回填数据
无论是 ClickHouse 新手还是负责现有部署的用户,都不可避免地需要使用历史数据回填表。在某些情况下,这相对简单,但当需要填充物化视图时,可能会变得更加复杂。本指南记录了用户可以应用于其用例的一些此任务流程。
本指南假定用户已经熟悉增量物化视图的概念以及使用表函数(如 s3 和 gcs)加载数据。我们还建议用户阅读我们的优化从对象存储插入性能指南,其中的建议可以应用于本指南中的所有插入。
示例数据集
在本指南中,我们使用 PyPI 数据集。此数据集中的每一行代表使用 pip 等工具下载的 Python 软件包。
例如,该子集涵盖了一天 - 2024-12-17,并且在 https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/ 上公开可用。用户可以使用以下命令查询
SELECT count()
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/*.parquet')
┌────count()─┐
│ 2039988137 │ -- 2.04 billion
└────────────┘
1 row in set. Elapsed: 32.726 sec. Processed 2.04 billion rows, 170.05 KB (62.34 million rows/s., 5.20 KB/s.)
Peak memory usage: 239.50 MiB.
此存储桶的完整数据集包含超过 320 GB 的 Parquet 文件。在下面的示例中,我们有意使用 glob 模式定位子集。
我们假设用户正在使用此数据流,例如来自 Kafka 或对象存储,用于此日期之后的数据。此数据的模式如下所示
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/*.parquet')
FORMAT PrettyCompactNoEscapesMonoBlock
SETTINGS describe_compact_output = 1
┌─name───────────────┬─type────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ timestamp │ Nullable(DateTime64(6)) │
│ country_code │ Nullable(String) │
│ url │ Nullable(String) │
│ project │ Nullable(String) │
│ file │ Tuple(filename Nullable(String), project Nullable(String), version Nullable(String), type Nullable(String)) │
│ installer │ Tuple(name Nullable(String), version Nullable(String)) │
│ python │ Nullable(String) │
│ implementation │ Tuple(name Nullable(String), version Nullable(String)) │
│ distro │ Tuple(name Nullable(String), version Nullable(String), id Nullable(String), libc Tuple(lib Nullable(String), version Nullable(String))) │
│ system │ Tuple(name Nullable(String), release Nullable(String)) │
│ cpu │ Nullable(String) │
│ openssl_version │ Nullable(String) │
│ setuptools_version │ Nullable(String) │
│ rustc_version │ Nullable(String) │
│ tls_protocol │ Nullable(String) │
│ tls_cipher │ Nullable(String) │
└────────────────────┴─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
完整的 PyPI 数据集包含超过 1 万亿行,可在我们的公共演示环境 clickpy.clickhouse.com 中找到。有关此数据集的更多详细信息,包括演示如何利用物化视图来提高性能以及如何每日填充数据,请参阅此处。
回填场景
当从时间点开始使用数据流时,通常需要回填。此数据正被插入到带有增量物化视图的 ClickHouse 表中,在插入块时触发。这些视图可能会在插入之前转换数据或计算聚合,并将结果发送到目标表,以便稍后在下游应用程序中使用。
我们将尝试涵盖以下场景
- 使用现有数据摄取回填数据 - 正在加载新数据,并且需要回填历史数据。已识别出此历史数据。
- 向现有表添加物化视图 - 需要为已填充历史数据且数据已在流式传输的设置添加新的物化视图。
我们假设将从对象存储回填数据。在所有情况下,我们的目标是避免暂停数据插入。
我们建议从对象存储回填历史数据。数据应尽可能导出到 Parquet 以获得最佳读取性能和压缩(减少网络传输)。通常首选约 150MB 的文件大小,但 ClickHouse 支持超过 70 种文件格式,并且能够处理所有大小的文件。
使用重复表和视图
对于所有场景,我们都依赖“重复表和视图”的概念。这些表和视图代表用于实时流式传输数据的表和视图的副本,并允许隔离执行回填,并在发生故障时轻松恢复。例如,我们有以下主 pypi 表和物化视图,它们计算每个 Python 项目的下载次数
CREATE TABLE pypi
(
`timestamp` DateTime,
`country_code` LowCardinality(String),
`project` String,
`type` LowCardinality(String),
`installer` LowCardinality(String),
`python_minor` LowCardinality(String),
`system` LowCardinality(String),
`on` String
)
ENGINE = MergeTree
ORDER BY (project, timestamp)
CREATE TABLE pypi_downloads
(
`project` String,
`count` Int64
)
ENGINE = SummingMergeTree
ORDER BY project
CREATE MATERIALIZED VIEW pypi_downloads_mv TO pypi_downloads
AS SELECT
project,
count() AS count
FROM pypi
GROUP BY project
我们使用数据的子集填充主表和关联的视图
INSERT INTO pypi SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-000000000{000..100}.parquet')
0 rows in set. Elapsed: 15.702 sec. Processed 41.23 million rows, 3.94 GB (2.63 million rows/s., 251.01 MB/s.)
