表分区
什么是 ClickHouse 中的表分区?
分区将 MergeTree 引擎系列中表的数据 parts 分组为有组织的逻辑单元,这是一种组织数据的方式,在概念上是有意义的,并且与特定标准(例如时间范围、类别或其他关键属性)对齐。这些逻辑单元使数据更易于管理、查询和优化。
当通过 PARTITION BY 子句 最初定义表时,可以启用分区。此子句可以包含任何列上的 SQL 表达式,其结果将定义行所属的分区。
为了说明这一点,我们增强了什么是表 parts 示例表,通过添加 PARTITION BY toStartOfMonth(date) 子句,该子句根据属性销售的月份组织表的数据 parts
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street)
PARTITION BY toStartOfMonth(date);
您可以在我们的 ClickHouse SQL Playground 中查询此表。
每当将一组行插入到表中时,ClickHouse 会为插入行中每个唯一分区键值创建一个新的数据 part,而不是创建(至少)包含所有插入行的单个数据 part(如此处所述)
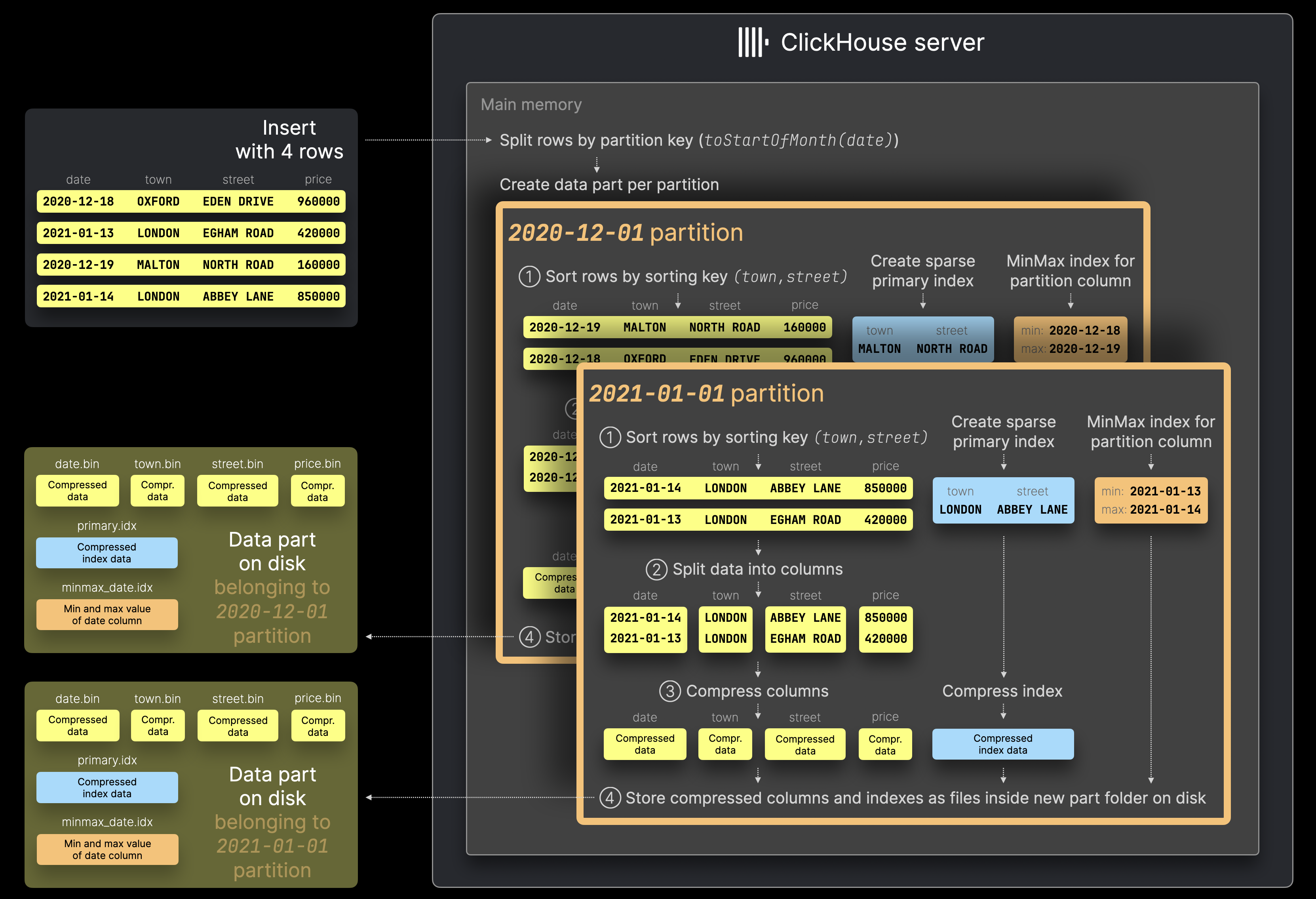
ClickHouse 服务器首先按分区键值 toStartOfMonth(date) 分割来自上述图表中草绘的具有 4 行的示例插入的行。然后,对于每个已识别的分区,这些行将按照通常的方式进行处理,执行几个连续步骤(① 排序,② 拆分为列,③ 压缩,④ 写入磁盘)。
请注意,启用分区后,ClickHouse 会自动为每个数据 part 创建 MinMax 索引。这些只是用于分区键表达式的每个表列的文件,其中包含该列在数据 part 中的最小值和最大值。
进一步注意,启用分区后,ClickHouse 仅在分区内合并数据 parts,而不是跨分区合并。我们为上面示例表草绘了这一点
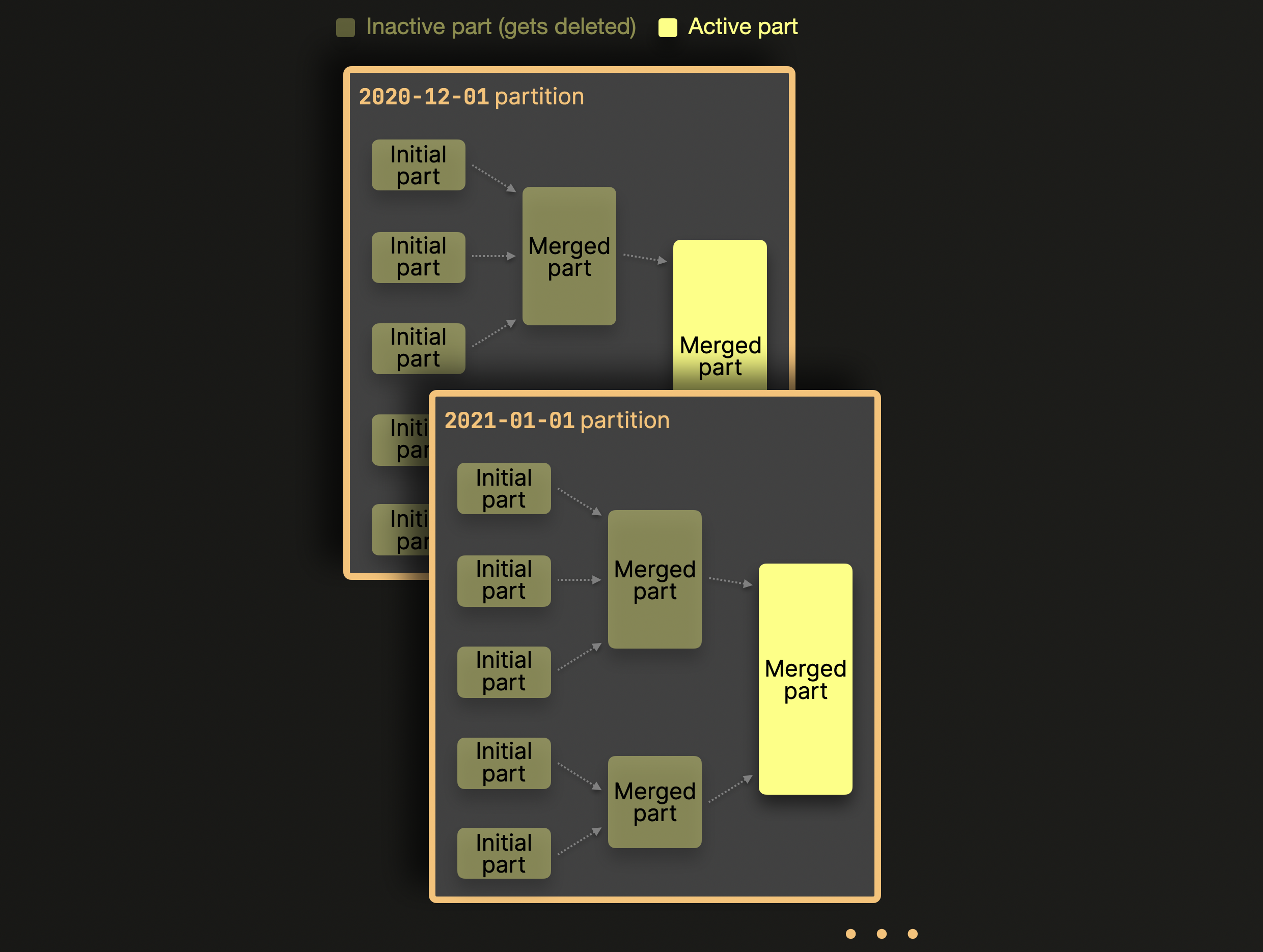
如上图所示,属于不同分区的 parts 永远不会合并。如果选择了高基数的分区键,则分布在数千个分区中的 parts 将永远不会成为合并候选对象 - 超过预配置的限制并导致可怕的 Too many parts 错误。解决此问题很简单:选择一个明智的分区键,其基数低于 1000..10000。
