从 Snowflake 迁移到 ClickHouse
本指南展示了如何将数据从 Snowflake 迁移到 ClickHouse。
在 Snowflake 和 ClickHouse 之间迁移数据需要使用对象存储(例如 S3)作为传输的中间存储。迁移过程还依赖于使用 Snowflake 的 COPY INTO 命令和 ClickHouse 的 INSERT INTO SELECT。
1. 从 Snowflake 导出数据
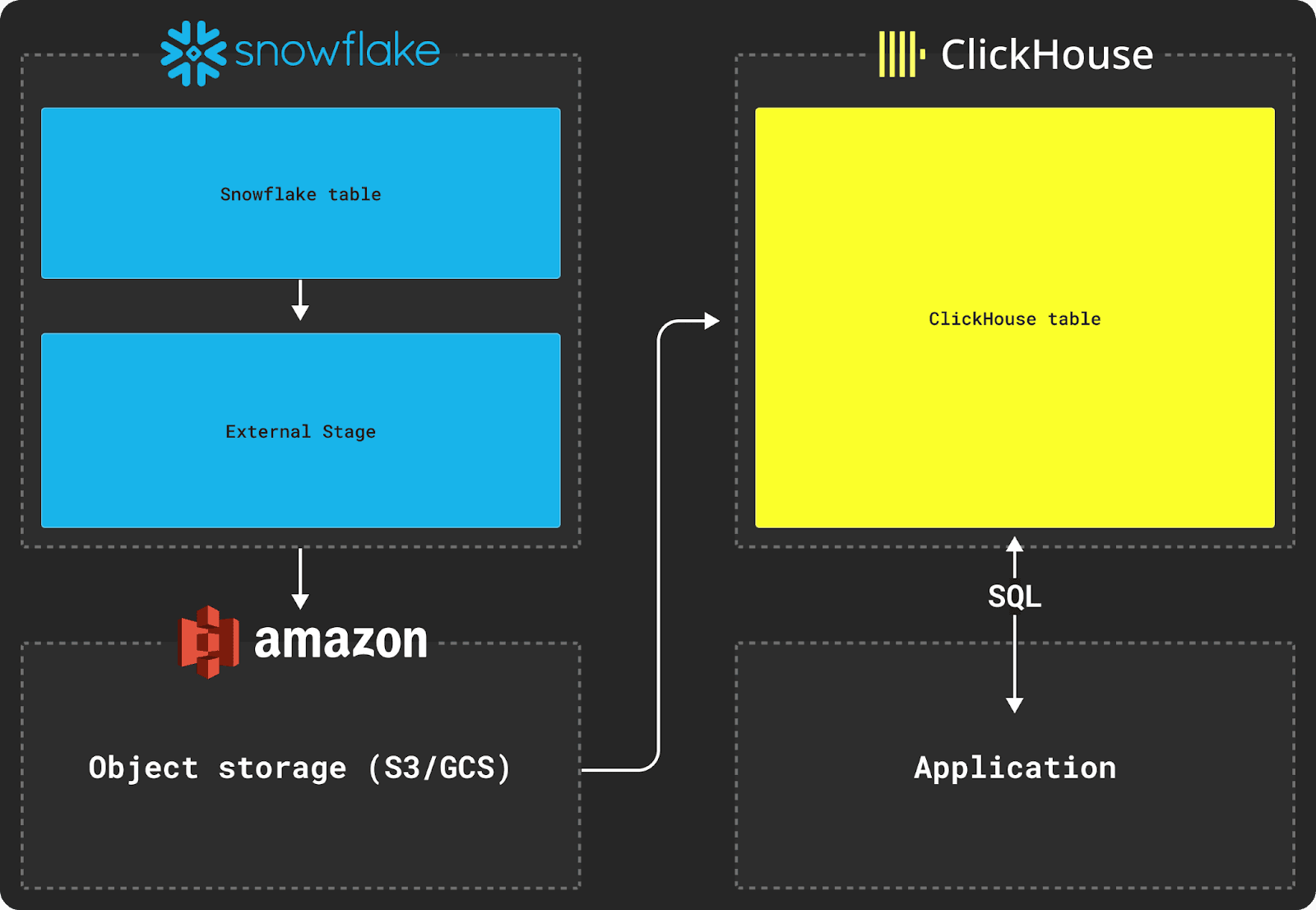
从 Snowflake 导出数据需要使用外部阶段,如上图所示。
假设我们要导出具有以下架构的 Snowflake 表
CREATE TABLE MYDATASET (
timestamp TIMESTAMP,
some_text varchar,
some_file OBJECT,
complex_data VARIANT,
) DATA_RETENTION_TIME_IN_DAYS = 0;
要将此表的数据移动到 ClickHouse 数据库,我们首先需要将此数据复制到外部阶段。在复制数据时,我们推荐使用 Parquet 作为中间格式,因为它允许共享类型信息,保留精度,压缩良好,并原生支持分析中常见的嵌套结构。
在下面的示例中,我们在 Snowflake 中创建一个命名文件格式来表示 Parquet 和所需的文件选项。然后,我们指定哪个存储桶将包含我们的复制数据集。最后,我们将数据集复制到存储桶。
CREATE FILE FORMAT my_parquet_format TYPE = parquet;
-- Create the external stage that specifies the S3 bucket to copy into
CREATE OR REPLACE STAGE external_stage
URL='s3://mybucket/mydataset'
CREDENTIALS=(AWS_KEY_ID='<key>' AWS_SECRET_KEY='<secret>')
FILE_FORMAT = my_parquet_format;
-- Apply "mydataset" prefix to all files and specify a max file size of 150mb
-- The `header=true` parameter is required to get column names
COPY INTO @external_stage/mydataset from mydataset max_file_size=157286400 header=true;
对于大约 5TB 的数据集,最大文件大小为 150MB,并使用位于同一 AWS us-east-1 区域的 2X-Large Snowflake 仓库,将数据复制到 S3 存储桶大约需要 30 分钟。
2. 导入到 ClickHouse
一旦数据在中间对象存储中暂存,就可以使用 ClickHouse 函数(例如 s3 表函数)将数据插入到表中,如下所示。
