插入数据
基本示例
您可以使用熟悉的 INSERT INTO TABLE 命令与 ClickHouse。 让我们将一些数据插入到我们在入门指南 “在 ClickHouse 中创建表” 中创建的表中。
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )
为了验证是否有效,我们将运行以下 SELECT 查询
SELECT * FROM helloworld.my_first_table
返回结果为
user_id message timestamp metric
101 Hello, ClickHouse! 2024-11-13 20:01:22 -1
101 Granules are the smallest chunks of data read 2024-11-13 20:01:27 3.14159
102 Insert a lot of rows per batch 2024-11-12 00:00:00 1.41421
102 Sort your data based on your commonly-used queries 2024-11-13 00:00:00 2.718
插入 ClickHouse 与 OLTP 数据库的比较
作为 OLAP(在线分析处理)数据库,ClickHouse 针对高性能和可扩展性进行了优化,允许每秒插入数百万行。 这是通过高度并行化的架构和高效的列式压缩相结合实现的,但在即时一致性方面做出了妥协。 更具体地说,ClickHouse 针对仅追加操作进行了优化,并且仅提供最终一致性保证。
相比之下,Postgres 等 OLTP 数据库专门针对具有完整 ACID 合规性的事务性插入进行了优化,确保了强大的数据一致性和可靠性保证。 PostgreSQL 使用 MVCC(多版本并发控制)来处理并发事务,这涉及维护数据的多个版本。 这些事务一次可能只涉及少量行,但由于可靠性保证限制了插入性能,因此会产生相当大的开销。
为了在保持强一致性保证的同时实现高插入性能,用户在将数据插入 ClickHouse 时应遵守以下描述的简单规则。 遵循这些规则将有助于避免用户首次使用 ClickHouse 时常遇到的问题,并尝试复制适用于 OLTP 数据库的插入策略。
插入的最佳实践
以大批量大小插入
默认情况下,每次发送到 ClickHouse 的插入操作都会导致 ClickHouse 立即创建一个存储部分,其中包含来自插入操作的数据以及需要存储的其他元数据。 因此,与发送大量每个包含较少数据的插入操作相比,发送少量每个包含更多数据的插入操作将减少所需的写入次数。 通常,我们建议以相当大的批次(每次至少 1,000 行,理想情况下在 10,000 到 100,000 行之间)插入数据。(更多详情请点击此处)。
如果无法进行大批量插入,请使用下面描述的异步插入。
