优化 S3 插入和读取性能
本节重点介绍在使用 s3 表函数从 S3 读取和插入数据时如何优化性能。
本指南中描述的课程可以应用于其他对象存储实现,它们有自己的专用表函数,例如 GCS 和 Azure Blob storage。
在调整线程和块大小以提高插入性能之前,我们建议用户了解 S3 插入的机制。如果您熟悉插入机制,或者只是想要一些快速提示,请跳到下面的示例。
插入机制(单节点)
除了硬件大小之外,还有两个主要因素影响 ClickHouse 的数据插入机制(对于单节点)的性能和资源使用情况:插入块大小和插入并行度。
插入块大小
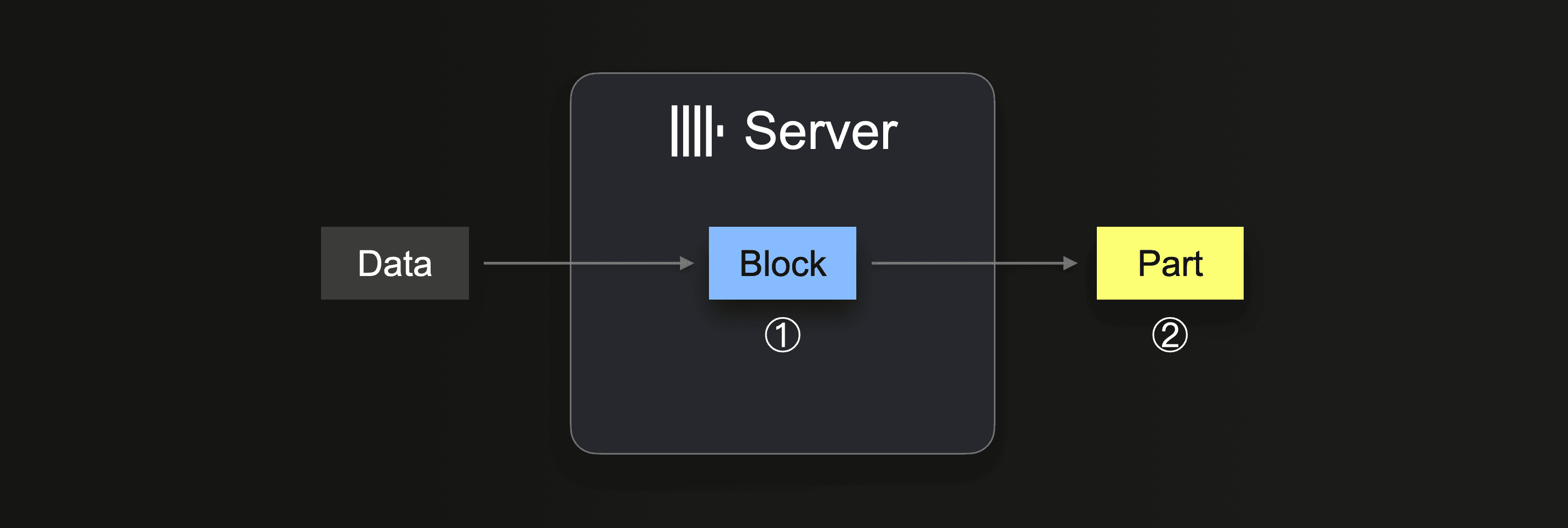
当执行 INSERT INTO SELECT 时,ClickHouse 接收一些数据部分,并从接收到的数据中形成(至少)一个内存中的插入块(每个 分区键)。块的数据被排序,并应用特定于表引擎的优化。然后,数据被压缩并以新数据 part 的形式写入数据库存储中的 ②。
插入块大小会影响 ClickHouse 服务器的 磁盘文件 I/O 使用率和内存使用率。较大的插入块使用更多内存,但生成更大且更少的初始 part。ClickHouse 为加载大量数据需要创建的 part 越少,磁盘文件 I/O 和自动 后台合并 就越少。
当将 INSERT INTO SELECT 查询与集成表引擎或表函数结合使用时,数据由 ClickHouse 服务器拉取
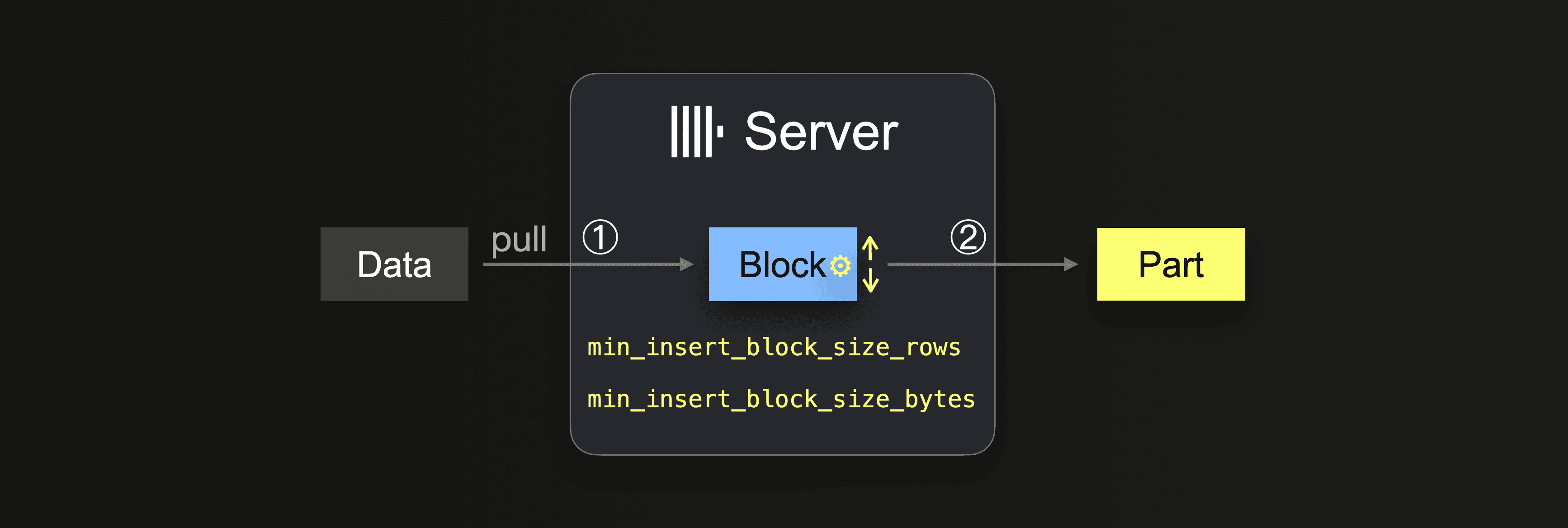
在数据完全加载之前,服务器执行一个循环
① Pull and parse the next portion of data and form an in-memory data block (one per partitioning key) from it.