您可以通过使用虚拟列 _partition_value查询示例表的所有现有唯一分区的列表
SELECT DISTINCT _partition_value AS partition
FROM uk.uk_price_paid_simple_partitioned
ORDER BY partition ASC;
┌─partition──────┐
1. │ ('1995-01-01') │
2. │ ('1995-02-01') │
3. │ ('1995-03-01') │
...
304. │ ('2021-04-01') │
305. │ ('2021-05-01') │
306. │ ('2021-06-01') │
└────────────────┘
或者,ClickHouse 在system.parts 系统表中跟踪所有表的所有 parts 和分区,以下查询返回上面示例表的当前所有分区的列表,以及每个分区的当前活动 parts 数量和这些 parts 中的行数总和
SELECT
partition,
count() AS parts,
sum(rows) AS rows
FROM system.parts
WHERE (database = 'uk') AND (`table` = 'uk_price_paid_simple_partitioned') AND active
GROUP BY partition
ORDER BY partition ASC;
┌─partition──┬─parts─┬───rows─┐
1. │ 1995-01-01 │ 1 │ 50473 │
2. │ 1995-02-01 │ 1 │ 50840 │
3. │ 1995-03-01 │ 1 │ 71276 │
...
304. │ 2021-04-01 │ 3 │ 23160 │
305. │ 2021-05-01 │ 3 │ 17607 │
306. │ 2021-06-01 │ 3 │ 5652 │
└─partition──┴─parts─┴───rows─┘
表分区用于什么?
数据管理
