64) │
│ CreationDate │ Nullable(DateTime64(3, 'UTC')) │
│ Score │ Nullable(Int64) │
│ ViewCount │ Nullable(Int64) │
│ Body │ Nullable(String) │
│ OwnerUserId │ Nullable(Int64) │
│ OwnerDisplayName │ Nullable(String) │
│ LastEditorUserId │ Nullable(Int64) │
│ LastEditorDisplayName │ Nullable(String) │
│ LastEditDate │ Nullable(DateTime64(3, 'UTC')) │
│ LastActivityDate │ Nullable(DateTime64(3, 'UTC')) │
│ Title │ Nullable(String) │
│ Tags │ Nullable(String) │
│ AnswerCount │ Nullable(Int64) │
│ CommentCount │ Nullable(Int64) │
│ FavoriteCount │ Nullable(Int64) │
│ ContentLicense │ Nullable(String) │
│ ParentId │ Nullable(String) │
│ CommunityOwnedDate │ Nullable(DateTime64(3, 'UTC')) │
│ ClosedDate │ Nullable(DateTime64(3, 'UTC')) │
└───────────────────────┴────────────────────────────────┘
s3 表函数允许从 ClickHouse 就地查询 S3 中的数据。此函数与 ClickHouse 支持的所有文件格式兼容。
这为我们提供了初始的非优化 schema。默认情况下,ClickHouse 将这些映射到等效的 Nullable 类型。我们可以使用简单的 CREATE EMPTY AS SELECT 命令,使用这些类型创建 ClickHouse 表。
CREATE TABLE posts
ENGINE = MergeTree
ORDER BY () EMPTY AS
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
几个要点
运行此命令后,我们的 posts 表为空。没有加载任何数据。我们已将 MergeTree 指定为我们的表引擎。 MergeTree 是您可能最常用的 ClickHouse 表引擎。它是您 ClickHouse 工具箱中的多功能工具,能够处理 PB 级数据,并服务于大多数分析用例。其他表引擎适用于需要支持高效更新的用例,例如 CDC。
子句 ORDER BY () 表示我们没有索引,更具体地说,我们的数据没有顺序。稍后会详细介绍。现在,只需知道所有查询都需要线性扫描。
确认表已创建
SHOW CREATE TABLE posts
CREATE TABLE posts
(
`Id` Nullable(Int64),
`PostTypeId` Nullable(Int64),
`AcceptedAnswerId` Nullable(Int64),
`CreationDate` Nullable(DateTime64(3, 'UTC')),
`Score` Nullable(Int64),
`ViewCount` Nullable(Int64),
`Body` Nullable(String),
`OwnerUserId` Nullable(Int64),
`OwnerDisplayName` Nullable(String),
`LastEditorUserId` Nullable(Int64),
`LastEditorDisplayName` Nullable(String),
`LastEditDate` Nullable(DateTime64(3, 'UTC')),
`LastActivityDate` Nullable(DateTime64(3, 'UTC')),
`Title` Nullable(String),
`Tags` Nullable(String),
`AnswerCount` Nullable(Int64),
`CommentCount` Nullable(Int64),
`FavoriteCount` Nullable(Int64),
`ContentLicense` Nullable(String),
`ParentId` Nullable(String),
`CommunityOwnedDate` Nullable(DateTime64(3, 'UTC')),
`ClosedDate` Nullable(DateTime64(3, 'UTC'))
)
ENGINE = MergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
ORDER BY tuple()
定义了初始 schema 后,我们可以使用 INSERT INTO SELECT 填充数据,使用 s3 表函数读取数据。以下操作在大约 2 分钟内在 8 核 ClickHouse Cloud 实例上加载 posts 数据。
INSERT INTO posts SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 148.140 sec. Processed 59.82 million rows, 38.07 GB (403.80 thousand rows/s., 257.00 MB/s.)