② Write the block into a new part on storage.
Go to ①
在 ① 中,大小取决于插入块大小,这可以通过两个设置来控制
min_insert_block_size_rows(默认值:1048545百万行)min_insert_block_size_bytes(默认值:256 MiB)
当插入块中收集到指定的行数,或达到配置的数据量(以先发生者为准)时,将触发将该块写入新的 part。插入循环在步骤 ① 继续。
请注意,min_insert_block_size_bytes 值表示未压缩的内存中块大小(而不是压缩的磁盘上 part 大小)。另请注意,创建的块和 part 很少精确地包含配置的行数或字节数,因为 ClickHouse 流式传输和 处理 数据行-块式数据。因此,这些设置指定了最小阈值。
注意合并
配置的插入块大小越小,为大型数据加载创建的初始 part 就越多,与数据摄取同时执行的后台 part 合并就越多。这可能会导致资源争用(CPU 和内存),并需要额外的时间(在摄取完成后达到 健康 (3000) 的 part 数量)。
如果 part 计数超过 建议的限制,ClickHouse 查询性能将受到负面影响。
ClickHouse 将持续将 part 合并为更大的 part,直到它们 达到 约 150 GiB 的压缩大小。此图表显示了 ClickHouse 服务器如何合并 part
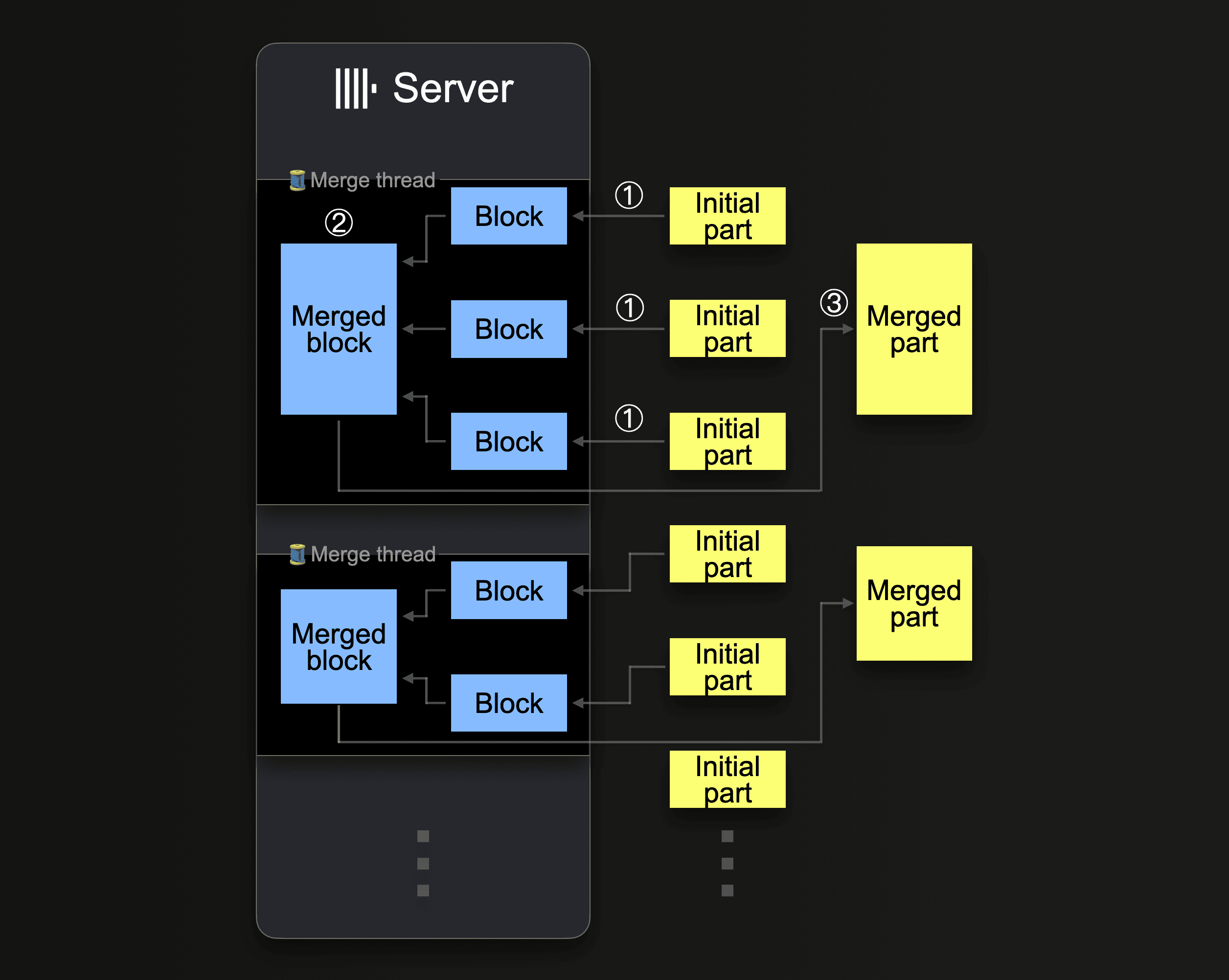
单个 ClickHouse 服务器利用多个 后台合并线程 来执行并发的 part 合并。每个线程执行一个循环
① Decide which parts to merge next, and load these parts as blocks into memory.
