集成 OpenTelemetry 以进行数据收集
任何可观测性解决方案都需要收集和导出日志和追踪的方法。为此,ClickHouse 推荐 OpenTelemetry (OTel) 项目。
“OpenTelemetry 是一个可观测性框架和工具包,旨在创建和管理遥测数据,例如追踪、指标和日志。”
与 ClickHouse 或 Prometheus 不同,OpenTelemetry 不是可观测性后端,而是专注于遥测数据的生成、收集、管理和导出。虽然 OpenTelemetry 最初的目标是允许用户使用特定于语言的 SDK 轻松地检测其应用程序或系统,但它已扩展到包括通过 OpenTelemetry 收集器(一个接收、处理和导出遥测数据的代理或代理)收集日志。
ClickHouse 相关组件
Open Telemetry 由许多组件组成。除了为字段/列提供数据和 API 规范、标准化协议和命名约定外,OTel 还提供了两项对于构建具有 ClickHouse 的可观测性解决方案至关重要的功能
- OpenTelemetry 收集器是一个代理,用于接收、处理和导出遥测数据。一个由 ClickHouse 驱动的解决方案使用此组件进行日志收集和事件处理,然后再进行批处理和插入。
- 语言 SDK 实现了规范、API 和遥测数据的导出。这些 SDK 有效地确保在应用程序的代码中正确记录追踪,生成构成 span 并确保上下文通过元数据在服务之间传播 - 从而形成分布式追踪并确保 span 可以关联。这些 SDK 由一个生态系统补充,该生态系统自动实现常见的库和框架,这意味着用户无需更改其代码即可获得开箱即用的检测能力。
一个由 ClickHouse 驱动的可观测性解决方案利用了这两种工具。
分发版
OpenTelemetry 收集器有许多分发版。ClickHouse 解决方案所需的文件日志接收器以及 ClickHouse 导出器仅存在于 OpenTelemetry Collector Contrib Distro 中。
此分发版包含许多组件,并允许用户尝试各种配置。但是,在生产环境中运行时,建议将收集器限制为仅包含环境所需的组件。这样做的一些原因
- 减小收集器的大小,缩短收集器的部署时间
- 通过减少可用的攻击面来提高收集器的安全性
可以使用 OpenTelemetry Collector Builder 构建自定义收集器。
使用 OTel 摄取数据
收集器部署角色
为了收集日志并将它们插入到 ClickHouse 中,我们建议使用 OpenTelemetry 收集器。OpenTelemetry 收集器可以部署在两个主要角色中
- Agent(代理) - 代理实例在边缘收集数据,例如在服务器或 Kubernetes 节点上,或直接从应用程序接收事件 - 使用 OpenTelemetry SDK 进行检测。在后一种情况下,代理实例与应用程序一起运行或与应用程序在同一主机上运行(例如 sidecar 或 DaemonSet)。代理可以直接将其数据发送到 ClickHouse 或网关实例。在前一种情况下,这被称为 Agent 部署模式。
- Gateway(网关) - 网关实例提供独立的服务(例如,Kubernetes 中的部署),通常每个集群、每个数据中心或每个区域一个。这些实例通过单个 OTLP 端点从应用程序(或其他收集器作为代理)接收事件。通常,部署一组网关实例,并使用开箱即用的负载均衡器在它们之间分配负载。如果所有代理和应用程序都将其信号发送到此单个端点,则通常称为 Gateway 部署模式。
下面我们假设一个简单的代理收集器,将其事件直接发送到 ClickHouse。有关使用网关以及何时适用网关的更多详细信息,请参阅 使用网关进行扩展。
收集日志
使用收集器的主要优势在于它允许您的服务快速卸载数据,而将诸如重试、批处理、加密甚至敏感数据过滤等额外处理留给收集器处理。
收集器在其三个主要处理阶段使用术语 receiver(接收器)、processor(处理器) 和 exporter(导出器)。接收器用于数据收集,可以是拉取或推送式的。处理器提供执行消息转换和丰富的能力。导出器负责将数据发送到下游服务。虽然理论上此服务可以是另一个收集器,但我们在下面的初始讨论中假设所有数据都直接发送到 ClickHouse。
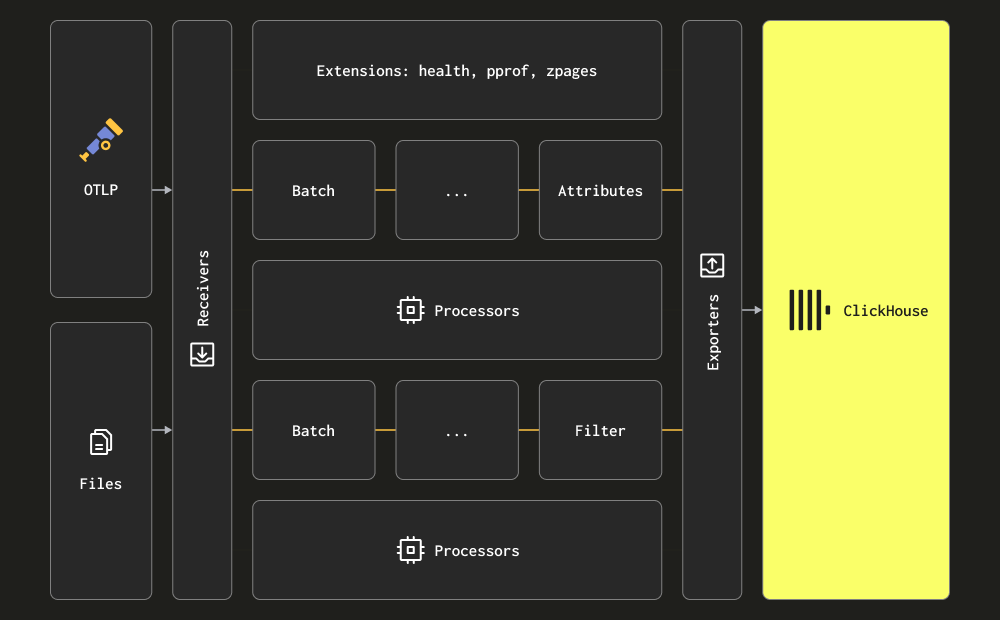
我们建议用户熟悉完整的接收器、处理器和导出器集。
收集器提供两个主要的接收器来收集日志
通过 OTLP - 在这种情况下,日志通过 OTLP 协议从 OpenTelemetry SDK 直接发送(推送)到收集器。OpenTelemetry 演示采用了这种方法,每种语言的 OTLP 导出器都假定本地收集器端点。在这种情况下,收集器必须配置 OTLP 接收器 - 请参阅上面的 演示配置。这种方法的优点是日志数据将自动包含追踪 ID,允许用户稍后识别特定日志的追踪,反之亦然。
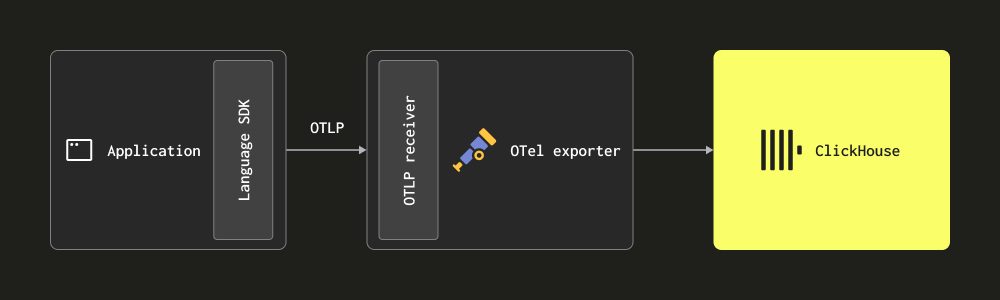
此方法要求用户使用其适当的语言 SDK 检测其代码。
- 通过 Filelog 接收器进行抓取 - 此接收器跟踪磁盘上的文件并制定日志消息,然后将这些消息发送到 ClickHouse。此接收器处理复杂的任务,例如检测多行消息、处理日志轮换、检查点以确保重启的鲁棒性以及提取结构。此接收器还能够跟踪 Docker 和 Kubernetes 容器日志,可作为 helm chart 部署,从这些日志中提取结构并使用 pod 详细信息丰富它们。
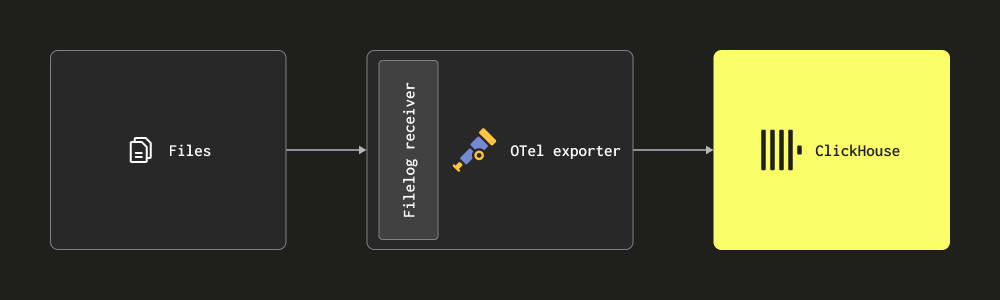
大多数部署将使用上述接收器的组合。我们建议用户阅读收集器文档并熟悉基本概念,以及配置结构和安装方法。
结构化与非结构化
日志可以是结构化的或非结构化的。
结构化日志将采用诸如 JSON 之类的数据格式,定义诸如 http 代码和源 IP 地址之类的元数据字段。
{
"remote_addr":"54.36.149.41",
"remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET",
"request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1",
"status":"200",
"size":"30577",
"referer":"-",
"user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"
}
非结构化日志,虽然通常也具有可以通过正则表达式模式提取的某些固有结构,但将日志纯粹表示为字符串。
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET
/filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"
