数据反规范化
数据反规范化是 ClickHouse 中的一种技术,它使用扁平化表来帮助最小化查询延迟,从而避免连接(joins)。
规范化与反规范化 Schema 的比较
数据反规范化涉及有意地逆转规范化过程,以针对特定的查询模式优化数据库性能。在规范化数据库中,数据被拆分为多个相关表,以最大限度地减少冗余并确保数据完整性。反规范化通过合并表、复制数据以及将计算字段合并到一个表中或更少的表中来重新引入冗余——有效地将任何连接从查询时转移到插入时。
此过程减少了查询时对复杂连接的需求,并可以显着加快读取操作,使其成为具有繁重读取需求和复杂查询的应用程序的理想选择。但是,它会增加写入操作和维护的复杂性,因为对重复数据的任何更改都必须在所有实例中传播以保持一致性。

NoSQL 解决方案普及的一种常见技术是在缺少 JOIN 支持的情况下对数据进行反规范化,有效地将所有统计信息或相关行作为列和嵌套对象存储在父行上。例如,在博客的示例 schema 中,我们可以将所有 Comments 作为对象 Array 存储在其各自的文章上。
何时使用反规范化
一般来说,我们建议在以下情况下进行反规范化
- 对更改不频繁的表或在分析查询中数据可用之前可以容忍延迟的表进行反规范化,即可以批量完全重新加载数据。
- 避免反规范化多对多关系。如果单个源行发生更改,这可能会导致需要更新许多行。
- 避免反规范化高基数关系。如果表中的每一行在另一个表中都有数千个相关条目,则这些条目将需要表示为
Array- 原始类型或元组的数组。通常,不建议使用超过 1000 个元组的数组。 - 与其将所有列都反规范化为嵌套对象,不如考虑仅使用物化视图反规范化统计信息(见下文)。
并非所有信息都需要反规范化 - 只需要经常访问的关键信息。
反规范化工作可以在 ClickHouse 中或上游(例如使用 Apache Flink)处理。
避免对频繁更新的数据进行反规范化
对于 ClickHouse,反规范化是用户可以用来优化查询性能的几种选择之一,但应谨慎使用。如果数据频繁更新并且需要在近乎实时的情况下更新,则应避免使用此方法。如果主表主要用于追加,或者可以定期批量重新加载(例如,每天),则可以使用此方法。
作为一种方法,它面临一个主要的挑战 - 写入性能和更新数据。更具体地说,反规范化有效地将数据连接的责任从查询时转移到摄取时。虽然这可以显着提高查询性能,但它使摄取变得复杂,并且意味着如果用于组成它的任何行发生更改,则数据管道需要将行重新插入 ClickHouse。这可能意味着一个源行的更改可能意味着需要更新 ClickHouse 中的许多行。在复杂的 schema 中,行由复杂的连接组成,连接的嵌套组件中的单个行更改可能意味着需要更新数百万行。
由于以下两个挑战,在实际应用中实时实现这一点通常是不现实的,并且需要大量的工程工作
- 当表行更改时触发正确的连接语句。理想情况下,这不应导致连接的所有对象都被更新 - 而只是那些受到影响的对象。修改连接以有效地过滤到正确的行,并在高吞吐量下实现这一点,需要外部工具或工程。
- ClickHouse 中的行更新需要仔细管理,这会引入额外的复杂性。
因此,批量更新过程更为常见,其中定期重新加载所有反规范化对象。
反规范化的实际案例
让我们考虑一些反规范化可能有意义的实际示例,以及其他替代方法更可取的示例。
考虑一个 Posts 表,该表已经使用统计信息(例如 AnswerCount 和 CommentCount)进行了反规范化 - 源数据以这种形式提供。实际上,我们可能希望实际规范化此信息,因为它很可能经常更改。许多这些列也可以通过其他表获得,例如,帖子的评论可以通过 PostId 列和 Comments 表获得。出于示例的目的,我们假设帖子是在批处理过程中重新加载的。
我们还只考虑将其他表反规范化到 Posts 上,因为我们认为这是我们用于分析的主表。在另一个方向上进行反规范化也适用于某些查询,但适用相同的上述注意事项。
对于以下每个示例,假设存在一个查询,该查询需要两个表都用于连接。
帖子和投票
帖子的投票表示为单独的表。此处的优化 schema 如下所示,以及加载数据的插入命令
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 26.272 sec. Processed 238.98 million rows, 2.13 GB (9.10 million rows/s., 80.97 MB/s.)
