物化视图
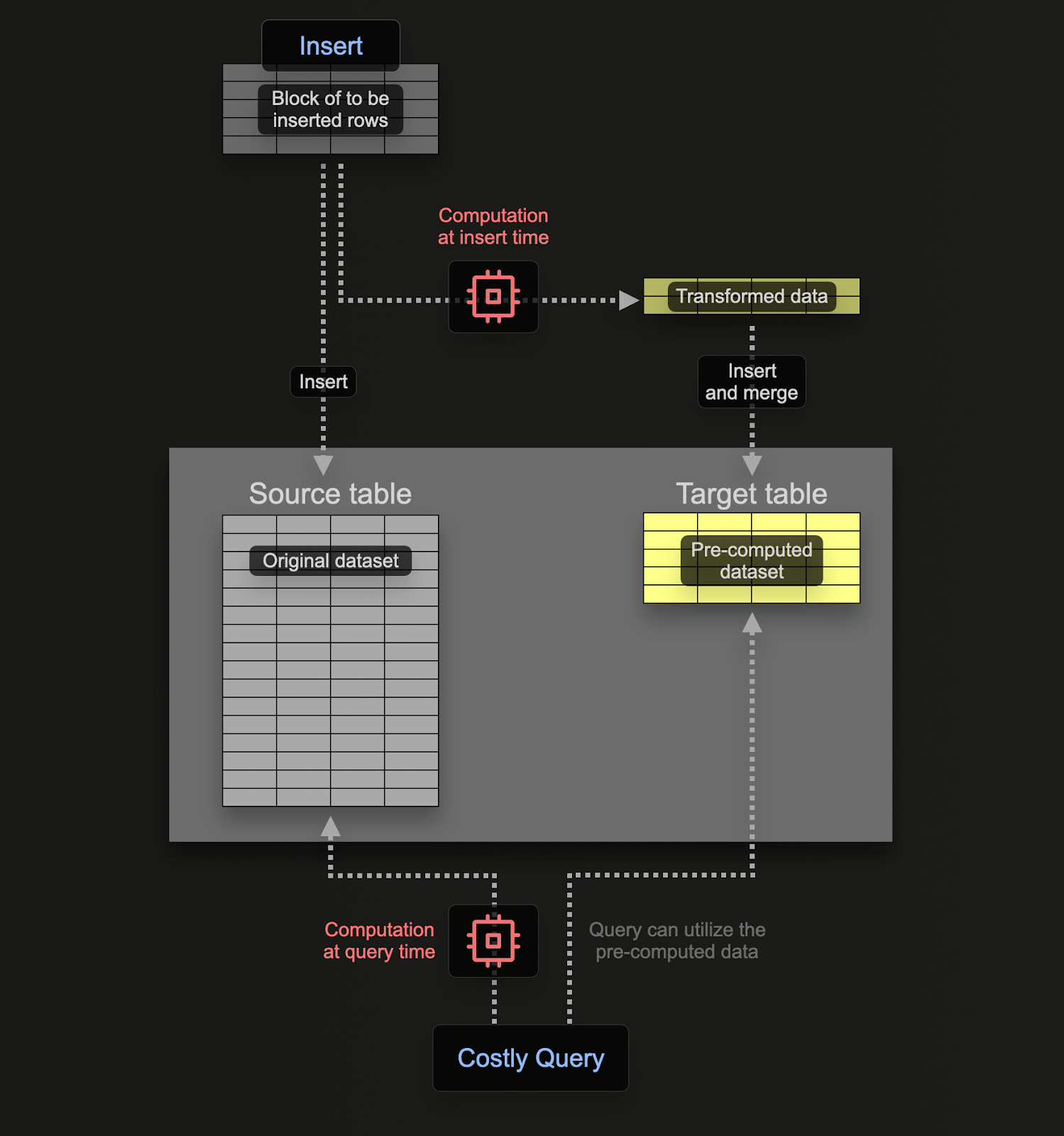
物化视图允许用户将计算成本从查询时转移到插入时,从而加快 SELECT 查询。
与 Postgres 等事务性数据库不同,ClickHouse 物化视图只是一个触发器,它在数据块插入表时运行查询。此查询的结果将插入到第二个“目标”表中。如果插入更多行,结果将再次发送到目标表,在目标表中,中间结果将被更新和合并。此合并结果等同于对所有原始数据运行查询。
物化视图的主要动机是插入到目标表中的结果表示对行进行聚合、过滤或转换的结果。这些结果通常是原始数据的较小表示(在聚合情况下为部分草图)。这与从目标表读取结果的查询很简单这一事实相结合,确保查询时间比在原始数据上执行相同计算更快,从而将计算(以及查询延迟)从查询时转移到插入时。
ClickHouse 中的物化视图随着数据流入它们所基于的表而实时更新,其功能更像持续更新的索引。这与其他数据库形成对比,在其他数据库中,物化视图通常是必须刷新的查询的静态快照(类似于 ClickHouse 可刷新物化视图)。
示例
假设我们想要获取每天每个帖子的赞成票和反对票的数量。
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 29.359 sec. Processed 238.98 million rows, 2.13 GB (8.14 million rows/s., 72.45 MB/s.)