在 ClickHouse 中,分区主要是一个数据管理功能。通过基于分区表达式以逻辑方式组织数据,可以独立管理每个分区。例如,上面示例表中的分区方案启用了以下场景:仅在主表中保留最近 12 个月的数据,方法是使用 TTL 规则自动删除旧数据(请参阅 DDL 语句的添加的最后一行)
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
PARTITION BY toStartOfMonth(date)
ORDER BY (town, street)
TTL date + INTERVAL 12 MONTH DELETE;
由于表按 toStartOfMonth(date) 分区,因此将删除满足 TTL 条件的整个分区(表 parts 集),从而使清理操作更高效,无需重写 parts。
同样,与其删除旧数据,不如自动且有效地将其移动到更具成本效益的存储层
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
PARTITION BY toStartOfMonth(date)
ORDER BY (town, street)
TTL date + INTERVAL 12 MONTH TO VOLUME 'slow_but_cheap';
查询优化
分区可以帮助提高查询性能,但这在很大程度上取决于访问模式。如果查询仅针对少数分区(理想情况下为一个),则性能可能会提高。这通常仅在分区键不在主键中并且您按分区键进行过滤时才有用,如下面的示例查询所示。
SELECT MAX(price) AS highest_price
FROM uk_price_paid_simple_partitioned
WHERE date >= '2020-12-01'
AND date <= '2020-12-31'
AND town = 'LONDON';
┌─highest_price─┐
1. │ 296280000 │ -- 296.28 million
└───────────────┘
1 row in set. Elapsed: 0.006 sec. Processed 8.19 thousand rows, 57.34 KB (1.36 million rows/s., 9.49 MB/s.)