上面的查询加载了 6000 万行。虽然对于 ClickHouse 来说很小,但互联网连接速度较慢的用户可能希望加载数据子集。这可以通过简单地指定他们希望通过 glob 模式加载的年份来实现,例如
https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2008.parquet或https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/{2008, 2009}.parquet。有关如何使用 glob 模式定位文件子集的信息,请参阅此处。
优化类型
ClickHouse 查询性能的秘诀之一是压缩。
磁盘上的数据越少,意味着 I/O 越少,从而使查询和插入速度更快。任何压缩算法相对于 CPU 的开销在大多数情况下都会被 I/O 的减少所抵消。因此,在确保 ClickHouse 查询速度快时,首先应关注提高数据压缩率。
有关 ClickHouse 为何能很好地压缩数据的原因,我们推荐这篇文章。总而言之,作为面向列的数据库,值将按列顺序写入。如果这些值已排序,则相同的值将彼此相邻。压缩算法利用连续的数据模式。最重要的是,ClickHouse 具有编解码器和粒度数据类型,允许用户进一步调整压缩技术。
ClickHouse 中的压缩将受到 3 个主要因素的影响:排序键、数据类型以及使用的任何编解码器。所有这些都通过 schema 配置。
压缩和查询性能的最大初始改进可以通过简单的类型优化过程获得。可以应用一些简单的规则来优化 schema
- 使用严格类型 - 我们的初始 schema 对许多明显是数字的列使用了字符串。使用正确的类型将确保在过滤和聚合时获得预期的语义。日期类型也是如此,它们已在 Parquet 文件中正确提供。
- 避免 Nullable 列 - 默认情况下,上述列已被假定为 Null。Nullable 类型允许查询确定空值和 Null 值之间的区别。这将创建一个单独的 UInt8 类型的列。用户每次使用 nullable 列时都必须处理此附加列。这导致使用了额外的存储空间,并且几乎总是对查询性能产生负面影响。仅当类型的默认空值和 Null 之间存在差异时才使用 Nullable。例如,