我们建议用户尽可能采用结构化日志记录并以 JSON(即 ndjson)格式记录日志。这将简化稍后所需的日志处理,无论是在使用 Collector 处理器 发送到 ClickHouse 之前,还是在使用物化视图的插入时。结构化日志最终将节省稍后的处理资源,从而减少 ClickHouse 解决方案中所需的 CPU。
示例
为了示例目的,我们提供了结构化 (JSON) 和非结构化日志记录数据集,每个数据集大约有 1000 万行,可从以下链接获得
我们在下面的示例中使用结构化数据集。确保下载并解压缩此文件以重现以下示例。
以下表示 OTel 收集器的简单配置,该配置使用 filelog 接收器读取磁盘上的这些文件,并将结果消息输出到 stdout。我们使用 json_parser 运算符,因为我们的日志是结构化的。修改 access-structured.log 文件的路径。
以下示例从日志中提取时间戳。这需要使用 json_parser 运算符,该运算符将整个日志行转换为 JSON 字符串,并将结果放在 LogAttributes 中。这可能在计算上很昂贵,并且 可以在 ClickHouse 中更有效地完成 - 使用 SQL 提取结构。一个等效的非结构化示例,它使用 regex_parser 来实现此目的,可以在 此处找到。
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
processors:
batch:
timeout: 5s
send_batch_size: 1
exporters:
logging:
loglevel: debug
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [logging]
用户可以按照 官方说明 在本地安装收集器。重要的是,确保修改说明以使用 contrib 分发版(其中包含 filelog 接收器),例如,用户将下载 otelcol-contrib_0.102.1_darwin_arm64.tar.gz 而不是 otelcol_0.102.1_darwin_arm64.tar.gz。可以在 此处 找到版本。
安装完成后,可以使用以下命令运行 OTel 收集器
./otelcol-contrib --config config-logs.yaml
假设使用结构化日志,消息将采用以下形式输出
LogRecord #98
ObservedTimestamp: 2024-06-19 13:21:16.414259 +0000 UTC
Timestamp: 2019-01-22 01:12:53 +0000 UTC
SeverityText:
SeverityNumber: Unspecified(0)
Body: Str({"remote_addr":"66.249.66.195","remote_user":"-","run_time":"0","time_local":"2019-01-22 01:12:53.000","request_type":"GET","request_path":"\/product\/7564","request_protocol":"HTTP\/1.1","status":"301","size":"178","referer":"-","user_agent":"Mozilla\/5.0 (Linux; Android 6.0.1; Nexus 5X Build\/MMB29P) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/41.0.2272.96 Mobile Safari\/537.36 (compatible; Googlebot\/2.1; +http:\/\/www.google.com\/bot.html)"})
Attributes:
-> remote_user: Str(-)
-> request_protocol: Str(HTTP/1.1)
-> time_local: Str(2019-01-22 01:12:53.000)
-> user_agent: Str(Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html))
-> log.file.name: Str(access.log)
-> status: Str(301)
-> size: Str(178)
-> referer: Str(-)
-> remote_addr: Str(66.249.66.195)
-> request_type: Str(GET)
-> request_path: Str(/product/7564)
-> run_time: Str(0)
Trace ID:
Span ID:
Flags: 0
以上表示 OTel 收集器生成的单个日志消息。我们在后面的章节中将这些相同的消息摄取到 ClickHouse 中。
日志消息的完整模式,以及如果使用其他接收器可能存在的其他列,维护在 此处。我们强烈建议用户熟悉此模式。
这里的关键是日志行本身作为字符串保存在 Body 字段中,但 JSON 已通过 json_parser 自动提取到 Attributes 字段。相同的 运算符 已用于将时间戳提取到相应的 Timestamp 列。有关使用 OTel 处理日志的建议,请参阅 处理。
运算符是日志处理的最基本单元。每个运算符都履行一个单一的职责,例如从文件中读取行或从字段中解析 JSON。然后将运算符链接到一个管道中以实现所需的结果。
以上消息没有 TraceID 或 SpanID 字段。如果存在,例如在用户实现 分布式追踪 的情况下,可以使用上面显示的相同技术从 JSON 中提取这些字段。
对于需要收集本地或 Kubernetes 日志文件的用户,我们建议用户熟悉 filelog 接收器 的可用配置选项,以及如何处理 偏移量 和 多行日志解析。
收集 Kubernetes 日志
为了收集 Kubernetes 日志,我们推荐 Open Telemetry 文档指南。Kubernetes Attributes Processor(Kubernetes 属性处理器) 建议用于使用 pod 元数据丰富日志和指标。这可能会生成动态元数据,例如标签,存储在 ResourceAttributes 列中。ClickHouse 目前为此列使用 Map(String, String) 类型。有关处理和优化此类型的更多详细信息,请参阅 使用 Map 和 从 Map 中提取。
收集追踪
对于希望检测其代码并收集追踪的用户,我们建议遵循官方 OTel 文档。
为了将事件传递到 ClickHouse,用户需要部署一个 OTel 收集器,以通过适当的接收器通过 OTLP 协议接收追踪事件。OpenTelemetry 演示提供了一个 检测每种受支持语言的示例,并将事件发送到收集器。下面显示了一个适当的收集器配置示例,该配置将事件输出到 stdout
