使用 GitHub 数据在 ClickHouse 中编写查询
此数据集包含 ClickHouse 存储库的所有提交和更改。它可以使用 ClickHouse 原生的 git-import 工具生成。
生成的数据为以下每个表提供一个 tsv 文件
commits- 带有统计信息的提交。file_changes- 每个提交中更改的文件,包含有关更改和统计信息。line_changes- 每个提交中每个更改文件中每一行更改的行,包含有关该行的完整信息以及有关该行先前更改的信息。
截至 2022 年 11 月 8 日,每个 TSV 的大小和行数大致如下
commits- 7.8M - 266,051 行file_changes- 53M - 266,051 行line_changes- 2.7G - 7,535,157 行
生成数据
这是可选的。我们免费分发数据 - 请参阅下载和插入数据。
git clone [email protected]:ClickHouse/ClickHouse.git
cd ClickHouse
clickhouse git-import --skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' --skip-commits-with-messages '^Merge branch '
对于 ClickHouse 存储库,这大约需要 3 分钟才能完成(截至 2022 年 11 月 8 日在 MacBook Pro 2021 上)。
可以从工具的本机帮助中获得可用选项的完整列表。
clickhouse git-import -h
此帮助还为上述每个表提供了 DDL,例如
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
这些查询应该在任何存储库上工作。欢迎探索并报告您的发现 关于执行时间的一些指南(截至 2022 年 11 月)
- Linux -
~/clickhouse git-import- 160 分钟
下载和插入数据
以下数据可用于重现工作环境。或者,此数据集可在 play.clickhouse.com 中找到 - 有关更多详细信息,请参阅查询。
以下存储库的生成文件可以在下面找到
- ClickHouse(2022 年 11 月 8 日)
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz - 2.5 MB
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz - 4.5MB
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz - 127.4 MB
- Linux(2022 年 11 月 8 日)
要插入此数据,请通过执行以下查询来准备数据库
DROP DATABASE IF EXISTS git;
CREATE DATABASE git;
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.file_changes
(
change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.line_changes
(
sign Int8,
line_number_old UInt32,
line_number_new UInt32,
hunk_num UInt32,
hunk_start_line_number_old UInt32,
hunk_start_line_number_new UInt32,
hunk_lines_added UInt32,
hunk_lines_deleted UInt32,
hunk_context LowCardinality(String),
line LowCardinality(String),
indent UInt8,
line_type Enum('Empty' = 0, 'Comment' = 1, 'Punct' = 2, 'Code' = 3),
prev_commit_hash String,
prev_author LowCardinality(String),
prev_time DateTime,
file_change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
file_lines_added UInt32,
file_lines_deleted UInt32,
file_hunks_added UInt32,
file_hunks_removed UInt32,
file_hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
使用 INSERT INTO SELECT 和s3 函数插入数据。例如,在下面,我们将 ClickHouse 文件插入到各自的表中
commits
INSERT INTO git.commits SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz', 'TSV', 'hash String,author LowCardinality(String), time DateTime, message String, files_added UInt32, files_deleted UInt32, files_renamed UInt32, files_modified UInt32, lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32')
0 rows in set. Elapsed: 1.826 sec. Processed 62.78 thousand rows, 8.50 MB (34.39 thousand rows/s., 4.66 MB/s.)
file_changes
INSERT INTO git.file_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz', 'TSV', 'change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6), path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32, commit_hash String, author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 2.688 sec. Processed 266.05 thousand rows, 48.30 MB (98.97 thousand rows/s., 17.97 MB/s.)
line_changes
INSERT INTO git.line_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz', 'TSV', ' sign Int8, line_number_old UInt32, line_number_new UInt32, hunk_num UInt32, hunk_start_line_number_old UInt32, hunk_start_line_number_new UInt32, hunk_lines_added UInt32,\n hunk_lines_deleted UInt32, hunk_context LowCardinality(String), line LowCardinality(String), indent UInt8, line_type Enum(\'Empty\' = 0, \'Comment\' = 1, \'Punct\' = 2, \'Code\' = 3), prev_commit_hash String, prev_author LowCardinality(String), prev_time DateTime, file_change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6),\n path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), file_lines_added UInt32, file_lines_deleted UInt32, file_hunks_added UInt32, file_hunks_removed UInt32, file_hunks_changed UInt32, commit_hash String,\n author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 50.535 sec. Processed 7.54 million rows, 2.09 GB (149.11 thousand rows/s., 41.40 MB/s.)
查询
该工具通过其帮助输出建议了几个查询。除了其他一些感兴趣的补充问题外,我们还回答了这些问题。这些查询的复杂性大约是递增的,而不是工具的任意顺序。
此数据集可在 play.clickhouse.com 的 git_clickhouse 数据库中找到。我们为所有查询提供了指向此环境的链接,并根据需要调整数据库名称。请注意,由于数据收集时间的不同,play 结果可能与此处显示的结果有所不同。
单个文件的历史记录
最简单的查询。在这里,我们查看 StorageReplicatedMergeTree.cpp 的所有提交消息。由于这些可能更有趣,我们首先按最新的消息排序。
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
old_path,
lines_added,
lines_deleted,
commit_message
FROM git.file_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY time DESC
LIMIT 10
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path────────────────────────────────────────┬─old_path─┬─lines_added─┬─lines_deleted─┬─commit_message───────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 13 │ 10 │ fix accessing part in Deleting state │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 30 │ better semantic of constsness of DataPartStorage │
│ 2022-10-23 01:23:15 │ 56e5daba0c9 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 44 │ remove DataPartStorageBuilder │
│ 2022-10-21 13:35:37 │ 851f556d65a │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Remove unused parameter │
│ 2022-10-21 13:02:52 │ 13d31eefbc3 │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 4 │ Replicated merge tree polishing │
│ 2022-10-21 12:25:19 │ 4e76629aafc │ Modify │ Azat Khuzhin │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Fixes for -Wshorten-64-to-32 │
│ 2022-10-19 13:59:28 │ 05e6b94b541 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 0 │ Polishing │
│ 2022-10-19 13:34:20 │ e5408aac991 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 53 │ Simplify logic │
│ 2022-10-18 15:36:11 │ 7befe2825c9 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 2 │ 2 │ Update StorageReplicatedMergeTree.cpp │
│ 2022-10-18 15:35:44 │ 0623ad4e374 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 1 │ 1 │ Update StorageReplicatedMergeTree.cpp │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴─────────────────────────────────────────────┴──────────┴─────────────┴───────────────┴──────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.006 sec. Processed 12.10 thousand rows, 1.60 MB (1.93 million rows/s., 255.40 MB/s.)
