在 ClickHouse 中使用 JOIN 操作
ClickHouse 具有 完整的 JOIN 操作支持,以及多种连接算法。为了最大化性能,我们建议遵循本指南中列出的连接优化建议。
- 为了获得最佳性能,用户应尽量减少查询中
JOIN的数量,特别是对于需要毫秒级性能的实时分析工作负载。目标是在一个查询中最多使用 3 到 4 个连接。我们在数据建模部分中详细介绍了减少连接数量的多种方法,包括反规范化、字典和物化视图。 - 目前,ClickHouse 不会对连接进行重新排序。始终确保最小的表位于 JOIN 的右侧。对于大多数连接算法,这将保存在内存中,并将确保查询的最低内存开销。
- 如果您的查询需要直接连接,即
LEFT ANY JOIN- 如下所示,我们建议尽可能使用字典。
- 如果执行内连接,通常更优的方法是将这些写成使用
IN子查询。考虑以下功能等效的查询。两者都查找在问题中没有提及 ClickHouse 但在comments中提及的posts数量。
SELECT count()
FROM stackoverflow.posts AS p
ANY INNER `JOIN` stackoverflow.comments AS c ON p.Id = c.PostId
WHERE (p.Title != '') AND (p.Title NOT ILIKE '%clickhouse%') AND (p.Body NOT ILIKE '%clickhouse%') AND (c.Text ILIKE '%clickhouse%')
┌─count()─┐
│ 86 │
└─────────┘
1 row in set. Elapsed: 8.209 sec. Processed 150.20 million rows, 56.05 GB (18.30 million rows/s., 6.83 GB/s.)
Peak memory usage: 1.23 GiB.
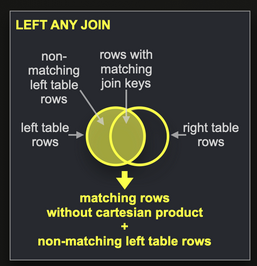
请注意,我们使用 ANY INNER JOIN 而不是仅仅使用 INNER 连接,因为我们不希望出现笛卡尔积,即我们只希望每个帖子有一个匹配项。
这个连接可以使用子查询重写,从而显着提高性能
SELECT count()
FROM stackoverflow.posts
WHERE (Title != '') AND (Title NOT ILIKE '%clickhouse%') AND (Body NOT ILIKE '%clickhouse%') AND (Id IN (
SELECT PostId
FROM stackoverflow.comments
WHERE Text ILIKE '%clickhouse%'
))
┌─count()─┐
│ 86 │
└─────────┘
1 row in set. Elapsed: 2.284 sec. Processed 150.20 million rows, 16.61 GB (65.76 million rows/s., 7.27 GB/s.)
Peak memory usage: 323.52 MiB.
尽管 ClickHouse 尝试将条件向下推送到所有连接子句和子查询,但我们建议用户始终在所有可能的子句上手动应用条件 - 从而最大限度地减少要 JOIN 的数据大小。考虑以下示例,我们想要计算自 2020 年以来与 Java 相关的帖子的赞成票数。
一个朴素的查询,左侧是较大的表,在 56 秒内完成
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.posts AS p
INNER JOIN stackoverflow.votes AS v ON p.Id = v.PostId
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 56.642 sec. Processed 252.30 million rows, 1.62 GB (4.45 million rows/s., 28.60 MB/s.)
重新排序此连接可将性能显着提高到 1.5 秒
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.votes AS v
INNER JOIN stackoverflow.posts AS p ON v.PostId = p.Id
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 1.519 sec. Processed 252.30 million rows, 1.62 GB (166.06 million rows/s., 1.07 GB/s.)
在右侧表上添加过滤器可将性能进一步提高到 0.5 秒。
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.votes AS v
INNER JOIN stackoverflow.posts AS p ON v.PostId = p.Id
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01') AND (v.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 0.597 sec. Processed 81.14 million rows, 1.31 GB (135.82 million rows/s., 2.19 GB/s.)
Peak memory usage: 249.42 MiB.
通过将 INNER JOIN 移动到子查询,可以进一步改进此查询,如前所述,保持外部和内部查询上的过滤器。
SELECT count() AS upvotes
FROM stackoverflow.votes
WHERE (VoteTypeId = 2) AND (PostId IN (
SELECT Id
FROM stackoverflow.posts
WHERE (CreationDate >= '2020-01-01') AND has(arrayFilter(t -> (t != ''), splitByChar('|', Tags)), 'java')
))
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 0.383 sec. Processed 99.64 million rows, 804.55 MB (259.85 million rows/s., 2.10 GB/s.)
Peak memory usage: 250.66 MiB.
选择连接算法
ClickHouse 支持多种连接算法。这些算法通常以内存使用量换取性能。以下概述了 ClickHouse 连接算法,基于它们的相对内存消耗和执行时间
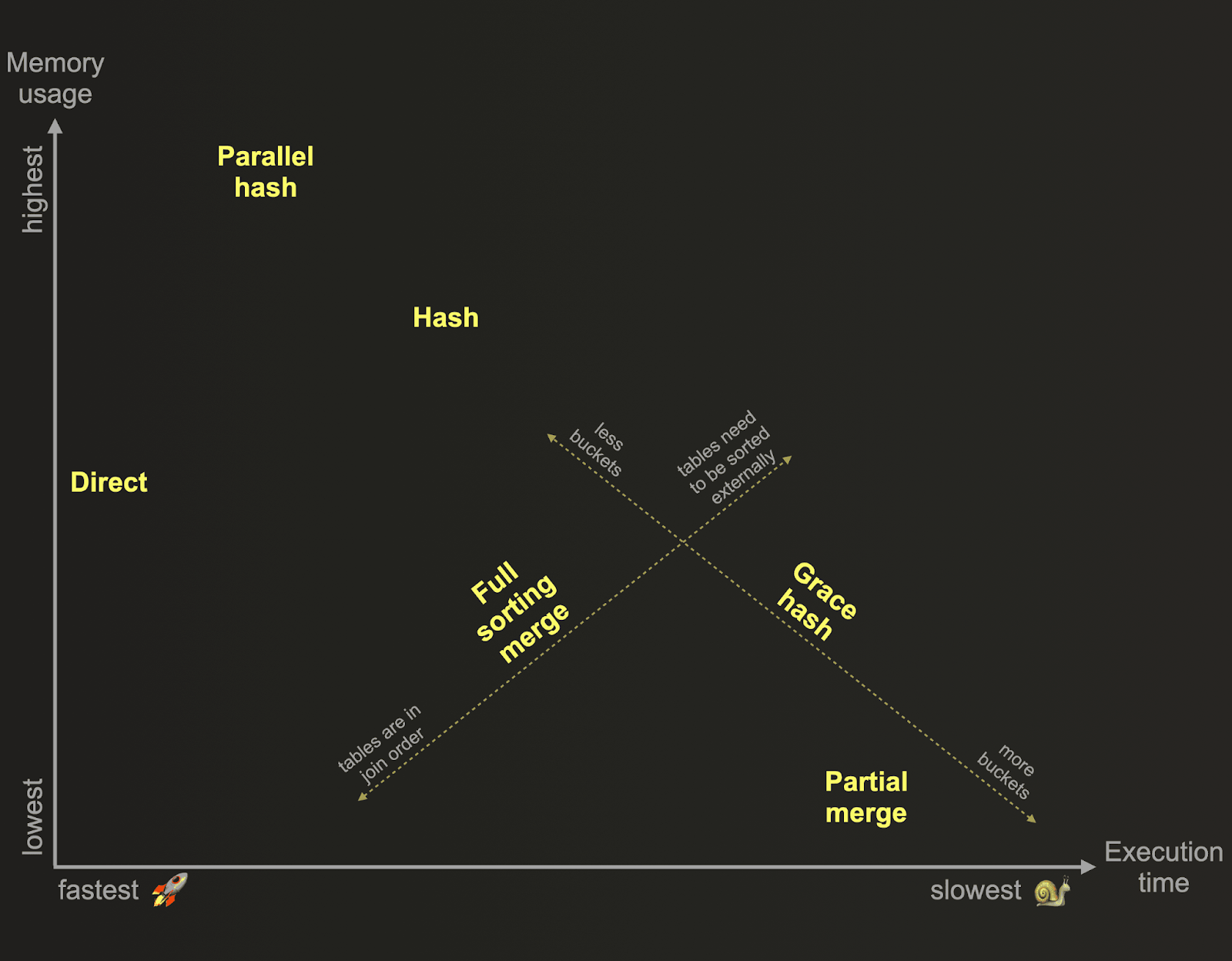
这些算法决定了连接查询的计划和执行方式。默认情况下,ClickHouse 根据使用的连接类型和严格性以及连接表的引擎,使用直接或哈希连接算法。或者,可以将 ClickHouse 配置为自适应地选择和动态更改运行时要使用的连接算法,具体取决于资源可用性和使用情况:当 join_algorithm=auto 时,ClickHouse 首先尝试哈希连接算法,如果该算法的内存限制被违反,则算法会动态切换到部分合并连接。您可以通过跟踪日志观察选择的算法。ClickHouse 还允许用户通过 join_algorithm 设置自行指定所需的连接算法。
下表显示了每种连接算法支持的 JOIN 类型,在优化之前应考虑这些类型
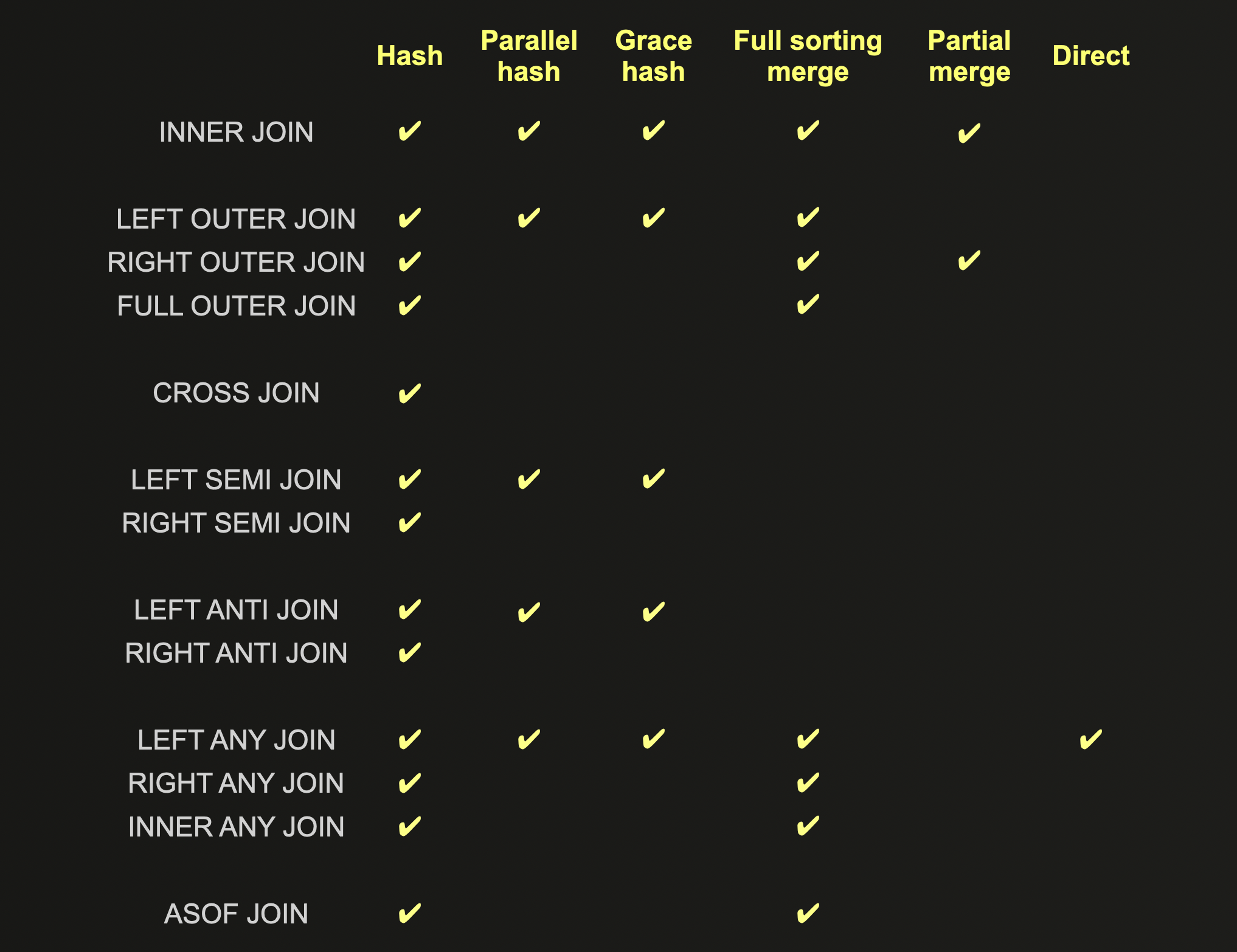
每种 JOIN 算法的完整详细描述可以在这里找到,包括它们的优点、缺点和扩展属性。
选择合适的连接算法取决于您是希望优化内存还是性能。
优化 JOIN 性能
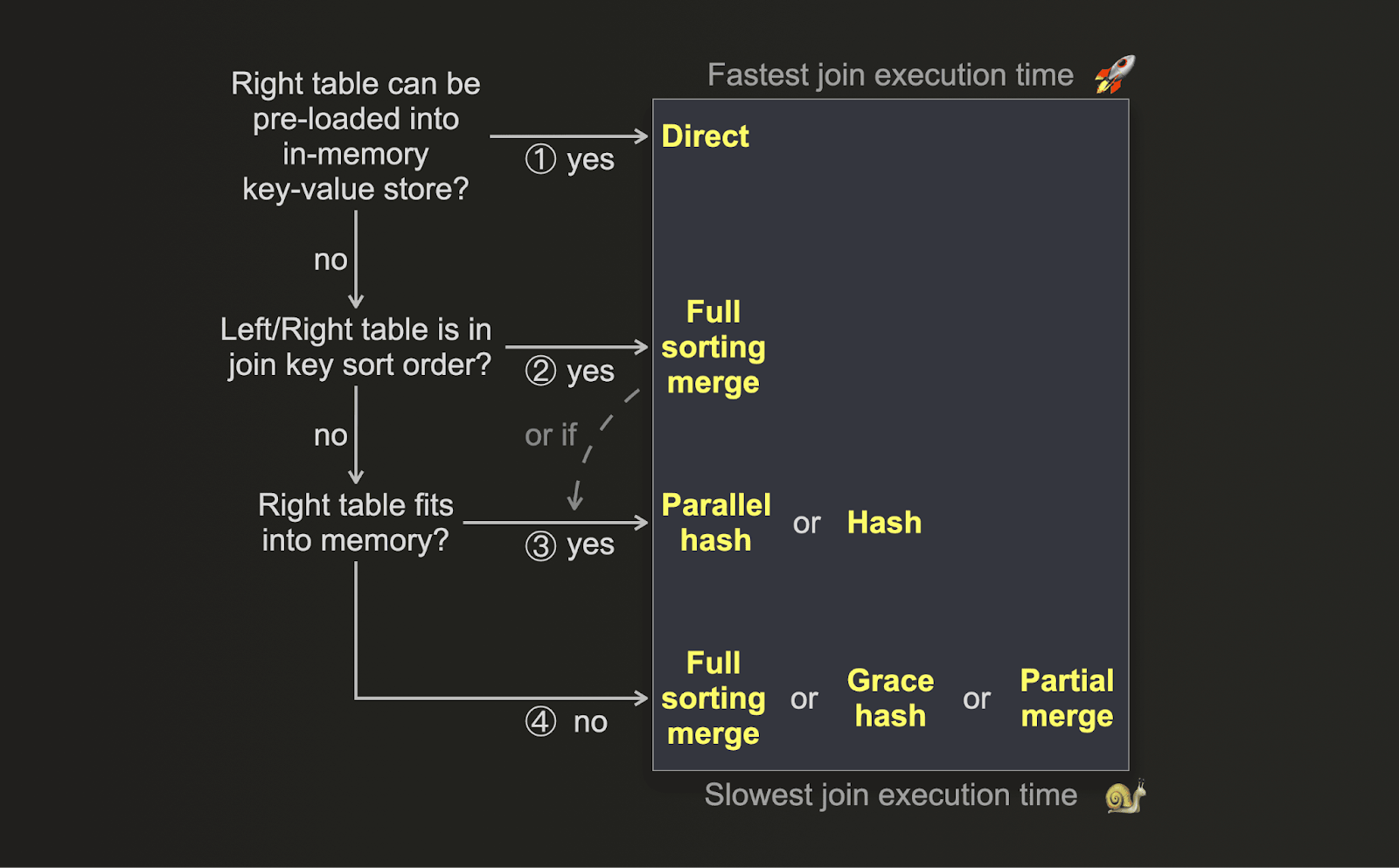
如果您的关键优化指标是性能,并且您希望尽可能快地执行连接,则可以使用以下决策树来选择正确的连接算法
-
(1) 如果可以预先将右侧表中的数据加载到内存中的低延迟键值数据结构中,例如字典,并且如果连接键与底层键值存储的键属性匹配,并且如果
LEFT ANY JOIN语义足够 - 那么直接连接是适用的,并且提供了最快的方法。 -
(2) 如果您的表的物理行顺序与连接键排序顺序匹配,则情况取决于具体情况。在这种情况下,完全排序合并连接 跳过排序阶段,从而显着减少内存使用量,并且,根据数据大小和连接键值分布,执行时间比某些哈希连接算法更快。
-
(3) 如果右表可以放入内存,即使考虑到并行哈希连接的额外内存使用开销,那么此算法或哈希连接可能会更快。这取决于数据大小、数据类型和连接键列的值分布。
-
(4) 如果右表无法放入内存,则再次取决于具体情况。ClickHouse 提供三种非内存限制连接算法。所有三种算法都会暂时将数据溢出到磁盘。完全排序合并连接和部分合并连接需要事先对数据进行排序。Grace 哈希连接改为从数据构建哈希表。根据数据量、数据类型和连接键列的值分布,在某些情况下,从数据构建哈希表比对数据进行排序更快。反之亦然。
部分合并连接经过优化,可在连接大表时最大限度地减少内存使用量,但代价是连接速度较慢。当左表的物理行顺序与连接键排序顺序不匹配时,尤其如此。
Grace 哈希连接是三种非内存限制连接算法中最灵活的一种,并通过其 grace_hash_join_initial_buckets 设置,可以很好地控制内存使用量与连接速度之间的平衡。根据数据量,当 buckets 的数量选择得使两种算法的内存使用量大致对齐时,grace 哈希可能比部分合并算法更快或更慢。当 grace 哈希连接的内存使用量配置为与完全排序合并的内存使用量大致对齐时,在我们的测试运行中,完全排序合并始终更快。
三种非内存限制算法中哪种最快取决于数据量、数据类型和连接键列的值分布。为了确定哪种算法最快,最好始终使用具有真实数据量的真实数据运行一些基准测试。
优化内存
如果您想优化连接以获得最低的内存使用量而不是最快的执行时间,则可以使用此决策树
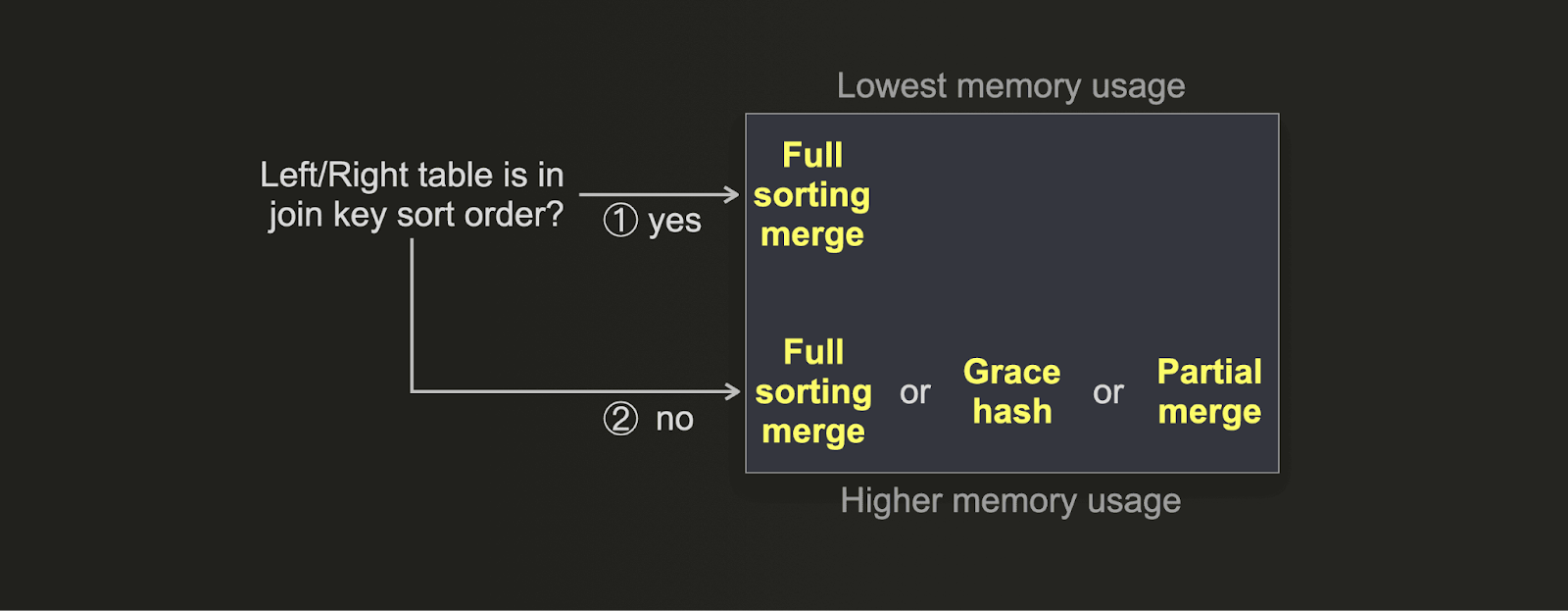
- (1) 如果您的表的物理行顺序与连接键排序顺序匹配,则完全排序合并连接的内存使用量是最低的。此外,由于排序阶段已禁用,因此连接速度也很好。
- (2) 可以调整 grace 哈希连接以获得非常低的内存使用量,方法是配置大量的buckets,但会牺牲连接速度。部分合并连接有意使用少量主内存。启用外部排序的完全排序合并连接通常比部分合并连接使用更多内存(假设行顺序与键排序顺序不匹配),但好处是连接执行时间显着缩短。
对于需要了解上述更多详细信息的用户,我们推荐以下博客系列。