确保一致的批次以实现幂等重试
默认情况下,插入 ClickHouse 是同步且幂等的(即,多次执行相同的插入操作与执行一次的效果相同)。 对于 MergeTree 引擎系列的表,ClickHouse 将默认自动去重插入。
这意味着在以下情况下,插入操作仍然具有弹性
-
- 如果接收数据的节点出现问题,则插入查询将超时(或给出更具体的错误),并且不会获得确认。
-
- 如果数据已由节点写入,但由于网络中断,确认无法返回给查询的发送者,则发送者将收到超时或网络错误。
从客户端的角度来看,(i) 和 (ii) 可能难以区分。 但是,在这两种情况下,未确认的插入都可以立即重试。 只要重试的插入查询包含相同的数据且顺序相同,如果(未确认的)原始插入成功,ClickHouse 将自动忽略重试的插入。
插入到 MergeTree 表或分布式表
我们建议直接插入到 MergeTree(或 Replicated 表)中,如果数据已分片,则在节点集之间平衡请求,并设置 internal_replication=true。 这将使 ClickHouse 将数据复制到任何可用的副本分片,并确保数据最终一致。
如果这种客户端负载均衡不方便,那么用户可以通过分布式表进行插入,这将跨节点分发写入。 同样,建议设置 internal_replication=true。 但应该注意的是,这种方法性能稍差,因为写入必须在具有分布式表的节点上本地进行,然后再发送到分片。
对小批量使用异步插入
在某些情况下,客户端批处理是不可行的,例如,可观测性使用场景,其中有数百或数千个单用途代理发送日志、指标、追踪等。 在这种情况下,实时传输数据是快速检测问题和异常的关键。 此外,观察到的系统存在事件峰值的风险,这可能会在尝试缓冲客户端可观测性数据时导致大型内存峰值和相关问题。 如果无法插入大批量数据,用户可以使用异步插入将批处理委托给 ClickHouse。
启用异步插入后,数据首先插入到缓冲区中,然后在稍后的 3 个步骤中写入数据库存储,如下图所示
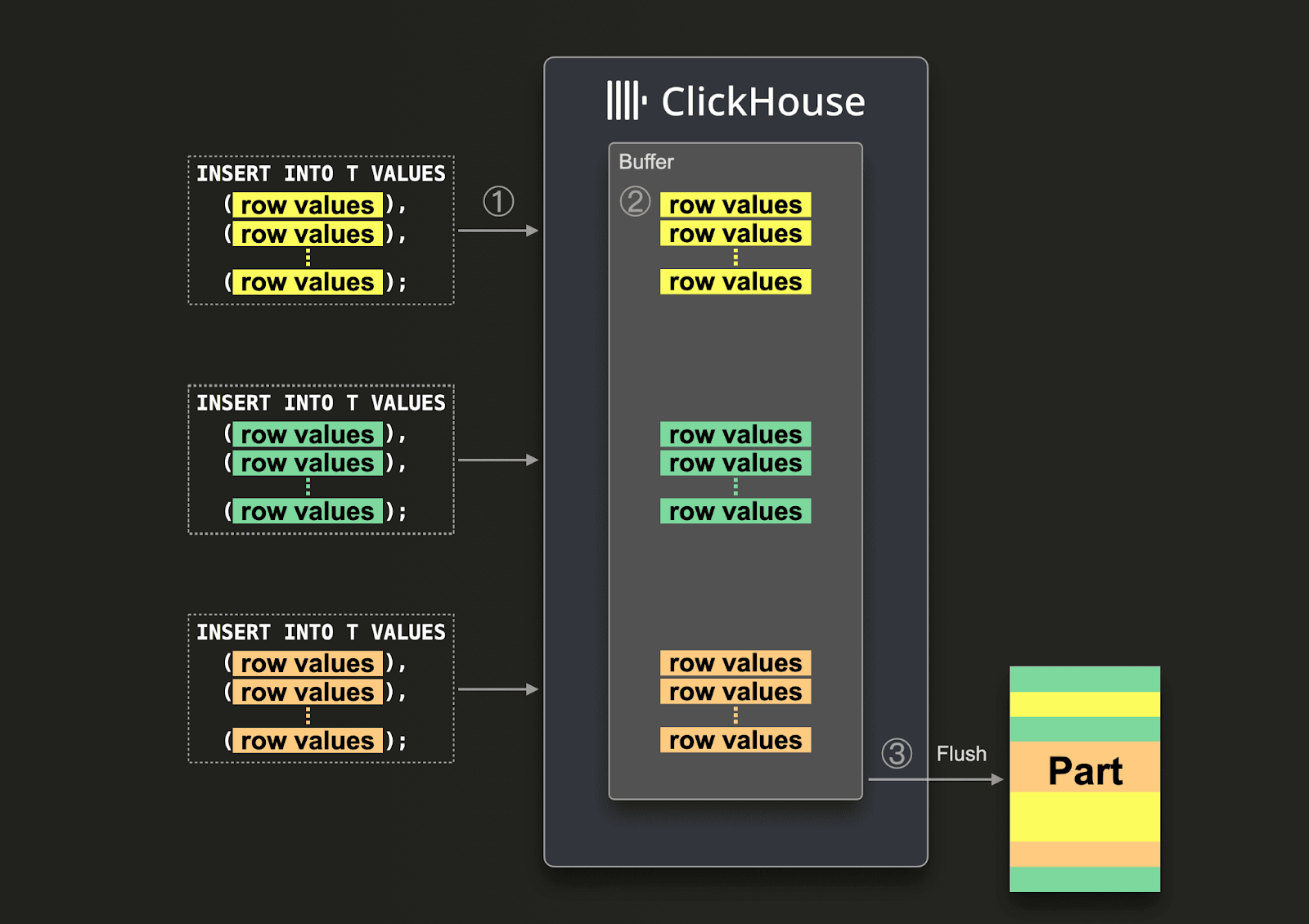
启用异步插入后,ClickHouse
(1)异步接收插入查询。
(2)首先将查询的数据写入内存缓冲区。
(3)仅在下一次缓冲区刷新发生时,才对数据进行排序并将其作为一部分写入数据库存储。
在缓冲区刷新之前,来自同一客户端或其他客户端的其他异步插入查询的数据可以收集在缓冲区中。 从缓冲区刷新创建的部分可能包含来自多个异步插入查询的数据。 通常,这些机制将数据批处理从客户端转移到服务器端(ClickHouse 实例)。
使用官方 ClickHouse 客户端
ClickHouse 在最流行的编程语言中都有客户端。 这些客户端经过优化,可确保正确执行插入操作,并原生支持异步插入,例如Go 客户端中直接支持异步插入,或者在查询、用户或连接级别设置中启用时间接支持异步插入。