② Merge the loaded blocks in memory into a larger block.
③ Write the merged block into a new part on disk.
Go to ①
请注意,增加 CPU 核心数和 RAM 大小会提高后台合并吞吐量。
合并为更大 part 的 part 被标记为 非活动,并在 可配置 的分钟数后最终删除。随着时间的推移,这将创建一个合并 part 树(因此得名 MergeTree 表)。
插入并行度
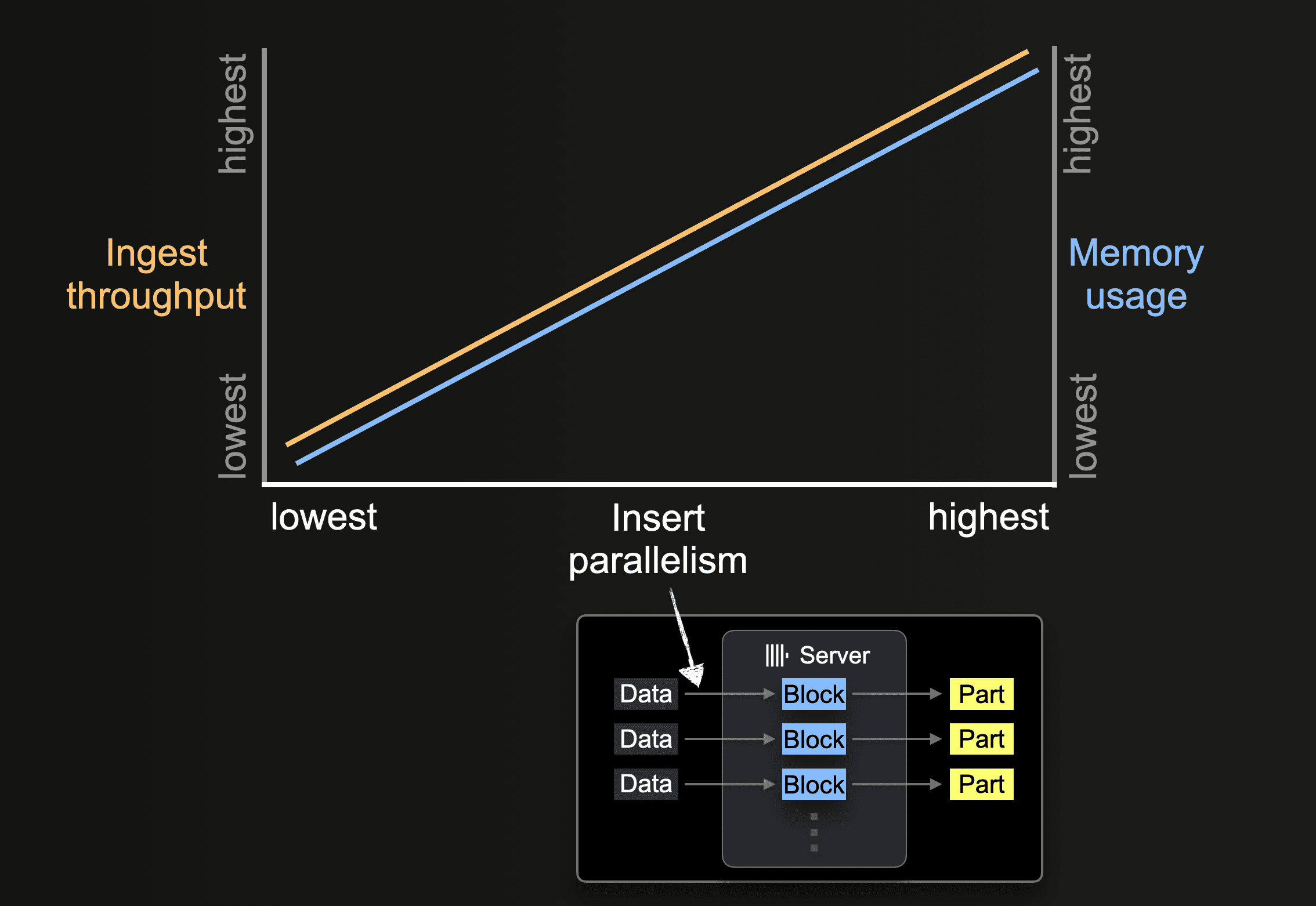
ClickHouse 服务器可以并行处理和插入数据。插入并行度级别会影响 ClickHouse 服务器的摄取吞吐量和内存使用率。并行加载和处理数据需要更多主内存,但由于数据处理速度更快,因此可以提高摄取吞吐量。
像 s3 这样的表函数允许通过 glob 模式指定要加载的文件名集。当 glob 模式匹配多个现有文件时,ClickHouse 可以并行化跨文件和文件内的读取,并通过利用并行运行的插入线程(每个服务器)将数据并行插入到表中
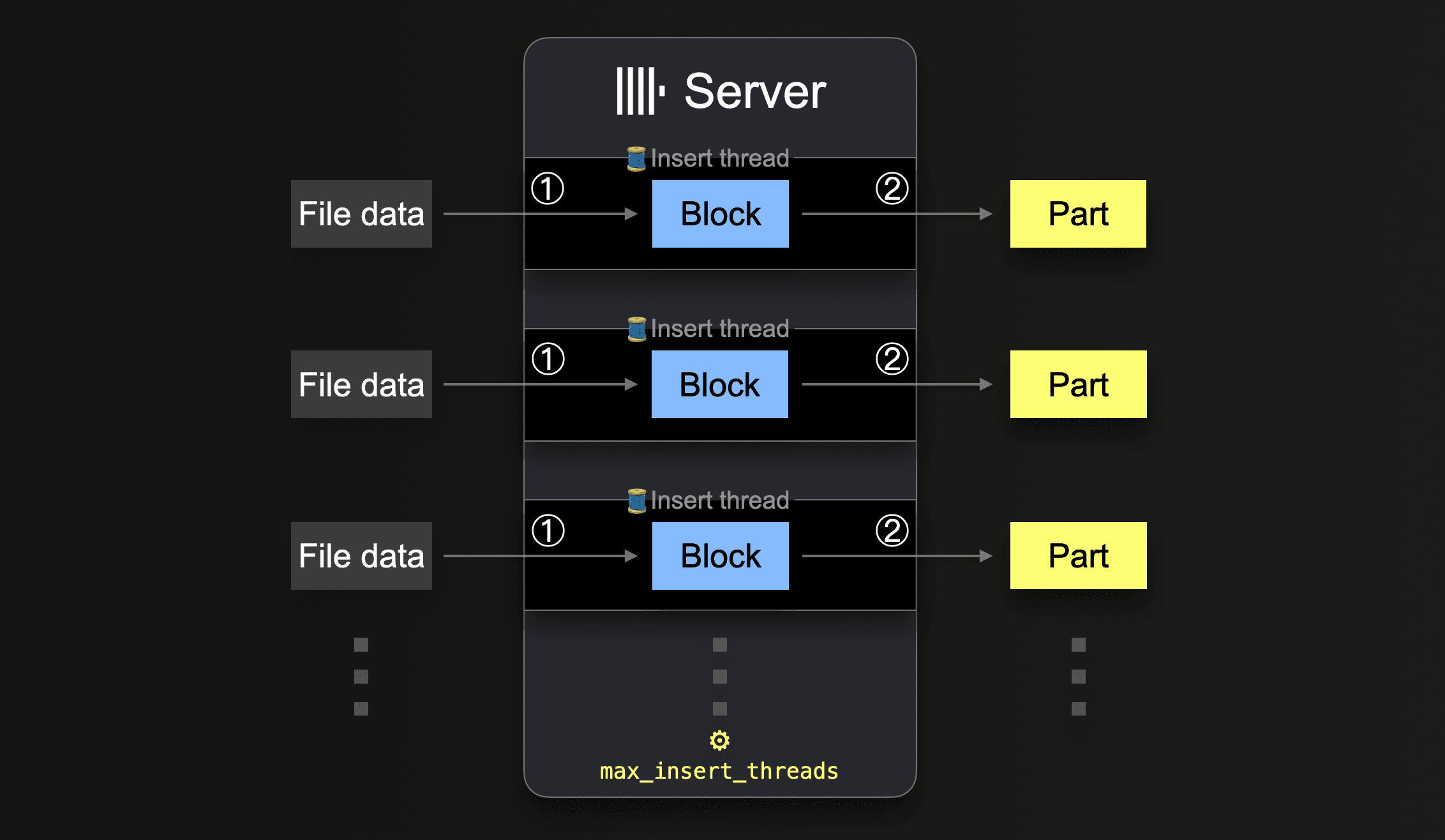
在处理完所有文件中的所有数据之前,每个插入线程都会执行一个循环
① Get the next portion of unprocessed file data (portion size is based on the configured block size) and create an in-memory data block from it.
② Write the block into a new part on storage.
Go to ①.
这种并行插入线程的数量可以使用 max_insert_threads 设置进行配置。开源 ClickHouse 的默认值为 1,ClickHouse Cloud 的默认值为 4。
对于大量文件,多个插入线程的并行处理效果良好。它可以完全饱和可用的 CPU 核心和网络带宽(用于并行文件下载)。在仅将少量大型文件加载到表中的情况下,ClickHouse 会自动建立高水平的数据处理并行度,并通过为每个插入线程生成额外的读取器线程来优化网络带宽使用率,以便并行读取(下载)大型文件中的更多不同范围。
