字典
ClickHouse 中的字典提供来自各种内部和外部来源数据的内存 键值 表示,针对超低延迟查找查询进行了优化。
字典对于以下方面很有用
- 提高查询性能,尤其是在与
JOIN结合使用时 - 在不减慢摄取过程的情况下,动态丰富摄取的数据
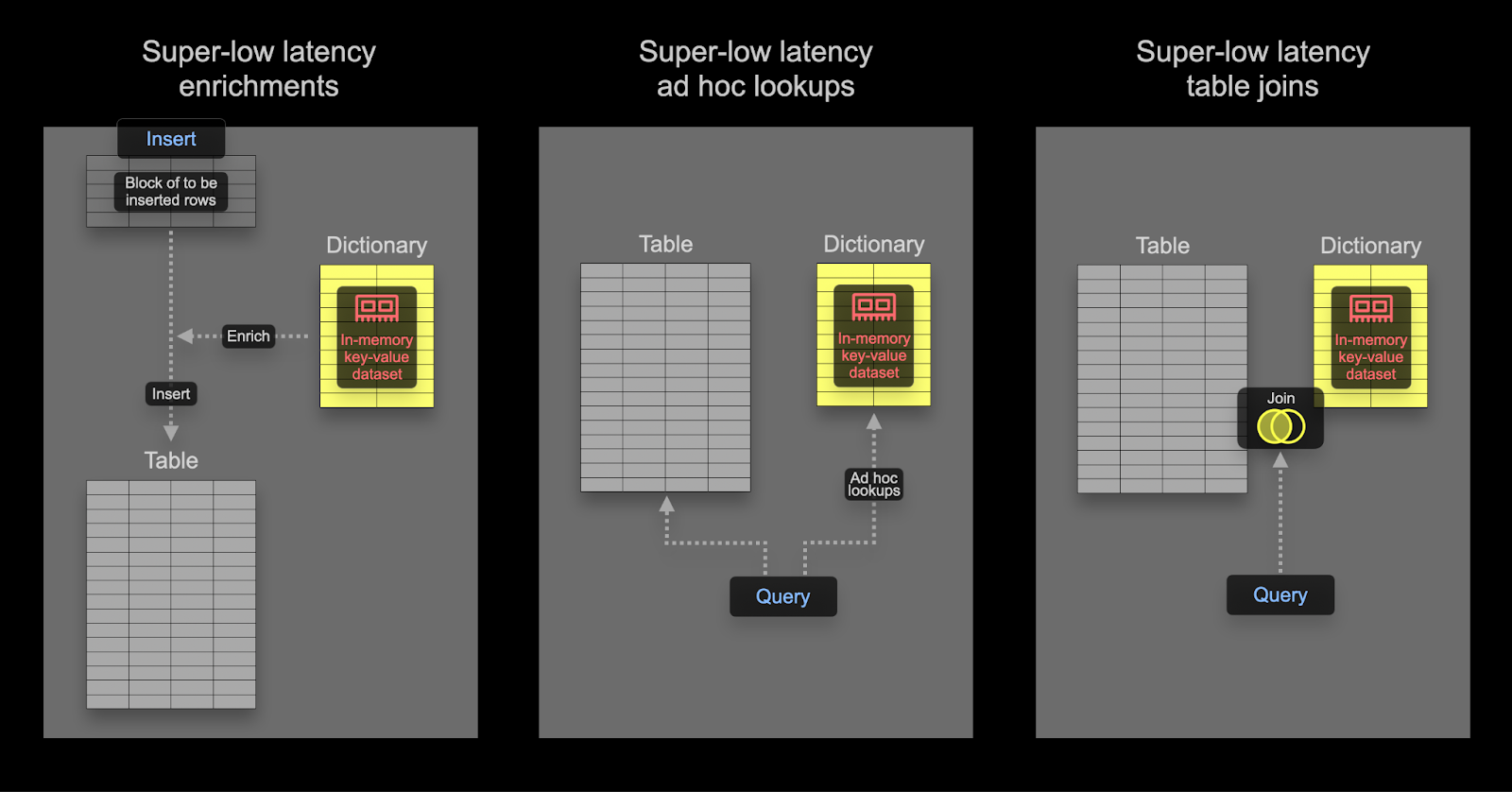
使用字典加速 Join
字典可以用于加速特定类型的 JOIN:LEFT ANY 类型,其中 join 键需要与底层键值存储的键属性匹配。
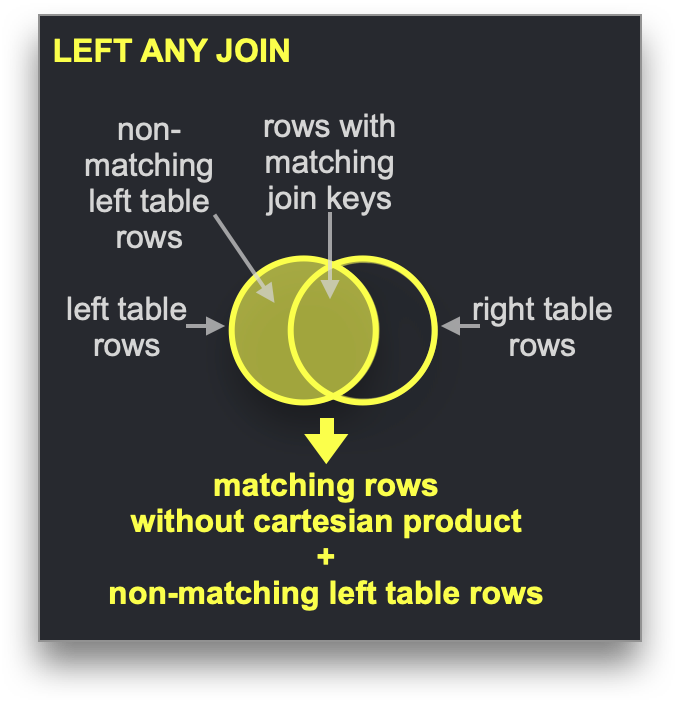
如果是这种情况,ClickHouse 可以利用字典来执行直接 Join。这是 ClickHouse 最快的 join 算法,当右侧表的底层表引擎支持低延迟键值请求时,此算法适用。ClickHouse 有三个表引擎提供此功能:Join(基本上是一个预先计算的哈希表)、EmbeddedRocksDB 和 Dictionary。我们将描述基于字典的方法,但对于所有三个引擎,机制都是相同的。
直接 join 算法要求右侧表由字典支持,以便来自该表的要 join 的数据已经以低延迟键值数据结构的形式存在于内存中。
示例
使用 Stack Overflow 数据集,让我们回答这个问题:*关于 Hacker News 上 SQL 最具争议的帖子是什么?*
我们将有争议性定义为帖子具有相似数量的赞成票和反对票。我们计算这个绝对差值,其中值越接近 0 表示争议性越大。我们假设帖子必须至少有 10 个赞成票和反对票 - 人们不投票的帖子争议性不大。
在我们的数据规范化之后,此查询当前需要使用 posts 和 votes 表进行 JOIN
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT
Id,
Title,
UpVotes,
DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
INNER JOIN
(
SELECT
PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
WHERE PostId IN (PostIds)
GROUP BY PostId
HAVING (UpVotes > 10) AND (DownVotes > 10)
) AS votes ON posts.Id = votes.PostId
WHERE Id IN (PostIds)
ORDER BY Controversial_ratio ASC
LIMIT 1
Row 1:
──────
Id: 25372161
Title: How to add exception handling to SqlDataSource.UpdateCommand
UpVotes: 13
DownVotes: 13
Controversial_ratio: 0
1 rows in set. Elapsed: 1.283 sec. Processed 418.44 million rows, 7.23 GB (326.07 million rows/s., 5.63 GB/s.)
Peak memory usage: 3.18 GiB.