我们还可以查看行更改,排除重命名,即,当文件以不同的名称存在时,我们将不显示重命名事件之前的更改
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
sign,
line_number_old,
line_number_new,
author,
line
FROM git.line_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY line_number_new ASC
LIMIT 10
┌────────────────time─┬─commit──────┬─sign─┬─line_number_old─┬─line_number_new─┬─author───────────┬─line──────────────────────────────────────────────────┐
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ -1 │ 1 │ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 1 │ Alexey Milovidov │ #include <Core/Defines.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 2 │ Alexey Milovidov │ │
│ 2021-05-03 23:46:51 │ 02ce9cc7254 │ -1 │ 3 │ 2 │ Alexey Milovidov │ #include <Common/FieldVisitors.h> │
│ 2021-05-27 22:21:02 │ e2f29b9df02 │ -1 │ 3 │ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 2022-10-03 22:30:50 │ 210882b9c4d │ 1 │ 2 │ 3 │ alesapin │ #include <ranges> │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ 1 │ 2 │ 3 │ Anton Popov │ #include <cstddef> │
│ 2021-06-20 09:24:43 │ 4c391f8e994 │ 1 │ 2 │ 3 │ Mike Kot │ #include "Common/hex.h" │
│ 2021-12-29 09:18:56 │ 8112a712336 │ -1 │ 6 │ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 2022-04-21 20:19:13 │ 9133e398b8c │ 1 │ 11 │ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
└─────────────────────┴─────────────┴──────┴─────────────────┴─────────────────┴──────────────────┴───────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.258 sec. Processed 7.54 million rows, 654.92 MB (29.24 million rows/s., 2.54 GB/s.)
请注意,存在此查询的更复杂变体,我们可以在其中找到文件的逐行提交历史记录,并考虑重命名。
查找当前活动的 files
这对于稍后的分析很重要,因为我们只想考虑存储库中的当前文件。我们将此集合估计为尚未重命名或删除(然后重新添加/重新命名)的文件。
请注意,在重命名期间,与 dbms、libs、tests/testflows/ 目录下的文件相关的提交历史记录似乎已损坏。因此,我们也将这些排除在外。
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
LIMIT 10
┌─path────────────────────────────────────────────────────────────┐
│ tests/queries/0_stateless/01054_random_printable_ascii_ubsan.sh │
│ tests/queries/0_stateless/02247_read_bools_as_numbers_json.sh │
│ tests/performance/file_table_function.xml │
│ tests/queries/0_stateless/01902_self_aliases_in_columns.sql │
│ tests/queries/0_stateless/01070_h3_get_base_cell.reference │
│ src/Functions/ztest.cpp │
│ src/Interpreters/InterpreterShowTablesQuery.h │
│ src/Parsers/Kusto/ParserKQLStatement.h │
│ tests/queries/0_stateless/00938_dataset_test.sql │
│ src/Dictionaries/Embedded/GeodataProviders/Types.h │
└─────────────────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.085 sec. Processed 532.10 thousand rows, 8.68 MB (6.30 million rows/s., 102.64 MB/s.)
请注意,这允许文件被重命名,然后重新重命名为其原始值。首先,我们聚合 old_path 以获取由于重命名而删除的文件列表。我们将此与每个 path 的最后操作联合起来。最后,我们将此列表过滤为最终事件不是 Delete 的列表。
SELECT uniq(path)
FROM
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
)
┌─uniq(path)─┐
│ 18559 │
└────────────┘
1 row in set. Elapsed: 0.089 sec. Processed 532.10 thousand rows, 8.68 MB (6.01 million rows/s., 97.99 MB/s.)
请注意,我们在导入期间跳过了几个目录的导入,即
--skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/'
将此模式应用于 git list-files,报告 18155。
git ls-files | grep -v -E 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' | wc -l
18155
因此,我们当前的解决方案是对当前文件的估计
此处的差异是由以下几个因素引起的
- 重命名可以与文件的其他修改同时发生。这些在 file_changes 中列为单独的事件,但时间相同。
argMax函数无法区分这些 - 它选择第一个值。插入的自然顺序(知道正确顺序的唯一方法)在联合中未维护,因此可以选择修改后的事件。例如,在下面,src/Functions/geometryFromColumn.h文件在重命名为src/Functions/geometryConverters.h之前进行了多次修改。我们当前的解决方案可能会选择一个 Modify 事件作为最新更改,从而导致保留src/Functions/geometryFromColumn.h。
SELECT
change_type,
path,
old_path,
time,
commit_hash
FROM git.file_changes
WHERE (path = 'src/Functions/geometryFromColumn.h') OR (old_path = 'src/Functions/geometryFromColumn.h')
┌─change_type─┬─path───────────────────────────────┬─old_path───────────────────────────┬────────────────time─┬─commit_hash──────────────────────────────┐
│ Add │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 9376b676e9a9bb8911b872e1887da85a45f7479d │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 6d59be5ea4768034f6526f7f9813062e0c369f7b │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 33acc2aa5dc091a7cb948f78c558529789b2bad8 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 78e0db268ceadc42f82bc63a77ee1a4da6002463 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 14a891057d292a164c4179bfddaef45a74eaf83a │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ d0d6e6953c2a2af9fb2300921ff96b9362f22edb │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ fe8382521139a58c0ba277eb848e88894658db66 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 3be3d5cde8788165bc0558f1e2a22568311c3103 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ afad9bf4d0a55ed52a3f55483bc0973456e10a56 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ e3290ecc78ca3ea82b49ebcda22b5d3a4df154e6 │
│ Rename │ src/Functions/geometryConverters.h │ src/Functions/geometryFromColumn.h │ 2021-03-11 12:08:16 │ 125945769586baf6ffd15919b29565b1b2a63218 │
└─────────────┴────────────────────────────────────┴────────────────────────────────────┴─────────────────────┴──────────────────────────────────────────┘
11 rows in set. Elapsed: 0.030 sec. Processed 266.05 thousand rows, 6.61 MB (8.89 million rows/s., 220.82 MB/s.)