示例
由于追踪必须通过 OTLP 接收,我们使用 telemetrygen 工具来生成追踪数据。按照 此处 的说明进行安装。
以下配置在 OTLP 接收器上接收追踪事件,然后将它们发送到 stdout。
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 1s
exporters:
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging]
通过以下方式运行此配置
./otelcol-contrib --config config-traces.yaml
通过 telemetrygen 将追踪事件发送到收集器
$GOBIN/telemetrygen traces --otlp-insecure --traces 300
这将导致类似于以下示例的追踪消息输出到 stdout
Span #86
Trace ID : 1bb5cdd2c9df5f0da320ca22045c60d9
Parent ID : ce129e5c2dd51378
ID : fbb14077b5e149a0
Name : okey-dokey-0
Kind : Server
Start time : 2024-06-19 18:03:41.603868 +0000 UTC
End time : 2024-06-19 18:03:41.603991 +0000 UTC
Status code : Unset
Status message :
Attributes:
-> net.peer.ip: Str(1.2.3.4)
-> peer.service: Str(telemetrygen-client)
以上表示 OTel 收集器生成的单个追踪消息。我们在后面的章节中将这些相同的消息摄取到 ClickHouse 中。
追踪消息的完整模式维护在 此处。我们强烈建议用户熟悉此模式。
处理 - 过滤、转换和丰富
正如在设置日志事件时间戳的早期示例中演示的那样,用户总是希望过滤、转换和丰富事件消息。这可以使用 Open Telemetry 中的许多功能来实现
-
Processors(处理器) - 处理器获取 接收器收集的数据,并在将其发送到导出器之前对其进行修改或转换。处理器按照收集器配置的
processors部分中配置的顺序应用。这些是可选的,但 通常建议 最小的集合。当将 OTel 收集器与 ClickHouse 一起使用时,我们建议将处理器限制为- memory_limiter(内存限制器) 用于防止收集器上出现内存不足的情况。有关建议,请参阅 估计资源。
- 任何基于上下文进行丰富的处理器。例如,Kubernetes Attributes Processor(Kubernetes 属性处理器) 允许使用 k8s 元数据自动设置 span、指标和日志资源属性,例如使用其源 pod id 丰富事件。
- 如果追踪需要,则进行 尾部或头部采样。
- 基本过滤 - 如果无法通过运算符完成,则删除不需要的事件(见下文)。
- Batching(批处理) - 与 ClickHouse 一起使用时必不可少,以确保数据以批处理形式发送。请参阅 “导出到 ClickHouse”。
-
Operators(运算符) - 运算符 提供接收器处可用的最基本处理单元。支持基本解析,允许设置诸如 Severity 和 Timestamp 之类的字段。此处支持 JSON 和正则表达式解析以及事件过滤和基本转换。我们建议在此处执行事件过滤。
我们建议用户避免使用运算符或 transform processors(转换处理器) 进行过多的事件处理。这些可能会导致相当大的内存和 CPU 开销,尤其是 JSON 解析。除了某些例外情况(特别是上下文感知的丰富,例如添加 k8s 元数据)之外,可以使用物化视图和列在插入时在 ClickHouse 中完成所有处理。有关更多详细信息,请参阅 使用 SQL 提取结构。
如果使用 OTel 收集器完成处理,我们建议在网关实例上进行转换,并最大限度地减少在代理实例上完成的任何工作。这将确保在服务器上运行的边缘代理所需的资源尽可能少。通常,我们看到用户仅执行过滤(以最大限度地减少不必要的网络使用)、时间戳设置(通过运算符)和丰富,这需要在代理中提供上下文。例如,如果网关实例驻留在不同的 Kubernetes 集群中,则 k8s 丰富将需要在代理中进行。
示例
以下配置显示了非结构化日志文件的收集。请注意,使用了运算符从日志行(regex_parser)中提取结构并过滤事件,以及使用处理器批处理事件和限制内存使用。
config-unstructured-logs-with-processor.yaml
receivers:
filelog:
include:
- /opt/data/logs/access-unstructured.log
start_at: beginning
operators:
- type: regex_parser
regex: '^(?P<ip>[\d.]+)\s+-\s+-\s+\[(?P<timestamp>[^\]]+)\]\s+"(?P<method>[A-Z]+)\s+(?P<url>[^\s]+)\s+HTTP/[^\s]+"\s+(?P<status>\d+)\s+(?P<size>\d+)\s+"(?P<referrer>[^"]*)"\s+"(?P<user_agent>[^"]*)"'
timestamp:
parse_from: attributes.timestamp
layout: '%d/%b/%Y:%H:%M:%S %z'
#22/Jan/2019:03:56:14 +0330
processors:
batch:
timeout: 1s
send_batch_size: 100
memory_limiter:
check_interval: 1s
limit_mib: 2048
spike_limit_mib: 256
exporters:
logging:
loglevel: debug
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch, memory_limiter]
exporters: [logging]
./otelcol-contrib --config config-unstructured-logs-with-processor.yaml
导出到 ClickHouse
导出器将数据发送到一个或多个后端或目标。导出器可以是拉取或推送式的。为了将事件发送到 ClickHouse,用户需要使用基于推送的 ClickHouse 导出器。
ClickHouse exporter 是 OpenTelemetry Collector Contrib 的一部分,而不是核心发行版。用户可以使用 contrib 发行版,也可以构建自己的 Collector。
