ReplacingMergeTree
虽然事务数据库针对事务更新和删除工作负载进行了优化,但 OLAP 数据库为此类操作提供的保证有所降低。相反,它们针对批量插入的不可变数据进行优化,从而显著加快分析查询速度。虽然 ClickHouse 通过 mutations 提供更新操作,以及轻量级的删除行的方法,但其面向列的结构意味着应谨慎安排这些操作,如上所述。这些操作是异步处理的,使用单线程处理,并且(在更新的情况下)需要将数据重写到磁盘上。因此,它们不应用于大量的小更改。为了处理更新和删除行的流,同时避免上述使用模式,我们可以使用 ClickHouse 表引擎 ReplacingMergeTree。
自动更新插入的行
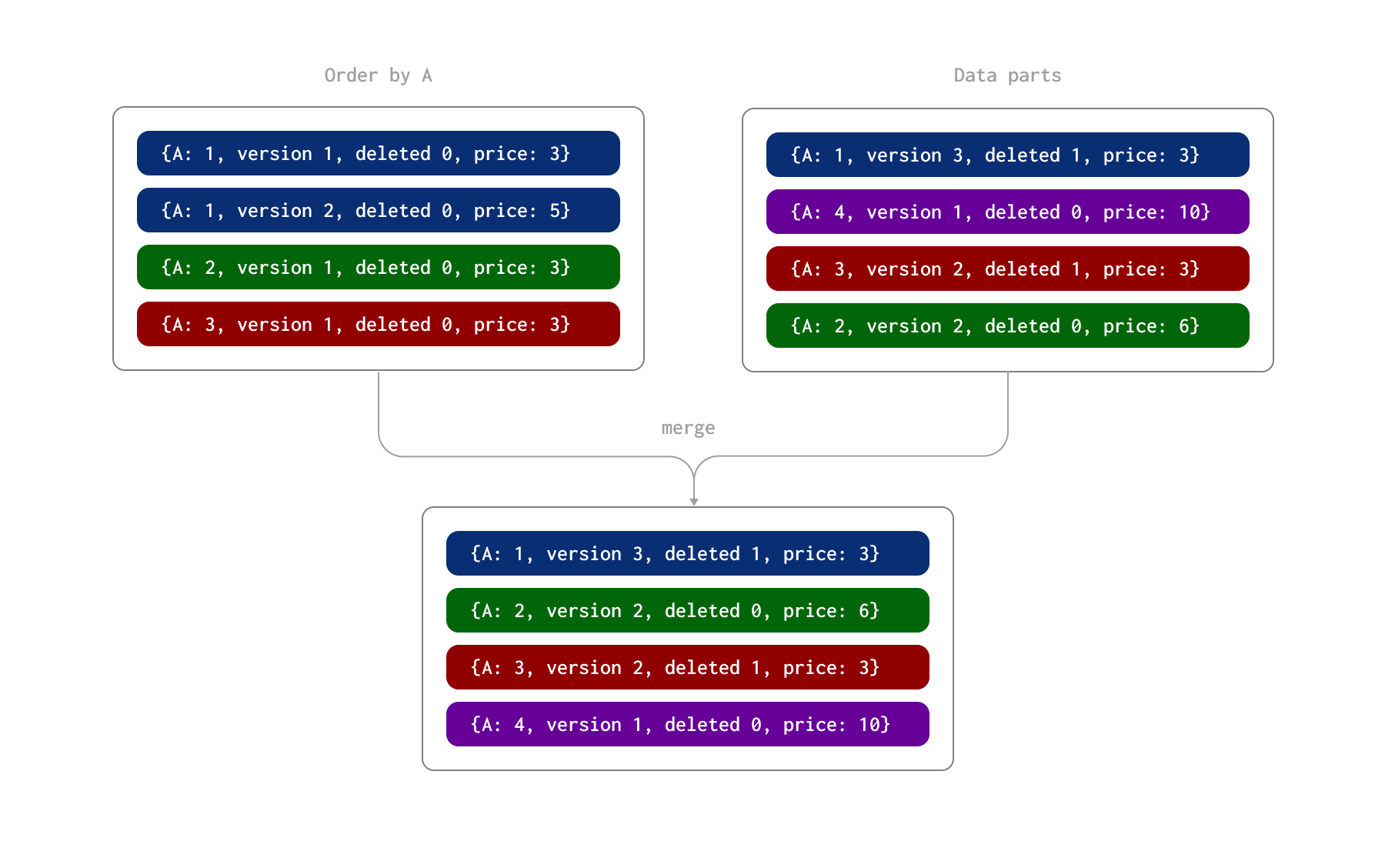
ReplacingMergeTree 表引擎允许对行应用更新操作,而无需使用低效的 ALTER 或 DELETE 语句,它允许用户插入同一行的多个副本,并将其中一个副本指定为最新版本。反过来,后台进程会异步删除同一行的旧版本,通过使用不可变插入有效地模拟更新操作。这依赖于表引擎识别重复行的能力。这是通过使用 ORDER BY 子句来确定唯一性来实现的,即,如果两行在 ORDER BY 中指定的列具有相同的值,则认为它们是重复的。在定义表时指定的 version 列允许在识别出两行是重复项时保留行的最新版本,即保留版本值最高的行。我们在下面的示例中说明了此过程。在此,行由 A 列(表的 ORDER BY)唯一标识。我们假设这些行已作为两个批次插入,从而在磁盘上形成两个数据 parts。稍后,在异步后台进程期间,这些 parts 将合并在一起。
ReplacingMergeTree 还允许指定 deleted 列。它可以包含 0 或 1,其中值 1 表示该行(及其重复项)已被删除,否则使用零。注意:已删除的行在合并时不会被删除。
在此过程中,part 合并期间会发生以下情况
- 由列 A 的值 1 标识的行既有版本为 2 的更新行,又有版本为 3 的删除行(以及 deleted 列值为 1)。因此,保留了标记为已删除的最新行。
- 由列 A 的值 2 标识的行有两行更新行。保留了后一行,价格列的值为 6。
- 由列 A 的值 3 标识的行具有版本为 1 的行和版本为 2 的删除行。保留了此删除行。
作为此合并过程的结果,我们有四行表示最终状态
请注意,已删除的行永远不会被删除。可以使用 OPTIMIZE table FINAL CLEANUP 强制删除它们。这需要实验性设置 allow_experimental_replacing_merge_with_cleanup=1。仅应在以下条件下发出此命令
- 您可以确保在发出操作后不会插入具有旧版本(对于那些正在使用清理操作删除的行)的行。如果插入了这些行,它们将被错误地保留,因为已删除的行将不再存在。
- 确保在发出清理操作之前所有副本都已同步。这可以使用以下命令实现
SYSTEM SYNC REPLICA table
我们建议在保证 (1) 后暂停插入,直到此命令和后续清理操作完成。
除非可以安排在上述条件下进行清理,否则仅建议对删除次数较少到中等的表(少于 10%)使用 ReplacingMergeTree 处理删除。
提示:用户还可以对不再进行更改的选定分区发出
OPTIMIZE FINAL CLEANUP。
选择主键/去重键