- 提交历史记录损坏 - 缺少删除事件。来源和原因待定。
这些差异不应有意义地影响我们的分析。我们欢迎此查询的改进版本。
列出修改次数最多的文件
限制为当前文件,我们认为修改次数是删除和添加的总和。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) + sum(lines_deleted) AS modifications
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY modifications DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─modifications─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────────────┘
10 rows in set. Elapsed: 0.134 sec. Processed 798.15 thousand rows, 16.46 MB (5.95 million rows/s., 122.62 MB/s.)
提交通常发生在星期几?
SELECT
day_of_week,
count() AS c
FROM git.commits
GROUP BY dayOfWeek(time) AS day_of_week
┌─day_of_week─┬─────c─┐
│ 1 │ 10575 │
│ 2 │ 10645 │
│ 3 │ 10748 │
│ 4 │ 10944 │
│ 5 │ 10090 │
│ 6 │ 4617 │
│ 7 │ 5166 │
└─────────────┴───────┘
7 rows in set. Elapsed: 0.262 sec. Processed 62.78 thousand rows, 251.14 KB (239.73 thousand rows/s., 958.93 KB/s.)
这在某种程度上是有道理的,星期五的生产力有所下降。很高兴看到人们在周末提交代码!非常感谢我们的贡献者!
子目录/文件的历史记录 - 随时间变化的行数、提交次数和贡献者人数
这将产生大量的查询结果,如果不进行过滤,则不切实际地显示或可视化。因此,我们在以下示例中允许过滤文件或子目录。在这里,我们使用 toStartOfWeek 函数按周分组 - 根据需要进行调整。
SELECT
week,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted,
uniq(commit_hash) AS num_commits,
uniq(author) AS authors
FROM git.file_changes
WHERE path LIKE 'src/Storages%'
GROUP BY toStartOfWeek(time) AS week
ORDER BY week ASC
LIMIT 10
┌───────week─┬─lines_added─┬─lines_deleted─┬─num_commits─┬─authors─┐
│ 2020-03-29 │ 49 │ 35 │ 4 │ 3 │
│ 2020-04-05 │ 940 │ 601 │ 55 │ 14 │
│ 2020-04-12 │ 1472 │ 607 │ 32 │ 11 │
│ 2020-04-19 │ 917 │ 841 │ 39 │ 12 │
│ 2020-04-26 │ 1067 │ 626 │ 36 │ 10 │
│ 2020-05-03 │ 514 │ 435 │ 27 │ 10 │
│ 2020-05-10 │ 2552 │ 537 │ 48 │ 12 │
│ 2020-05-17 │ 3585 │ 1913 │ 83 │ 9 │
│ 2020-05-24 │ 2851 │ 1812 │ 74 │ 18 │
│ 2020-05-31 │ 2771 │ 2077 │ 77 │ 16 │
└────────────┴─────────────┴───────────────┴─────────────┴─────────┘
10 rows in set. Elapsed: 0.043 sec. Processed 266.05 thousand rows, 15.85 MB (6.12 million rows/s., 364.61 MB/s.)
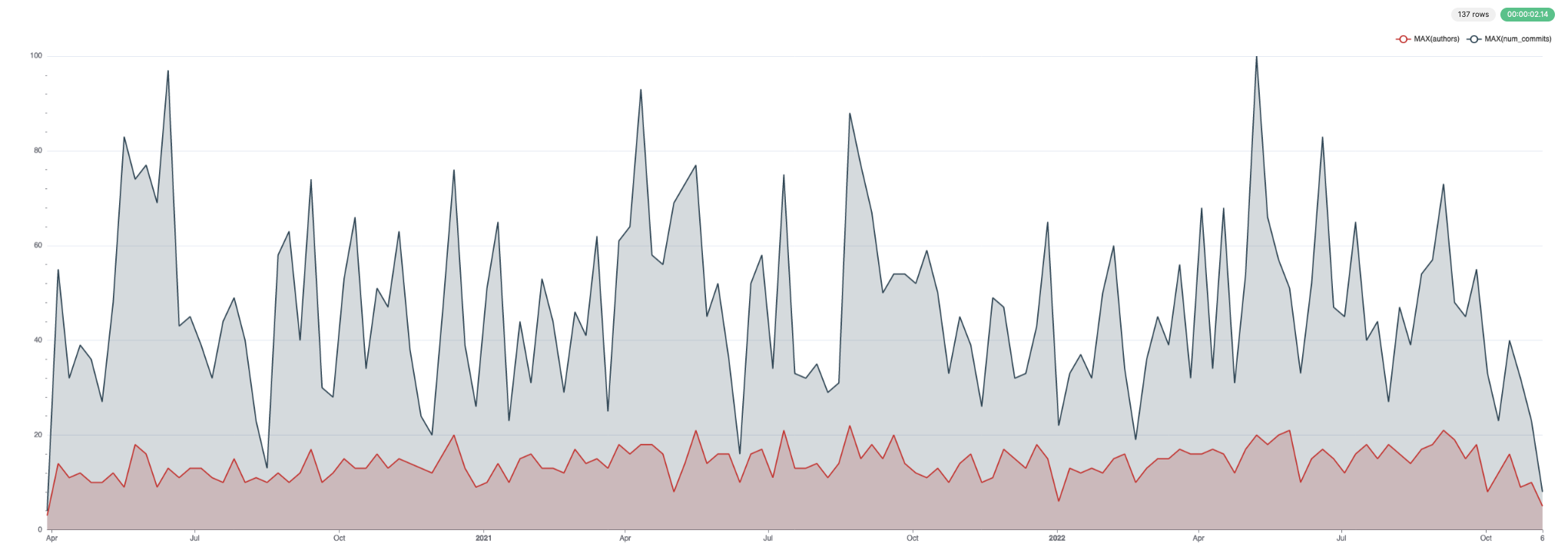
此数据可视化效果很好。下面我们使用 Superset。
对于添加和删除的行
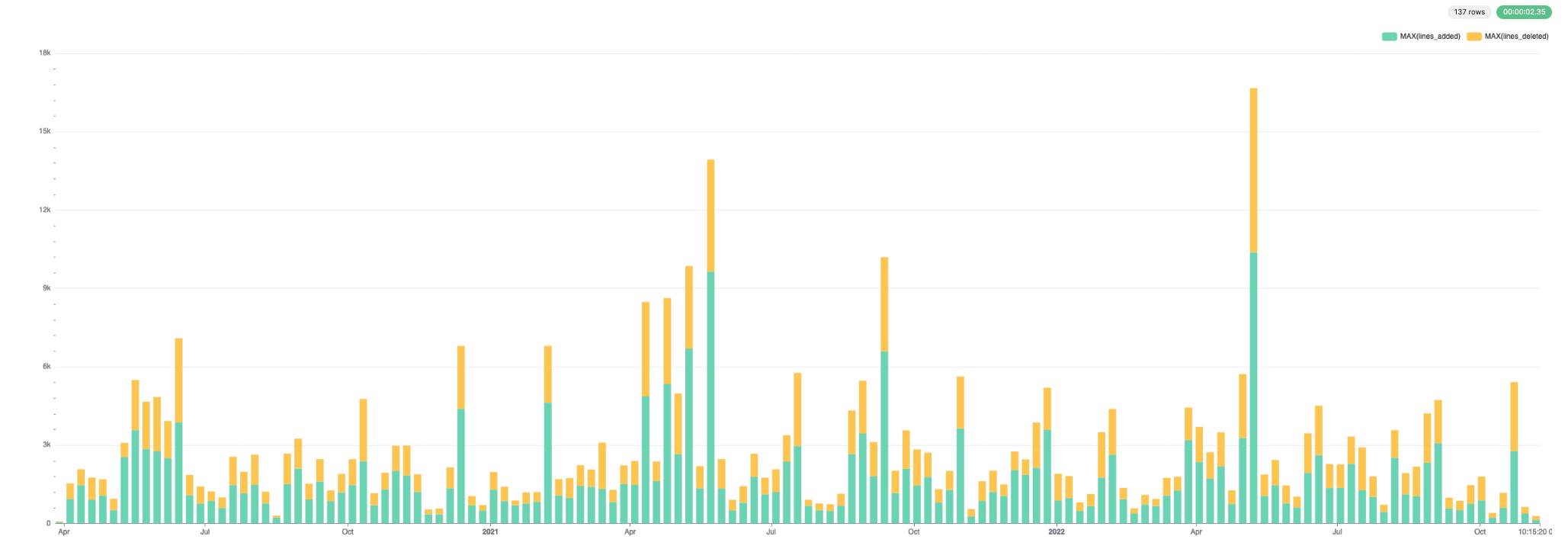
对于提交和作者
列出作者数量最多的文件
仅限当前文件。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
uniq(author) AS num_authors
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY num_authors DESC
LIMIT 10
┌─path────────────────────────────────────────┬─num_authors─┐
│ src/Core/Settings.h │ 127 │
│ CMakeLists.txt │ 96 │
│ .gitmodules │ 85 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 72 │
│ src/CMakeLists.txt │ 71 │
│ programs/server/Server.cpp │ 70 │
│ src/Interpreters/Context.cpp │ 64 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 63 │
│ src/Common/ErrorCodes.cpp │ 61 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 59 │
└─────────────────────────────────────────────┴─────────────┘
