将数据从 Redshift 迁移到 ClickHouse
相关内容
简介
Amazon Redshift 是一种流行的云数据仓库解决方案,是 Amazon Web Services 产品的一部分。本指南介绍了将数据从 Redshift 实例迁移到 ClickHouse 的不同方法。我们将介绍三种选择:

从 ClickHouse 实例的角度来看,您可以选择:
-
PUSH(推送) 使用第三方 ETL/ELT 工具或服务将数据推送到 ClickHouse
-
PULL(拉取) 利用 ClickHouse JDBC Bridge 从 Redshift 拉取数据
-
PIVOT(枢轴) 使用 S3 对象存储,采用 “卸载然后加载” 逻辑
在本教程中,我们使用 Redshift 作为数据源。但是,此处介绍的迁移方法并非 Redshift 独有,对于任何兼容的数据源,都可以推导出类似的步骤。
将数据从 Redshift 推送到 ClickHouse
在推送场景中,想法是利用第三方工具或服务(自定义代码或 ETL/ELT)将您的数据发送到您的 ClickHouse 实例。例如,您可以使用像 Airbyte 这样的软件在您的 Redshift 实例(作为源)和 ClickHouse 作为目标之间移动数据(请参阅我们的 Airbyte 集成指南)

优点
- 它可以利用 ETL/ELT 软件现有的连接器目录。
- 内置功能,用于保持数据同步(追加/覆盖/增量逻辑)。
- 启用数据转换场景(例如,请参阅我们的 dbt 集成指南)。
缺点
- 用户需要设置和维护 ETL/ELT 基础设施。
- 在架构中引入了第三方元素,这可能会成为潜在的可扩展性瓶颈。
从 Redshift 拉取数据到 ClickHouse
在拉取场景中,想法是利用 ClickHouse JDBC Bridge 直接从 ClickHouse 实例连接到 Redshift 集群,并执行 INSERT INTO ... SELECT 查询