Peak memory usage: 977.49 MiB.
SELECT count() FROM pypi
┌──count()─┐
│ 20612750 │ -- 20.61 million
└──────────┘
1 row in set. Elapsed: 0.004 sec.
SELECT sum(count)
FROM pypi_downloads
┌─sum(count)─┐
│ 20612750 │ -- 20.61 million
└────────────┘
1 row in set. Elapsed: 0.006 sec. Processed 96.15 thousand rows, 769.23 KB (16.53 million rows/s., 132.26 MB/s.)
Peak memory usage: 682.38 KiB.
假设我们希望加载另一个子集 {101..200}。虽然我们可以直接插入到 pypi 中,但我们可以通过创建重复表来隔离执行此回填。
如果回填失败,我们不会影响主表,只需截断重复表并重复即可。
要创建这些视图的新副本,我们可以使用带有后缀 _v2 的 CREATE TABLE AS 子句
CREATE TABLE pypi_v2 AS pypi
CREATE TABLE pypi_downloads_v2 AS pypi_downloads
CREATE MATERIALIZED VIEW pypi_downloads_mv_v2 TO pypi_downloads_v2
AS SELECT
project,
count() AS count
FROM pypi_v2
GROUP BY project
我们使用大约相同大小的第二个子集填充它,并确认加载成功。
INSERT INTO pypi_v2 SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-000000000{101..200}.parquet')
0 rows in set. Elapsed: 17.545 sec. Processed 40.80 million rows, 3.90 GB (2.33 million rows/s., 222.29 MB/s.)
Peak memory usage: 991.50 MiB.
SELECT count()
FROM pypi_v2
┌──count()─┐
│ 20400020 │ -- 20.40 million
└──────────┘
1 row in set. Elapsed: 0.004 sec.
SELECT sum(count)
FROM pypi_downloads_v2
┌─sum(count)─┐
│ 20400020 │ -- 20.40 million
└────────────┘
1 row in set. Elapsed: 0.006 sec. Processed 95.49 thousand rows, 763.90 KB (14.81 million rows/s., 118.45 MB/s.)
Peak memory usage: 688.77 KiB.
如果我们在第二次加载期间的任何时候遇到故障,我们可以简单地截断我们的 pypi_v2 和 pypi_downloads_v2 并重复数据加载。
数据加载完成后,我们可以使用 ALTER TABLE MOVE PARTITION 子句将数据从重复表移动到主表。
ALTER TABLE pypi
(MOVE PARTITION () FROM pypi_v2)
0 rows in set. Elapsed: 1.401 sec.
ALTER TABLE pypi_downloads
(MOVE PARTITION () FROM pypi_downloads_v2)
0 rows in set. Elapsed: 0.389 sec.
