高级教程
本教程内容预告?
在本教程中,您将创建一个表并插入一个大型数据集(两百万行纽约出租车数据)。然后,您将在该数据集上运行查询,包括如何创建字典并使用它执行 JOIN 的示例。
本教程假设您可以访问正在运行的 ClickHouse 服务。如果不是,请查看快速入门。
1. 创建新表
纽约市出租车数据包含数百万次出租车行程的详细信息,包括上下车时间和地点、费用、小费金额、通行费、付款类型等等。让我们创建一个表来存储这些数据……
- 连接到 SQL 控制台
如果您需要 SQL 客户端连接,您的 ClickHouse Cloud 服务有一个关联的基于 Web 的 SQL 控制台;展开下面的连接到 SQL 控制台以获取详细信息。
连接到 SQL 控制台
从您的 ClickHouse Cloud 服务列表中,选择您要使用的服务,然后单击连接。从这里您可以打开 SQL 控制台
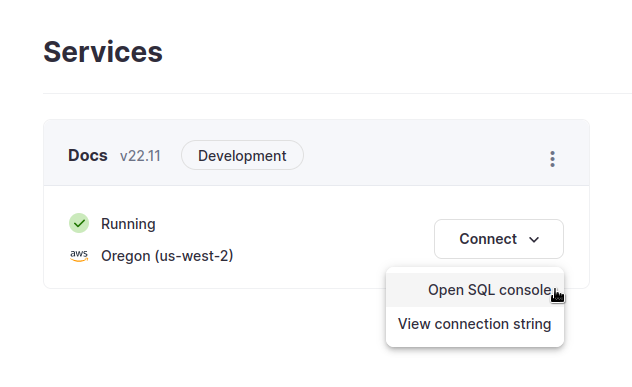
如果您使用的是自托管 ClickHouse,则可以连接到 https://hostname:8443/play 上的 SQL 控制台(详情请咨询您的 ClickHouse 管理员)。
- 在 default 数据库中创建以下
trips表CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime;
2. 插入数据集
现在您已经创建了一个表,让我们添加 NYC 出租车数据。它位于 S3 的 CSV 文件中,您可以从那里加载数据。
-
以下命令从 S3 中的两个不同文件
trips_1.tsv.gz和trips_2.tsv.gz向您的trips表插入约 2,000,000 行INSERT INTO trips
SELECT * FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz',
'TabSeparatedWithNames', "
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
") SETTINGS input_format_try_infer_datetimes = 0 -
等待
INSERT完成 - 下载 150 MB 的数据可能需要一些时间。注意s3函数巧妙地知道如何解压缩数据,而TabSeparatedWithNames格式告诉 ClickHouse 数据是制表符分隔的,并且还跳过每个文件的标题行。 -
插入完成后,验证它是否工作
SELECT count() FROM trips您应该看到大约 200 万行(准确地说是 1,999,657 行)。
注意注意到 ClickHouse 需要多快和多少的行来处理以确定计数吗?您可以在 0.001 秒内获得计数,仅处理了 6 行。
-
如果您运行需要命中每一行的查询,您会注意到需要处理更多的行,但运行时仍然非常快
SELECT DISTINCT(pickup_ntaname) FROM trips此查询必须处理 200 万行并返回 190 个值,但请注意它在大约 1 秒内完成此操作。
pickup_ntaname列表示出租车行程始发的纽约市社区的名称。
3. 分析数据
让我们运行一些查询来分析 200 万行数据……
-
我们将从一些简单的计算开始,例如计算平均小费金额
SELECT round(avg(tip_amount), 2) FROM trips响应是
┌─round(avg(tip_amount), 2)─┐
│ 1.68 │
└───────────────────────────┘ -
此查询根据乘客人数计算平均费用
SELECT
passenger_count,
ceil(avg(total_amount),2) AS average_total_amount
FROM trips
GROUP BY passenger_countpassenger_count的范围从 0 到 9┌─passenger_count─┬─average_total_amount─┐
│ 0 │ 22.69 │
│ 1 │ 15.97 │
│ 2 │ 17.15 │
│ 3 │ 16.76 │
│ 4 │ 17.33 │
│ 5 │ 16.35 │
│ 6 │ 16.04 │
│ 7 │ 59.8 │
│ 8 │ 36.41 │
│ 9 │ 9.81 │
└─────────────────┴──────────────────────┘ -
这是一个计算每个社区每日接客次数的查询
SELECT
pickup_date,
pickup_ntaname,
SUM(1) AS number_of_trips
FROM trips
GROUP BY pickup_date, pickup_ntaname
ORDER BY pickup_date ASC结果看起来像
┌─pickup_date─┬─pickup_ntaname───────────────────────────────────────────┬─number_of_trips─┐
│ 2015-07-01 │ Brooklyn Heights-Cobble Hill │ 13 │
│ 2015-07-01 │ Old Astoria │ 5 │
│ 2015-07-01 │ Flushing │ 1 │
│ 2015-07-01 │ Yorkville │ 378 │
│ 2015-07-01 │ Gramercy │ 344 │
│ 2015-07-01 │ Fordham South │ 2 │
│ 2015-07-01 │ SoHo-TriBeCa-Civic Center-Little Italy │ 621 │