Peak memory usage: 2.73 MiB.
该查询在上面的示例表上运行,并通过按表的分区键中使用的列 (date) 和表的主键中使用的列 (town) 进行过滤来计算 2020 年 12 月伦敦所有售出房产的最高价格(并且 date 不是主键的一部分)。
ClickHouse 通过应用一系列剪枝技术来处理该查询,以避免评估不相关的数据
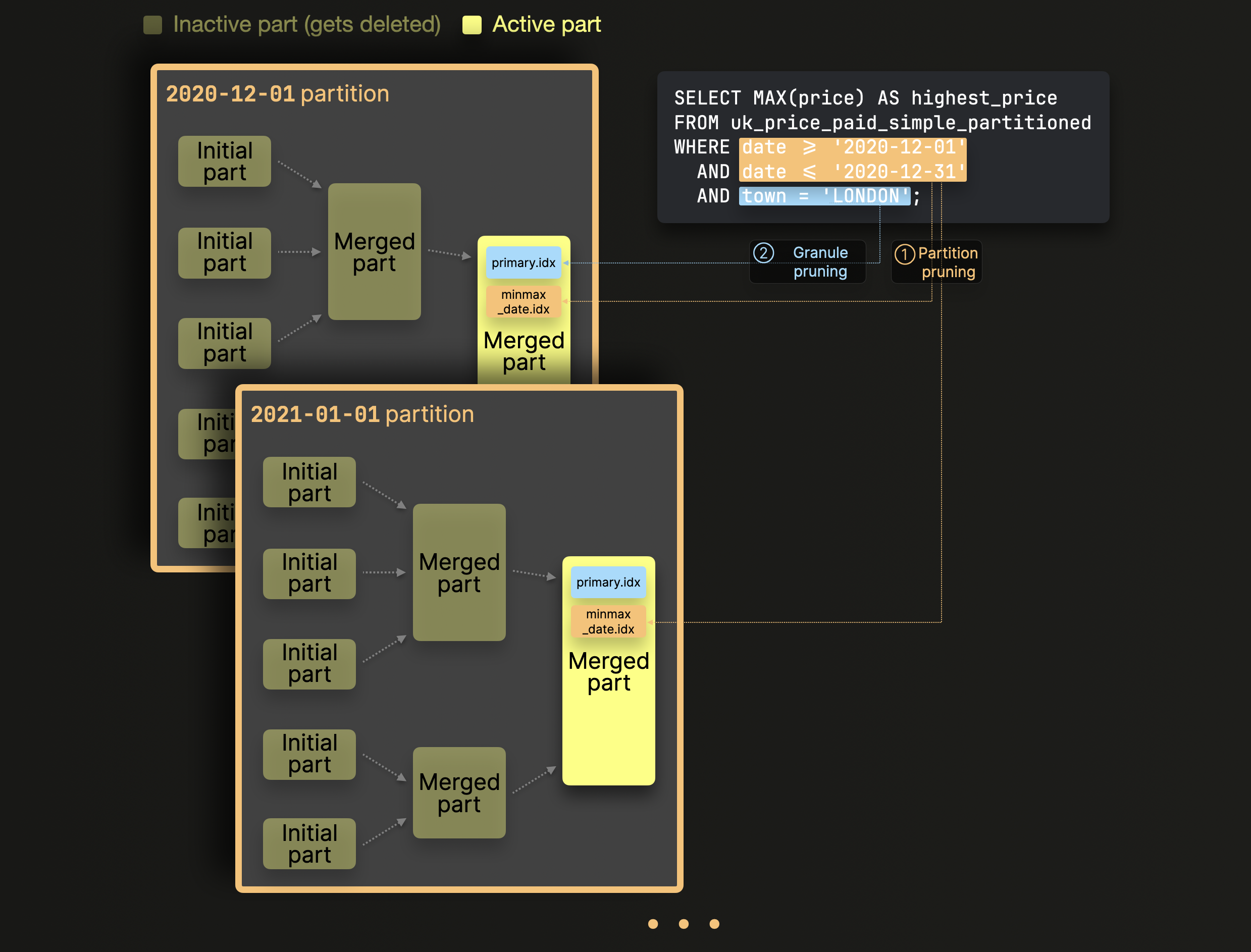
① 分区剪枝:MinMax 索引用于忽略逻辑上无法匹配查询在表分区键中使用的列上的过滤器的整个分区(parts 集)。
② 粒度剪枝:对于步骤 ① 之后剩余的数据 parts,其主索引用于忽略逻辑上无法匹配查询在表主键中使用的列上的过滤器的所有粒度(行块)。
我们可以通过检查上面示例查询的物理查询执行计划,通过 EXPLAIN 子句
EXPLAIN indexes = 1
SELECT MAX(price) AS highest_price
FROM uk_price_paid_simple_partitioned
WHERE date >= '2020-12-01'
AND date <= '2020-12-31'
AND town = 'LONDON';
┌─explain──────────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Expression │
5. │ ReadFromMergeTree (uk.uk_price_paid_simple_partitioned) │
6. │ Indexes: │
7. │ MinMax │
8. │ Keys: │
9. │ date │
10. │ Condition: and((date in (-Inf, 18627]), (date in [18597, +Inf))) │
11. │ Parts: 1/436 │
12. │ Granules: 11/3257 │