ViewCount列中空值的 0 值可能足以满足大多数查询,并且不会影响结果。如果应以不同的方式处理空值,则通常也可以使用过滤器将其从查询中排除。为数值类型使用最小精度 - ClickHouse 有许多数值类型,专为不同的数值范围和精度而设计。始终旨在最大限度地减少用于表示列的位数。除了不同大小的整数(例如 Int16)之外,ClickHouse 还提供无符号变体,其最小值为 0。这些变体可以使用更少的位数来表示列,例如 UInt16 的最大值为 65535,是 Int16 的两倍。如果可能,首选这些类型而不是更大的有符号变体。 - 日期类型的最小精度 - ClickHouse 支持多种日期和日期时间类型。Date 和 Date32 可用于存储纯日期,后者以更多位为代价支持更大的日期范围。DateTime 和 DateTime64 提供对日期时间的支持。DateTime 仅限于秒级粒度,并使用 32 位。DateTime64,顾名思义,使用 64 位,但提供高达纳秒级粒度的支持。与以往一样,选择查询可接受的更粗糙的版本,最大限度地减少所需的位数。
- 使用 LowCardinality - 唯一值数量较少的数字、字符串、Date 或 DateTime 列可以使用 LowCardinality 类型进行编码。此字典对值进行编码,从而减小磁盘上的大小。对于唯一值少于 10k 的列,请考虑使用此类型。FixedString 用于特殊情况 - 长度固定的字符串可以使用 FixedString 类型进行编码,例如语言和货币代码。当数据长度正好为 N 个字节时,这非常有效。在所有其他情况下,它可能会降低效率,并且首选 LowCardinality。
- 枚举用于数据验证 - 枚举类型可用于有效地编码枚举类型。枚举可以是 8 位或 16 位,具体取决于它们需要存储的唯一值的数量。如果您需要在插入时进行关联验证(未声明的值将被拒绝)或希望执行利用枚举值自然顺序的查询,请考虑使用此类型,例如,想象一个包含用户响应的反馈列
Enum(':(' = 1, ':|' = 2, ':)' = 3)。
提示:要查找所有列的范围以及不同值的数量,用户可以使用简单的查询
SELECT * APPLY min, * APPLY max, * APPLY uniq FROM table FORMAT Vertical。我们建议对较小的数据子集执行此操作,因为这可能会很昂贵。此查询要求数值至少定义为如此才能获得准确的结果,即不是字符串。
通过将这些简单的规则应用于我们的 posts 表,我们可以为每一列识别出最佳类型