│ 2015-07-01 │ Park Slope-Gowanus │ 29 │
│ 2015-07-01 │ Bushwick South │ 5 │ -
此查询计算行程的长度,并按该值对结果进行分组
SELECT
avg(tip_amount) AS avg_tip,
avg(fare_amount) AS avg_fare,
avg(passenger_count) AS avg_passenger,
count() AS count,
truncate(date_diff('second', pickup_datetime, dropoff_datetime)/60) as trip_minutes
FROM trips
WHERE trip_minutes > 0
GROUP BY trip_minutes
ORDER BY trip_minutes DESC结果看起来像
┌──────────────avg_tip─┬───────────avg_fare─┬──────avg_passenger─┬──count─┬─trip_minutes─┐
│ 1.9600000381469727 │ 8 │ 1 │ 1 │ 27511 │
│ 0 │ 12 │ 2 │ 1 │ 27500 │
│ 0.542166673981895 │ 19.716666666666665 │ 1.9166666666666667 │ 60 │ 1439 │
│ 0.902499997522682 │ 11.270625001192093 │ 1.95625 │ 160 │ 1438 │
│ 0.9715789457909146 │ 13.646616541353383 │ 2.0526315789473686 │ 133 │ 1437 │
│ 0.9682692398245518 │ 14.134615384615385 │ 2.076923076923077 │ 104 │ 1436 │
│ 1.1022105210705808 │ 13.778947368421052 │ 2.042105263157895 │ 95 │ 1435 │ -
此查询显示每个社区的接客次数,按一天中的小时细分
SELECT
pickup_ntaname,
toHour(pickup_datetime) as pickup_hour,
SUM(1) AS pickups
FROM trips
WHERE pickup_ntaname != ''
GROUP BY pickup_ntaname, pickup_hour
ORDER BY pickup_ntaname, pickup_hour结果看起来像
┌─pickup_ntaname───────────────────────────────────────────┬─pickup_hour─┬─pickups─┐
│ Airport │ 0 │ 3509 │
│ Airport │ 1 │ 1184 │
│ Airport │ 2 │ 401 │
│ Airport │ 3 │ 152 │
│ Airport │ 4 │ 213 │
│ Airport │ 5 │ 955 │
│ Airport │ 6 │ 2161 │
│ Airport │ 7 │ 3013 │
│ Airport │ 8 │ 3601 │
│ Airport │ 9 │ 3792 │
│ Airport │ 10 │ 4546 │
│ Airport │ 11 │ 4659 │
│ Airport │ 12 │ 4621 │
│ Airport │ 13 │ 5348 │
│ Airport │ 14 │ 5889 │
│ Airport │ 15 │ 6505 │
│ Airport │ 16 │ 6119 │
│ Airport │ 17 │ 6341 │
│ Airport │ 18 │ 6173 │
│ Airport │ 19 │ 6329 │
│ Airport │ 20 │ 6271 │
│ Airport │ 21 │ 6649 │
│ Airport │ 22 │ 6356 │
│ Airport │ 23 │ 6016 │
│ Allerton-Pelham Gardens │ 4 │ 1 │
│ Allerton-Pelham Gardens │ 6 │ 1 │
│ Allerton-Pelham Gardens │ 7 │ 1 │
│ Allerton-Pelham Gardens │ 9 │ 5 │
│ Allerton-Pelham Gardens │ 10 │ 3 │
│ Allerton-Pelham Gardens │ 15 │ 1 │
│ Allerton-Pelham Gardens │ 20 │ 2 │
│ Allerton-Pelham Gardens │ 23 │ 1 │
│ Annadale-Huguenot-Prince's Bay-Eltingville │ 23 │ 1 │
│ Arden Heights │ 11 │ 1 │ -
让我们看看去拉瓜迪亚机场或肯尼迪国际机场的行程
SELECT
pickup_datetime,
dropoff_datetime,
total_amount,
pickup_nyct2010_gid,
dropoff_nyct2010_gid,
CASE
WHEN dropoff_nyct2010_gid = 138 THEN 'LGA'
WHEN dropoff_nyct2010_gid = 132 THEN 'JFK'
END AS airport_code,
EXTRACT(YEAR FROM pickup_datetime) AS year,