上面,我们强调了一个重要的附加约束,该约束也必须在 ReplacingMergeTree 的情况下满足:ORDER BY 列的值唯一标识跨更改的行。如果从像 Postgres 这样的事务数据库迁移,则原始 Postgres 主键应包含在 Clickhouse ORDER BY 子句中。
ClickHouse 用户将熟悉选择其表中 ORDER BY 子句中的列,以优化查询性能。通常,应根据您的频繁查询并按基数递增的顺序列出这些列来选择这些列。重要的是,ReplacingMergeTree 施加了一个额外的约束 - 这些列必须是不可变的,即,如果从 Postgres 复制,则仅当这些列在底层 Postgres 数据中不更改时才将它们添加到此子句中。虽然其他列可以更改,但这些列必须保持一致,以便唯一标识行。对于分析工作负载,Postgres 主键通常用途不大,因为用户很少执行点行查找。鉴于我们建议按基数递增的顺序对列进行排序,并且匹配ORDER BY 中较早列出的列通常会更快,因此 Postgres 主键应附加到 ORDER BY 的末尾(除非它具有分析价值)。如果多个列在 Postgres 中形成主键,则应将它们附加到 ORDER BY,并考虑基数和查询值的可能性。用户可能还希望通过 MATERIALIZED 列使用值的串联来生成唯一主键。
考虑 Stack Overflow 数据集中的 posts 表。
CREATE TABLE stackoverflow.posts_updateable
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = ReplacingMergeTree(Version, Deleted)
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
我们使用 (PostTypeId, toDate(CreationDate), CreationDate, Id) 的 ORDER BY 键。对于每个帖子唯一的 Id 列确保可以对行进行去重。根据需要将 Version 和 Deleted 列添加到 schema 中。
查询 ReplacingMergeTree
在合并时,ReplacingMergeTree 使用 ORDER BY 列的值作为唯一标识符来识别重复行,并且如果最新版本指示删除,则仅保留最高版本或删除所有重复项。然而,这仅提供最终正确性 - 它不保证行将被去重,您不应依赖它。因此,由于查询中考虑了更新和删除行,查询可能会产生不正确的答案。
为了获得正确的答案,用户将需要补充后台合并和查询时去重和删除移除。这可以使用 FINAL 运算符来实现。
考虑上面的 posts 表。我们可以使用加载此数据集的正常方法,但在值 0 之外指定 deleted 和 version 列。为了示例目的,我们仅加载 10000 行。
INSERT INTO stackoverflow.posts_updateable SELECT 0 AS Version, 0 AS Deleted, *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet') WHERE AnswerCount > 0 LIMIT 10000
0 rows in set. Elapsed: 1.980 sec. Processed 8.19 thousand rows, 3.52 MB (4.14 thousand rows/s., 1.78 MB/s.)
让我们确认行数