对于 s3 函数和表,单个文件的并行下载由值 max_download_threads 和 max_download_buffer_size 确定。仅当文件大小大于 2 * max_download_buffer_size 时,才会并行下载文件。默认情况下,max_download_buffer_size 默认设置为 10MiB。在某些情况下,您可以安全地将此缓冲区大小增加到 50 MB (max_download_buffer_size=52428800),目的是确保每个文件都由单个线程下载。这可以减少每个线程进行 S3 调用的时间,从而也减少 S3 等待时间。此外,对于太小而无法并行读取的文件,为了提高吞吐量,ClickHouse 会通过异步预读取此类文件来自动预取数据。
衡量性能
当对就地数据运行查询时,即仅使用 ClickHouse 计算且数据保留在 S3 中的原始格式的临时查询,以及当从 S3 将数据插入到 ClickHouse MergeTree 表引擎中时,都需要优化使用 S3 表函数的查询性能。除非另有说明,以下建议适用于这两种情况。
硬件大小的影响
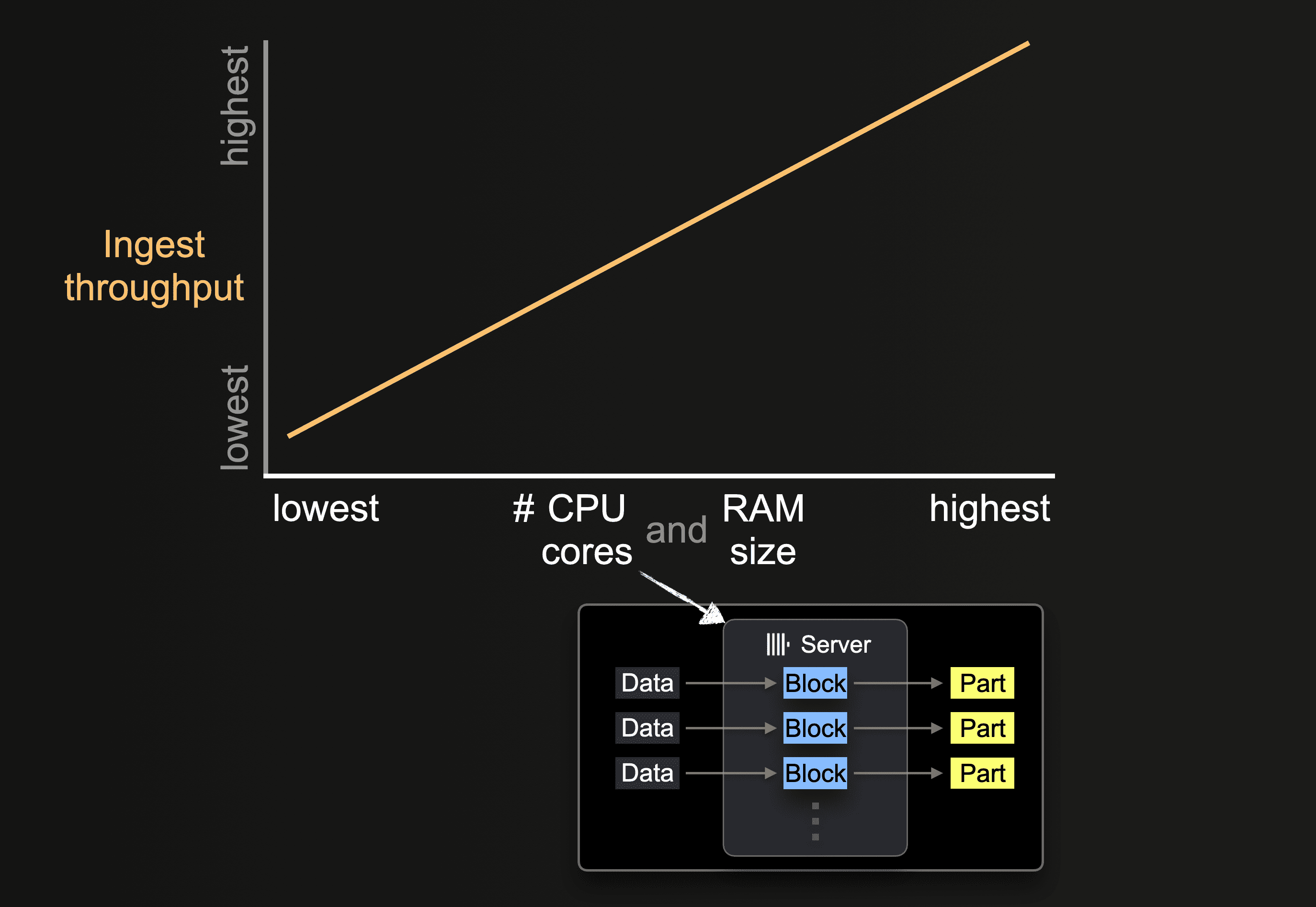
可用的 CPU 核心数和 RAM 大小会影响
- part 的初始大小
- 可能的插入并行度级别
- 后台 part 合并的吞吐量
因此,整体摄取吞吐量。
区域本地性
确保您的存储桶与您的 ClickHouse 实例位于同一区域。这种简单的优化可以显着提高吞吐量性能,特别是当您在 AWS 基础设施上部署 ClickHouse 实例时。
格式
ClickHouse 可以使用 s3 函数和 S3 引擎读取 S3 存储桶中以 支持的格式 存储的文件。如果读取原始文件,其中一些格式具有明显的优势
- 具有编码列名的格式(例如 Native、Parquet、CSVWithNames 和 TabSeparatedWithNames)的查询将不太冗长,因为用户无需在
s3函数中指定列名。列名允许推断此信息。 - 格式在读取和写入吞吐量方面的性能会有所不同。Native 和 Parquet 代表了读取性能的最佳格式,因为它们已经是面向列的并且更紧凑。Native 格式还受益于与 ClickHouse 在内存中存储数据的方式对齐 - 从而减少了数据流式传输到 ClickHouse 时的处理开销。
- 块大小通常会影响读取大型文件的延迟。如果您仅对数据进行采样(例如,返回前 N 行),这将非常明显。对于 CSV 和 TSV 等格式,必须解析文件才能返回一组行。Native 和 Parquet 等格式将允许更快的采样。