EXTRACT(DAY FROM pickup_datetime) AS day,
EXTRACT(HOUR FROM pickup_datetime) AS hour
FROM trips
WHERE dropoff_nyct2010_gid IN (132, 138)
ORDER BY pickup_datetime响应是
┌─────pickup_datetime─┬────dropoff_datetime─┬─total_amount─┬─pickup_nyct2010_gid─┬─dropoff_nyct2010_gid─┬─airport_code─┬─year─┬─day─┬─hour─┐
│ 2015-07-01 00:04:14 │ 2015-07-01 00:15:29 │ 13.3 │ -34 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:09:42 │ 2015-07-01 00:12:55 │ 6.8 │ 50 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:23:04 │ 2015-07-01 00:24:39 │ 4.8 │ -125 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:27:51 │ 2015-07-01 00:39:02 │ 14.72 │ -101 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:32:03 │ 2015-07-01 00:55:39 │ 39.34 │ 48 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:34:12 │ 2015-07-01 00:40:48 │ 9.95 │ -93 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:38:26 │ 2015-07-01 00:49:00 │ 13.3 │ -11 │ 138 │ LGA │ 2015 │ 1 │ 0 │
│ 2015-07-01 00:41:48 │ 2015-07-01 00:44:45 │ 6.3 │ -94 │ 132 │ JFK │ 2015 │ 1 │ 0 │
│ 2015-07-01 01:06:18 │ 2015-07-01 01:14:43 │ 11.76 │ 37 │ 132 │ JFK │ 2015 │ 1 │ 1 │
4. 创建字典
如果您是 ClickHouse 的新手,那么理解字典的工作原理非常重要。关于字典的一个简单的想法是存储在内存中的键->值对的映射。字典的详细信息和所有选项都在教程末尾链接。
- 让我们看看如何在您的 ClickHouse 服务中创建一个与表关联的字典。该表以及字典将基于一个 CSV 文件,该文件包含 265 行,纽约市每个社区一行。社区映射到纽约市行政区(纽约市有 5 个行政区:布朗克斯区、布鲁克林区、曼哈顿区、皇后区和斯塔顿岛),并且此文件也将纽瓦克机场 (EWR) 计为一个行政区。
这是 CSV 文件的一部分(为清楚起见,显示为表格)。文件中的 LocationID 列映射到您的 trips 表中的 pickup_nyct2010_gid 和 dropoff_nyct2010_gid 列
| 位置ID | 行政区 | 区域 | 服务区 |
|---|---|---|---|
| 1 | EWR | 纽瓦克机场 | EWR |
| 2 | 皇后区 | 牙买加湾 | 行政区区域 |
| 3 | 布朗克斯区 | 奥勒顿/佩勒姆花园 | 行政区区域 |
| 4 | 曼哈顿 | 字母城 | 黄色区域 |
| 5 | 斯塔顿岛 | 阿登高地 | 行政区区域 |
- 该文件的 URL 是
https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/taxi_zone_lookup.csv。运行以下 SQL,它将创建一个名为taxi_zone_dictionary的字典,并从 S3 中的 CSV 文件填充该字典
CREATE DICTIONARY taxi_zone_dictionary
(
`LocationID` UInt16 DEFAULT 0,
`Borough` String,
`Zone` String,
`service_zone` String
)
PRIMARY KEY LocationID
SOURCE(HTTP(URL 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/taxi_zone_lookup.csv' FORMAT 'CSVWithNames'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(HASHED_ARRAY())
将 LIFETIME 设置为 0 意味着此字典永远不会使用其源更新。此处使用它是为了不向我们的 S3 存储桶发送不必要的流量,但通常您可以指定您喜欢的任何生命周期值。
例如
LIFETIME(MIN 1 MAX 10)
指定字典在 1 到 10 秒之间的某个随机时间后更新。(随机时间是必要的,以便在大量服务器上更新时分配字典源上的负载。)
-
验证它是否工作 - 您应该获得 265 行(每个社区一行)
SELECT * FROM taxi_zone_dictionary -
使用