SELECT count() FROM stackoverflow.posts_updateable
┌─count()─┐
│ 10000 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
我们现在更新我们的帖子-答案统计信息。我们没有更新这些值,而是插入了 5000 行的新副本,并将它们的版本号加一(这意味着表中将存在 150 行)。我们可以使用简单的 INSERT INTO SELECT 来模拟此操作
INSERT INTO posts_updateable SELECT
Version + 1 AS Version,
Deleted,
Id,
PostTypeId,
AcceptedAnswerId,
CreationDate,
Score,
ViewCount,
Body,
OwnerUserId,
OwnerDisplayName,
LastEditorUserId,
LastEditorDisplayName,
LastEditDate,
LastActivityDate,
Title,
Tags,
AnswerCount,
CommentCount,
FavoriteCount,
ContentLicense,
ParentId,
CommunityOwnedDate,
ClosedDate
FROM posts_updateable --select 100 random rows
WHERE (Id % toInt32(floor(randUniform(1, 11)))) = 0
LIMIT 5000
0 rows in set. Elapsed: 4.056 sec. Processed 1.42 million rows, 2.20 GB (349.63 thousand rows/s., 543.39 MB/s.)
此外,我们通过重新插入行但 deleted 列值为 1 来删除 1000 个随机帖子。同样,可以使用简单的 INSERT INTO SELECT 来模拟此操作。
INSERT INTO posts_updateable SELECT
Version + 1 AS Version,
1 AS Deleted,
Id,
PostTypeId,
AcceptedAnswerId,
CreationDate,
Score,
ViewCount,
Body,
OwnerUserId,
OwnerDisplayName,
LastEditorUserId,
LastEditorDisplayName,
LastEditDate,
LastActivityDate,
Title,
Tags,
AnswerCount + 1 AS AnswerCount,
CommentCount,
FavoriteCount,
ContentLicense,
ParentId,
CommunityOwnedDate,
ClosedDate
FROM posts_updateable --select 100 random rows
WHERE (Id % toInt32(floor(randUniform(1, 11)))) = 0 AND AnswerCount > 0
LIMIT 1000
0 rows in set. Elapsed: 0.166 sec. Processed 135.53 thousand rows, 212.65 MB (816.30 thousand rows/s., 1.28 GB/s.)