此示例使用 AWS S3 的 s3 表函数,但 gcs 表函数 可用于 Google Cloud Storage,azureBlobStorage 表函数 可用于 Azure Blob Storage。
假设以下目标表架构
CREATE TABLE default.mydataset
(
`timestamp` DateTime64(6),
`some_text` String,
`some_file` Tuple(filename String, version String),
`complex_data` Tuple(name String, description String),
)
ENGINE = MergeTree
ORDER BY (timestamp)
然后,我们可以使用 INSERT INTO SELECT 命令将数据从 S3 插入到 ClickHouse 表中
INSERT INTO mydataset
SELECT
timestamp,
some_text,
JSONExtract(
ifNull(some_file, '{}'),
'Tuple(filename String, version String)'
) AS some_file,
JSONExtract(
ifNull(complex_data, '{}'),
'Tuple(filename String, description String)'
) AS complex_data,
FROM s3('https://mybucket.s3.amazonaws.com/mydataset/mydataset*.parquet')
SETTINGS input_format_null_as_default = 1, -- Ensure columns are inserted as default if values are null
input_format_parquet_case_insensitive_column_matching = 1 -- Column matching between source data and target table should be case insensitive
原始 Snowflake 表架构中的 VARIANT 和 OBJECT 列将默认输出为 JSON 字符串,迫使我们在将它们插入 ClickHouse 时进行转换。
诸如 some_file 之类的嵌套结构在 Snowflake 复制时会转换为 JSON 字符串。导入此数据需要我们在 ClickHouse 的插入时将这些结构转换为元组,使用 JSONExtract 函数,如上所示。
3. 测试数据导出是否成功
要测试您的数据是否已正确插入,只需在新表上运行 SELECT 查询
SELECT * FROM mydataset limit 10;
进一步阅读和支持
除了本指南外,我们还建议阅读我们的博客文章 比较 Snowflake 和 ClickHouse。
如果您在将数据从 Snowflake 传输到 ClickHouse 时遇到问题,请随时通过 [email protected] 联系我们。