10 rows in set. Elapsed: 0.239 sec. Processed 798.15 thousand rows, 14.13 MB (3.35 million rows/s., 59.22 MB/s.)
存储库中最旧的代码行
仅限于当前文件。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
any(path) AS file_path,
line,
max(time) AS latest_change,
any(file_change_type)
FROM git.line_changes
WHERE path IN (current_files)
GROUP BY line
ORDER BY latest_change ASC
LIMIT 10
┌─file_path───────────────────────────────────┬─line────────────────────────────────────────────────────────┬───────latest_change─┬─any(file_change_type)─┐
│ utils/compressor/test.sh │ ./compressor -d < compressor.snp > compressor2 │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.snp │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor -d < compressor.qlz > compressor2 │ 2014-02-24 03:14:30 │ Add │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.qlz │ 2014-02-24 03:14:30 │ Add │
│ utils/config-processor/config-processor.cpp │ if (argc != 2) │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "std::exception: " << e.what() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Exception: " << e.displayText() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ Poco::XML::DOMWriter().writeNode(std::cout, document); │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Some exception" << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "usage: " << argv[0] << " path" << std::endl; │ 2014-02-26 19:10:00 │ Add │
└─────────────────────────────────────────────┴─────────────────────────────────────────────────────────────┴─────────────────────┴───────────────────────┘
10 rows in set. Elapsed: 1.101 sec. Processed 8.07 million rows, 905.86 MB (7.33 million rows/s., 823.13 MB/s.)
历史记录最长的文件
仅限于当前文件。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
count() AS c,
path,
max(time) AS latest_change
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌───c─┬─path────────────────────────────────────────┬───────latest_change─┐
│ 790 │ src/Storages/StorageReplicatedMergeTree.cpp │ 2022-10-30 16:30:51 │
│ 788 │ src/Storages/MergeTree/MergeTreeData.cpp │ 2022-11-04 09:26:44 │
│ 752 │ src/Core/Settings.h │ 2022-10-25 11:35:25 │
│ 749 │ CMakeLists.txt │ 2022-10-05 21:00:49 │
│ 575 │ src/Interpreters/InterpreterSelectQuery.cpp │ 2022-11-01 10:20:10 │
│ 563 │ CHANGELOG.md │ 2022-10-27 08:19:50 │
│ 491 │ src/Interpreters/Context.cpp │ 2022-10-25 12:26:29 │
│ 437 │ programs/server/Server.cpp │ 2022-10-21 12:25:19 │
│ 375 │ programs/client/Client.cpp │ 2022-11-03 03:16:55 │
│ 350 │ src/CMakeLists.txt │ 2022-10-24 09:22:37 │
└─────┴─────────────────────────────────────────────┴─────────────────────┘
10 rows in set. Elapsed: 0.124 sec. Processed 798.15 thousand rows, 14.71 MB (6.44 million rows/s., 118.61 MB/s.)