上述操作的结果将是 16,000 行,即 10,000 + 5000 + 1000。这里的正确总数实际上应该比我们的原始总数少 1000 行,即 10,000 - 1000 = 9000。
SELECT count()
FROM posts_updateable
┌─count()─┐
│ 10000 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
您的结果将因已发生的合并而异。我们可以看到这里的总数不同,因为我们有重复的行。将 FINAL 应用于表可以提供正确的结果。
SELECT count()
FROM posts_updateable
FINAL
┌─count()─┐
│ 9000 │
└─────────┘
1 row in set. Elapsed: 0.006 sec. Processed 11.81 thousand rows, 212.54 KB (2.14 million rows/s., 38.61 MB/s.)
Peak memory usage: 8.14 MiB.
FINAL 性能
尽管不断改进,FINAL 运算符仍会对查询产生性能开销。当查询未按主键列进行过滤时,这将最为明显,这将导致读取更多数据并增加去重开销。如果用户使用 WHERE 条件按键列进行过滤,则加载并传递以进行去重的数据将减少。
如果 WHERE 条件未使用键列,则在使用 FINAL 时,ClickHouse 当前不使用 PREWHERE 优化。此优化旨在减少为非过滤列读取的行数。有关模拟此 PREWHERE 并因此可能提高性能的示例,请参见此处。
利用 ReplacingMergeTree 的分区
ClickHouse 中的数据合并发生在分区级别。当使用 ReplacingMergeTree 时,我们建议用户按照最佳实践对表进行分区,前提是用户可以确保此分区键对于行保持不变。这将确保与同一行相关的更新将被发送到同一 ClickHouse 分区。您可以重复使用与 Postgres 相同的分区键,前提是您遵守此处概述的最佳实践。
假设情况如此,用户可以使用设置 do_not_merge_across_partitions_select_final=1 来提高 FINAL 查询性能。此设置会导致在使用 FINAL 时独立合并和处理分区。
考虑以下 posts 表,我们没有使用分区
CREATE TABLE stackoverflow.posts_no_part
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
…
)
ENGINE = ReplacingMergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
INSERT INTO stackoverflow.posts_no_part SELECT 0 AS Version, 0 AS Deleted, *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 182.895 sec. Processed 59.82 million rows, 38.07 GB (327.07 thousand rows/s., 208.17 MB/s.)
为了确保 FINAL 需要做一些工作,我们更新了 100 万行 - 通过插入重复行来增加它们的 AnswerCount。
INSERT INTO posts_no_part SELECT Version + 1 AS Version, Deleted, Id, PostTypeId, AcceptedAnswerId, CreationDate, Score, ViewCount, Body, OwnerUserId, OwnerDisplayName, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Title, Tags, AnswerCount + 1 AS AnswerCount, CommentCount, FavoriteCount, ContentLicense, ParentId, CommunityOwnedDate, ClosedDate
FROM posts_no_part
LIMIT 1000000
使用 FINAL 计算每年答案的总和
SELECT toYear(CreationDate) AS year, sum(AnswerCount) AS total_answers
FROM posts_no_part
FINAL
GROUP BY year
ORDER BY year ASC
┌─year─┬─total_answers─┐
│ 2008 │ 371480 │
…
│ 2024 │ 127765 │
└──────┴───────────────┘
17 rows in set. Elapsed: 2.338 sec. Processed 122.94 million rows, 1.84 GB (52.57 million rows/s., 788.58 MB/s.)
Peak memory usage: 2.09 GiB.
对按年份分区的表重复这些相同的步骤,并使用 do_not_merge_across_partitions_select_final=1 重复上述查询。
CREATE TABLE stackoverflow.posts_with_part
(
`Version` UInt32,
`Deleted` UInt8,
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
...
)
ENGINE = ReplacingMergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate, Id)
// populate & update omitted
SELECT toYear(CreationDate) AS year, sum(AnswerCount) AS total_answers
FROM posts_with_part
FINAL
GROUP BY year
ORDER BY year ASC
┌─year─┬─total_answers─┐
│ 2008 │ 387832 │
│ 2009 │ 1165506 │
│ 2010 │ 1755437 │
...
│ 2023 │ 787032 │
│ 2024 │ 127765 │
└──────┴───────────────┘
17 rows in set. Elapsed: 0.994 sec. Processed 64.65 million rows, 983.64 MB (65.02 million rows/s., 989.23 MB/s.)
如图所示,在这种情况下,分区显着提高了查询性能,因为它允许去重过程在分区级别并行发生。
合并行为注意事项
ClickHouse 的合并选择机制不仅仅是简单的 parts 合并。下面,我们将在 ReplacingMergeTree 的上下文中检查此行为,包括用于更积极地合并旧数据的配置选项以及对较大 parts 的考虑。
合并选择逻辑
虽然合并旨在最大限度地减少 parts 的数量,但它也会权衡此目标与写入放大的成本。因此,某些范围的 parts 如果会导致过度的写入放大,则会被排除在合并之外,这基于内部计算。此行为有助于防止不必要的资源使用并延长存储组件的寿命。
大型 parts 的合并行为
ClickHouse 中的 ReplacingMergeTree 引擎经过优化,可通过合并数据 parts 来管理重复行,仅保留基于指定唯一键的每个行的最新版本。但是,当合并的 part 达到 max_bytes_to_merge_at_max_space_in_pool 阈值时,即使设置了 min_age_to_force_merge_seconds,它也不会再被选择用于进一步合并。因此,不能再依靠自动合并来删除可能随着持续数据插入而累积的重复项。
为了解决这个问题,用户可以调用 OPTIMIZE FINAL 手动合并 parts 并删除重复项。与自动合并不同,OPTIMIZE FINAL 绕过了 max_bytes_to_merge_at_max_space_in_pool 阈值,仅根据可用资源(尤其是磁盘空间)合并 parts,直到每个分区中只剩下一个 part。但是,这种方法在大型表上可能会占用大量内存,并且可能需要重复执行,因为会添加新数据。
为了获得更可持续的解决方案来保持性能,建议对表进行分区。这可以帮助防止数据 parts 达到最大合并大小,并减少对持续手动优化的需求。
跨分区的分区和合并
正如在“利用 ReplacingMergeTree 的分区”中讨论的那样,我们建议将分区表作为最佳实践。分区隔离数据以实现更高效的合并,并避免跨分区合并,尤其是在查询执行期间。从 23.12 版本开始,此行为得到了增强:如果分区键是排序键的前缀,则在查询时不会执行跨分区合并,从而提高查询性能。
调整合并以获得更好的查询性能
默认情况下,min_age_to_force_merge_seconds 和 min_age_to_force_merge_on_partition_only 分别设置为 0 和 false,从而禁用这些功能。在此配置中,ClickHouse 将应用标准合并行为,而不会强制基于分区年龄进行合并。
如果为 min_age_to_force_merge_seconds 指定了值,则 ClickHouse 将忽略比指定时间段更旧的 parts 的正常合并启发式方法。虽然这通常仅在目标是最大限度地减少 parts 总数时才有效,但它可以通过减少查询时需要合并的 parts 数量来提高 ReplacingMergeTree 中的查询性能。
可以通过设置 min_age_to_force_merge_on_partition_only=true 来进一步调整此行为,这要求分区中的所有 parts 都比 min_age_to_force_merge_seconds 更旧才能进行积极合并。此配置允许较旧的分区随着时间的推移合并为一个 part,从而整合数据并保持查询性能。
推荐设置
调整合并行为是一项高级操作。我们建议在生产工作负载中启用这些设置之前咨询 ClickHouse 支持。
在大多数情况下,最好将 min_age_to_force_merge_seconds 设置为较低的值 - 远小于分区周期。这最大限度地减少了 parts 的数量,并防止在使用 FINAL 运算符进行查询时进行不必要的合并。
例如,考虑一个已合并为单个 part 的每月分区。如果一个小的、零散的插入在此分区中创建了一个新的 part,则查询性能可能会受到影响,因为 ClickHouse 必须读取多个 parts,直到合并完成。设置 min_age_to_force_merge_seconds 可以确保这些 parts 被积极地合并,从而防止查询性能下降。