乍一看,这些可能是帖子表上反规范化的候选对象。此方法存在一些挑战。
投票会频繁添加到帖子中。虽然每个帖子的投票可能会随着时间的推移而减少,但以下查询显示,在 30k 个帖子中,我们每小时大约有 4 万个投票。
SELECT round(avg(c)) AS avg_votes_per_hr, round(avg(posts)) AS avg_posts_per_hr
FROM
(
SELECT
toStartOfHour(CreationDate) AS hr,
count() AS c,
uniq(PostId) AS posts
FROM votes
GROUP BY hr
)
┌─avg_votes_per_hr─┬─avg_posts_per_hr─┐
│ 41759 │ 33322 │
└──────────────────┴──────────────────┘
如果可以容忍延迟,则可以通过批处理来解决此问题,但这仍然需要我们处理更新,除非我们定期重新加载所有帖子(不太理想)。
更麻烦的是,某些帖子的投票数非常高
SELECT PostId, concat('https://stackoverflow.com/questions/', PostId) AS url, count() AS c
FROM votes
GROUP BY PostId
ORDER BY c DESC
LIMIT 5
┌───PostId─┬─url──────────────────────────────────────────┬─────c─┐
│ 11227902 │ https://stackoverflow.com/questions/11227902 │ 35123 │
│ 927386 │ https://stackoverflow.com/questions/927386 │ 29090 │
│ 11227809 │ https://stackoverflow.com/questions/11227809 │ 27475 │
│ 927358 │ https://stackoverflow.com/questions/927358 │ 26409 │
│ 2003515 │ https://stackoverflow.com/questions/2003515 │ 25899 │
└──────────┴──────────────────────────────────────────────┴───────┘
这里的主要观察结果是,每个帖子的聚合投票统计信息对于大多数分析来说就足够了 - 我们不需要反规范化所有的投票信息。例如,当前的 Score 列表示这样的统计信息,即总赞成票数减去反对票数。理想情况下,我们应该能够在查询时通过简单的查找来检索这些统计信息(请参阅 字典)。
用户和徽章
现在让我们考虑一下 Users 和 Badges
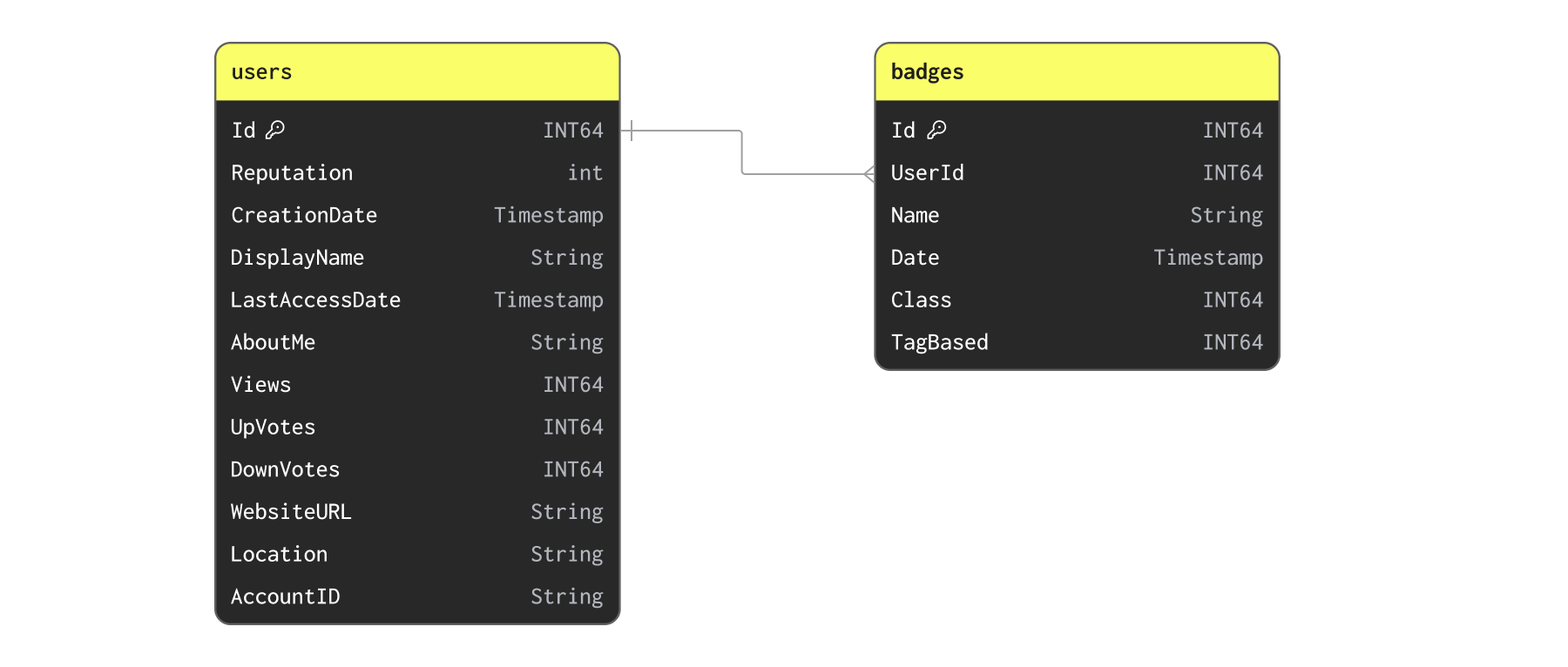
我们首先使用以下命令插入数据
CREATE TABLE users
(
`Id` Int32,
`Reputation` LowCardinality(String),
`CreationDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`DisplayName` String,
`LastAccessDate` DateTime64(3, 'UTC'),
`AboutMe` String,