完整的配置文件如下所示。
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 5s
send_batch_size: 5000
exporters:
clickhouse:
endpoint: tcp://:9000?dial_timeout=10s&compress=lz4&async_insert=1
# ttl: 72h
traces_table_name: otel_traces
logs_table_name: otel_logs
create_schema: true
timeout: 5s
database: default
sending_queue:
queue_size: 1000
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [clickhouse]
traces:
receivers: [otlp]
processors: [batch]
exporters: [clickhouse]
请注意以下关键设置
- pipelines - 上述配置重点介绍了 pipelines 的使用,它由一组接收器、处理器和导出器组成,其中一个用于日志,另一个用于追踪。
- endpoint - 与 ClickHouse 的通信通过
endpoint参数配置。连接字符串tcp://:9000?dial_timeout=10s&compress=lz4&async_insert=1指定通过 TCP 进行通信。如果用户出于流量切换的原因更喜欢 HTTP,请按照此处的描述修改此连接字符串。完整的连接详情,以及在此连接字符串中指定用户名和密码的功能,请参见此处。
重要提示: 请注意,上述连接字符串同时启用了压缩 (lz4) 和异步插入。我们建议始终启用这两者。有关异步插入的更多详细信息,请参阅批量处理。应始终指定压缩,并且在较旧版本的导出器中默认情况下不会启用压缩。
- ttl - 此处的值决定了数据保留的时间。更多详情请参见“数据管理”。这应以小时为单位指定,例如 72h。我们在下面的示例中禁用了 TTL,因为我们的数据来自 2019 年,如果插入,ClickHouse 将立即删除这些数据。
- traces_table_name 和 logs_table_name - 决定了日志和追踪表的名称。
- create_schema - 决定了是否在启动时使用默认模式创建表。默认为 true,以便快速入门。用户应将其设置为 false 并定义自己的模式。
- database - 目标数据库。
- retry_on_failure - 确定是否应重试失败批次的设置。
- batch - 批处理器确保事件以批次形式发送。我们建议值约为 5000,超时时间为 5 秒。无论哪个先达到,都将启动一个批次刷新到导出器。降低这些值意味着更低延迟的管道,数据可以更快地用于查询,但代价是更多连接和发送到 ClickHouse 的批次。如果用户未使用异步插入,则不建议这样做,因为它可能会导致 ClickHouse 中parts 过多的问题。相反,如果用户正在使用异步插入,则用于查询的数据可用性也将取决于异步插入设置 - 尽管数据仍将更快地从连接器刷新。有关更多详细信息,请参阅批量处理。
- sending_queue - 控制发送队列的大小。队列中的每个项目都包含一个批次。如果此队列超出限制(例如,由于 ClickHouse 无法访问但事件继续到达),则批次将被丢弃。
假设用户已提取结构化日志文件并运行了本地 ClickHouse 实例(使用默认身份验证),用户可以通过以下命令运行此配置
./otelcol-contrib --config clickhouse-config.yaml
要将追踪数据发送到此 Collector,请使用 telemetrygen 工具运行以下命令
$GOBIN/telemetrygen traces --otlp-insecure --traces 300
运行后,使用简单的查询确认日志事件是否存在
SELECT *
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Timestamp: 2019-01-22 06:46:14.000000000
TraceId:
SpanId:
TraceFlags: 0
SeverityText:
SeverityNumber: 0
ServiceName:
Body: {"remote_addr":"109.230.70.66","remote_user":"-","run_time":"0","time_local":"2019-01-22 06:46:14.000","request_type":"GET","request_path":"\/image\/61884\/productModel\/150x150","request_protocol":"HTTP\/1.1","status":"200","size":"1684","referer":"https:\/\/www.zanbil.ir\/filter\/p3%2Cb2","user_agent":"Mozilla\/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko\/20100101 Firefox\/64.0"}
ResourceSchemaUrl:
ResourceAttributes: {}
ScopeSchemaUrl:
ScopeName:
ScopeVersion:
ScopeAttributes: {}
LogAttributes: {'referer':'https://www.zanbil.ir/filter/p3%2Cb2','log.file.name':'access-structured.log','run_time':'0','remote_user':'-','request_protocol':'HTTP/1.1','size':'1684','user_agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0','remote_addr':'109.230.70.66','request_path':'/image/61884/productModel/150x150','status':'200','time_local':'2019-01-22 06:46:14.000','request_type':'GET'}
1 row in set. Elapsed: 0.012 sec. Processed 5.04 thousand rows, 4.62 MB (414.14 thousand rows/s., 379.48 MB/s.)
Peak memory usage: 5.41 MiB.