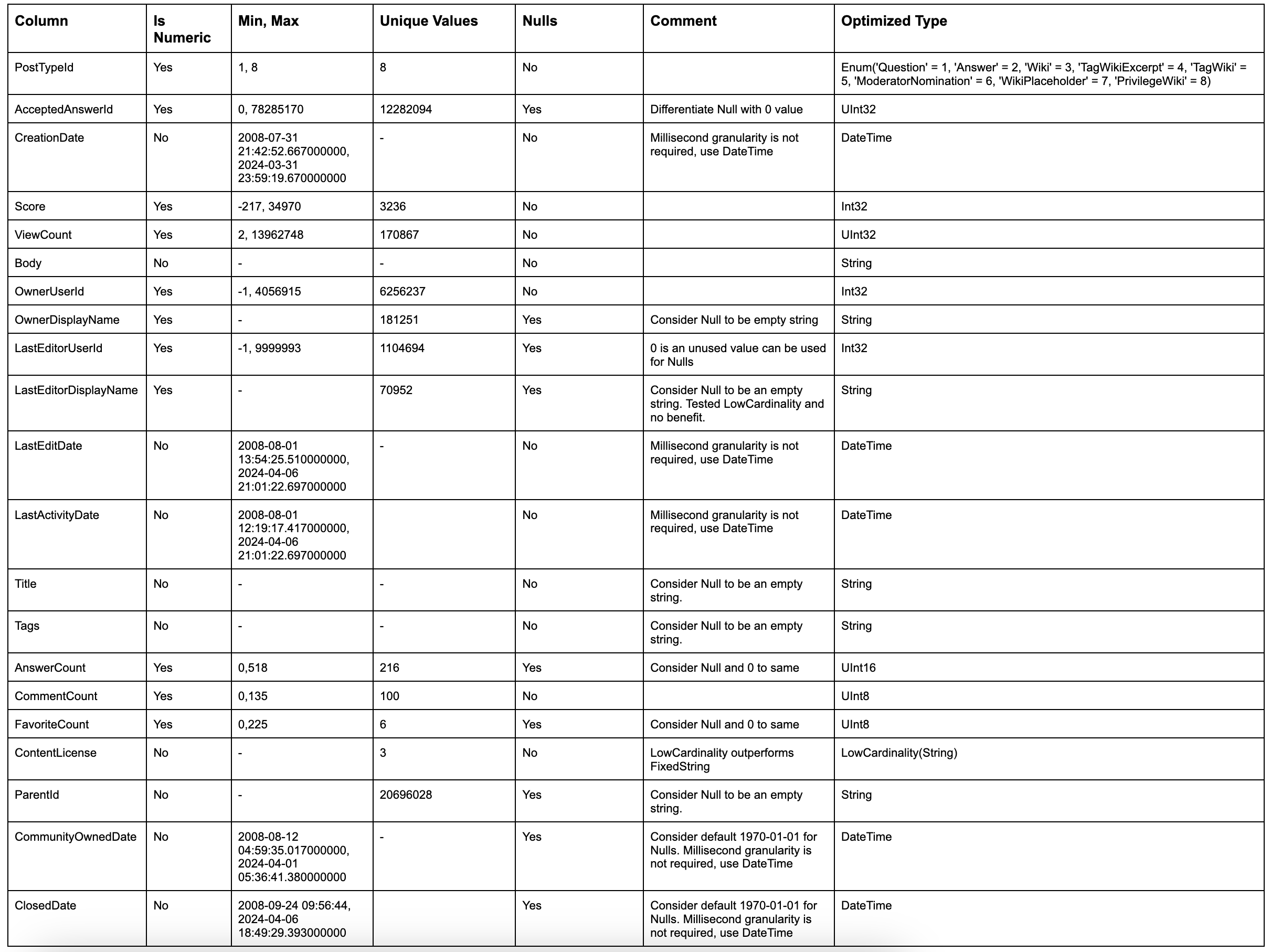
以上为我们提供了以下 schema
CREATE TABLE posts_v2
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT 'Optimized types'
我们可以使用简单的 INSERT INTO SELECT 填充它,从我们之前的表读取数据并插入到此表中
INSERT INTO posts_v2 SELECT * FROM posts
0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
我们在新的 schema 中不保留任何 null 值。上面的插入将这些隐式转换为其各自类型的默认值 - 整数为 0,字符串为空值。ClickHouse 还会自动将任何数值转换为其目标精度。ClickHouse 中的主(排序)键 来自 OLTP 数据库的用户通常会在 ClickHouse 中寻找等效的概念。
选择排序键
在 ClickHouse 通常使用的规模下,内存和磁盘效率至关重要。数据以称为部件的块写入 ClickHouse 表,并应用规则在后台合并部件。在 ClickHouse 中,每个部件都有自己的主索引。当部件合并时,合并部件的主索引也会合并。部件的主索引对于每组行有一个索引条目 - 这种技术称为稀疏索引。
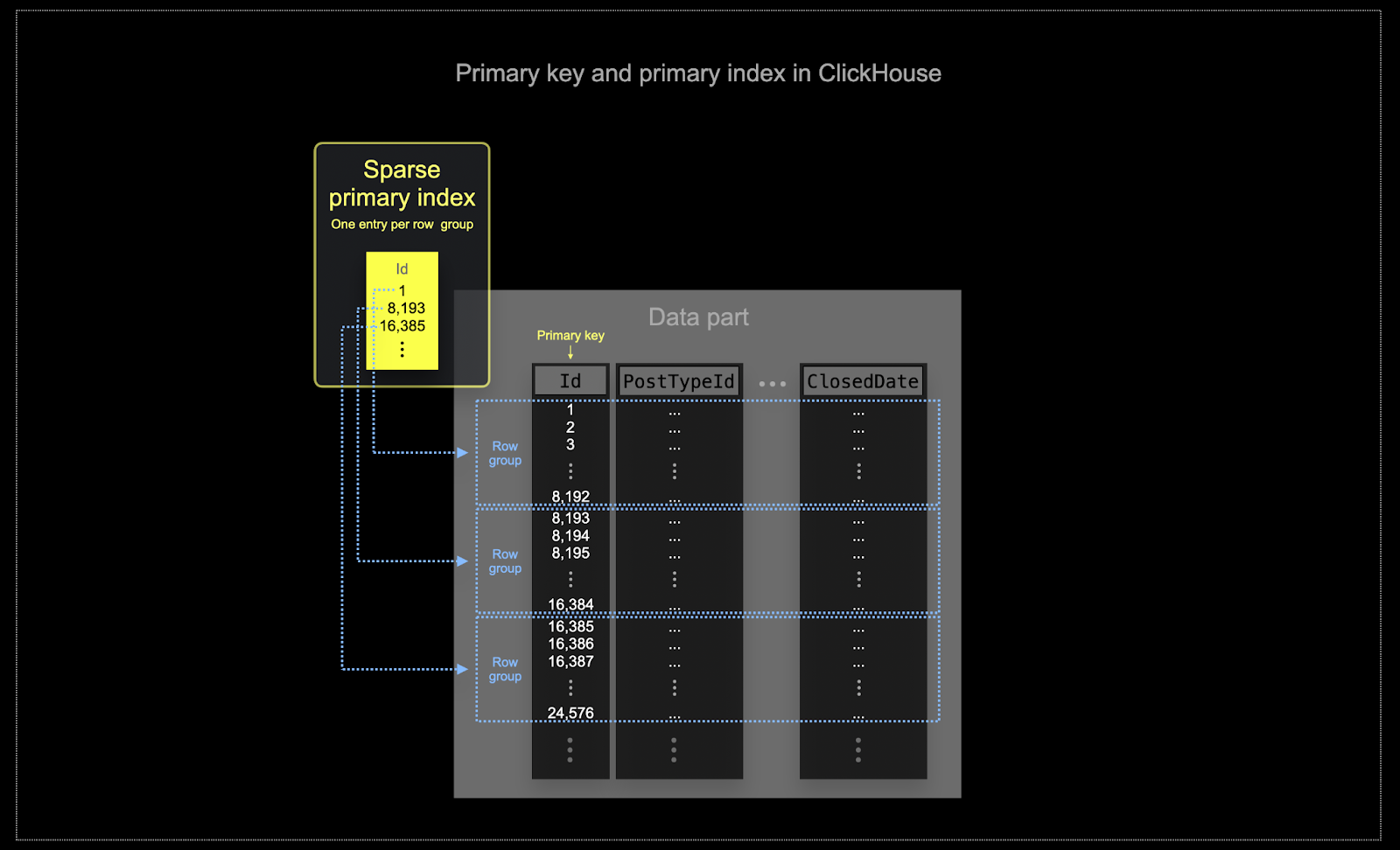
ClickHouse 中选择的键不仅将确定索引,还将确定数据写入磁盘的顺序。因此,它可能会极大地影响压缩级别,进而影响查询性能。使大多数列的值以连续顺序写入的排序键将允许所选的压缩算法(和编解码器)更有效地压缩数据。
表中的所有列都将根据指定的排序键的值进行排序,无论它们是否包含在键本身中。例如,如果将
CreationDate用作键,则所有其他列中的值的顺序将对应于CreationDate列中的值的顺序。可以指定多个排序键 - 这将以与SELECT查询中的ORDER BY子句相同的语义进行排序。
可以应用一些简单的规则来帮助选择排序键。以下内容有时可能会冲突,因此请按顺序考虑这些内容。用户可以从此过程中识别出多个键,通常 4-5 个就足够了
- 选择与您的常用过滤器对齐的列。如果一列在