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32,
`WebsiteUrl` String,
`Location` LowCardinality(String),
`AccountId` Int32
)
ENGINE = MergeTree
ORDER BY (Id, CreationDate)
CREATE TABLE badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
INSERT INTO users SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet')
0 rows in set. Elapsed: 26.229 sec. Processed 22.48 million rows, 1.36 GB (857.21 thousand rows/s., 51.99 MB/s.)
INSERT INTO badges SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 18.126 sec. Processed 51.29 million rows, 797.05 MB (2.83 million rows/s., 43.97 MB/s.)
虽然用户可能会频繁获得徽章,但这不太可能是一个我们需要每天更新多次的数据集。徽章和用户之间的关系是一对多的。也许我们可以简单地将徽章作为元组列表反规范化到用户上?虽然有可能,但快速检查以确认每个用户的徽章数量最多表明这并不理想
SELECT UserId, count() AS c FROM badges GROUP BY UserId ORDER BY c DESC LIMIT 5
┌─UserId─┬─────c─┐
│ 22656 │ 19334 │
│ 6309 │ 10516 │
│ 100297 │ 7848 │
│ 157882 │ 7574 │
│ 29407 │ 6512 │
└────────┴───────┘
将 1.9 万个对象反规范化到单个行上可能是不现实的。这种关系最好保留为单独的表或添加统计信息。
我们可能希望将徽章的统计信息反规范化到用户上,例如徽章的数量。在使用字典插入此数据集时,我们会考虑这样一个示例。
帖子和 PostLinks
PostLinks 连接用户认为相关或重复的 Posts。以下查询显示了 schema 和加载命令
CREATE TABLE postlinks
(
`Id` UInt64,
`CreationDate` DateTime64(3, 'UTC'),
`PostId` Int32,
`RelatedPostId` Int32,
`LinkTypeId` Enum('Linked' = 1, 'Duplicate' = 3)
)
ENGINE = MergeTree
ORDER BY (PostId, RelatedPostId)
INSERT INTO postlinks SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/postlinks.parquet')
0 rows in set. Elapsed: 4.726 sec. Processed 6.55 million rows, 129.70 MB (1.39 million rows/s., 27.44 MB/s.)