由于 toStartOfDay 函数,这在 ClickHouse 中是一个相当简单的查询
SELECT toStartOfDay(CreationDate) AS day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY day
ORDER BY day ASC
LIMIT 10
┌─────────────────day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 00:00:00 │ 6 │ 0 │
│ 2008-08-01 00:00:00 │ 182 │ 50 │
│ 2008-08-02 00:00:00 │ 436 │ 107 │
│ 2008-08-03 00:00:00 │ 564 │ 100 │
│ 2008-08-04 00:00:00 │ 1306 │ 259 │
│ 2008-08-05 00:00:00 │ 1368 │ 269 │
│ 2008-08-06 00:00:00 │ 1701 │ 211 │
│ 2008-08-07 00:00:00 │ 1544 │ 211 │
│ 2008-08-08 00:00:00 │ 1241 │ 212 │
│ 2008-08-09 00:00:00 │ 576 │ 46 │
└─────────────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.133 sec. Processed 238.98 million rows, 2.15 GB (1.79 billion rows/s., 16.14 GB/s.)
Peak memory usage: 363.22 MiB.
由于 ClickHouse,此查询已经很快,但我们可以做得更好吗?
如果我们想使用物化视图在插入时计算此值,我们需要一个表来接收结果。此表应每天仅保留 1 行。如果收到对现有日期的更新,则其他列应合并到现有日期的行中。为了实现增量状态的合并,必须为其他列存储部分状态。
这需要在 ClickHouse 中使用特殊的引擎类型:SummingMergeTree。这将所有具有相同排序键的行替换为一行,其中包含数值列的求和值。以下表将合并任何具有相同日期的行,并对任何数值列求和
CREATE TABLE up_down_votes_per_day
(
`Day` Date,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = SummingMergeTree
ORDER BY Day
为了演示我们的物化视图,假设我们的 votes 表为空,并且尚未接收到任何数据。我们的物化视图对插入到 votes 中的数据执行上述 SELECT,结果发送到 up_down_votes_per_day
CREATE MATERIALIZED VIEW up_down_votes_per_day_mv TO up_down_votes_per_day AS
SELECT toStartOfDay(CreationDate)::Date AS Day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY Day
此处的 TO 子句是关键,表示结果将发送到哪里,即 up_down_votes_per_day。
我们可以从我们之前的插入中重新填充 votes 表
INSERT INTO votes SELECT toUInt32(Id) AS Id, toInt32(PostId) AS PostId, VoteTypeId, CreationDate, UserId, BountyAmount
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 111.964 sec. Processed 477.97 million rows, 3.89 GB (4.27 million rows/s., 34.71 MB/s.)
Peak memory usage: 283.49 MiB.
完成后,我们可以确认 up_down_votes_per_day 的大小 - 我们应该每天有 1 行
SELECT count()
FROM up_down_votes_per_day
FINAL
┌─count()─┐
│ 5723 │
└─────────┘
通过存储查询结果,我们有效地将此处的行数从 2.38 亿(在 votes 中)减少到 5000 行。然而,这里的关键是,如果将新的投票插入到 votes 表中,则新值将发送到 up_down_votes_per_day 中各自的日期,并在后台自动异步合并 - 每天仅保留一行。因此,up_down_votes_per_day 将始终保持小巧且最新。
由于行的合并是异步的,因此当用户查询时,每天可能有多于一个投票。为了确保在查询时合并任何未完成的行,我们有两个选项
- 在表名上使用
FINAL修饰符。我们在上面的计数查询中执行了此操作。 - 按最终表中使用的排序键(即
CreationDate)聚合并对指标求和。通常,这更高效且更灵活(该表可用于其他用途),但对于某些查询,前者可能更简单。我们在下面展示了两者
SELECT
Day,
UpVotes,
DownVotes
FROM up_down_votes_per_day
FINAL
ORDER BY Day ASC
LIMIT 10
10 rows in set. Elapsed: 0.004 sec. Processed 8.97 thousand rows, 89.68 KB (2.09 million rows/s., 20.89 MB/s.)