上面的 MOVE PARTITION 调用使用分区名称 ()。这表示此表的单个分区(未分区)。对于已分区的表,用户需要调用多个 MOVE PARTITION 调用 - 每个分区一个。当前分区的名称可以从 system.parts 表中建立,例如 SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2')。
我们现在可以确认 pypi 和 pypi_downloads 包含完整的数据。可以安全地删除 pypi_downloads_v2 和 pypi_v2。
SELECT count()
FROM pypi
┌──count()─┐
│ 41012770 │ -- 41.01 million
└──────────┘
1 row in set. Elapsed: 0.003 sec.
SELECT sum(count)
FROM pypi_downloads
┌─sum(count)─┐
│ 41012770 │ -- 41.01 million
└────────────┘
1 row in set. Elapsed: 0.007 sec. Processed 191.64 thousand rows, 1.53 MB (27.34 million rows/s., 218.74 MB/s.)
SELECT count()
FROM pypi_v2
重要的是,MOVE PARTITION 操作既轻量级(利用硬链接)又是原子性的,即它要么失败,要么成功,没有中间状态。
我们在下面的回填场景中大量利用此流程。
请注意,此流程要求用户选择每次插入操作的大小。
较大的插入,即更多的行,意味着需要较少的 MOVE PARTITION 操作。但是,这必须与发生插入失败(例如,由于网络中断)时的恢复成本相平衡。用户可以使用批处理文件来补充此流程,以降低风险。这可以使用范围查询(例如,WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00)或 glob 模式来执行。例如,
INSERT INTO pypi_v2 SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-000000000{101..200}.parquet')
INSERT INTO pypi_v2 SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-000000000{201..300}.parquet')
INSERT INTO pypi_v2 SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-000000000{301..400}.parquet')
--continued to all files loaded OR MOVE PARTITION call is performed
ClickPipes 在从对象存储加载数据时使用此方法,自动创建目标表及其物化视图的副本,并避免用户执行上述步骤。通过还使用多个工作线程,每个线程处理不同的子集(通过 glob 模式)并具有自己的重复表,可以快速加载数据,并具有精确一次的语义。对于那些感兴趣的人,可以在此博客中找到更多详细信息。
场景 1:使用现有数据摄取回填数据
在此场景中,我们假设要回填的数据不在隔离的存储桶中,因此需要过滤。数据已在插入,并且可以从其中识别出需要回填历史数据的时间戳或单调递增列。
此过程遵循以下步骤
- 识别检查点 - 需要从中恢复历史数据的时间戳或列值。
- 创建主表和物化视图目标表的重复项。
- 创建指向步骤 (2) 中创建的目标表的任何物化视图的副本。
- 插入到步骤 (2) 中创建的重复主表中。
- 将所有分区从重复表移动到其原始版本。删除重复表。
例如,在我们的 PyPI 数据中,假设我们已加载数据。我们可以识别最小时间戳,从而识别我们的“检查点”。
SELECT min(timestamp)
FROM pypi
┌──────min(timestamp)─┐
│ 2024-12-17 09:00:00 │
└─────────────────────┘
1 row in set. Elapsed: 0.163 sec. Processed 1.34 billion rows, 5.37 GB (8.24 billion rows/s., 32.96 GB/s.)
Peak memory usage: 227.84 MiB.
从上面,我们知道我们需要加载 2024-12-17 09:00:00 之前的数据。使用我们之前的流程,我们创建重复表和视图,并使用时间戳过滤器加载子集。
CREATE TABLE pypi_v2 AS pypi
CREATE TABLE pypi_downloads_v2 AS pypi_downloads
CREATE MATERIALIZED VIEW pypi_downloads_mv_v2 TO pypi_downloads_v2
AS SELECT project, count() AS count
FROM pypi_v2
GROUP BY project
INSERT INTO pypi_v2 SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/1734393600-*.parquet')
WHERE timestamp < '2024-12-17 09:00:00'
0 rows in set. Elapsed: 500.152 sec. Processed 2.74 billion rows, 364.40 GB (5.47 million rows/s., 728.59 MB/s.)