在
JOIN的右侧使用较小的数据集:此查询可能看起来比需要的更冗长,PostId上的过滤发生在外部查询和子查询中。这是一种性能优化,可确保查询响应时间很快。为了获得最佳性能,请始终确保JOIN的右侧是较小的集合,并尽可能小。有关优化 JOIN 性能和了解可用算法的提示,我们建议阅读此系列博客文章。
虽然此查询速度很快,但它依赖于我们仔细编写 JOIN 以获得良好的性能。理想情况下,我们只需将帖子过滤为包含“SQL”的帖子,然后再查看博客子集的 UpVote 和 DownVote 计数来计算我们的指标。
应用字典
为了演示这些概念,我们对我们的投票数据使用字典。由于字典通常保存在内存中(ssd_cache 是例外),因此用户应注意数据的大小。确认我们的 votes 表大小
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE table IN ('votes')
GROUP BY table
┌─table───────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ votes │ 1.25 GiB │ 3.79 GiB │ 3.04 │
└─────────────────┴─────────────────┴───────────────────┴───────┘
数据将以未压缩的形式存储在我们的字典中,因此如果我们要在字典中存储所有列(我们不会),则至少需要 4GB 的内存。字典将在我们的集群中复制,因此每个节点都需要保留此内存量。
在下面的示例中,我们字典的数据来自 ClickHouse 表。虽然这代表了最常见的字典来源,但许多来源都受支持,包括文件、http 和数据库,包括 Postgres。正如我们将展示的那样,字典可以自动刷新,从而为直接 join 提供理想的方式,以确保频繁更改的小数据集可用。
我们的字典需要一个主键,将在其上执行查找。这在概念上与事务数据库主键相同,并且应该是唯一的。我们上面的查询需要查找 join 键 - PostId。字典应反过来填充我们 votes 表中每个 PostId 的赞成票和反对票总数。以下是获取此字典数据的查询
SELECT PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY PostId
要创建我们的字典,需要以下 DDL - 请注意使用我们上面的查询
CREATE DICTIONARY votes_dict
(
`PostId` UInt64,
`UpVotes` UInt32,
`DownVotes` UInt32
)
PRIMARY KEY PostId
SOURCE(CLICKHOUSE(QUERY 'SELECT PostId, countIf(VoteTypeId = 2) AS UpVotes, countIf(VoteTypeId = 3) AS DownVotes FROM votes GROUP BY PostId'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
0 rows in set. Elapsed: 36.063 sec.
在自管理的 OSS 中,上述命令需要在所有节点上执行。在 ClickHouse Cloud 中,字典将自动复制到所有节点。以上操作在具有 64GB RAM 的 ClickHouse Cloud 节点上执行,加载时间为 36 秒。
要确认我们的字典消耗的内存
SELECT formatReadableSize(bytes_allocated) AS size
FROM system.dictionaries
WHERE name = 'votes_dict'
┌─size─────┐
│ 4.00 GiB │
└──────────┘
现在可以使用简单的 dictGet 函数检索特定 PostId 的赞成票和反对票。下面我们检索帖子 11227902 的值
SELECT dictGet('votes_dict', ('UpVotes', 'DownVotes'), '11227902') AS votes
┌─votes──────┐
│ (34999,32) │
└────────────┘
Exploiting this in our earlier query, we can remove the JOIN:
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT Id, Title,
dictGet('votes_dict', 'UpVotes', Id) AS UpVotes,
dictGet('votes_dict', 'DownVotes', Id) AS DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
WHERE (Id IN (PostIds)) AND (UpVotes > 10) AND (UpVotes > 10)
ORDER BY Controversial_ratio ASC
LIMIT 3
3 rows in set. Elapsed: 0.551 sec. Processed 119.64 million rows, 3.29 GB (216.96 million rows/s., 5.97 GB/s.)
Peak memory usage: 552.26 MiB.
不仅此查询更简单,而且速度也快两倍以上!可以通过仅将赞成票和反对票超过 10 票的帖子加载到字典中,并且仅存储预先计算的有争议值来进一步优化此操作。
查询时数据丰富
字典可用于在查询时查找值。这些值可以在结果中返回或在聚合中使用。假设我们创建一个字典将用户 ID 映射到他们的位置
CREATE DICTIONARY users_dict
(
`Id` Int32,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM stackoverflow.users'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
我们可以使用此字典来丰富帖子结果
SELECT
Id,
Title,
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location
FROM posts
WHERE Title ILIKE '%clickhouse%'
LIMIT 5
FORMAT PrettyCompactMonoBlock
┌───────Id─┬─Title─────────────────────────────────────────────────────────┬─Location──────────────┐
│ 52296928 │ Comparision between two Strings in ClickHouse │ Spain │
│ 52345137 │ How to use a file to migrate data from mysql to a clickhouse? │ 中国江苏省Nanjing Shi │
│ 61452077 │ How to change PARTITION in clickhouse │ Guangzhou, 广东省中国 │
│ 55608325 │ Clickhouse select last record without max() on all table │ Moscow, Russia │
│ 55758594 │ ClickHouse create temporary table │ Perm', Russia │
└──────────┴───────────────────────────────────────────────────────────────┴───────────────────────┘
5 rows in set. Elapsed: 0.033 sec. Processed 4.25 million rows, 82.84 MB (130.62 million rows/s., 2.55 GB/s.)