我们可以确认没有帖子的链接数量过多,从而阻止反规范化
SELECT PostId, count() AS c
FROM postlinks
GROUP BY PostId
ORDER BY c DESC LIMIT 5
┌───PostId─┬───c─┐
│ 22937618 │ 125 │
│ 9549780 │ 120 │
│ 3737139 │ 109 │
│ 18050071 │ 103 │
│ 25889234 │ 82 │
└──────────┴─────┘
同样,这些链接不是过于频繁发生的事件
SELECT
round(avg(c)) AS avg_votes_per_hr,
round(avg(posts)) AS avg_posts_per_hr
FROM
(
SELECT
toStartOfHour(CreationDate) AS hr,
count() AS c,
uniq(PostId) AS posts
FROM postlinks
GROUP BY hr
)
┌─avg_votes_per_hr─┬─avg_posts_per_hr─┐
│ 54 │ 44 │
└──────────────────┴──────────────────┘
我们在下面的反规范化示例中使用它。
简单的统计信息示例
在大多数情况下,反规范化需要向父行添加单个列或统计信息。例如,我们可能只希望使用重复帖子数来丰富我们的帖子,而我们只需要添加一列即可。
CREATE TABLE posts_with_duplicate_count
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
... -other columns
`DuplicatePosts` UInt16
) ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
为了填充此表,我们利用 INSERT INTO SELECT 将我们的重复统计信息与我们的帖子连接起来。
INSERT INTO posts_with_duplicate_count SELECT
posts.*,
DuplicatePosts
FROM posts AS posts
LEFT JOIN
(
SELECT PostId, countIf(LinkTypeId = 'Duplicate') AS DuplicatePosts
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts.Id = postlinks.PostId
利用复杂类型进行一对多关系
为了执行反规范化,我们通常需要利用复杂类型。如果要反规范化一对一关系,并且列数较少,则用户只需将这些列作为具有其原始类型的行添加,如上所示。但是,对于较大的对象来说,这通常是不理想的,并且对于一对多关系来说是不可能的。
在复杂对象或一对多关系的情况下,用户可以使用
- 命名元组 - 这些允许将相关结构表示为一组列。
- Array(Tuple) 或 Nested - 命名元组的数组,也称为 Nested,每个条目代表一个对象。适用于一对多关系。
作为一个示例,我们在下面演示了如何将 PostLinks 反规范化到 Posts 上。
每个帖子可以包含许多指向其他帖子的链接,如之前的 PostLinks schema 所示。作为 Nested 类型,我们可以将这些链接的和重复的帖子表示如下
SET flatten_nested=0
CREATE TABLE posts_with_links
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
... -other columns
`LinkedPosts` Nested(CreationDate DateTime64(3, 'UTC'), PostId Int32),
`DuplicatePosts` Nested(CreationDate DateTime64(3, 'UTC'), PostId Int32),
) ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
请注意设置
flatten_nested=0的使用。我们建议禁用嵌套数据的扁平化。
我们可以使用带有 OUTER JOIN 查询的 INSERT INTO SELECT 来执行此反规范化
INSERT INTO posts_with_links
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts.Id = postlinks.PostId
0 rows in set. Elapsed: 155.372 sec. Processed 66.37 million rows, 76.33 GB (427.18 thousand rows/s., 491.25 MB/s.)
Peak memory usage: 6.98 GiB.
请注意此处的时间。我们设法在 2 分钟左右的时间内反规范化了 6600 万行。正如我们稍后将看到的,这是一个我们可以调度的操作。
请注意使用 groupArray 函数在连接之前将 PostLinks 折叠成每个 PostId 的数组。然后,此数组被过滤成两个子列表:LinkedPosts 和 DuplicatePosts,它们也排除了来自外部连接的任何空结果。
我们可以选择一些行来查看我们新的反规范化结构
SELECT LinkedPosts, DuplicatePosts
FROM posts_with_links
WHERE (length(LinkedPosts) > 2) AND (length(DuplicatePosts) > 0)
LIMIT 1
FORMAT Vertical
Row 1:
──────
LinkedPosts: [('2017-04-11 11:53:09.583',3404508),('2017-04-11 11:49:07.680',3922739),('2017-04-11 11:48:33.353',33058004)]
DuplicatePosts: [('2017-04-11 12:18:37.260',3922739),('2017-04-11 12:18:37.260',33058004)]
编排和调度反规范化
批量
利用反规范化需要一个转换过程,可以在其中执行和编排反规范化。
我们上面已经展示了如何使用 ClickHouse 在通过 INSERT INTO SELECT 加载数据后执行此转换。这适用于定期批量转换。
假设可以接受定期批量加载过程,用户可以使用多种选项在 ClickHouse 中编排此过程
- 可刷新物化视图 - 可刷新物化视图可用于定期调度查询,并将结果发送到目标表。在查询执行时,视图确保目标表以原子方式更新。这提供了一种 ClickHouse 原生的调度此工作的方式。
- 外部工具 - 利用 dbt 和 Airflow 等工具定期调度转换。dbt 的 ClickHouse 集成 确保使用新版本的目标表原子地执行此操作,然后与接收查询的版本原子地交换(通过 EXCHANGE 命令)。
流式
用户也可以选择在插入之前在 ClickHouse 外部执行此操作,使用 Apache Flink 等流式技术。或者,可以使用增量 物化视图 在插入数据时执行此过程。