- 每种压缩格式都有其优点和缺点,通常在压缩级别之间进行平衡以获得速度,并偏向压缩或解压缩性能。如果压缩 CSV 或 TSV 等原始文件,lz4 提供最快的解压缩性能,但会牺牲压缩级别。Gzip 通常压缩得更好,但读取速度稍慢。Xz 更进一步,通常提供最佳压缩,但压缩和解压缩性能最慢。如果导出,Gz 和 lz4 提供相当的压缩速度。根据您的连接速度对此进行权衡。更快的解压缩或压缩带来的任何增益都可能很容易被与您的 s3 存储桶的较慢连接所抵消。
- Native 或 Parquet 等格式通常不需要压缩的开销。数据大小的任何节省都可能是最小的,因为这些格式本身就很紧凑。压缩和解压缩所花费的时间很少能抵消网络传输时间 - 尤其是在 s3 全球可用且具有更高网络带宽的情况下。
示例数据集
为了进一步说明潜在的优化,我们将使用 Stack Overflow 数据集中的帖子 - 优化此数据的查询和插入性能。
此数据集包含 189 个 Parquet 文件,每个文件对应 2008 年 7 月至 2024 年 3 月之间的每个月。
请注意,根据我们上面的 建议,我们使用 Parquet 来提高性能,并在与存储桶位于同一区域的 ClickHouse 集群上执行所有查询。此集群有 3 个节点,每个节点具有 32GiB RAM 和 8 个 vCPU。
在没有调优的情况下,我们演示了将此数据集插入到 MergeTree 表引擎以及执行查询以计算提问最多的用户的性能。这两个查询都有意需要完整扫描数据。
-- Top usernames
SELECT
OwnerDisplayName,
count() AS num_posts
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
WHERE OwnerDisplayName NOT IN ('', 'anon')
GROUP BY OwnerDisplayName
ORDER BY num_posts DESC
LIMIT 5
┌─OwnerDisplayName─┬─num_posts─┐
│ user330315 │ 10344 │
│ user4039065 │ 5316 │
│ user149341 │ 4102 │
│ user529758 │ 3700 │
│ user3559349 │ 3068 │
└──────────────────┴───────────┘
5 rows in set. Elapsed: 3.013 sec. Processed 59.82 million rows, 24.03 GB (19.86 million rows/s., 7.98 GB/s.)