Likewise, for trace events, users can check the `otel_traces` table:
SELECT *
FROM otel_traces
LIMIT 1
FORMAT Vertical
Row 1:
──────
Timestamp: 2024-06-20 11:36:41.181398000
TraceId: 00bba81fbd38a242ebb0c81a8ab85d8f
SpanId: beef91a2c8685ace
ParentSpanId:
TraceState:
SpanName: lets-go
SpanKind: SPAN_KIND_CLIENT
ServiceName: telemetrygen
ResourceAttributes: {'service.name':'telemetrygen'}
ScopeName: telemetrygen
ScopeVersion:
SpanAttributes: {'peer.service':'telemetrygen-server','net.peer.ip':'1.2.3.4'}
Duration: 123000
StatusCode: STATUS_CODE_UNSET
StatusMessage:
Events.Timestamp: []
Events.Name: []
Events.Attributes: []
Links.TraceId: []
Links.SpanId: []
Links.TraceState: []
Links.Attributes: []
开箱即用模式
默认情况下,ClickHouse exporter 为日志和追踪都创建一个目标日志表。可以通过设置 create_schema 禁用此功能。此外,日志和追踪表的名称都可以通过上述设置从默认的 otel_logs 和 otel_traces 修改。
在下面的模式中,我们假设 TTL 已启用为 72 小时。
下面显示了日志的默认模式 (otelcol-contrib v0.102.1)
CREATE TABLE default.otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_key mapKeys(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_value mapValues(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(3)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
此处的列与 OTel 官方日志规范相对应,文档请参阅此处。
关于此模式的一些重要说明
- 默认情况下,表按日期分区,通过
PARTITION BY toDate(Timestamp)。这使得删除过期数据非常高效。 - TTL 通过
TTL toDateTime(Timestamp) + toIntervalDay(3)设置,并与 Collector 配置中设置的值相对应。ttl_only_drop_parts=1表示仅当所有包含的行都过期时,才删除整个 parts。这比删除 parts 中的行更有效,后者会产生昂贵的删除操作。我们建议始终设置此项。有关更多详细信息,请参阅使用 TTL 进行数据管理。 - 该表使用经典的
MergeTree引擎。建议将此引擎用于日志和追踪,无需更改。 - 表按
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)排序。这意味着查询将针对ServiceName、SeverityText、Timestamp和TraceId的过滤器进行优化 - 列表中较早的列将比后面的列更快地进行过滤,例如,按ServiceName过滤将比按TraceId过滤快得多。用户应根据其预期的访问模式修改此排序 - 请参阅选择主排序键。 - 上述模式将
ZSTD(1)应用于列。这为日志提供了最佳压缩。用户可以提高 ZSTD 压缩级别(高于默认值 1)以获得更好的压缩,但这很少有益。增加此值将在插入时(压缩期间)产生更大的 CPU 开销,但解压缩(以及查询)应保持相当。有关更多详细信息,请参阅此处。额外的 delta 编码应用于 Timestamp,目的是减小其在磁盘上的大小。 - 请注意
ResourceAttributes、LogAttributes和ScopeAttributes是 map。用户应熟悉这些 map 之间的区别。有关如何访问这些 map 并优化访问其中键的信息,请参阅使用 map。 - 此处的大多数其他类型(例如,作为 LowCardinality 的
ServiceName)都已优化。请注意,Body 虽然在我们示例日志中是 JSON,但存储为 String。 - Bloom 过滤器应用于 map 的键和值,以及 Body 列。这些旨在提高访问这些列的查询时间,但通常不是必需的。请参阅辅助/数据跳过索引。
CREATE TABLE default.otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(3)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
同样,这将与 OTel 官方追踪规范对应的列相关联,文档请参阅此处。此处的模式采用了与上述日志模式相同的许多设置,并添加了特定于 span 的 Link 列。
我们建议用户禁用自动模式创建并手动创建表。这样可以修改主键和二级键,并有机会引入其他列以优化查询性能。有关更多详细信息,请参阅模式设计。
优化插入
为了在获得强大的数据一致性保证的同时实现高插入性能,用户在通过 Collector 将可观测性数据插入 ClickHouse 时应遵守简单的规则。通过正确配置 OTel Collector,应该很容易遵循以下规则。这还可以避免用户首次使用 ClickHouse 时遇到的常见问题。
批量处理
默认情况下,每次发送到 ClickHouse 的插入都会导致 ClickHouse 立即创建一个存储 part,其中包含来自插入的数据以及需要存储的其他元数据。因此,与发送大量每个都包含较少数据的插入相比,发送少量每个都包含更多数据的插入将减少所需的写入次数。我们建议以相当大的批次(每次至少 1,000 行)插入数据。更多详细信息请参阅此处。
默认情况下,插入到 ClickHouse 的操作是同步的,并且如果相同则是幂等的。对于 merge tree 引擎系列的表,ClickHouse 默认情况下会自动去重插入。这意味着插入在以下情况下是容错的
- (1) 如果接收数据的节点出现问题,则插入查询将超时(或收到更具体的错误)并且不会收到确认。
- (2) 如果数据已由节点写入,但由于网络中断而无法将确认返回给查询发送者,则发送者将收到超时或网络错误。
从 Collector 的角度来看,(1) 和 (2) 可能难以区分。但是,在这两种情况下,未确认的插入都可以立即重试。只要重试的插入查询包含相同顺序的相同数据,如果(未确认的)原始插入成功,ClickHouse 将自动忽略重试的插入。
我们建议用户使用前面配置中显示的批处理器来满足上述要求。这确保了插入作为满足上述要求的一致的行批次发送。如果 Collector 预期具有高吞吐量(每秒事件数),并且每次插入可以发送至少 5000 个事件,则这通常是管道中唯一需要的批处理。在这种情况下,Collector 将在批处理器的 timeout 到达之前刷新批次,从而确保管道的端到端延迟保持较低,并且批次大小一致。
使用异步插入
通常,当 Collector 的吞吐量较低时,用户被迫发送较小的批次,但他们仍然希望数据在最短的端到端延迟内到达 ClickHouse。在这种情况下,当批处理器的 timeout 过期时,会发送小批次。这可能会导致问题,这时就需要异步插入。这种情况通常发生在代理角色中的 Collector 被配置为直接发送到 ClickHouse 时。网关通过充当聚合器可以缓解此问题 - 请参阅使用网关进行扩展。
如果无法保证大批次,用户可以使用异步插入将批处理委托给 ClickHouse。使用异步插入,数据首先插入到缓冲区,然后分别在稍后或异步写入数据库存储。
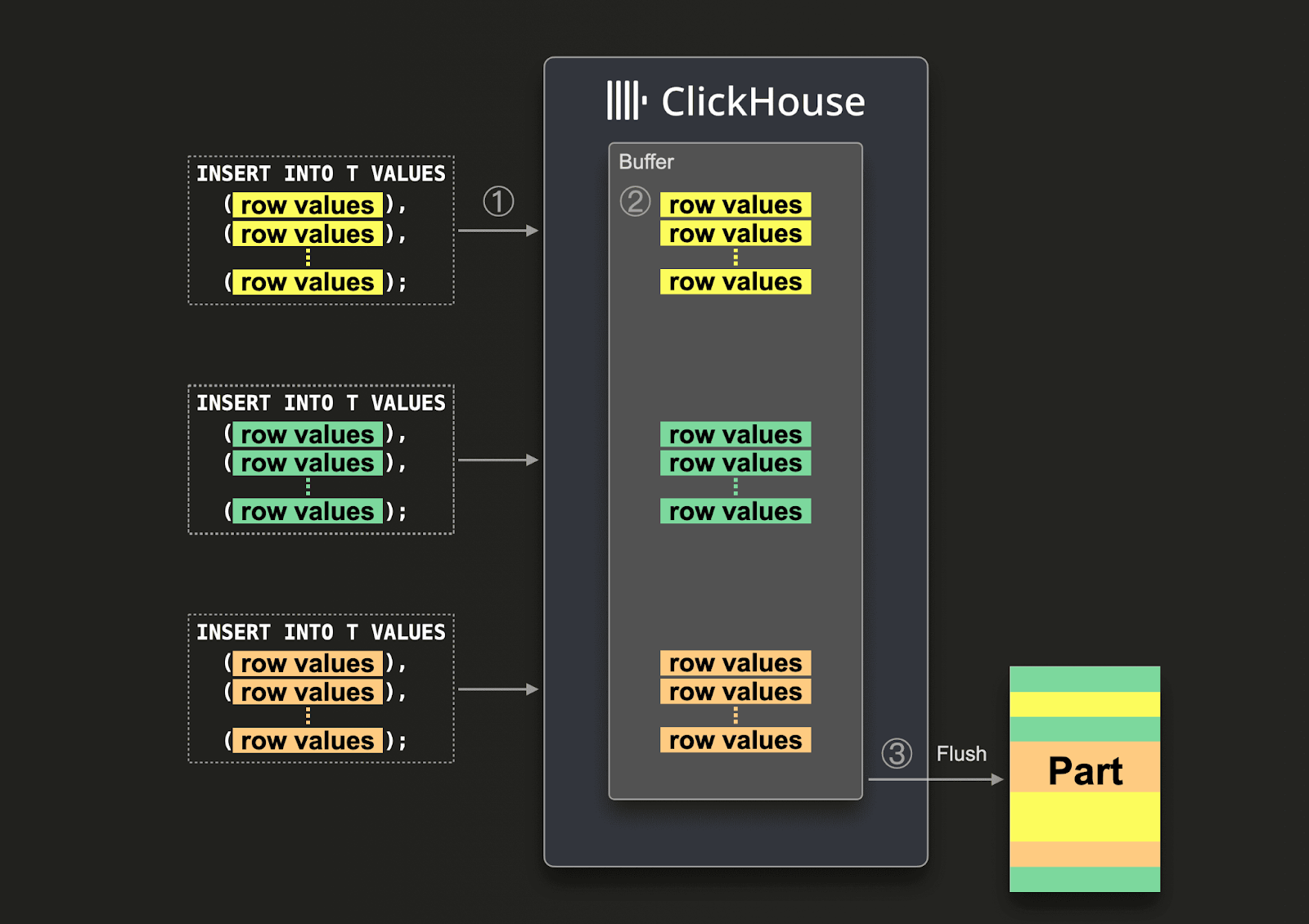
使用启用的异步插入,当 ClickHouse ① 接收到插入查询时,查询的数据 ② 立即首先写入内存缓冲区。当 ③ 下一次缓冲区刷新发生时,缓冲区的数据将排序并作为 part 写入数据库存储。请注意,在刷新到数据库存储之前,数据不可用于查询搜索;缓冲区刷新是可配置的。
要为 Collector 启用异步插入,请将 async_insert=1 添加到连接字符串。我们建议用户使用 wait_for_async_insert=1(默认值)以获得交付保证 - 有关更多详细信息,请参阅此处。