WHERE子句中经常使用,请优先将其包含在您的键中,而不是那些使用频率较低的列。首选有助于在过滤时排除总行数很大百分比的列,从而减少需要读取的数据量。 - 首选可能与表中其他列高度相关的列。这将有助于确保这些值也连续存储,从而提高压缩率。可以使排序键中列的
GROUP BY和ORDER BY操作更节省内存。
在识别排序键的列子集时,以特定顺序声明列。此顺序会显着影响查询中辅助键列的过滤效率以及表数据文件的压缩率。通常,最好按基数升序对键进行排序。这应与以下事实相平衡:对排序键中稍后出现的列进行过滤的效率将低于对元组中较早出现的列进行过滤的效率。平衡这些行为并考虑您的访问模式(最重要的是测试变体)。
示例
将上述指南应用于我们的 posts 表,假设我们的用户希望执行按日期和帖子类型过滤的分析,例如
“过去 3 个月内哪些问题评论最多”。
使用我们之前的 posts_v2 表(具有优化的类型但没有排序键)对此问题的查询
SELECT
Id,
Title,
CommentCount
FROM posts_v2
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
ORDER BY CommentCount DESC
LIMIT 3
┌───────Id─┬─Title─────────────────────────────────────────────────────────────┬─CommentCount─┐
│ 78203063 │ How to avoid default initialization of objects in std::vector? │ 74 │
│ 78183948 │ About memory barrier │ 52 │
│ 77900279 │ Speed Test for Buffer Alignment: IBM's PowerPC results vs. my CPU │ 49 │
└──────────┴───────────────────────────────────────────────────────────────────┴──────────────
10 rows in set. Elapsed: 0.070 sec. Processed 59.82 million rows, 569.21 MB (852.55 million rows/s., 8.11 GB/s.)
Peak memory usage: 429.38 MiB.