dictGet函数(或其变体)从字典中检索值。您传入字典的名称、您想要的值以及键(在我们的示例中是taxi_zone_dictionary的LocationID列)。例如,以下查询返回
LocationID为 132 的Borough(正如我们上面看到的,它是肯尼迪国际机场)SELECT dictGet('taxi_zone_dictionary', 'Borough', 132)肯尼迪国际机场在皇后区,请注意检索值的时间基本上为 0
┌─dictGet('taxi_zone_dictionary', 'Borough', 132)─┐
│ Queens │
└─────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.004 sec. -
使用
dictHas函数查看字典中是否存在键。例如,以下查询返回 1(在 ClickHouse 中为“true”)SELECT dictHas('taxi_zone_dictionary', 132) -
以下查询返回 0,因为 4567 不是字典中
LocationID的值SELECT dictHas('taxi_zone_dictionary', 4567) -
使用
dictGet函数在查询中检索行政区的名称。例如SELECT
count(1) AS total,
dictGetOrDefault('taxi_zone_dictionary','Borough', toUInt64(pickup_nyct2010_gid), 'Unknown') AS borough_name
FROM trips
WHERE dropoff_nyct2010_gid = 132 OR dropoff_nyct2010_gid = 138
GROUP BY borough_name
ORDER BY total DESC此查询汇总了每个行政区的出租车行程数量,这些行程在拉瓜迪亚机场或肯尼迪国际机场结束。结果如下所示,请注意,有很多行程的接客社区未知
┌─total─┬─borough_name──┐
│ 23683 │ Unknown │
│ 7053 │ Manhattan │
│ 6828 │ Brooklyn │
│ 4458 │ Queens │
│ 2670 │ Bronx │
│ 554 │ Staten Island │
│ 53 │ EWR │
└───────┴───────────────┘
7 rows in set. Elapsed: 0.019 sec. Processed 2.00 million rows, 4.00 MB (105.70 million rows/s., 211.40 MB/s.)
5. 执行 Join
让我们编写一些查询,将 taxi_zone_dictionary 与您的 trips 表连接起来。
-
我们可以从一个简单的 JOIN 开始,它的作用类似于上面之前的机场查询
SELECT
count(1) AS total,
Borough
FROM trips
JOIN taxi_zone_dictionary ON toUInt64(trips.pickup_nyct2010_gid) = taxi_zone_dictionary.LocationID
WHERE dropoff_nyct2010_gid = 132 OR dropoff_nyct2010_gid = 138
GROUP BY Borough
ORDER BY total DESC响应看起来很熟悉
┌─total─┬─Borough───────┐
│ 7053 │ Manhattan │
│ 6828 │ Brooklyn │
│ 4458 │ Queens │
│ 2670 │ Bronx │
│ 554 │ Staten Island │
│ 53 │ EWR │
└───────┴───────────────┘
6 rows in set. Elapsed: 0.034 sec. Processed 2.00 million rows, 4.00 MB (59.14 million rows/s., 118.29 MB/s.)注意请注意,上面
JOIN查询的输出与之前使用dictGetOrDefault的查询相同(只是不包括Unknown值)。在幕后,ClickHouse 实际上是在为taxi_zone_dictionary字典调用dictGet函数,但JOIN语法对于 SQL 开发人员来说更熟悉。 -
我们在 ClickHouse 中不经常使用
SELECT *- 您应该只检索您实际需要的列!但是很难找到一个需要很长时间的查询,因此此查询特意选择每一列并返回每一行(默认情况下,响应中内置了 10,000 行的最大值),并且还对每一行与字典进行右连接SELECT *
FROM trips
JOIN taxi_zone_dictionary
ON trips.dropoff_nyct2010_gid = taxi_zone_dictionary.LocationID
WHERE tip_amount > 0
ORDER BY tip_amount DESC
LIMIT 1000
恭喜!
做得好 - 您已完成本教程,希望您对如何使用 ClickHouse 有了更好的理解。以下是一些后续操作的选项
- 阅读主键在 ClickHouse 中的工作原理 - 这些知识将使您在成为 ClickHouse 专家的道路上前进一大步
- 集成外部数据源,如文件、Kafka、PostgreSQL、数据管道或许多其他数据源
- 将您喜欢的 UI/BI 工具连接到 ClickHouse
- 查看 SQL 参考并浏览各种函数。ClickHouse 拥有用于转换、处理和分析数据的惊人函数集合
- 了解有关 字典的更多信息