Peak memory usage: 603.64 MiB.
-- Load into posts table
INSERT INTO posts SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
0 rows in set. Elapsed: 191.692 sec. Processed 59.82 million rows, 24.03 GB (312.06 thousand rows/s., 125.37 MB/s.)
在我们的示例中,我们仅返回少量行。如果衡量 SELECT 查询的性能,其中将大量数据返回到客户端,则可以使用 null 格式 进行查询,或将结果直接定向到 Null 引擎。这应避免客户端被数据淹没和网络饱和。
从查询中读取时,初始查询通常看起来比重复相同查询时慢。这可以归因于 S3 自身的缓存以及 ClickHouse Schema Inference Cache。这会存储文件的推断模式,这意味着可以在后续访问中跳过推断步骤,从而减少查询时间。
使用线程进行读取
S3 上的读取性能将随着核心数量线性扩展,前提是您不受网络带宽或本地 I/O 的限制。增加线程数也会产生用户应注意的内存开销排列。可以修改以下内容以潜在地提高读取吞吐量性能
- 通常,
max_threads的默认值就足够了,即核心数。如果查询使用的内存量很大,并且需要减少内存量,或者结果的LIMIT很低,则可以将此值设置得更低。拥有大量内存的用户可能希望尝试增加此值,以获得可能更高的 S3 读取吞吐量。通常,这仅在核心数较低的机器上才有利,即 < 10。随着其他资源充当瓶颈(例如,网络和 CPU 争用),进一步并行化的好处通常会减少。 - 22.3.1 之前的 ClickHouse 版本仅在使用
s3函数或S3表引擎时才跨多个文件并行读取。这要求用户确保文件在 S3 上拆分为块,并使用 glob 模式读取以实现最佳读取性能。更高版本现在可以并行化文件内的下载。 - 在低线程计数场景中,用户可以通过将
remote_filesystem_read_method设置为 "read" 来实现从 S3 同步读取文件,从而获益。 - 对于 s3 函数和表,单个文件的并行下载由值
max_download_threads和max_download_buffer_size确定。虽然max_download_threads控制使用的线程数,但仅当文件大小大于 2 *max_download_buffer_size时,才会并行下载文件。默认情况下,max_download_buffer_size默认设置为 10MiB。在某些情况下,您可以安全地将此缓冲区大小增加到 50 MB (max_download_buffer_size=52428800),目的是确保较小的文件仅由单个线程下载。这可以减少每个线程进行 S3 调用的时间,从而也减少 S3 等待时间。有关示例,请参阅 此博客文章。
在对性能进行任何改进之前,请确保您进行了适当的衡量。由于 S3 API 调用对延迟敏感,并且可能会影响客户端计时,因此请使用查询日志来获取性能指标,即 system.query_log。
考虑我们之前的查询,将 max_threads 加倍到 16(默认 max_thread 是节点上的核心数)将我们的读取查询性能提高了 2 倍,但代价是更高的内存。如所示,进一步增加 max_threads 的回报会递减。
SELECT
OwnerDisplayName,
count() AS num_posts
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
WHERE OwnerDisplayName NOT IN ('', 'anon')
GROUP BY OwnerDisplayName
ORDER BY num_posts DESC
LIMIT 5
SETTINGS max_threads = 16
┌─OwnerDisplayName─┬─num_posts─┐
│ user330315 │ 10344 │
│ user4039065 │ 5316 │
│ user149341 │ 4102 │
│ user529758 │ 3700 │
│ user3559349 │ 3068 │
└──────────────────┴───────────┘
5 rows in set. Elapsed: 1.505 sec. Processed 59.82 million rows, 24.03 GB (39.76 million rows/s., 15.97 GB/s.)
Peak memory usage: 178.58 MiB.
SETTINGS max_threads = 32
5 rows in set. Elapsed: 0.779 sec. Processed 59.82 million rows, 24.03 GB (76.81 million rows/s., 30.86 GB/s.)
Peak memory usage: 369.20 MiB.
SETTINGS max_threads = 64
5 rows in set. Elapsed: 0.674 sec. Processed 59.82 million rows, 24.03 GB (88.81 million rows/s., 35.68 GB/s.)
Peak memory usage: 639.99 MiB.
调整线程和块大小以进行插入
为了实现最大的摄取性能,您必须根据 (3) 可用的 CPU 核心数和 RAM 量来选择 (1) 插入块大小和 (2) 适当级别的插入并行度。总结
这两个性能因素之间存在冲突的权衡(以及与后台 part 合并的权衡)。ClickHouse 服务器的可用主内存量是有限的。较大的块使用更多主内存,这限制了我们可以利用的并行插入线程数。相反,更高数量的并行插入线程需要更多主内存,因为插入线程数决定了并发在内存中创建的插入块数。这限制了插入块的可能大小。此外,插入线程和后台合并线程之间可能存在资源争用。大量配置的插入线程 (1) 会创建更多需要合并的 part,并且 (2) 会从后台合并线程中占用 CPU 核心和内存空间。
有关这些参数的行为如何影响性能和资源的详细说明,我们建议阅读此博客文章。如这篇博客文章所述,调优可能涉及仔细平衡这两个参数。这种详尽的测试通常是不切实际的,因此,总而言之,我们建议
• max_insert_threads: choose ~ half of the available CPU cores for insert threads (to leave enough dedicated cores for background merges)
• peak_memory_usage_in_bytes: choose an intended peak memory usage; either all available RAM (if it is an isolated ingest) or half or less (to leave room for other concurrent tasks)
Then:
min_insert_block_size_bytes = peak_memory_usage_in_bytes / (~3 * max_insert_threads)
使用此公式,您可以将 min_insert_block_size_rows 设置为 0(以禁用基于行的阈值),同时将 max_insert_threads 设置为选定的值,并将 min_insert_block_size_bytes 设置为从上述公式计算出的结果。
将此公式应用于我们之前的 Stack Overflow 示例。
max_insert_threads=4(每个节点 8 核)peak_memory_usage_in_bytes- 32 GiB (节点资源的 100%) 或34359738368字节。min_insert_block_size_bytes=34359738368/(3*4) = 2863311530
INSERT INTO posts SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet') SETTINGS min_insert_block_size_rows=0, max_insert_threads=4, min_insert_block_size_bytes=2863311530
0 rows in set. Elapsed: 128.566 sec. Processed 59.82 million rows, 24.03 GB (465.28 thousand rows/s., 186.92 MB/s.)