即使已线性扫描了所有 6000 万行,此处的查询也非常快 - ClickHouse 就是这么快 :) 您必须相信我们,排序键在 TB 和 PB 规模下是值得的!
让我们选择列 PostTypeId 和 CreationDate 作为我们的排序键。
也许在我们的案例中,我们期望用户始终按 PostTypeId 进行过滤。它的基数为 8,是排序键中第一个条目的逻辑选择。认识到日期粒度过滤可能就足够了(它仍然会使日期时间过滤器受益),因此我们使用 toDate(CreationDate) 作为我们键的第二个组成部分。这还将产生更小的索引,因为日期可以用 16 表示,从而加快过滤速度。我们的最后一个键条目是 CommentCount,以帮助查找评论最多的帖子(最终排序)。
CREATE TABLE posts_v3
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
COMMENT 'Ordering Key'
--populate table from existing table
INSERT INTO posts_v3 SELECT * FROM posts_v2
0 rows in set. Elapsed: 158.074 sec. Processed 59.82 million rows, 76.21 GB (378.42 thousand rows/s., 482.14 MB/s.)
Peak memory usage: 6.41 GiB.
Our previous query improves the query response time by over 3x:
SELECT
Id,
Title,
CommentCount
FROM posts_v3
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
ORDER BY CommentCount DESC
LIMIT 3
10 rows in set. Elapsed: 0.020 sec. Processed 290.09 thousand rows, 21.03 MB (14.65 million rows/s., 1.06 GB/s.)
对于有兴趣了解通过使用特定类型和适当的排序键实现的压缩改进的用户,请参阅ClickHouse 中的压缩。如果用户需要进一步提高压缩率,我们还建议阅读选择正确的列压缩编解码器部分。
下一步:数据建模技术
到目前为止,我们仅迁移了一个表。虽然这使我们能够介绍一些核心 ClickHouse 概念,但不幸的是,大多数 schema 并非如此简单。
在下面列出的其他指南中,我们将探讨许多技术来重构我们更广泛的 schema,以实现最佳 ClickHouse 查询。在整个过程中,我们的目标是使 Posts 仍然是我们的中心表,大多数分析查询都通过它执行。虽然其他表仍然可以单独查询,但我们假设大多数分析都希望在 posts 的上下文中执行。
在本节中,我们使用了其他表的优化变体。虽然我们提供了这些表的 schema,但为了简洁起见,我们省略了所做的决策。这些决策基于前面描述的规则,我们将推断决策留给读者。
以下方法都旨在最大限度地减少使用 JOIN 以优化读取和提高查询性能的需求。虽然 ClickHouse 完全支持 JOIN,但我们建议谨慎使用它们(JOIN 查询中 2 到 3 个表就足够了)以实现最佳性能。
ClickHouse 没有外键的概念。这并不禁止连接,但意味着引用完整性留给用户在应用程序级别管理。在像 ClickHouse 这样的 OLAP 系统中,数据完整性通常在应用程序级别或数据摄取过程中进行管理,而不是由数据库本身强制执行,因为数据库本身会产生巨大的开销。这种方法允许更大的灵活性和更快的数据插入。这与 ClickHouse 专注于速度和大规模数据集的读取和插入查询的可扩展性相一致。
为了最大限度地减少查询时 Join 的使用,用户有几种工具/方法
- 数据反规范化 - 通过组合表并为非 1:1 关系使用复杂类型来反规范化数据。这通常涉及将任何连接从查询时转移到插入时。
- 字典 - ClickHouse 的一项特定功能,用于处理直接连接和键值查找。
- 增量物化视图 - ClickHouse 的一项功能,用于将计算成本从查询时转移到插入时,包括增量计算聚合值的能力。
- 可刷新物化视图 - 类似于其他数据库产品中使用的物化视图,这允许定期计算查询结果并将结果缓存。
我们在每个指南中都探讨了这些方法,重点介绍了每种方法适用的情况,并提供了一个示例,说明如何将其应用于解决 Stack Overflow 数据集的问题。