在 Parquet 中过滤时间戳列可能非常高效。ClickHouse 将仅读取时间戳列以识别要加载的完整数据范围,从而最大限度地减少网络流量。ClickHouse 查询引擎也可以利用 Parquet 索引,例如 min-max。
一旦此插入完成,我们可以移动关联的分区。
ALTER TABLE pypi
(MOVE PARTITION () FROM pypi_v2)
ALTER TABLE pypi_downloads
(MOVE PARTITION () FROM pypi_downloads_v2)
如果历史数据是隔离的存储桶,则不需要上述时间过滤器。如果时间或单调列不可用,请隔离您的历史数据。
如果数据可以隔离在其自己的存储桶中(并且不需要过滤器),ClickHouse Cloud 用户应使用 ClickPipes 恢复历史备份。除了使用多个工作线程并行化加载,从而减少加载时间外,ClickPipes 还自动化了上述流程 - 为主表和物化视图创建重复表。
场景 2:向现有表添加物化视图
对于需要为已填充大量数据并且正在插入数据的设置添加新的物化视图的情况并不少见。时间戳或单调递增列(可用于识别流中的某个点)在此处很有用,并且可以避免暂停数据摄取。在下面的示例中,我们假设两种情况,优先选择避免暂停摄取的方法。
对于除暂停摄取的小型数据集之外的任何内容,我们不建议使用 POPULATE 命令来回填物化视图。此运算符可能会遗漏插入到其源表中的行,物化视图在填充哈希完成后创建。此外,此填充针对所有数据运行,并且容易受到大型数据集的中断或内存限制的影响。
时间戳或单调递增列可用
在这种情况下,我们建议新的物化视图包含一个过滤器,该过滤器将行限制为大于未来任意数据的行。随后可以使用主表中的历史数据从此日期回填物化视图。回填方法取决于数据大小和关联查询的复杂性。
我们最简单的方法包括以下步骤
- 创建我们的物化视图,并使用一个过滤器,该过滤器仅考虑大于不久的将来的任意时间的行。
- 运行一个
INSERT INTO SELECT查询,该查询将插入到我们的物化视图的目标表中,并从源表中读取视图的聚合查询。
可以进一步增强此功能,以定位步骤 (2) 中的数据子集和/或为物化视图使用重复目标表(在插入完成后将分区附加到原始表),以便在失败后更轻松地恢复。
考虑以下物化视图,该视图计算每小时最受欢迎的项目。
CREATE TABLE pypi_downloads_per_day
(
`hour` DateTime,
`project` String,
`count` Int64
)
ENGINE = SummingMergeTree
ORDER BY (project, hour)
CREATE MATERIALIZED VIEW pypi_downloads_per_day_mv TO pypi_downloads_per_day
AS SELECT
toStartOfHour(timestamp) as hour,
project,
count() AS count
FROM pypi
GROUP BY
hour,
project
虽然我们可以在添加物化视图之前添加目标表,但我们修改其 SELECT 子句以包含一个过滤器,该过滤器仅考虑大于不久的将来的任意时间的行 - 在这种情况下,我们假设 2024-12-17 09:00:00 是未来几分钟。
CREATE MATERIALIZED VIEW pypi_downloads_per_day_mv TO pypi_downloads_per_day
AS SELECT
toStartOfHour(timestamp) as hour,
project, count() AS count
FROM pypi WHERE timestamp >= '2024-12-17 09:00:00'
GROUP BY hour, project
添加此视图后,我们可以回填此数据之前的所有物化视图数据。
最简单的方法是简单地在主表上运行物化视图中的查询,并使用忽略最近添加的数据的过滤器,通过 INSERT INTO SELECT 将结果插入到视图的目标表中。例如,对于上面的视图
INSERT INTO pypi_downloads_per_day SELECT
toStartOfHour(timestamp) AS hour,
project,
count() AS count
FROM pypi
WHERE timestamp < '2024-12-17 09:00:00'
GROUP BY
hour,
project
Ok.
0 rows in set. Elapsed: 2.830 sec. Processed 798.89 million rows, 17.40 GB (282.28 million rows/s., 6.15 GB/s.)