Peak memory usage: 249.32 MiB.
与我们上面的 join 示例类似,我们可以使用相同的字典来有效确定大多数帖子来自哪里
SELECT
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location,
count() AS c
FROM posts
WHERE location != ''
GROUP BY location
ORDER BY c DESC
LIMIT 5
┌─location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
│ United Kingdom │ 537699 │
└────────────────────────┴────────┘
5 rows in set. Elapsed: 0.763 sec. Processed 59.82 million rows, 239.28 MB (78.40 million rows/s., 313.60 MB/s.)
Peak memory usage: 248.84 MiB.
索引时数据丰富
在上面的示例中,我们在查询时使用字典来删除 join。字典还可用于在插入时丰富行。如果丰富值不更改并且存在于可用于填充字典的外部来源中,则通常适用这种情况。在这种情况下,在插入时丰富行可以避免查询时查找字典。
假设 Stack Overflow 中用户的 Location 永远不会更改(实际上会更改) - 特别是 users 表的 Location 列。假设我们想按位置对帖子表执行分析查询。这包含一个 UserId。
字典提供了从用户 ID 到位置的映射,由 users 表支持
CREATE DICTIONARY users_dict
(
`Id` UInt64,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM users WHERE Id >= 0'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
我们省略了
Id < 0的用户,从而允许我们使用Hashed字典类型。Id < 0的用户是系统用户。
为了在插入帖子表时利用此字典,我们需要修改架构
CREATE TABLE posts_with_location
(
`Id` UInt32,
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
…
`Location` MATERIALIZED dictGet(users_dict, 'Location', OwnerUserId::'UInt64')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
在上面的示例中,Location 被声明为 MATERIALIZED 列。这意味着该值可以作为 INSERT 查询的一部分提供,并且将始终被计算。
ClickHouse 还支持
DEFAULT列(如果未提供值,则可以插入或计算该值)。
要填充表,我们可以使用常用的 INSERT INTO SELECT 从 S3
INSERT INTO posts_with_location SELECT Id, PostTypeId::UInt8, AcceptedAnswerId, CreationDate, Score, ViewCount, Body, OwnerUserId, OwnerDisplayName, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Title, Tags, AnswerCount, CommentCount, FavoriteCount, ContentLicense, ParentId, CommunityOwnedDate, ClosedDate FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 36.830 sec. Processed 238.98 million rows, 2.64 GB (6.49 million rows/s., 71.79 MB/s.)
我们现在可以获得大多数帖子来自的位置名称
SELECT Location, count() AS c
FROM posts_with_location
WHERE Location != ''
GROUP BY Location
ORDER BY c DESC
LIMIT 4
┌─Location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
└────────────────────────┴────────┘
4 rows in set. Elapsed: 0.142 sec. Processed 59.82 million rows, 1.08 GB (420.73 million rows/s., 7.60 GB/s.)
Peak memory usage: 666.82 MiB.
高级字典主题
选择字典 LAYOUT
LAYOUT 子句控制字典的内部数据结构。存在许多选项,并在此处记录。有关选择正确布局的一些提示,请访问 此处。
刷新字典
我们为字典指定了 LIFETIME 为 MIN 600 MAX 900。LIFETIME 是字典的更新间隔,此处的值会导致在 600 到 900 秒之间的随机间隔内定期重新加载。这种随机间隔是必要的,以便在大量服务器上更新时分散字典源上的负载。在更新期间,旧版本的字典仍然可以查询,只有初始加载会阻止查询。请注意,设置 (LIFETIME(0)) 会阻止字典更新。可以使用 SYSTEM RELOAD DICTIONARY 命令强制重新加载字典。
对于诸如 ClickHouse 和 Postgres 之类的数据库源,您可以设置一个查询,该查询仅在字典确实更改时(查询的响应确定这一点)而不是定期间隔更新字典。更多详细信息可以在此处找到。