有关可用 ClickHouse 客户端和驱动程序的完整列表,请参阅客户端和驱动程序。
优先使用 Native 格式
ClickHouse 在插入(和查询)时支持多种输入格式。 这与 OLTP 数据库有显着不同,并且使从外部源加载数据变得更加容易 - 尤其是与表函数以及从磁盘文件加载数据的功能结合使用时。 这些格式非常适合临时数据加载和数据工程任务。
对于希望获得最佳插入性能的应用程序,用户应使用 Native 格式进行插入。 大多数客户端(例如 Go 和 Python)都支持此格式,并确保服务器只需执行最少的工作,因为此格式已经是面向列的。 这样做会将将数据转换为面向列的格式的责任放在客户端。 这对于有效扩展插入操作非常重要。
或者,如果首选行格式,用户可以使用 RowBinary 格式(Java 客户端使用)。RowBinary 格式通常比 Native 格式更容易编写。 就压缩、网络开销和服务器上的处理而言,它比 JSON 等其他行格式JSON更有效。JSONEachRow 格式可以考虑用于写入吞吐量较低且希望快速集成的用户。 用户应该意识到,此格式会在 ClickHouse 中产生 CPU 开销以进行解析。
使用 HTTP 接口
与许多传统数据库不同,ClickHouse 支持 HTTP 接口。 用户可以使用此接口插入和查询数据,使用上述任何格式。 这通常比 ClickHouse 的原生协议更可取,因为它允许使用负载均衡器轻松切换流量。 我们预计与原生协议的插入性能略有差异,原生协议产生的开销略少。 现有客户端使用这些协议中的任何一种(在某些情况下两者都使用,例如 Go 客户端)。 原生协议确实允许轻松跟踪查询进度。
有关更多详细信息,请参阅HTTP 接口。
从 Postgres 加载数据
对于从 Postgres 加载数据,用户可以使用
PeerDB by ClickHouse,一种专门为 PostgreSQL 数据库复制设计的 ETL 工具。 这在以下两种方式中都可用- PostgreSQL 表引擎可以直接读取数据,如前面的示例所示。 如果基于已知水印(例如,时间戳)的批量复制就足够了,或者如果这是一次性迁移,则通常适用。 这种方法可以扩展到数千万行。 希望迁移更大数据集的用户应考虑多个请求,每个请求处理一部分数据。 暂存表可用于每个数据块,然后再将其分区移动到最终表。 这允许重试失败的请求。 有关此批量加载策略的更多详细信息,请参阅此处。
- 数据可以 CSV 格式从 PostgreSQL 导出。 然后,可以使用表函数从本地文件或通过对象存储将其插入到 ClickHouse 中。
如果您在插入大型数据集时需要帮助,或者在将数据导入 ClickHouse Cloud 时遇到任何错误,请通过 [email protected] 联系我们,我们可以提供帮助。