我们的核心数据结构 Merge Tree 显然在不断发展,具有悠久的编辑历史!
贡献者在文档和代码方面的分布(按月份)
在数据捕获期间,由于提交历史记录非常脏乱,因此已过滤掉 docs/ 文件夹中的更改。因此,此查询的结果不准确。
我们在每月的某些时候(例如,在发布日期前后)编写更多文档吗?我们可以使用 countIf 函数来计算一个简单的比率,并使用 bar 函数可视化结果。
SELECT
day,
bar(docs_ratio * 1000, 0, 100, 100) AS bar
FROM
(
SELECT
day,
countIf(file_extension IN ('h', 'cpp', 'sql')) AS code,
countIf(file_extension = 'md') AS docs,
docs / (code + docs) AS docs_ratio
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp', 'sql', 'md'))
GROUP BY dayOfMonth(time) AS day
)
┌─day─┬─bar─────────────────────────────────────────────────────────────┐
│ 1 │ ███████████████████████████████████▍ │
│ 2 │ ███████████████████████▋ │
│ 3 │ ████████████████████████████████▋ │
│ 4 │ █████████████ │
│ 5 │ █████████████████████▎ │
│ 6 │ ████████ │
│ 7 │ ███▋ │
│ 8 │ ████████▌ │
│ 9 │ ██████████████▎ │
│ 10 │ █████████████████▏ │
│ 11 │ █████████████▎ │
│ 12 │ ███████████████████████████████████▋ │
│ 13 │ █████████████████████████████▎ │
│ 14 │ ██████▋ │
│ 15 │ █████████████████████████████████████████▊ │
│ 16 │ ██████████▎ │
│ 17 │ ██████████████████████████████████████▋ │
│ 18 │ █████████████████████████████████▌ │
│ 19 │ ███████████ │
│ 20 │ █████████████████████████████████▊ │
│ 21 │ █████ │
│ 22 │ ███████████████████████▋ │
│ 23 │ ███████████████████████████▌ │
│ 24 │ ███████▌ │
│ 25 │ ██████████████████████████████████▎ │
│ 26 │ ███████████▏ │
│ 27 │ ███████████████████████████████████████████████████████████████ │
│ 28 │ ████████████████████████████████████████████████████▏ │
│ 29 │ ███▌ │
│ 30 │ ████████████████████████████████████████▎ │
│ 31 │ █████████████████████████████████▏ │
└─────┴─────────────────────────────────────────────────────────────────┘
31 rows in set. Elapsed: 0.043 sec. Processed 7.54 million rows, 40.53 MB (176.71 million rows/s., 950.40 MB/s.)
可能在月底附近稍微多一点,但总的来说,我们保持良好的均匀分布。同样,由于在数据插入期间过滤了文档过滤器,因此这是不可靠的。
影响最多样化的作者
我们在此处认为多样性是指作者贡献的唯一文件数。
SELECT
author,
uniq(path) AS num_files
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author─────────────┬─num_files─┐
│ Alexey Milovidov │ 8433 │
│ Nikolai Kochetov │ 3257 │
│ Vitaly Baranov │ 2316 │
│ Maksim Kita │ 2172 │
│ Azat Khuzhin │ 1988 │
│ alesapin │ 1818 │
│ Alexander Tokmakov │ 1751 │
│ Amos Bird │ 1641 │
│ Ivan │ 1629 │
│ alexey-milovidov │ 1581 │
└────────────────────┴───────────┘
10 rows in set. Elapsed: 0.041 sec. Processed 266.05 thousand rows, 4.92 MB (6.56 million rows/s., 121.21 MB/s.)
让我们看看谁在最近的工作中拥有最多样化的提交。与其按日期限制,不如限制为作者的最后 N 次提交(在本例中,我们使用了 3,但可以随意修改)
SELECT
author,
sum(num_files_commit) AS num_files
FROM
(
SELECT
author,
commit_hash,
uniq(path) AS num_files_commit,
max(time) AS commit_time
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
author,
commit_hash
ORDER BY
author ASC,
commit_time DESC
LIMIT 3 BY author
)
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author───────────────┬─num_files─┐
│ Mikhail │ 782 │
│ Li Yin │ 553 │
│ Roman Peshkurov │ 119 │
│ Vladimir Smirnov │ 88 │
│ f1yegor │ 65 │
│ maiha │ 54 │
│ Vitaliy Lyudvichenko │ 53 │
│ Pradeep Chhetri │ 40 │
│ Orivej Desh │ 38 │
│ liyang │ 36 │
└──────────────────────┴───────────┘
10 rows in set. Elapsed: 0.106 sec. Processed 266.05 thousand rows, 21.04 MB (2.52 million rows/s., 198.93 MB/s.)
作者最喜欢的文件
在这里,我们选择了我们的创始人 Alexey Milovidov,并将我们的分析限制为当前文件。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path────────────────────────────────────────┬───c─┐
│ CMakeLists.txt │ 165 │
│ CHANGELOG.md │ 126 │
│ programs/server/Server.cpp │ 73 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 71 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 68 │
│ src/Core/Settings.h │ 65 │
│ programs/client/Client.cpp │ 57 │
│ programs/server/play.html │ 48 │
│ .gitmodules │ 47 │
│ programs/install/Install.cpp │ 37 │
└─────────────────────────────────────────────┴─────┘
10 rows in set. Elapsed: 0.106 sec. Processed 798.15 thousand rows, 13.97 MB (7.51 million rows/s., 131.41 MB/s.)
这是有道理的,因为 Alexey 一直负责维护变更日志。但是,如果我们使用文件的基本名称来识别他流行的文件会怎样 - 这允许重命名,并且应该关注代码贡献。
SELECT
base,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY basename(path) AS base
ORDER BY c DESC
LIMIT 10
┌─base───────────────────────────┬───c─┐
│ StorageReplicatedMergeTree.cpp │ 393 │
│ InterpreterSelectQuery.cpp │ 299 │
│ Aggregator.cpp │ 297 │
│ Client.cpp │ 280 │
│ MergeTreeData.cpp │ 274 │
│ Server.cpp │ 264 │
│ ExpressionAnalyzer.cpp │ 259 │
│ StorageMergeTree.cpp │ 239 │
│ Settings.h │ 225 │
│ TCPHandler.cpp │ 205 │
└────────────────────────────────┴─────┘
10 rows in set. Elapsed: 0.032 sec. Processed 266.05 thousand rows, 5.68 MB (8.22 million rows/s., 175.50 MB/s.)