来自异步插入的数据在 ClickHouse 缓冲区刷新后插入。这发生在超过 async_insert_max_data_size 或自第一个 INSERT 查询以来经过 async_insert_busy_timeout_ms 毫秒之后。如果 async_insert_stale_timeout_ms 设置为非零值,则数据在自上次查询以来经过 async_insert_stale_timeout_ms 毫秒后插入。用户可以调整这些设置以控制其管道的端到端延迟。有关可用于调整缓冲区刷新的更多设置,请参阅此处。通常,默认值是合适的。
在使用的代理数量较少、吞吐量较低但端到端延迟要求严格的情况下,自适应异步插入可能很有用。通常,这些不适用于 ClickHouse 中看到的高吞吐量可观测性用例。
最后,与同步插入 ClickHouse 相关的先前去重行为在使用异步插入时默认情况下未启用。如果需要,请参阅设置 async_insert_deduplicate。
有关配置此功能的完整详细信息,请参见此处,深入探讨请参见此处。
部署架构
将 OTel Collector 与 ClickHouse 结合使用时,有几种可能的部署架构。我们在下面描述每种架构及其可能的适用场景。
仅代理
在仅代理架构中,用户将 OTel Collector 作为代理部署到边缘。这些代理接收来自本地应用程序的追踪(例如,作为 sidecar 容器),并从服务器和 Kubernetes 节点收集日志。在这种模式下,代理将其数据直接发送到 ClickHouse。
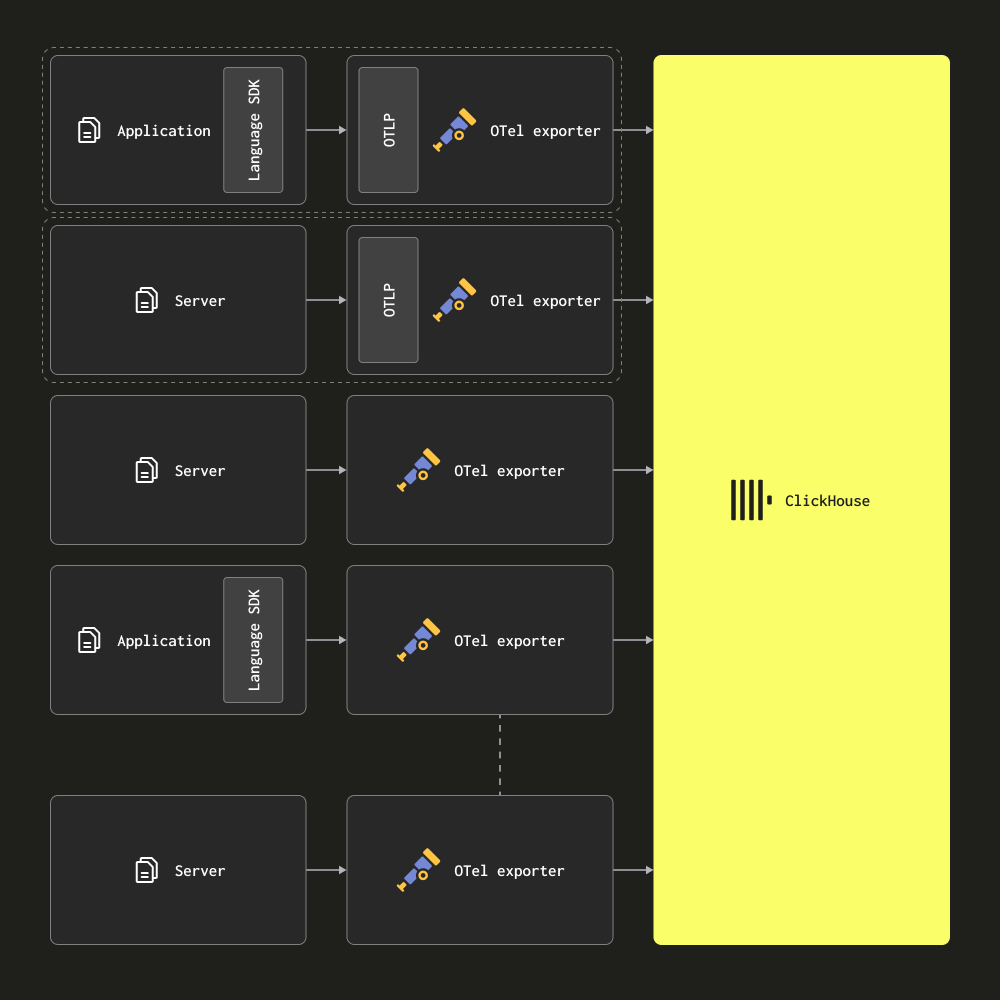
此架构适用于中小型部署。其主要优点是不需要额外的硬件,并将 ClickHouse 可观测性解决方案的总资源占用保持在最低水平,应用程序和 Collector 之间具有简单的映射关系。
一旦代理数量超过数百个,用户应考虑迁移到基于网关的架构。此架构有几个缺点,使其难以扩展
- 连接扩展 - 每个代理都将建立与 ClickHouse 的连接。虽然 ClickHouse 能够维护数百个(甚至数千个)并发插入连接,但这最终将成为一个限制因素,并使插入效率降低 - 即 ClickHouse 维护连接将使用更多资源。使用网关可以最大限度地减少连接数,并提高插入效率。
- 边缘处理 - 在此架构中,任何转换或事件处理都必须在边缘或 ClickHouse 中执行。除了具有限制性之外,这还可能意味着复杂的 ClickHouse 实物化视图,或者将大量的计算推送到边缘 - 在边缘,关键服务可能会受到影响,并且资源稀缺。
- 小批次和延迟 - 代理 Collector 可能会单独收集非常少的事件。这通常意味着需要将它们配置为按设定的间隔刷新,以满足交付 SLA。这可能会导致 Collector 向 ClickHouse 发送小批次。虽然这是一个缺点,但可以通过异步插入来缓解 - 请参阅优化插入。
使用网关进行扩展
OTel Collector 可以部署为网关实例,以解决上述限制。这些网关提供独立的服务,通常每个数据中心或每个区域一个。这些网关通过单个 OTLP 端点接收来自应用程序(或代理角色中的其他 Collector)的事件。通常部署一组网关实例,并使用开箱即用的负载均衡器在它们之间分配负载。
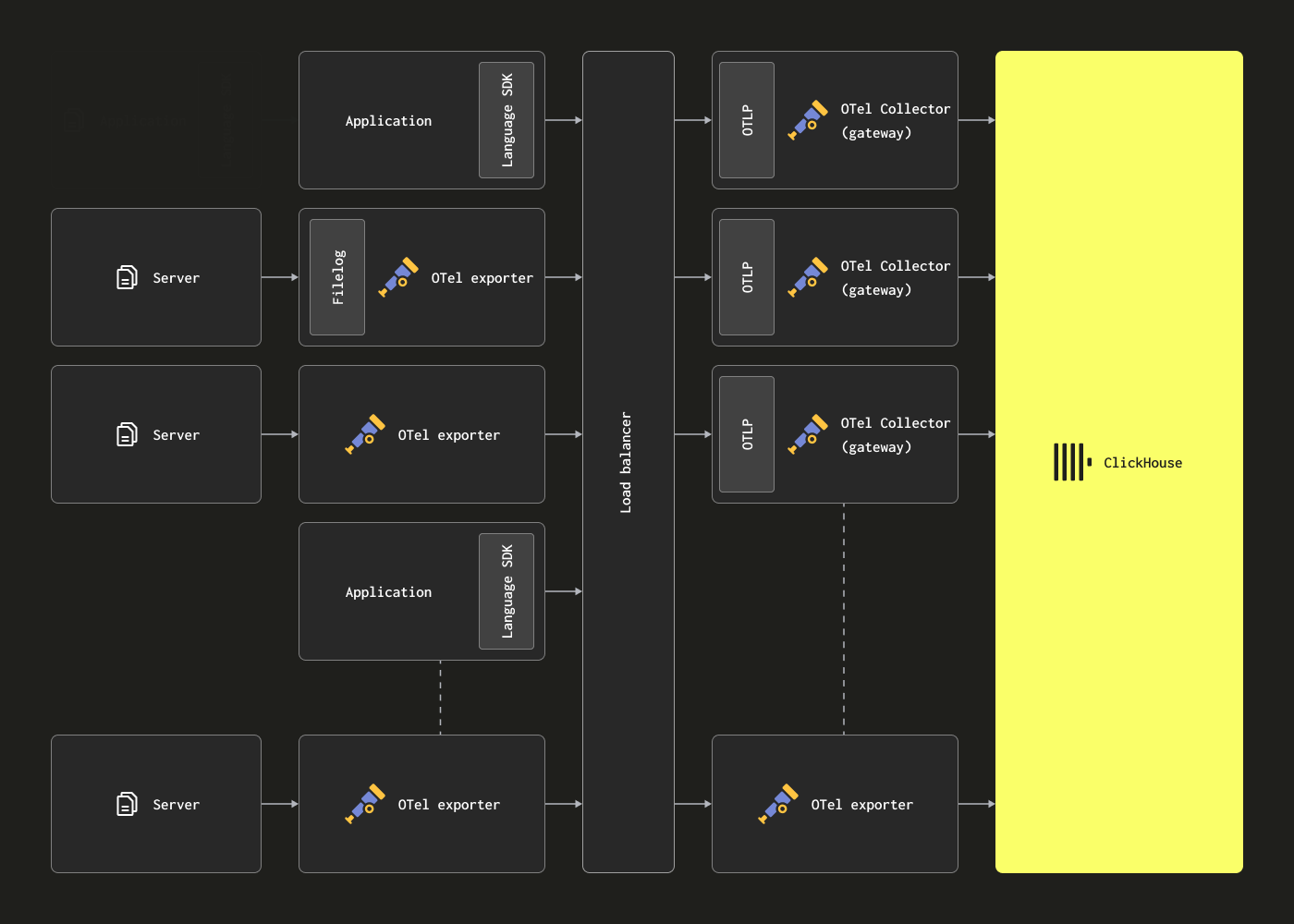
此架构的目标是从代理卸载计算密集型处理,从而最大限度地减少其资源使用。这些网关可以执行原本需要在代理上完成的转换任务。此外,通过聚合来自多个代理的事件,网关可以确保向 ClickHouse 发送大批次 - 从而实现高效插入。随着添加更多代理和事件吞吐量增加,这些网关 Collector 可以轻松扩展。下面显示了一个示例网关配置,以及一个使用示例结构化日志文件的关联代理配置。请注意,代理和网关之间的通信使用了 OTLP。
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
processors:
batch:
timeout: 5s
send_batch_size: 1000
exporters:
otlp:
endpoint: localhost:4317
tls:
insecure: true # Set to false if you are using a secure connection