13. │ Partition │
14. │ Keys: │
15. │ toStartOfMonth(date) │
16. │ Condition: and((toStartOfMonth(date) in (-Inf, 18597]), (toStartOfMonth(date) in [18597, +Inf))) │
17. │ Parts: 1/1 │
18. │ Granules: 11/11 │
19. │ PrimaryKey │
20. │ Keys: │
21. │ town │
22. │ Condition: (town in ['LONDON', 'LONDON']) │
23. │ Parts: 1/1 │
24. │ Granules: 1/11 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
上面的输出显示
① 分区剪枝:上面 EXPLAIN 输出的第 7 到 18 行显示,ClickHouse 首先使用 date 字段的MinMax 索引来识别 3257 个现有粒度(行块)中的 11 个(存储在 436 个现有活动数据 parts 中的 1 个中),这些粒度包含与查询的 date 过滤器匹配的行。
② 粒度剪枝:上面 EXPLAIN 输出的第 19 到 24 行表明,ClickHouse 随后使用步骤 ① 中标识的数据 part 的主索引(在 town 字段上创建)来
进一步将粒度数量(其中包含可能也与查询的 town 过滤器匹配的行)从 11 个减少到 1 个。这也反映在我们上面为查询运行打印的 ClickHouse 客户端输出中
... Elapsed: 0.006 sec. Processed 8.19 thousand rows, 57.34 KB (1.36 million rows/s., 9.49 MB/s.)
Peak memory usage: 2.73 MiB.