这可能更能反映他感兴趣的领域。
作者数量最少的大型文件
为此,我们首先需要识别最大的文件。对于每个文件,从提交历史记录中估算完整的文档重建将非常昂贵!
为了估计,假设我们限制为当前文件,我们对添加的行求和并减去删除的行。然后,我们可以计算长度与作者数量的比率。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Common/ClassificationDictionaries/emotional_dictionary_rus.txt │ 148590 │ 1 │ 148590 │
│ src/Functions/ClassificationDictionaries/emotional_dictionary_rus.txt │ 55533 │ 1 │ 55533 │
│ src/Functions/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ src/Common/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ tests/integration/test_storage_meilisearch/movies.json │ 19549 │ 1 │ 19549 │
│ tests/queries/0_stateless/02364_multiSearch_function_family.reference │ 12874 │ 1 │ 12874 │
│ src/Functions/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ src/Common/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ tests/performance/explain_ast.xml │ 5911 │ 1 │ 5911 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
└───────────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.138 sec. Processed 798.15 thousand rows, 16.57 MB (5.79 million rows/s., 120.11 MB/s.)
文本字典可能不现实,因此让我们通过文件扩展名过滤器仅限于代码!
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
│ src/Analyzer/QueryTreeBuilder.cpp │ 880 │ 1 │ 880 │
│ src/Planner/Planner.cpp │ 873 │ 1 │ 873 │
│ src/Backups/RestorerFromBackup.cpp │ 869 │ 1 │ 869 │
│ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ src/Planner/PlannerActionsVisitor.cpp │ 765 │ 1 │ 765 │
│ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ src/Planner/PlannerJoinTree.cpp │ 708 │ 1 │ 708 │
│ src/Planner/PlannerJoins.cpp │ 695 │ 1 │ 695 │
│ src/Analyzer/QueryNode.h │ 607 │ 1 │ 607 │
└───────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.140 sec. Processed 798.15 thousand rows, 16.84 MB (5.70 million rows/s., 120.32 MB/s.)
这存在一些近因偏差 - 较新的文件提交的机会较少。如果我们将文件限制为至少 1 年的文件呢?
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
min(time) AS min_date,
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
HAVING min_date <= (now() - toIntervalYear(1))
ORDER BY lines_author_ratio DESC
LIMIT 10
┌────────────min_date─┬─path───────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ 2021-03-08 07:00:54 │ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ 2021-05-04 13:47:34 │ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ 2021-03-14 16:52:51 │ utils/memcpy-bench/glibc/dwarf2.h │ 592 │ 1 │ 592 │
│ 2021-03-08 09:04:52 │ utils/memcpy-bench/FastMemcpy_Avx.h │ 496 │ 1 │ 496 │
│ 2020-10-19 01:10:50 │ tests/queries/0_stateless/01518_nullable_aggregate_states2.sql │ 411 │ 1 │ 411 │
│ 2020-11-24 14:53:34 │ programs/server/GRPCHandler.cpp │ 399 │ 1 │ 399 │
│ 2021-03-09 14:10:28 │ src/DataTypes/Serializations/SerializationSparse.cpp │ 363 │ 1 │ 363 │
│ 2021-08-20 15:06:57 │ src/Functions/vectorFunctions.cpp │ 1327 │ 4 │ 331.75 │
│ 2020-08-04 03:26:23 │ src/Interpreters/MySQL/CreateQueryConvertVisitor.cpp │ 311 │ 1 │ 311 │
│ 2020-11-06 15:45:13 │ src/Storages/Rocksdb/StorageEmbeddedRocksdb.cpp │ 611 │ 2 │ 305.5 │
└─────────────────────┴────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.143 sec. Processed 798.15 thousand rows, 18.00 MB (5.58 million rows/s., 125.87 MB/s.)
按时间、星期几、作者、特定子目录的代码提交和行数分布
我们将其解释为星期几添加和删除的行数。在这种情况下,我们专注于 Functions 目录
SELECT
dayOfWeek,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toDayOfWeek(time) AS dayOfWeek
┌─dayOfWeek─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 1 │ 476 │ 24619 │ 15782 │
│ 2 │ 434 │ 18098 │ 9938 │
│ 3 │ 496 │ 26562 │ 20883 │
│ 4 │ 587 │ 65674 │ 18862 │
│ 5 │ 504 │ 85917 │ 14518 │
│ 6 │ 314 │ 13604 │ 10144 │
│ 7 │ 294 │ 11938 │ 6451 │
└───────────┴─────────┴─────────────┴───────────────┘
7 rows in set. Elapsed: 0.034 sec. Processed 266.05 thousand rows, 14.66 MB (7.73 million rows/s., 425.56 MB/s.)
以及一天中的时间,
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
┌─hourOfDay─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 0 │ 71 │ 4169 │ 3404 │
│ 1 │ 90 │ 2174 │ 1927 │
│ 2 │ 65 │ 2343 │ 1515 │
│ 3 │ 76 │ 2552 │ 493 │
│ 4 │ 62 │ 1480 │ 1304 │
│ 5 │ 38 │ 1644 │ 253 │
│ 6 │ 104 │ 4434 │ 2979 │
│ 7 │ 117 │ 4171 │ 1678 │
│ 8 │ 106 │ 4604 │ 4673 │
│ 9 │ 135 │ 60550 │ 2678 │
│ 10 │ 149 │ 6133 │ 3482 │
│ 11 │ 182 │ 8040 │ 3833 │
│ 12 │ 209 │ 29428 │ 15040 │
│ 13 │ 187 │ 10204 │ 5491 │
│ 14 │ 204 │ 9028 │ 6060 │
│ 15 │ 231 │ 15179 │ 10077 │
│ 16 │ 196 │ 9568 │ 5925 │
│ 17 │ 138 │ 4941 │ 3849 │
│ 18 │ 123 │ 4193 │ 3036 │
│ 19 │ 165 │ 8817 │ 6646 │
│ 20 │ 140 │ 3749 │ 2379 │
│ 21 │ 132 │ 41585 │ 4182 │
│ 22 │ 85 │ 4094 │ 3955 │
│ 23 │ 100 │ 3332 │ 1719 │
└───────────┴─────────┴─────────────┴───────────────┘
24 rows in set. Elapsed: 0.039 sec. Processed 266.05 thousand rows, 14.66 MB (6.77 million rows/s., 372.89 MB/s.)