Peak memory usage: 543.71 MiB.
在上面的示例中,我们的目标表是 SummingMergeTree。在这种情况下,我们可以简单地使用我们原始的聚合查询。对于更复杂的用例,这些用例利用了 AggregatingMergeTree,用户将使用 -State 函数进行聚合。可以在此处找到示例。
在我们的例子中,这是一个相对轻量级的聚合,在 3 秒内完成,并且使用的内存少于 600MiB。对于更复杂或运行时间更长的聚合,用户可以使用更早的重复表方法使此过程更具弹性,即创建影子目标表,例如 pypi_downloads_per_day_v2,插入到其中,并将其结果分区附加到 pypi_downloads_per_day。
通常,物化视图的查询可能更复杂(否则用户不会使用视图!),并且会消耗资源。在极少数情况下,查询的资源超出了服务器的资源。这突出了 ClickHouse 物化视图的优势之一 - 它们是增量的,不会一次处理整个数据集!
在这种情况下,用户有几个选项
- 修改您的查询以回填范围,例如
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00、WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00等。 - 使用 Null 表引擎填充物化视图。这复制了物化视图的典型增量填充,在其查询的数据块(大小可配置)上执行。
(1)表示最简单的方法通常就足够了。为简洁起见,我们不包含示例。
我们在下面进一步探讨(2)。
使用 Null 表引擎填充物化视图
Null 表引擎提供了一个不持久化数据的存储引擎(可以将其视为表引擎世界的 /dev/null)。虽然这看起来是矛盾的,但物化视图仍将在插入到此表引擎的数据上执行。这允许构建物化视图,而无需持久化原始数据 - 避免 I/O 和关联的存储。
重要的是,附加到表引擎的任何物化视图仍然在其插入的数据块上执行 - 将其结果发送到目标表。这些块的大小是可配置的。虽然较大的块可能更有效(并且处理速度更快),但它们会消耗更多资源(主要是内存)。使用此表引擎意味着我们可以增量构建物化视图,即一次一个块,从而避免需要将整个聚合保存在内存中。
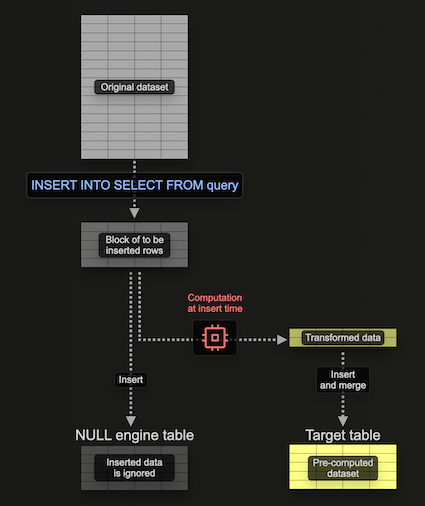
考虑以下示例
CREATE TABLE pypi_v2
(
`timestamp` DateTime,
`project` String
)
ENGINE = Null
CREATE MATERIALIZED VIEW pypi_downloads_per_day_mv_v2 TO pypi_downloads_per_day
AS SELECT
toStartOfHour(timestamp) as hour,
project,
count() AS count
FROM pypi_v2
GROUP BY
hour,
project
在这里,我们创建一个 Null 表 pypi_v2,以接收将用于构建物化视图的行。请注意,我们如何将模式限制为仅我们需要的列。我们的物化视图对插入到此表中的行(一次一个块)执行聚合,并将结果发送到我们的目标表 pypi_downloads_per_day。
我们在此处使用了 pypi_downloads_per_day 作为我们的目标表。为了获得额外的弹性,用户可以创建一个重复表 pypi_downloads_per_day_v2,并将其用作视图的目标表,如前面的示例所示。在插入完成后,pypi_downloads_per_day_v2 中的分区可以依次移动到 pypi_downloads_per_day。这将允许在我们的插入由于内存问题或服务器中断而失败的情况下进行恢复,即我们只需截断 pypi_downloads_per_day_v2,调整设置,然后重试。
要填充此物化视图,我们只需将要回填的相关数据从 pypi 插入到 pypi_v2。
INSERT INTO pypi_v2 SELECT timestamp, project FROM pypi WHERE timestamp < '2024-12-17 09:00:00'
0 rows in set. Elapsed: 27.325 sec. Processed 1.50 billion rows, 33.48 GB (54.73 million rows/s., 1.23 GB/s.)
Peak memory usage: 639.47 MiB.
请注意,此处的内存使用量为 639.47 MiB。
调整性能和资源
几个因素将决定上述场景中的性能和使用的资源。我们建议读者在尝试调整之前,先了解此处详细记录的插入机制。总结如下
- 读取并行度 - 用于读取的线程数。通过
max_threads控制。在 ClickHouse Cloud 中,这由实例大小决定,默认值为 vCPU 的数量。增加此值可能会提高读取性能,但会增加内存使用量。 - 插入并行度 - 用于插入的插入线程数。通过
max_insert_threads控制。在 ClickHouse Cloud 中,这由实例大小(介于 2 和 4 之间)决定,在 OSS 中设置为 1。增加此值可能会提高性能,但会增加内存使用量。 - 插入块大小 - 数据在一个循环中处理,在该循环中,数据被拉取、解析并根据分区键形成内存中的插入块。这些块经过排序、优化、压缩,并作为新的数据 parts写入存储。插入块的大小由设置
min_insert_block_size_rows和min_insert_block_size_bytes(未压缩)控制,它会影响内存使用量和磁盘 I/O。较大的块使用更多的内存,但创建的 parts 更少,从而减少 I/O 和后台合并。这些设置表示最小阈值(无论哪个先达到都会触发刷新)。 - 物化视图块大小 - 除了主插入的上述机制外,在插入到物化视图之前,还会压缩块以提高处理效率。这些块的大小由设置
min_insert_block_size_bytes_for_materialized_views和min_insert_block_size_rows_for_materialized_views确定。较大的块允许更高效的处理,但会增加内存使用量。默认情况下,这些设置恢复为源表设置min_insert_block_size_rows和min_insert_block_size_bytes的值。
为了提高性能,用户可以参考此处概述的指南。在大多数情况下,无需修改min_insert_block_size_bytes_for_materialized_views和min_insert_block_size_rows_for_materialized_views也能提高性能。如果修改了这些设置,请遵循与min_insert_block_size_rows和min_insert_block_size_bytes相同的最佳实践。
为了最大限度地减少内存占用,用户可能希望尝试调整这些设置。但这将不可避免地降低性能。我们使用之前的查询,在下面展示一些示例。
将max_insert_threads降低到 1 可以减少我们的内存开销。
INSERT INTO pypi_v2
SELECT
timestamp,
project
FROM pypi
WHERE timestamp < '2024-12-17 09:00:00'
SETTINGS max_insert_threads = 1
0 rows in set. Elapsed: 27.752 sec. Processed 1.50 billion rows, 33.48 GB (53.89 million rows/s., 1.21 GB/s.)
Peak memory usage: 506.78 MiB.
我们可以通过将max_threads设置降低到 1 来进一步降低内存占用。
INSERT INTO pypi_v2
SELECT timestamp, project
FROM pypi
WHERE timestamp < '2024-12-17 09:00:00'
SETTINGS max_insert_threads = 1, max_threads = 1
Ok.
0 rows in set. Elapsed: 43.907 sec. Processed 1.50 billion rows, 33.48 GB (34.06 million rows/s., 762.54 MB/s.)
Peak memory usage: 272.53 MiB.