如所示,调整这些设置将插入性能提高了 33% 以上。我们将其留给读者,看看他们是否可以进一步提高单节点性能。
随资源和节点扩展
随资源和节点扩展适用于读取和插入查询。
垂直扩展
之前的所有调整和查询仅使用了 ClickHouse Cloud 集群中的单个节点。用户通常也会有多个 ClickHouse 节点可用。我们建议用户首先进行垂直扩展,随着核心数量线性提高 S3 吞吐量。如果我们在更大的 ClickHouse Cloud 节点上重复我们之前的插入和读取查询,资源增加一倍(64GiB,16 个 vCPU),并使用适当的设置,则两者执行速度大约快一倍。
INSERT INTO posts SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet') SETTINGS min_insert_block_size_rows=0, max_insert_threads=8, min_insert_block_size_bytes=2863311530
0 rows in set. Elapsed: 67.294 sec. Processed 59.82 million rows, 24.03 GB (888.93 thousand rows/s., 357.12 MB/s.)
SELECT
OwnerDisplayName,
count() AS num_posts
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
WHERE OwnerDisplayName NOT IN ('', 'anon')
GROUP BY OwnerDisplayName
ORDER BY num_posts DESC
LIMIT 5
SETTINGS max_threads = 92
5 rows in set. Elapsed: 0.421 sec. Processed 59.82 million rows, 24.03 GB (142.08 million rows/s., 57.08 GB/s.)
单个节点也可能受到网络和 S3 GET 请求的瓶颈限制,从而阻止性能的线性垂直扩展。
水平扩展
最终,由于硬件可用性和成本效益,水平扩展通常是必要的。在 ClickHouse Cloud 中,生产集群至少有 3 个节点。因此,用户可能还希望利用所有节点进行插入。
利用集群进行 S3 读取需要使用 s3Cluster 函数,如利用集群中所述。这允许跨节点分发读取。
最初接收插入查询的服务器首先解析 glob 模式,然后动态地将每个匹配文件的处理分发给自己和其他服务器。
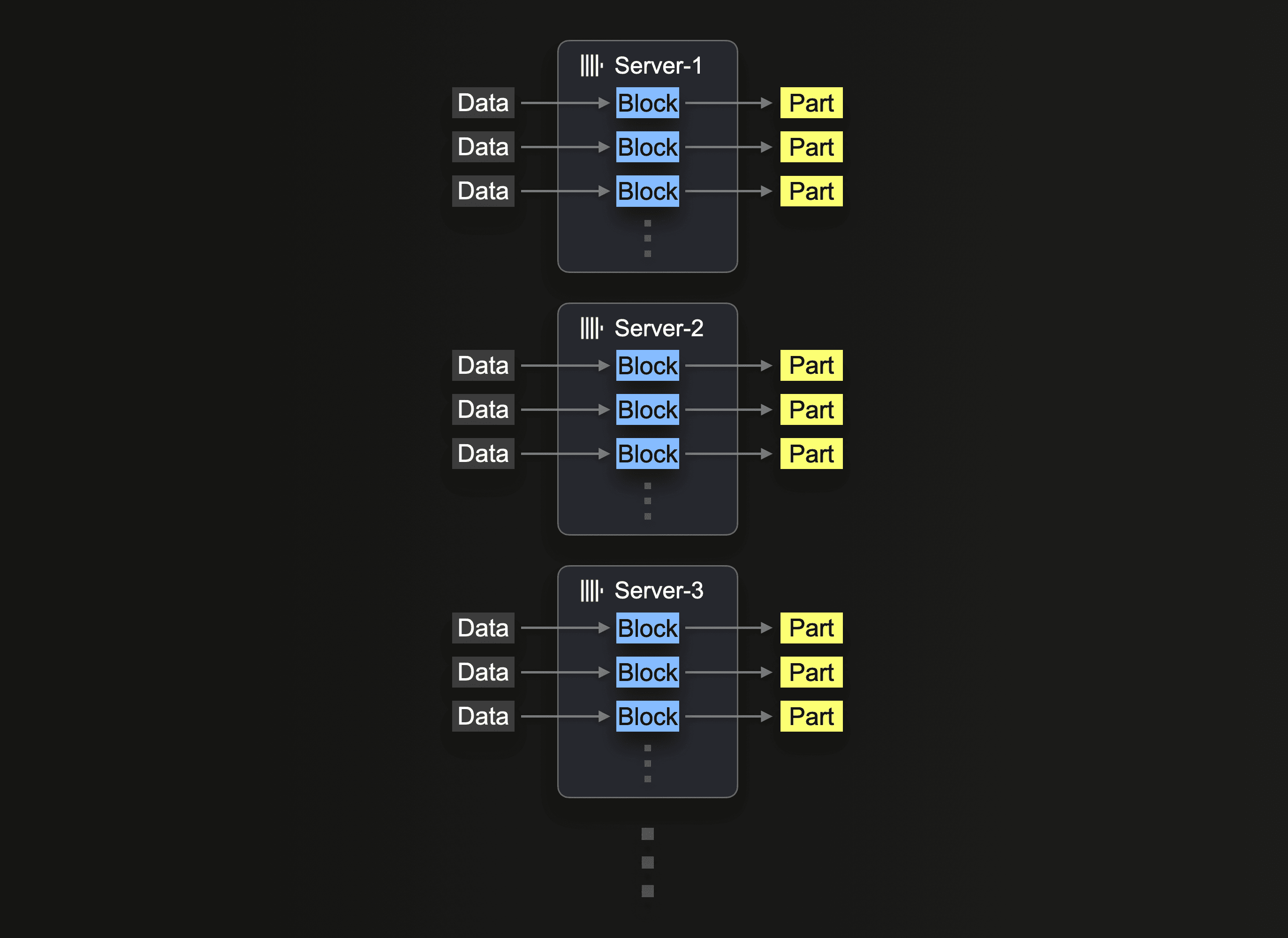
我们重复之前的读取查询,跨 3 个节点分发工作负载,调整查询以使用 s3Cluster。这在 ClickHouse Cloud 中自动执行,通过引用 default 集群。
如利用集群中所述,这项工作是在文件级别分发的。为了从此功能中受益,用户将需要足够数量的文件,即至少 > 节点数量。
SELECT
OwnerDisplayName,
count() AS num_posts
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
WHERE OwnerDisplayName NOT IN ('', 'anon')
GROUP BY OwnerDisplayName
ORDER BY num_posts DESC
LIMIT 5
SETTINGS max_threads = 16
┌─OwnerDisplayName─┬─num_posts─┐
│ user330315 │ 10344 │
│ user4039065 │ 5316 │
│ user149341 │ 4102 │
│ user529758 │ 3700 │
│ user3559349 │ 3068 │
└──────────────────┴───────────┘
5 rows in set. Elapsed: 0.622 sec. Processed 59.82 million rows, 24.03 GB (96.13 million rows/s., 38.62 GB/s.)
Peak memory usage: 176.74 MiB.
同样,我们的插入查询也可以使用之前为单节点确定的改进设置进行分发
INSERT INTO posts SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet') SETTINGS min_insert_block_size_rows=0, max_insert_threads=4, min_insert_block_size_bytes=2863311530
0 rows in set. Elapsed: 171.202 sec. Processed 59.82 million rows, 24.03 GB (349.41 thousand rows/s., 140.37 MB/s.)