考虑到我们的大部分开发团队都在阿姆斯特丹,这种分布是有道理的。bar 函数帮助我们可视化这些分布
SELECT
hourOfDay,
bar(commits, 0, 400, 50) AS commits,
bar(lines_added, 0, 30000, 50) AS lines_added,
bar(lines_deleted, 0, 15000, 50) AS lines_deleted
FROM
(
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
)
┌─hourOfDay─┬─commits───────────────────────┬─lines_added────────────────────────────────────────┬─lines_deleted──────────────────────────────────────┐
│ 0 │ ████████▊ │ ██████▊ │ ███████████▎ │
│ 1 │ ███████████▎ │ ███▌ │ ██████▍ │
│ 2 │ ████████ │ ███▊ │ █████ │
│ 3 │ █████████▌ │ ████▎ │ █▋ │
│ 4 │ ███████▋ │ ██▍ │ ████▎ │
│ 5 │ ████▋ │ ██▋ │ ▋ │
│ 6 │ █████████████ │ ███████▍ │ █████████▊ │
│ 7 │ ██████████████▋ │ ██████▊ │ █████▌ │
│ 8 │ █████████████▎ │ ███████▋ │ ███████████████▌ │
│ 9 │ ████████████████▊ │ ██████████████████████████████████████████████████ │ ████████▊ │
│ 10 │ ██████████████████▋ │ ██████████▏ │ ███████████▌ │
│ 11 │ ██████████████████████▋ │ █████████████▍ │ ████████████▋ │
│ 12 │ ██████████████████████████ │ █████████████████████████████████████████████████ │ ██████████████████████████████████████████████████ │
│ 13 │ ███████████████████████▍ │ █████████████████ │ ██████████████████▎ │
│ 14 │ █████████████████████████▌ │ ███████████████ │ ████████████████████▏ │
│ 15 │ ████████████████████████████▊ │ █████████████████████████▎ │ █████████████████████████████████▌ │
│ 16 │ ████████████████████████▌ │ ███████████████▊ │ ███████████████████▋ │
│ 17 │ █████████████████▎ │ ████████▏ │ ████████████▋ │
│ 18 │ ███████████████▍ │ ██████▊ │ ██████████ │
│ 19 │ ████████████████████▋ │ ██████████████▋ │ ██████████████████████▏ │
│ 20 │ █████████████████▌ │ ██████▏ │ ███████▊ │
│ 21 │ ████████████████▌ │ ██████████████████████████████████████████████████ │ █████████████▊ │
│ 22 │ ██████████▋ │ ██████▋ │ █████████████▏ │
│ 23 │ ████████████▌ │ █████▌ │ █████▋ │
└───────────┴───────────────────────────────┴────────────────────────────────────────────────────┴────────────────────────────────────────────────────┘
24 rows in set. Elapsed: 0.038 sec. Processed 266.05 thousand rows, 14.66 MB (7.09 million rows/s., 390.69 MB/s.)
作者矩阵,显示哪些作者倾向于重写其他作者的代码
sign = -1 表示代码删除。我们排除标点符号和空行的插入。
SELECT
prev_author || '(a)' as add_author,
author || '(d)' as delete_author,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author) AND (prev_author != '')
GROUP BY
prev_author,
author
ORDER BY c DESC
LIMIT 1 BY prev_author
LIMIT 100
┌─prev_author──────────┬─author───────────┬─────c─┐
│ Ivan │ Alexey Milovidov │ 18554 │
│ Alexey Arno │ Alexey Milovidov │ 18475 │
│ Michael Kolupaev │ Alexey Milovidov │ 14135 │
│ Alexey Milovidov │ Nikolai Kochetov │ 13435 │
│ Andrey Mironov │ Alexey Milovidov │ 10418 │
│ proller │ Alexey Milovidov │ 7280 │
│ Nikolai Kochetov │ Alexey Milovidov │ 6806 │
│ alexey-milovidov │ Alexey Milovidov │ 5027 │
│ Vitaliy Lyudvichenko │ Alexey Milovidov │ 4390 │
│ Amos Bird │ Ivan Lezhankin │ 3125 │
│ f1yegor │ Alexey Milovidov │ 3119 │
│ Pavel Kartavyy │ Alexey Milovidov │ 3087 │
│ Alexey Zatelepin │ Alexey Milovidov │ 2978 │
│ alesapin │ Alexey Milovidov │ 2949 │
│ Sergey Fedorov │ Alexey Milovidov │ 2727 │
│ Ivan Lezhankin │ Alexey Milovidov │ 2618 │
│ Vasily Nemkov │ Alexey Milovidov │ 2547 │
│ Alexander Tokmakov │ Alexey Milovidov │ 2493 │
│ Nikita Vasilev │ Maksim Kita │ 2420 │
│ Anton Popov │ Amos Bird │ 2127 │
└──────────────────────┴──────────────────┴───────┘
20 rows in set. Elapsed: 0.098 sec. Processed 7.54 million rows, 42.16 MB (76.67 million rows/s., 428.99 MB/s.)