这意味着 ClickHouse 扫描并处理了 1 个粒度(8192 行的块),在 6 毫秒内计算出查询结果。
分区主要是一个数据管理功能
请注意,跨所有分区查询通常比在非分区表上运行相同查询要慢。
通过分区,数据通常分布在更多数据 parts 中,这通常导致 ClickHouse 扫描和处理更大量的数据。
我们可以通过在什么是表 parts 示例表(未启用分区)和我们当前的上面示例表(已启用分区)上运行相同的查询来演示这一点。两个表包含相同的数据和行数
SELECT
table,
sum(rows) AS rows
FROM system.parts
WHERE (database = 'uk') AND (table IN ['uk_price_paid_simple', 'uk_price_paid_simple_partitioned']) AND active
GROUP BY table;
┌─table────────────────────────────┬─────rows─┐
1. │ uk_price_paid_simple │ 25248433 │
2. │ uk_price_paid_simple_partitioned │ 25248433 │
└──────────────────────────────────┴──────────┘
但是,启用分区的表具有更多活动的数据 parts,因为如上所述,ClickHouse 仅在分区内合并数据 parts,而不是跨分区合并
SELECT
table,
count() AS parts
FROM system.parts
WHERE (database = 'uk') AND (table IN ['uk_price_paid_simple', 'uk_price_paid_simple_partitioned']) AND active
GROUP BY table;
┌─table────────────────────────────┬─parts─┐
1. │ uk_price_paid_simple │ 1 │
2. │ uk_price_paid_simple_partitioned │ 436 │
└──────────────────────────────────┴───────┘
如上文进一步所示,分区表 uk_price_paid_simple_partitioned 具有 306 个分区,因此至少有 306 个活动数据 parts。而对于我们的非分区表 uk_price_paid_simple,所有初始数据 parts 都可以通过后台合并合并为单个活动 part。
当我们使用EXPLAIN 子句检查物理查询执行计划时,对于没有在分区表上运行分区过滤器的上面示例查询,我们可以在下面输出的第 19 行和第 20 行看到,ClickHouse 识别出 3257 个现有粒度(行块)中的 671 个,分布在 436 个现有活动数据 parts 中的 431 个上,这些 parts 可能包含与查询过滤器匹配的行,因此将被查询引擎扫描和处理
EXPLAIN indexes = 1
SELECT MAX(price) AS highest_price
FROM uk.uk_price_paid_simple_partitioned
WHERE town = 'LONDON';
┌─explain─────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Expression │
5. │ ReadFromMergeTree (uk.uk_price_paid_simple_partitioned) │
6. │ Indexes: │
7. │ MinMax │
8. │ Condition: true │
9. │ Parts: 436/436 │
10. │ Granules: 3257/3257 │
11. │ Partition │
12. │ Condition: true │
13. │ Parts: 436/436 │
14. │ Granules: 3257/3257 │
15. │ PrimaryKey │
16. │ Keys: │
17. │ town │
18. │ Condition: (town in ['LONDON', 'LONDON']) │
19. │ Parts: 431/436 │
20. │ Granules: 671/3257 │
└─────────────────────────────────────────────────────────────────┘
在没有分区的表上运行的相同示例查询的物理查询执行计划显示在下面输出的第 11 行和第 12 行中,ClickHouse 识别出表的单个活动数据 part 中 3083 个现有行块中的 241 个,这些块可能包含与查询过滤器匹配的行
EXPLAIN indexes = 1
SELECT MAX(price) AS highest_price
FROM uk.uk_price_paid_simple
WHERE town = 'LONDON';
┌─explain───────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Expression │
5. │ ReadFromMergeTree (uk.uk_price_paid_simple) │
6. │ Indexes: │
7. │ PrimaryKey │
8. │ Keys: │
9. │ town │
10. │ Condition: (town in ['LONDON', 'LONDON']) │
11. │ Parts: 1/1 │
12. │ Granules: 241/3083 │
└───────────────────────────────────────────────────────┘
对于在分区表版本上运行查询,ClickHouse 在 90 毫秒内扫描和处理 671 个行块(约 550 万行)
SELECT MAX(price) AS highest_price
FROM uk.uk_price_paid_simple_partitioned
WHERE town = 'LONDON';
┌─highest_price─┐
1. │ 594300000 │ -- 594.30 million
└───────────────┘
1 row in set. Elapsed: 0.090 sec. Processed 5.48 million rows, 27.95 MB (60.66 million rows/s., 309.51 MB/s.)
Peak memory usage: 163.44 MiB.
而对于在非分区表上运行查询,ClickHouse 在 12 毫秒内扫描和处理 241 个块(约 200 万行)的行
SELECT MAX(price) AS highest_price
FROM uk.uk_price_paid_simple
WHERE town = 'LONDON';
┌─highest_price─┐
1. │ 594300000 │ -- 594.30 million
└───────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 1.97 million rows, 9.87 MB (162.23 million rows/s., 811.17 MB/s.)
Peak memory usage: 62.02 MiB.