Peak memory usage: 289.75 KiB.
SELECT Day, sum(UpVotes) AS UpVotes, sum(DownVotes) AS DownVotes
FROM up_down_votes_per_day
GROUP BY Day
ORDER BY Day ASC
LIMIT 10
┌────────Day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 │ 6 │ 0 │
│ 2008-08-01 │ 182 │ 50 │
│ 2008-08-02 │ 436 │ 107 │
│ 2008-08-03 │ 564 │ 100 │
│ 2008-08-04 │ 1306 │ 259 │
│ 2008-08-05 │ 1368 │ 269 │
│ 2008-08-06 │ 1701 │ 211 │
│ 2008-08-07 │ 1544 │ 211 │
│ 2008-08-08 │ 1241 │ 212 │
│ 2008-08-09 │ 576 │ 46 │
└────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.010 sec. Processed 8.97 thousand rows, 89.68 KB (907.32 thousand rows/s., 9.07 MB/s.)
Peak memory usage: 567.61 KiB.
这使我们的查询速度从 0.133 秒提高到 0.004 秒,提高了 25 倍以上!
ORDER BY = GROUP BY在大多数情况下,如果使用 SummingMergeTree 或 AggregatingMergeTree 表引擎,则物化视图转换的 GROUP BY 子句中使用的列应与目标表的 ORDER BY 子句中使用的列保持一致。这些引擎依赖于 ORDER BY 列在后台合并操作期间合并具有相同值的行。GROUP BY 列和 ORDER BY 列之间的错位可能导致低效的查询性能、次优的合并,甚至数据差异。
更复杂的示例
上面的示例使用物化视图来计算和维护每天的两个总和。总和表示要维护部分状态的最简单聚合形式 - 当新值到达时,我们可以简单地将新值添加到现有值。但是,ClickHouse 物化视图可以用于任何聚合类型。
假设我们希望计算每天帖子的某些统计信息:Score 的第 99.9 个百分位数和 CommentCount 的平均值。计算此值的查询可能如下所示
SELECT
toStartOfDay(CreationDate) AS Day,
quantile(0.999)(Score) AS Score_99th,
avg(CommentCount) AS AvgCommentCount
FROM posts
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
┌─────────────────Day─┬────────Score_99th─┬────AvgCommentCount─┐
1. │ 2024-03-31 00:00:00 │ 5.23700000000008 │ 1.3429811866859624 │
2. │ 2024-03-30 00:00:00 │ 5 │ 1.3097158891616976 │
3. │ 2024-03-29 00:00:00 │ 5.78899999999976 │ 1.2827635327635327 │
4. │ 2024-03-28 00:00:00 │ 7 │ 1.277746158224246 │
5. │ 2024-03-27 00:00:00 │ 5.738999999999578 │ 1.2113264918282023 │
6. │ 2024-03-26 00:00:00 │ 6 │ 1.3097536945812809 │
7. │ 2024-03-25 00:00:00 │ 6 │ 1.2836721018539201 │
8. │ 2024-03-24 00:00:00 │ 5.278999999999996 │ 1.2931667891256429 │
9. │ 2024-03-23 00:00:00 │ 6.253000000000156 │ 1.334061135371179 │
10. │ 2024-03-22 00:00:00 │ 9.310999999999694 │ 1.2388059701492538 │
└─────────────────────┴───────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.113 sec. Processed 59.82 million rows, 777.65 MB (528.48 million rows/s., 6.87 GB/s.)
Peak memory usage: 658.84 MiB.
