表部件
ClickHouse 中的表部件是什么?
ClickHouse MergeTree 引擎族中每个表的数据在磁盘上组织为一组不可变的 data parts。
为了说明这一点,我们使用此表(改编自英国房价数据集),跟踪英国已售房产的日期、城镇、街道和价格
CREATE TABLE uk.uk_price_paid_simple
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street);
您可以在我们的 ClickHouse SQL Playground 中查询此表。
每当将一组行插入到表中时,就会创建一个数据部件。下图描绘了这一点
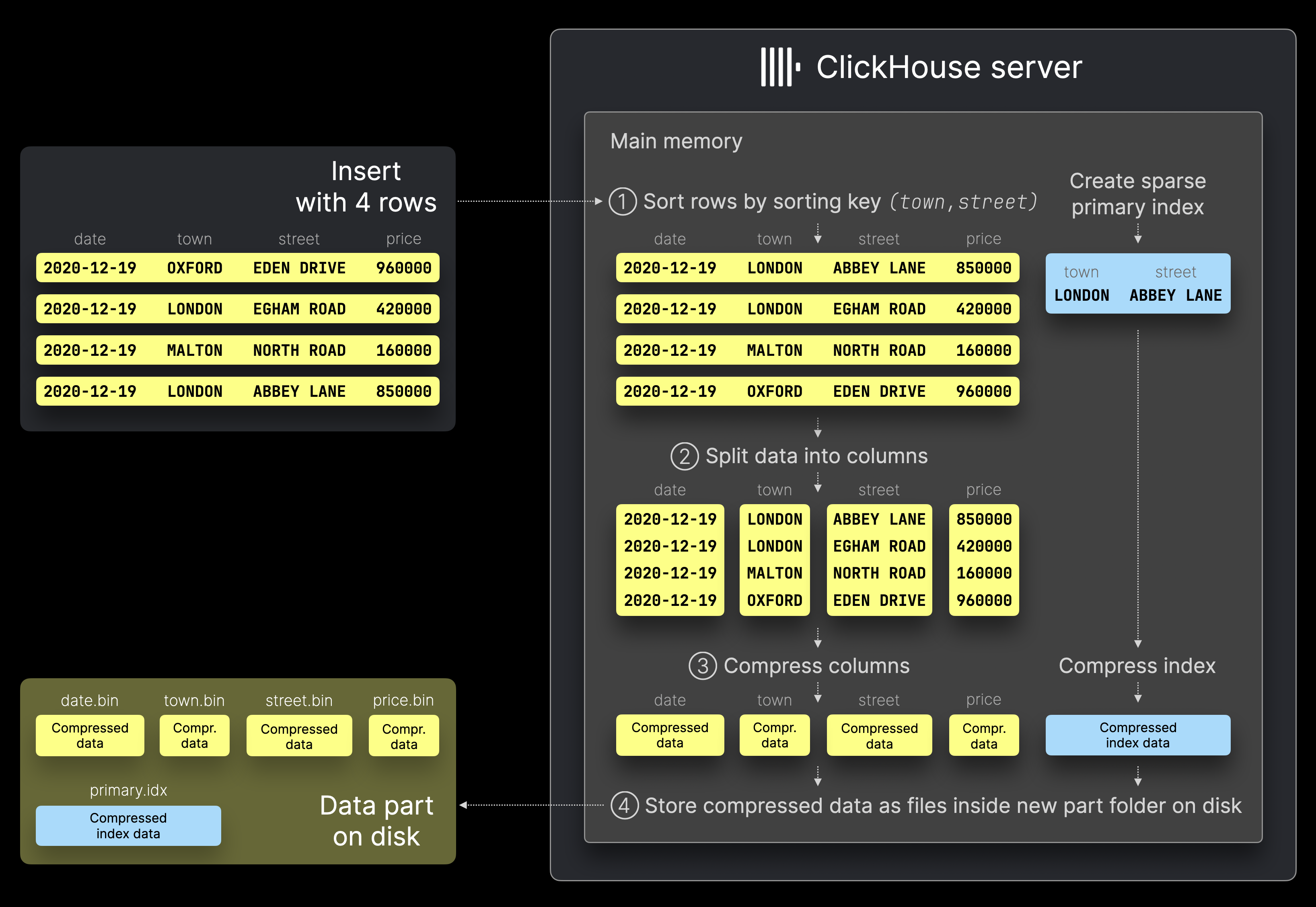
当 ClickHouse 服务器处理包含 4 行的示例插入(例如,通过 INSERT INTO 语句)时,它会执行以下几个步骤
① 排序:行按照表的排序键 (town, street) 排序,并为排序后的行生成一个稀疏主索引。
② 分割:排序后的数据被分割成列。
③ 压缩:每列都被压缩。
④ 写入磁盘:压缩后的列以二进制列文件的形式保存在一个新目录中,该目录代表插入的数据部件。稀疏主索引也被压缩并存储在同一目录中。
根据表的具体引擎,除了排序之外,可能还会发生其他转换。
数据部件是自包含的,包括解释其内容所需的所有元数据,而无需中央目录。除了稀疏主索引外,部件还包含额外的元数据,例如二级数据跳过索引、列统计信息、校验和、min-max 索引(如果使用分区)以及更多。
为了管理每个表的部件数量,后台合并作业会定期将较小的部件合并为较大的部件,直到它们达到可配置的压缩大小(通常约为 150 GB)。合并后的部件被标记为非活动状态,并在可配置的时间间隔后删除。随着时间的推移,此过程创建了合并部件的层次结构,这就是为什么它被称为 MergeTree 表
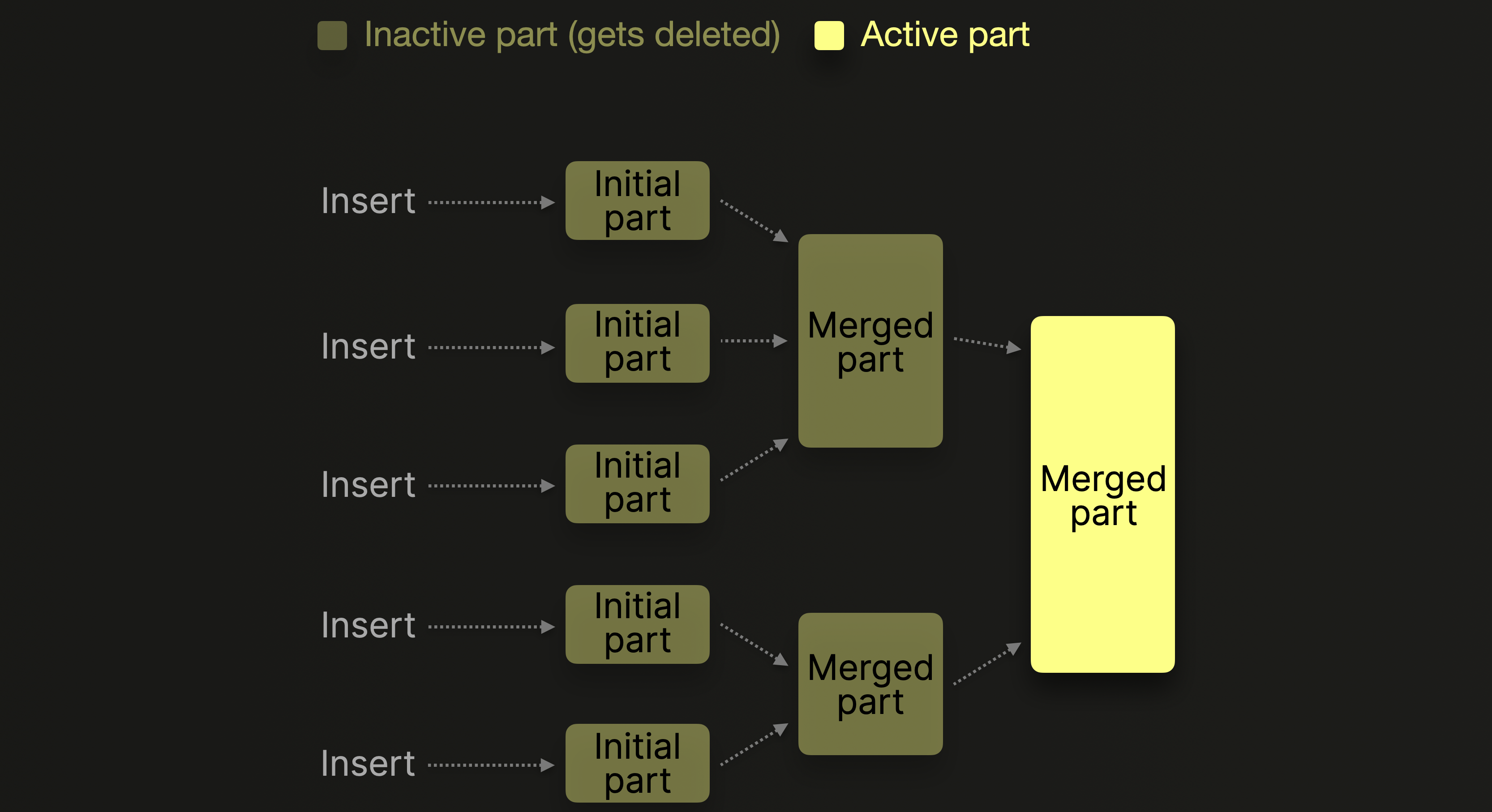