优点
- 通用性,适用于所有 JDBC 兼容工具
- 优雅的解决方案,允许从 ClickHouse 内部查询多个外部数据源
缺点
- 需要 ClickHouse JDBC Bridge 实例,这可能会成为潜在的可扩展性瓶颈
即使 Redshift 基于 PostgreSQL,也无法使用 ClickHouse PostgreSQL 表函数或表引擎,因为 ClickHouse 需要 PostgreSQL 9 或更高版本,而 Redshift API 基于早期版本 (8.x)。
教程
要使用此选项,您需要设置 ClickHouse JDBC Bridge。ClickHouse JDBC Bridge 是一个独立的 Java 应用程序,用于处理 JDBC 连接,并充当 ClickHouse 实例和数据源之间的代理。在本教程中,我们使用了预先填充了 示例数据库 的 Redshift 实例。
- 部署 ClickHouse JDBC Bridge。有关更多详细信息,请参阅我们的 JDBC for External Data sources(JDBC 用于外部数据源) 用户指南
如果您正在使用 ClickHouse Cloud,您将需要在单独的环境中运行 ClickHouse JDBC Bridge,并使用 remoteSecure 函数连接到 ClickHouse Cloud
- 为 ClickHouse JDBC Bridge 配置您的 Redshift 数据源。例如,
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json
{
"redshift-server": {
"aliases": [
"redshift"
],
"driverUrls": [
"https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.4/redshift-jdbc42-2.1.0.4.jar"
],
"driverClassName": "com.amazon.redshift.jdbc.Driver",
"jdbcUrl": "jdbc:redshift://redshift-cluster-1.ckubnplpz1uv.us-east-1.redshift.amazonaws.com:5439/dev",
"username": "awsuser",
"password": "<password>",
"maximumPoolSize": 5
}
}
- 一旦 ClickHouse JDBC Bridge 部署并运行,您就可以开始从 ClickHouse 查询您的 Redshift 实例了
SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users limit 5')
Query id: 1b7de211-c0f6-4117-86a2-276484f9f4c0
┌─username─┬─firstname─┬─lastname─┐
│ PGL08LJI │ Vladimir │ Humphrey │
│ XDZ38RDD │ Barry │ Roy │
│ AEB55QTM │ Reagan │ Hodge │
│ OWY35QYB │ Tamekah │ Juarez │
│ MSD36KVR │ Mufutau │ Watkins │
└──────────┴───────────┴──────────┘
5 rows in set. Elapsed: 0.438 sec.
SELECT *
FROM jdbc('redshift', 'select count(*) from sales')
Query id: 2d0f957c-8f4e-43b2-a66a-cc48cc96237b
┌──count─┐
│ 172456 │
└────────┘
1 rows in set. Elapsed: 0.304 sec.
- 在下面,我们展示了使用
INSERT INTO ... SELECT语句导入数据
# TABLE CREATION with 3 columns
CREATE TABLE users_imported
(
`username` String,
`firstname` String,
`lastname` String
)
ENGINE = MergeTree
ORDER BY firstname
Query id: c7c4c44b-cdb2-49cf-b319-4e569976ab05
Ok.
0 rows in set. Elapsed: 0.233 sec.
# IMPORTING DATA
INSERT INTO users_imported (*) SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users')
Query id: 9d3a688d-b45a-40f4-a7c7-97d93d7149f1
Ok.
0 rows in set. Elapsed: 4.498 sec. Processed 49.99 thousand rows, 2.49 MB (11.11 thousand rows/s., 554.27 KB/s.)
使用 S3 从 Redshift 枢轴数据到 ClickHouse
在此场景中,我们将数据导出到 S3 中的中间枢轴格式,然后在第二步中,将数据从 S3 加载到 ClickHouse。
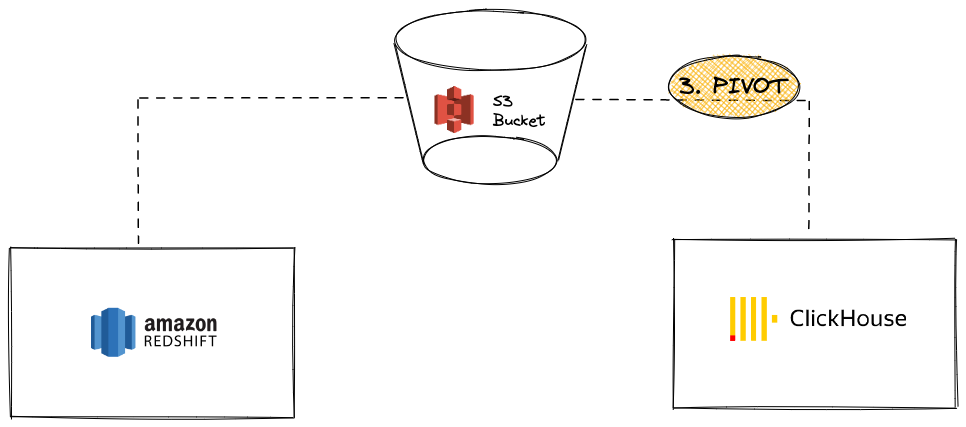
优点
- Redshift 和 ClickHouse 都具有强大的 S3 集成功能。
- 利用现有功能,例如 Redshift
UNLOAD命令和 ClickHouse S3 表函数/表引擎。 - 由于 ClickHouse 中来自/到 S3 的并行读取和高吞吐量能力,因此可以无缝扩展。
- 可以利用复杂的压缩格式,例如 Apache Parquet。
缺点
- 过程中有两个步骤(从 Redshift 卸载,然后加载到 ClickHouse)。
教程
-
使用 Redshift 的 UNLOAD 功能,将数据导出到现有的私有 S3 存储桶中
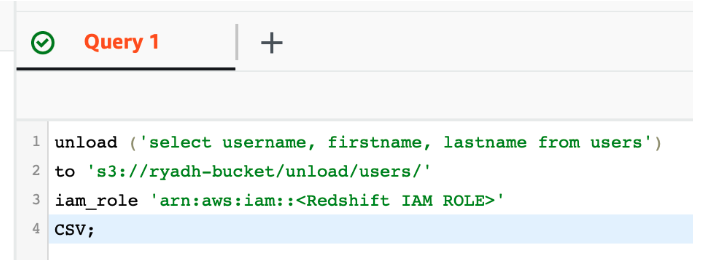
它将生成包含 S3 中原始数据的部分文件

-
在 ClickHouse 中创建表
CREATE TABLE users
(
username String,
firstname String,
lastname String
)
ENGINE = MergeTree
ORDER BY username或者,ClickHouse 可以尝试使用
CREATE TABLE ... EMPTY AS SELECT推断表结构CREATE TABLE users
ENGINE = MergeTree ORDER BY username
EMPTY AS
SELECT * FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')当数据采用包含数据类型信息的格式(如 Parquet)时,此方法尤其有效。
-
使用
INSERT INTO ... SELECT语句将 S3 文件加载到 ClickHouse 中INSERT INTO users SELECT *
FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')Query id: 2e7e219a-6124-461c-8d75-e4f5002c8557
Ok.
0 rows in set. Elapsed: 0.545 sec. Processed 49.99 thousand rows, 2.34 MB (91.72 thousand rows/s., 4.30 MB/s.)
此示例使用 CSV 作为枢轴格式。但是,对于生产工作负载,我们建议使用 Apache Parquet 作为大型迁移的最佳选择,因为它带有压缩功能,可以节省一些存储成本,同时减少传输时间。(默认情况下,每个行组都使用 SNAPPY 压缩)。ClickHouse 还利用 Parquet 的列式方向来加速数据摄取。