最后,我们可以通过将min_insert_block_size_rows设置为 0(禁用其作为块大小的决定因素)并将min_insert_block_size_bytes设置为 10485760 (10MiB) 来进一步减少内存占用。
INSERT INTO pypi_v2
SELECT
timestamp,
project
FROM pypi
WHERE timestamp < '2024-12-17 09:00:00'
SETTINGS max_insert_threads = 1, max_threads = 1, min_insert_block_size_rows = 0, min_insert_block_size_bytes = 10485760
0 rows in set. Elapsed: 43.293 sec. Processed 1.50 billion rows, 33.48 GB (34.54 million rows/s., 773.36 MB/s.)
Peak memory usage: 218.64 MiB.
最后,请注意,降低块大小会产生更多的数据 part 并导致更大的合并压力。正如此处讨论的那样,应谨慎更改这些设置。
没有时间戳或单调递增列
以上过程依赖于用户拥有时间戳或单调递增列。在某些情况下,这可能不可用。在这种情况下,我们推荐以下流程,该流程利用了前面概述的许多步骤,但需要用户暂停数据摄取。
- 暂停向主表的插入操作。
- 使用
CREATE AS语法创建主目标表的副本。 - 使用
ALTER TABLE ATTACH将原始目标表的分区附加到副本。注意:此附加操作与之前使用的移动操作不同。虽然依赖于硬链接,但原始表中的数据得以保留。 - 创建新的物化视图。
- 重新启动插入操作。注意:插入操作只会更新目标表,而不会更新副本,副本将仅引用原始数据。
- 回填物化视图,应用与上述针对具有时间戳的数据相同的流程,并使用副本表作为源。
考虑以下使用 PyPI 和我们之前新的物化视图 pypi_downloads_per_day 的示例(我们假设我们无法使用时间戳)
SELECT count() FROM pypi
┌────count()─┐
│ 2039988137 │ -- 2.04 billion
└────────────┘
1 row in set. Elapsed: 0.003 sec.
-- (1) Pause inserts
-- (2) Create a duplicate of our target table
CREATE TABLE pypi_v2 AS pypi
SELECT count() FROM pypi_v2
┌────count()─┐
│ 2039988137 │ -- 2.04 billion
└────────────┘
1 row in set. Elapsed: 0.004 sec.
-- (3) Attach partitions from the original target table to the duplicate.
ALTER TABLE pypi_v2
(ATTACH PARTITION tuple() FROM pypi)
-- (4) Create our new materialized views
CREATE TABLE pypi_downloads_per_day
(
`hour` DateTime,
`project` String,
`count` Int64
)
ENGINE = SummingMergeTree
ORDER BY (project, hour)
CREATE MATERIALIZED VIEW pypi_downloads_per_day_mv TO pypi_downloads_per_day
AS SELECT
toStartOfHour(timestamp) as hour,
project,
count() AS count
FROM pypi
GROUP BY
hour,
project
-- (4) Restart inserts. We replicate here by inserting a single row.
INSERT INTO pypi SELECT *
FROM pypi
LIMIT 1
SELECT count() FROM pypi
┌────count()─┐
│ 2039988138 │ -- 2.04 billion
└────────────┘
1 row in set. Elapsed: 0.003 sec.
-- notice how pypi_v2 contains same number of rows as before
SELECT count() FROM pypi_v2
┌────count()─┐
│ 2039988137 │ -- 2.04 billion
└────────────┘
-- (5) Backfill the view using the backup pypi_v2
INSERT INTO pypi_downloads_per_day SELECT
toStartOfHour(timestamp) as hour,
project,
count() AS count
FROM pypi_v2
GROUP BY
hour,
project
0 rows in set. Elapsed: 3.719 sec. Processed 2.04 billion rows, 47.15 GB (548.57 million rows/s., 12.68 GB/s.)
DROP TABLE pypi_v2;
在倒数第二步中,我们使用之前描述的简单 INSERT INTO SELECT 方法回填 pypi_downloads_per_day。也可以使用上面记录的 Null 表方法来增强此操作,并可选择使用副本表以提高弹性。
虽然此操作确实需要暂停插入操作,但中间操作通常可以快速完成,从而最大限度地减少任何数据中断。