与之前一样,我们可以创建一个物化视图,该视图在将新帖子插入到我们的 posts 表中时执行上述查询。
为了示例目的,并避免从 S3 加载帖子数据,我们将创建一个与 posts 具有相同 schema 的重复表 posts_null。但是,此表不会存储任何数据,并且仅供物化视图在插入行时使用。为了防止存储数据,我们可以使用 Null 表引擎类型。
CREATE TABLE posts_null AS posts ENGINE = Null
Null 表引擎是一个强大的优化 - 可以将其视为 /dev/null。当我们的 posts_null 表在插入时接收到行时,我们的物化视图将计算并存储我们的摘要统计信息 - 它只是一个触发器。但是,原始数据将不会存储。虽然在我们的例子中,我们可能仍然希望存储原始帖子,但此方法可用于计算聚合,同时避免原始数据的存储开销。
因此,物化视图变为
CREATE MATERIALIZED VIEW post_stats_mv TO post_stats_per_day AS
SELECT toStartOfDay(CreationDate) AS Day,
quantileState(0.999)(Score) AS Score_quantiles,
avgState(CommentCount) AS AvgCommentCount
FROM posts_null
GROUP BY Day
请注意我们如何将后缀 State 附加到聚合函数的末尾。这确保返回函数的聚合状态,而不是最终结果。这将包含允许此部分状态与其他状态合并的附加信息。例如,对于平均值,这将包括列的计数和总和。
部分聚合状态对于计算正确结果是必要的。例如,对于计算平均值,简单地对子范围的平均值求平均值会产生不正确的结果。
我们现在为此视图 post_stats_per_day 创建目标表,该表存储这些部分聚合状态
CREATE TABLE post_stats_per_day
(
`Day` Date,
`Score_quantiles` AggregateFunction(quantile(0.999), Int32),
`AvgCommentCount` AggregateFunction(avg, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY Day
虽然早期的 SummingMergeTree 足以存储计数,但对于其他函数,我们需要更高级的引擎类型:AggregatingMergeTree。为了确保 ClickHouse 知道将存储聚合状态,我们将 Score_quantiles 和 AvgCommentCount 定义为 AggregateFunction 类型,指定部分状态的函数源及其源列的类型。与 SummingMergeTree 类似,具有相同 ORDER BY 键值的行将被合并(在上面的示例中为 Day)。
为了通过我们的物化视图填充我们的 post_stats_per_day,我们可以简单地将 posts 中的所有行插入到 posts_null 中
INSERT INTO posts_null SELECT * FROM posts
0 rows in set. Elapsed: 13.329 sec. Processed 119.64 million rows, 76.99 GB (8.98 million rows/s., 5.78 GB/s.)
在生产环境中,您可能会将物化视图附加到
posts表。我们在此处使用了posts_null来演示 null 表。
我们的最终查询需要为我们的函数使用 Merge 后缀(因为列存储部分聚合状态)
SELECT
Day,
quantileMerge(0.999)(Score_quantiles),
avgMerge(AvgCommentCount)
FROM post_stats_per_day
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
请注意,我们在此处使用 GROUP BY 而不是使用 FINAL。
在物化视图的过滤器和 JOIN 中使用源表
在使用 ClickHouse 中的物化视图时,重要的是要了解在执行物化视图的查询期间如何处理源表。具体来说,物化视图查询中的源表被插入的数据块替换。如果不正确理解此行为,可能会导致一些意外结果。
示例场景
考虑以下设置
CREATE TABLE t0 (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw1_inner (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw2_inner (`c0` Int) ENGINE = Memory;
CREATE VIEW vt0 AS SELECT * FROM t0;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN ( SELECT * FROM t0 ) AS x ON t0.c0 = x.c0;
CREATE MATERIALIZED VIEW mvw2 TO mvw2_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN vt0 ON t0.c0 = vt0.c0;
INSERT INTO t0 VALUES (1),(2),(3);
INSERT INTO t0 VALUES (1),(2),(3),(4),(5);
SELECT * FROM mvw1;
┌─c0─┐
1. │ 3 │
2. │ 5 │
└────┘
SELECT * FROM mvw2;
┌─c0─┐
1. │ 3 │
2. │ 8 │
└────┘
解释
在上面的示例中,我们有两个物化视图 mvw1 和 mvw2,它们执行类似的操作,但在引用源表 t0 的方式上略有不同。
在 mvw1 中,表 t0 在 JOIN 右侧的 (SELECT * FROM t0) 子查询中被直接引用。当数据插入到 t0 中时,物化视图的查询将执行,插入的数据块将替换 t0。这意味着 join 操作仅在新插入的行上执行,而不是在整个表上执行。
在第二个与 vt0 连接的情况下,视图从 t0 读取所有数据。这确保 join 操作考虑 t0 中的所有行,而不仅仅是新插入的数据块。
为什么这样工作
关键区别在于 ClickHouse 如何处理物化视图查询中的源表。当物化视图由插入触发时,源表(在本例中为 t0)将被插入的数据块替换。可以利用此行为来优化查询,但也需要仔细考虑以避免意外结果。
用例和注意事项
在实践中,您可以使用此行为来优化仅需要处理源表数据子集的物化视图。例如,您可以使用子查询在将源表与其他表连接之前对其进行过滤。这可以帮助减少物化视图处理的数据量并提高性能。
CREATE TABLE t0 (id UInt32, value String) ENGINE = MergeTree() ORDER BY id;
CREATE TABLE t1 (id UInt32, description String) ENGINE = MergeTree() ORDER BY id;
INSERT INTO t1 VALUES (1, 'A'), (2, 'B'), (3, 'C');
CREATE TABLE mvw1_target_table (id UInt32, value String, description String) ENGINE = MergeTree() ORDER BY id;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_target_table AS
SELECT t0.id, t0.value, t1.description
FROM t0
JOIN (SELECT * FROM t1 WHERE t1.id IN (SELECT id FROM t0)) AS t1
ON t0.id = t1.id;
在此示例中,从 IN (SELECT id FROM t0) 子查询构建的集合仅包含新插入的行,这可以帮助根据它过滤 t1。
其他应用
以上主要侧重于使用物化视图来增量更新数据的部分聚合,从而将计算从查询时转移到插入时。除了这种常见的用例之外,物化视图还有许多其他应用。
过滤和转换
在某些情况下,我们可能希望仅在插入时插入行和列的子集。在这种情况下,我们的 posts_null 表可以接收插入,并在插入到 posts 表之前使用 SELECT 查询过滤行。例如,假设我们希望转换 posts 表中的 Tags 列。这包含一个管道分隔的标签名称列表。通过将这些转换为数组,我们可以更轻松地按单个标签值进行聚合。
我们可以在运行
INSERT INTO SELECT时执行此转换。物化视图允许我们将此逻辑封装在 ClickHouse DDL 中,并保持我们的INSERT简单,转换应用于任何新行。
此转换的物化视图如下所示
CREATE MATERIALIZED VIEW posts_mv TO posts AS
SELECT * EXCEPT Tags, arrayFilter(t -> (t != ''), splitByChar('|', Tags)) as Tags FROM posts_null
查找表
用户在选择 ClickHouse 排序键时应考虑其访问模式,并使用经常在过滤器和聚合子句中使用的列。对于用户具有更多样化的访问模式(无法封装在单个列集中)的场景,这可能会受到限制。例如,考虑以下 comments 表
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY PostId
0 rows in set. Elapsed: 46.357 sec. Processed 90.38 million rows, 11.14 GB (1.95 million rows/s., 240.22 MB/s.)
此处的排序键优化了按 PostId 过滤的表的查询。
假设用户希望按特定的 UserId 进行过滤并计算其平均 Score
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.778 sec. Processed 90.38 million rows, 361.59 MB (116.16 million rows/s., 464.74 MB/s.)
Peak memory usage: 217.08 MiB.
虽然速度很快(对于 ClickHouse 来说数据量很小),但我们可以从处理的行数(9038 万)中看出这需要全表扫描。对于更大的数据集,我们可以使用物化视图来查找过滤列 UserId 的排序键值 PostId。然后可以使用这些值来执行高效的查找。
在此示例中,我们的物化视图可以非常简单,仅从插入时的 comments 中选择 PostId 和 UserId。这些结果反过来发送到按 UserId 排序的表 comments_posts_users。我们在下面创建了 Comments 表的 null 版本,并使用它来填充我们的视图和 comments_posts_users 表
CREATE TABLE comments_posts_users (
PostId UInt32,
UserId Int32
) ENGINE = MergeTree ORDER BY UserId
CREATE TABLE comments_null AS comments
ENGINE = Null
CREATE MATERIALIZED VIEW comments_posts_users_mv TO comments_posts_users AS
SELECT PostId, UserId FROM comments_null
INSERT INTO comments_null SELECT * FROM comments
0 rows in set. Elapsed: 5.163 sec. Processed 90.38 million rows, 17.25 GB (17.51 million rows/s., 3.34 GB/s.)
我们现在可以在子查询中使用此视图来加速我们之前的查询
SELECT avg(Score)
FROM comments
WHERE PostId IN (
SELECT PostId
FROM comments_posts_users
WHERE UserId = 8592047
) AND UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 88.61 thousand rows, 771.37 KB (7.09 million rows/s., 61.73 MB/s.)
链式
物化视图可以链接在一起,从而可以建立复杂的工作流程。对于实际示例,我们推荐此博客文章。