service:
telemetry:
metrics:
address: 0.0.0.0:9888 # Modified as 2 collectors running on same host
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [otlp]
clickhouse-gateway-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 5s
send_batch_size: 10000
exporters:
clickhouse:
endpoint: tcp://:9000?dial_timeout=10s&compress=lz4
ttl: 96h
traces_table_name: otel_traces
logs_table_name: otel_logs
create_schema: true
timeout: 10s
database: default
sending_queue:
queue_size: 10000
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
logs:
receivers: [otlp]
processors: [batch]
exporters: [clickhouse]
这些配置可以使用以下命令运行。
./otelcol-contrib --config clickhouse-gateway-config.yaml
./otelcol-contrib --config clickhouse-agent-config.yaml
此架构的主要缺点是管理一组 Collector 相关的成本和开销。
有关管理更大的基于网关的架构以及相关学习的示例,我们推荐这篇博客文章。
添加 Kafka
读者可能会注意到上述架构未使用 Kafka 作为消息队列。
使用 Kafka 队列作为消息缓冲区是在日志记录架构中常见的流行设计模式,并由 ELK 堆栈推广。它提供了一些好处;主要是,它有助于提供更强的消息传递保证并帮助处理反压。消息从收集代理发送到 Kafka 并写入磁盘。理论上,集群式 Kafka 实例应提供高吞吐量消息缓冲区,因为它线性写入数据到磁盘比解析和处理消息(例如,在 Elastic 中,分词和索引会产生大量开销)产生的计算开销更少。通过将数据从代理移开,还可以减少因源端日志轮换而丢失消息的风险。最后,它提供了一些消息回复和跨区域复制功能,这可能对某些用例具有吸引力。
但是,ClickHouse 可以非常快速地插入数据 - 在中等硬件上每秒数百万行。来自 ClickHouse 的反压很少见。通常,利用 Kafka 队列意味着更多的架构复杂性和成本。如果您可以接受日志不需要与银行交易和其他任务关键型数据相同的交付保证的原则,我们建议避免 Kafka 的复杂性。
但是,如果您需要高交付保证或重放数据(可能到多个源)的能力,Kafka 可能是一个有用的架构补充。
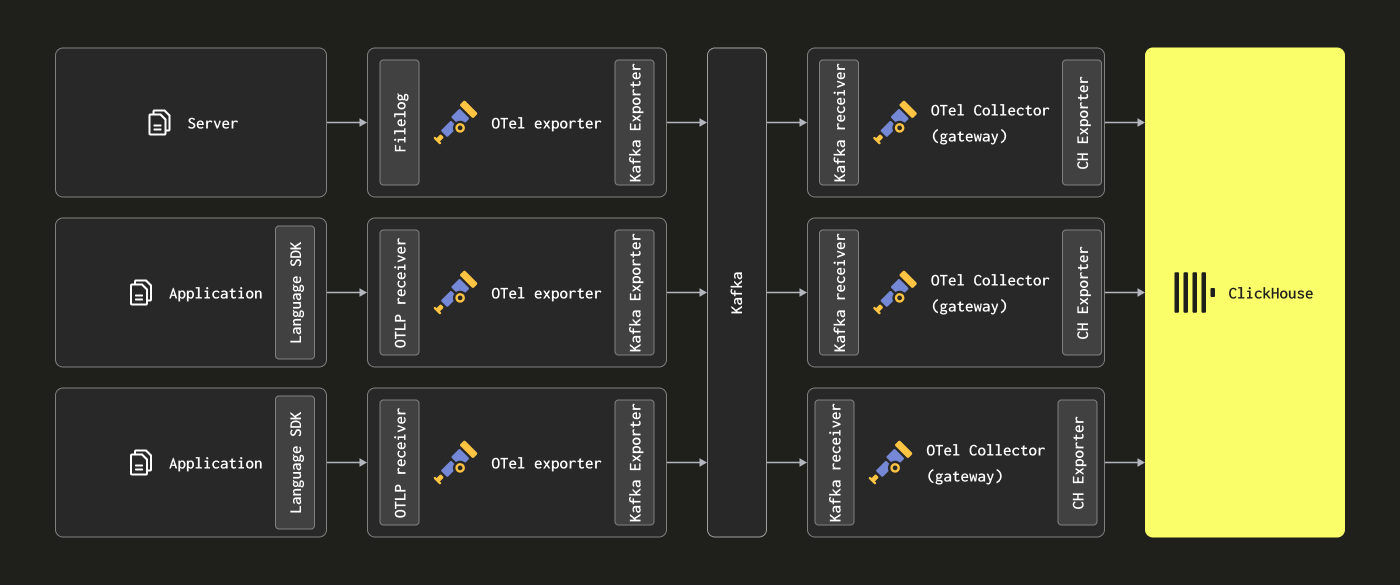
在这种情况下,OTel 代理可以配置为通过 Kafka exporter 将数据发送到 Kafka。反过来,网关实例使用 Kafka receiver 消费消息。我们建议参考 Confluent 和 OTel 文档以获取更多详细信息。
估计资源
OTel Collector 的资源需求将取决于事件吞吐量、消息大小和执行的处理量。OpenTelemetry 项目维护了基准测试,用户可以使用这些基准测试来估计资源需求。
根据我们的经验,具有 3 个核心和 12GB RAM 的网关实例可以处理大约每秒 6 万个事件。这假设一个最小的处理管道,负责重命名字段,并且没有正则表达式。
对于负责将事件发送到网关的代理实例,并且仅设置事件的时间戳,我们建议用户根据预期的每秒日志数来确定大小。以下代表用户可以作为起点的近似数字
日志记录速率 Collector 代理的资源 1k/秒 0.2CPU, 0.2GiB 5k/秒 0.5 CPU, 0.5GiB 10k/秒 1 CPU, 1GiB
| 日志记录速率 | Collector 代理的资源 |
|---|---|
| 1k/秒 | 0.2CPU, 0.2GiB |
| 5k/秒 | 0.5 CPU, 0.5GiB |
| 10k/秒 | 1 CPU, 1GiB |