为了最大限度地减少初始部件的数量和合并的开销,建议数据库客户端批量插入元组,例如一次 20,000 行,或者使用异步插入模式,在这种模式下,ClickHouse 会缓冲来自多个传入 INSERT 到同一表中的行,并且仅在缓冲区大小超过可配置的阈值或超时到期后才创建新部件。
您可以使用虚拟列 _part 查询我们示例表中当前所有活动部件的列表
SELECT _part
FROM uk.uk_price_paid_simple
GROUP BY _part
ORDER BY _part ASC;
┌─_part───────┐
1. │ all_0_5_1 │
2. │ all_12_17_1 │
3. │ all_18_23_1 │
4. │ all_6_11_1 │
└─────────────┘
上面的查询检索磁盘上目录的名称,每个目录代表表的活动数据部件。这些目录名称的组成部分具有特定的含义,对于有兴趣进一步探索的人,此处有文档记录。
或者,ClickHouse 在 system.parts 系统表中跟踪所有表的所有部件的信息,以下查询返回我们上面示例表的当前所有活动部件的列表、它们的合并级别以及存储在这些部件中的行数
SELECT
name,
level,
rows
FROM system.parts
WHERE (database = 'uk') AND (`table` = 'uk_price_paid_simple') AND active
ORDER BY name ASC;
┌─name────────┬─level─┬────rows─┐
1. │ all_0_5_1 │ 1 │ 6368414 │
2. │ all_12_17_1 │ 1 │ 6442494 │
3. │ all_18_23_1 │ 1 │ 5977762 │
4. │ all_6_11_1 │ 1 │ 6459763 │
└─────────────┴───────┴─────────┘
每次对部件进行额外的合并,合并级别都会增加一。级别为 0 表示这是一个尚未合并的新部件。