读者会注意到,读取文件提高了查询性能,但没有提高插入性能。默认情况下,虽然读取是使用 s3Cluster 分发的,但插入将针对发起者节点进行。这意味着虽然读取将在每个节点上发生,但生成的行将被路由到发起者以进行分发。在高吞吐量场景中,这可能会成为瓶颈。为了解决这个问题,为 s3cluster 函数设置参数 parallel_distributed_insert_select。
将此参数设置为 parallel_distributed_insert_select=2,可确保 SELECT 和 INSERT 将在每个分片上从/到每个节点上分布式引擎的底层表执行。
INSERT INTO posts
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SETTINGS parallel_distributed_insert_select = 2, min_insert_block_size_rows=0, max_insert_threads=4, min_insert_block_size_bytes=2863311530
0 rows in set. Elapsed: 54.571 sec. Processed 59.82 million rows, 24.03 GB (1.10 million rows/s., 440.38 MB/s.)
Peak memory usage: 11.75 GiB.
正如预期的那样,这使插入性能降低了 3 倍。
进一步调整
禁用重复数据删除
插入操作有时可能会因错误(如超时)而失败。当插入失败时,数据可能已成功插入,也可能未成功插入。为了允许客户端安全地重试插入,默认情况下在分布式部署(如 ClickHouse Cloud)中,ClickHouse 尝试确定数据是否已成功插入。如果插入的数据被标记为重复,ClickHouse 不会将其插入到目标表中。但是,用户仍然会收到成功的操作状态,就像数据已正常插入一样。
虽然这种行为(会产生插入开销)在从客户端或批量加载数据时有意义,但在执行从对象存储 INSERT INTO SELECT 时可能是不必要的。通过在插入时禁用此功能,我们可以提高性能,如下所示
INSERT INTO posts
SETTINGS parallel_distributed_insert_select = 2, min_insert_block_size_rows = 0, max_insert_threads = 4, min_insert_block_size_bytes = 2863311530, insert_deduplicate = 0
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SETTINGS parallel_distributed_insert_select = 2, min_insert_block_size_rows = 0, max_insert_threads = 4, min_insert_block_size_bytes = 2863311530, insert_deduplicate = 0
0 rows in set. Elapsed: 52.992 sec. Processed 59.82 million rows, 24.03 GB (1.13 million rows/s., 453.50 MB/s.)
Peak memory usage: 26.57 GiB.
插入时优化
在 ClickHouse 中,optimize_on_insert 设置控制是否在插入过程中合并数据部件。当启用时(默认情况下 optimize_on_insert = 1),小部件在插入时合并为更大的部件,通过减少需要读取的部件数量来提高查询性能。但是,这种合并会增加插入过程的开销,可能会减慢高吞吐量插入的速度。
禁用此设置 (optimize_on_insert = 0) 会跳过插入期间的合并,从而允许更快地写入数据,尤其是在处理频繁的小插入时。合并过程被推迟到后台,从而允许更好的插入性能,但暂时增加了小部件的数量,这可能会减慢查询速度,直到后台合并完成。当插入性能是首要任务,并且后台合并过程可以稍后有效地处理优化时,此设置是理想的选择。如下所示,禁用此设置可以提高插入吞吐量
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SETTINGS parallel_distributed_insert_select = 2, min_insert_block_size_rows = 0, max_insert_threads = 4, min_insert_block_size_bytes = 2863311530, insert_deduplicate = 0, optimize_on_insert = 0
0 rows in set. Elapsed: 49.688 sec. Processed 59.82 million rows, 24.03 GB (1.20 million rows/s., 483.66 MB/s.)
杂项注释
- 对于低内存场景,如果插入到 S3,请考虑降低
max_insert_delayed_streams_for_parallel_write。