桑基图 (SuperSet) 可以很好地可视化这一点。请注意,我们将 LIMIT BY 增加到 3,以获得每个作者的前 3 名代码删除者,以提高视觉效果的多样性。
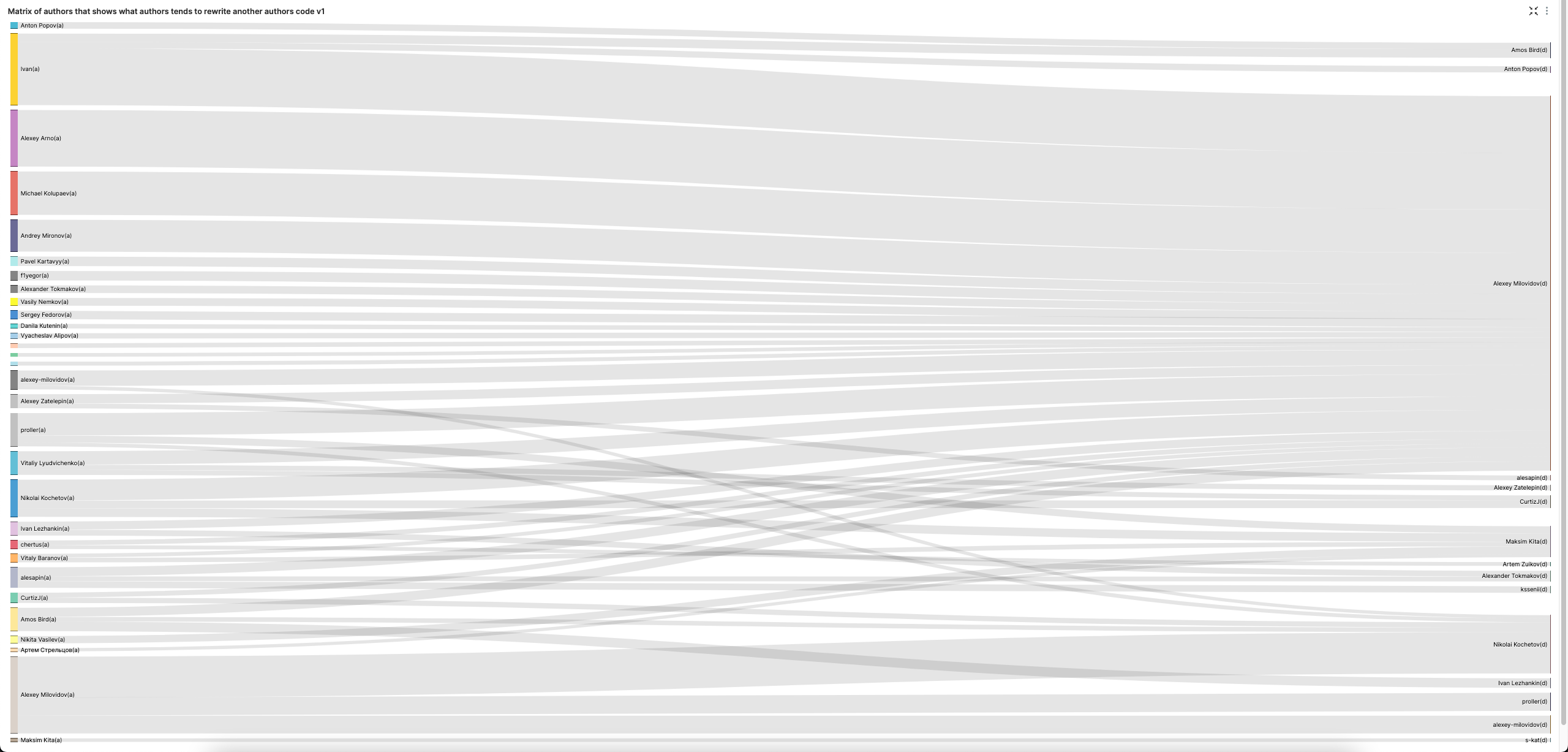
Alexey 显然喜欢删除其他人的代码。让我们排除他,以获得更平衡的代码删除视图。

谁是每周每天贡献百分比最高的人?
如果我们仅按提交次数考虑
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬────c─┐
│ 1 │ Alexey Milovidov │ 2204 │
│ 2 │ Alexey Milovidov │ 1588 │
│ 3 │ Alexey Milovidov │ 1725 │
│ 4 │ Alexey Milovidov │ 1915 │
│ 5 │ Alexey Milovidov │ 1940 │
│ 6 │ Alexey Milovidov │ 1851 │
│ 7 │ Alexey Milovidov │ 2400 │
└─────────────┴──────────────────┴──────┘
7 rows in set. Elapsed: 0.012 sec. Processed 62.78 thousand rows, 395.47 KB (5.44 million rows/s., 34.27 MB/s.)
好的,这里可能有一些对最长的贡献者 - 我们的创始人 Alexey 的优势。让我们将分析限制在过去一年。
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
WHERE time > (now() - toIntervalYear(1))
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬───c─┐
│ 1 │ Alexey Milovidov │ 198 │
│ 2 │ alesapin │ 162 │
│ 3 │ alesapin │ 163 │
│ 4 │ Azat Khuzhin │ 166 │
│ 5 │ alesapin │ 191 │
│ 6 │ Alexey Milovidov │ 179 │
│ 7 │ Alexey Milovidov │ 243 │
└─────────────┴──────────────────┴─────┘
7 rows in set. Elapsed: 0.004 sec. Processed 21.82 thousand rows, 140.02 KB (4.88 million rows/s., 31.29 MB/s.)
这仍然有点简单,不能反映人们的工作。
更好的指标可能是谁是每天的主要贡献者,占过去一年执行的总工作量的比例。请注意,我们平等对待删除和添加代码。
SELECT
top_author.day_of_week,
top_author.author,
top_author.author_work / all_work.total_work AS top_author_percent
FROM
(
SELECT
day_of_week,
author,
sum(lines_added) + sum(lines_deleted) AS author_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY
author,
dayOfWeek(time) AS day_of_week
ORDER BY
day_of_week ASC,
author_work DESC
LIMIT 1 BY day_of_week
) AS top_author
INNER JOIN
(
SELECT
day_of_week,
sum(lines_added) + sum(lines_deleted) AS total_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY dayOfWeek(time) AS day_of_week
) AS all_work USING (day_of_week)
┌─day_of_week─┬─author──────────────┬──top_author_percent─┐
│ 1 │ Alexey Milovidov │ 0.3168282877768332 │
│ 2 │ Mikhail f. Shiryaev │ 0.3523434231193969 │
│ 3 │ vdimir │ 0.11859742484577324 │
│ 4 │ Nikolay Degterinsky │ 0.34577318920318467 │
│ 5 │ Alexey Milovidov │ 0.13208704423684223 │
│ 6 │ Alexey Milovidov │ 0.18895257783624633 │
│ 7 │ Robert Schulze │ 0.3617405888930302 │
└─────────────┴─────────────────────┴─────────────────────┘
7 rows in set. Elapsed: 0.014 sec. