使用 ClickHouse 分析 Stack Overflow 数据
此数据集包含 Stack Overflow 上发生的所有 Posts、Users、Votes、Comments、Badges、PostHistory 和 PostLinks。
用户可以下载预先准备好的 Parquet 数据版本(包含截至 2024 年 4 月的所有帖子),或者下载 XML 格式的最新数据并加载它。Stack Overflow 会定期更新此数据 - 历史上每 3 个月更新一次。
以下图表显示了 Parquet 格式的可用表的架构。
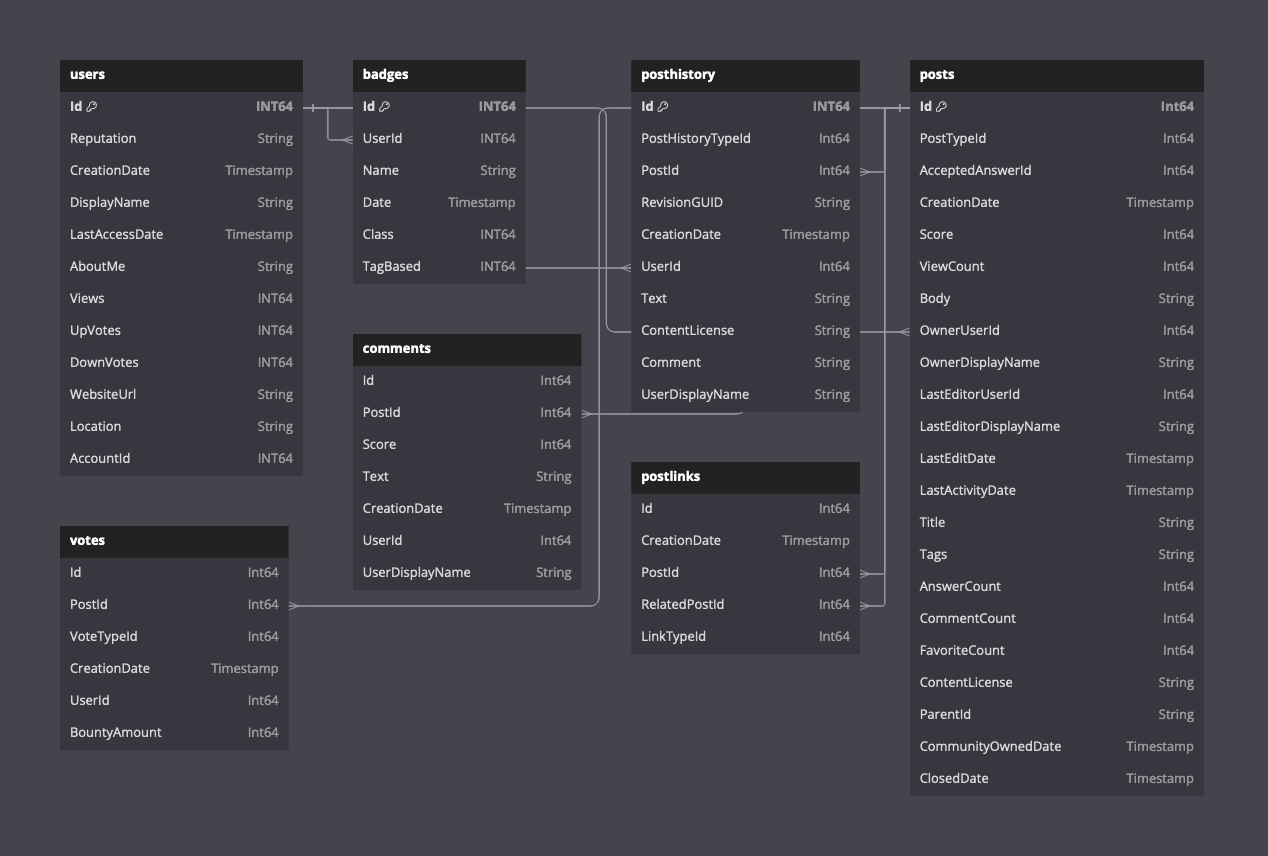
有关此数据架构的描述,请点击此处。
预先准备的数据
我们提供了 Parquet 格式的此数据副本,截至 2024 年 4 月是最新的。虽然对于 ClickHouse 来说,就行数而言很小(6000 万个帖子),但此数据集包含大量的文本和大型 String 列。
CREATE DATABASE stackoverflow
以下时间是针对位于 eu-west-2 的 96 GiB、24 vCPU ClickHouse Cloud 集群。数据集位于 eu-west-3。
帖子
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate)
INSERT INTO stackoverflow.posts SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 265.466 sec. Processed 59.82 million rows, 38.07 GB (225.34 thousand rows/s., 143.42 MB/s.)
帖子也按年份提供,例如 https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
投票
CREATE TABLE stackoverflow.votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId, UserId)
INSERT INTO stackoverflow.votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 21.605 sec. Processed 238.98 million rows, 2.13 GB (11.06 million rows/s., 98.46 MB/s.)
投票也按年份提供,例如 https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
评论
CREATE TABLE stackoverflow.comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY CreationDate
INSERT INTO stackoverflow.comments SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/comments/*.parquet')
0 rows in set. Elapsed: 56.593 sec. Processed 90.38 million rows, 11.14 GB (1.60 million rows/s., 196.78 MB/s.)
评论也按年份提供,例如 https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2020.parquet
用户
CREATE TABLE stackoverflow.users
(
`Id` Int32,
`Reputation` LowCardinality(String),
`CreationDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`DisplayName` String,
`LastAccessDate` DateTime64(3, 'UTC'),
`AboutMe` String,
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32,
`WebsiteUrl` String,
`Location` LowCardinality(String),
`AccountId` Int32
)
ENGINE = MergeTree
ORDER BY (Id, CreationDate)
INSERT INTO stackoverflow.users SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet')
0 rows in set. Elapsed: 10.988 sec. Processed 22.48 million rows, 1.36 GB (2.05 million rows/s., 124.10 MB/s.)
徽章
CREATE TABLE stackoverflow.badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
INSERT INTO stackoverflow.badges SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 6.635 sec. Processed 51.29 million rows, 797.05 MB (7.73 million rows/s., 120.13 MB/s.)
帖子链接
CREATE TABLE stackoverflow.postlinks
(
`Id` UInt64,
`CreationDate` DateTime64(3, 'UTC'),
`PostId` Int32,
`RelatedPostId` Int32,
`LinkTypeId` Enum8('Linked' = 1, 'Duplicate' = 3)
)
ENGINE = MergeTree
ORDER BY (PostId, RelatedPostId)
INSERT INTO stackoverflow.postlinks SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/postlinks.parquet')
0 rows in set. Elapsed: 1.534 sec. Processed 6.55 million rows, 129.70 MB (4.27 million rows/s., 84.57 MB/s.)
帖子历史记录
CREATE TABLE stackoverflow.posthistory
(
`Id` UInt64,
`PostHistoryTypeId` UInt8,
`PostId` Int32,
`RevisionGUID` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`Text` String,
`ContentLicense` LowCardinality(String),
`Comment` String,
`UserDisplayName` String
)
ENGINE = MergeTree
ORDER BY (CreationDate, PostId)
INSERT INTO stackoverflow.posthistory SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posthistory/*.parquet')
0 rows in set. Elapsed: 422.795 sec. Processed 160.79 million rows, 67.08 GB (380.30 thousand rows/s., 158.67 MB/s.)
原始数据集
原始数据集以压缩 (7zip) XML 格式在 https://archive.org/download/stackexchange 提供 - 文件前缀为 stackoverflow.com*。
下载
wget https://archive.org/download/stackexchange/stackoverflow.com-Badges.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Comments.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-PostHistory.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-PostLinks.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Posts.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Users.7z
wget https://archive.org/download/stackexchange/stackoverflow.com-Votes.7z
这些文件最大可达 35GB,下载可能需要大约 30 分钟,具体取决于互联网连接 - 下载服务器的速率限制约为 20MB/秒。
转换为 JSON
在撰写本文时,ClickHouse 不支持 XML 作为输入格式。要将数据加载到 ClickHouse 中,我们首先将其转换为 NDJSON。
要将 XML 转换为 JSON,我们推荐使用 xq Linux 工具,这是一个用于 XML 文档的简单 jq 包装器。
安装 xq 和 jq
sudo apt install jq
pip install yq
以下步骤适用于上述任何文件。我们以 stackoverflow.com-Posts.7z 文件为例。根据需要修改。
使用 p7zip 解压文件。这将生成一个 xml 文件 - 在本例中为 Posts.xml。
文件压缩率约为 4.5 倍。压缩后为 22GB,帖子文件需要大约 97G 解压缩空间。
p7zip -d stackoverflow.com-Posts.7z
以下命令将 xml 文件拆分为多个文件,每个文件包含 10000 行。
mkdir posts
cd posts
# the following splits the input xml file into sub files of 10000 rows
tail +3 ../Posts.xml | head -n -1 | split -l 10000 --filter='{ printf "<rows>\n"; cat - ; printf "</rows>\n"; } > $FILE' -
运行上述命令后,用户将拥有一组文件,每个文件包含 10000 行。这确保了下一个命令的内存开销不会过大(xml 到 JSON 的转换是在内存中完成的)。
find . -maxdepth 1 -type f -exec xq -c '.rows.row[]' {} \; | sed -e 's:"@:":g' > posts_v2.json
上述命令将生成一个 posts.json 文件。
使用以下命令加载到 ClickHouse 中。请注意,为 posts.json 文件指定了架构。这将需要根据数据类型进行调整,以与目标表对齐。
clickhouse local --query "SELECT * FROM file('posts.json', JSONEachRow, 'Id Int32, PostTypeId UInt8, AcceptedAnswerId UInt32, CreationDate DateTime64(3, \'UTC\'), Score Int32, ViewCount UInt32, Body String, OwnerUserId Int32, OwnerDisplayName String, LastEditorUserId Int32, LastEditorDisplayName String, LastEditDate DateTime64(3, \'UTC\'), LastActivityDate DateTime64(3, \'UTC\'), Title String, Tags String, AnswerCount UInt16, CommentCount UInt8, FavoriteCount UInt8, ContentLicense String, ParentId String, CommunityOwnedDate DateTime64(3, \'UTC\'), ClosedDate DateTime64(3, \'UTC\')') FORMAT Native" | clickhouse client --host <host> --secure --password <password> --query "INSERT INTO stackoverflow.posts_v2 FORMAT Native"
示例查询
几个简单的问题,帮助您入门。
Stack Overflow 上最受欢迎的标签
SELECT
arrayJoin(arrayFilter(t -> (t != ''), splitByChar('|', Tags))) AS Tags,
count() AS c
FROM stackoverflow.posts
GROUP BY Tags
ORDER BY c DESC
LIMIT 10
┌─Tags───────┬───────c─┐
│ javascript │ 2527130 │
│ python │ 2189638 │
│ java │ 1916156 │
│ c# │ 1614236 │
│ php │ 1463901 │
│ android │ 1416442 │
│ html │ 1186567 │
│ jquery │ 1034621 │
│ c++ │ 806202 │
│ css │ 803755 │
└────────────┴─────────┘
10 rows in set. Elapsed: 1.013 sec. Processed 59.82 million rows, 1.21 GB (59.07 million rows/s., 1.19 GB/s.)
Peak memory usage: 224.03 MiB.
回答最多(活跃账户)的用户
帐户需要 UserId。
SELECT
any(OwnerUserId) UserId,
OwnerDisplayName,
count() AS c
FROM stackoverflow.posts WHERE OwnerDisplayName != '' AND PostTypeId='Answer' AND OwnerUserId != 0
GROUP BY OwnerDisplayName
ORDER BY c DESC
LIMIT 5
┌─UserId─┬─OwnerDisplayName─┬────c─┐
│ 22656 │ Jon Skeet │ 2727 │
│ 23354 │ Marc Gravell │ 2150 │
│ 12950 │ tvanfosson │ 1530 │
│ 3043 │ Joel Coehoorn │ 1438 │
│ 10661 │ S.Lott │ 1087 │
└────────┴──────────────────┴──────┘
5 rows in set. Elapsed: 0.154 sec. Processed 35.83 million rows, 193.39 MB (232.33 million rows/s., 1.25 GB/s.)
Peak memory usage: 206.45 MiB.
浏览量最多的 ClickHouse 相关帖子
SELECT
Id,
Title,
ViewCount,
AnswerCount
FROM stackoverflow.posts
WHERE Title ILIKE '%ClickHouse%'
ORDER BY ViewCount DESC
LIMIT 10
┌───────Id─┬─Title────────────────────────────────────────────────────────────────────────────┬─ViewCount─┬─AnswerCount─┐
│ 52355143 │ Is it possible to delete old records from clickhouse table? │ 41462 │ 3 │
│ 37954203 │ Clickhouse Data Import │ 38735 │ 3 │
│ 37901642 │ Updating data in Clickhouse │ 36236 │ 6 │
│ 58422110 │ Pandas: How to insert dataframe into Clickhouse │ 29731 │ 4 │
│ 63621318 │ DBeaver - Clickhouse - SQL Error [159] .. Read timed out │ 27350 │ 1 │
│ 47591813 │ How to filter clickhouse table by array column contents? │ 27078 │ 2 │
│ 58728436 │ How to search the string in query with case insensitive on Clickhouse database? │ 26567 │ 3 │
│ 65316905 │ Clickhouse: DB::Exception: Memory limit (for query) exceeded │ 24899 │ 2 │
│ 49944865 │ How to add a column in clickhouse │ 24424 │ 1 │
│ 59712399 │ How to cast date Strings to DateTime format with extended parsing in ClickHouse? │ 22620 │ 1 │
└──────────┴──────────────────────────────────────────────────────────────────────────────────┴───────────┴─────────────┘
10 rows in set. Elapsed: 0.472 sec. Processed 59.82 million rows, 1.91 GB (126.63 million rows/s., 4.03 GB/s.)
Peak memory usage: 240.01 MiB.
最具争议的帖子
SELECT
Id,
Title,
UpVotes,
DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM stackoverflow.posts
INNER JOIN
(
SELECT
PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM stackoverflow.votes
GROUP BY PostId
HAVING (UpVotes > 10) AND (DownVotes > 10)
) AS votes ON posts.Id = votes.PostId
WHERE Title != ''
ORDER BY Controversial_ratio ASC
LIMIT 3
┌───────Id─┬─Title─────────────────────────────────────────────┬─UpVotes─┬─DownVotes─┬─Controversial_ratio─┐
│ 583177 │ VB.NET Infinite For Loop │ 12 │ 12 │ 0 │
│ 9756797 │ Read console input as enumerable - one statement? │ 16 │ 16 │ 0 │
│ 13329132 │ What's the point of ARGV in Ruby? │ 22 │ 22 │ 0 │
└──────────┴───────────────────────────────────────────────────┴─────────┴───────────┴─────────────────────┘
3 rows in set. Elapsed: 4.779 sec. Processed 298.80 million rows, 3.16 GB (62.52 million rows/s., 661.05 MB/s.)
Peak memory usage: 6.05 GiB.
致谢
感谢 Stack Overflow 根据 cc-by-sa 4.0 许可提供此数据,并感谢他们的努力和 https://archive.org/details/stackexchange 上的原始数据来源。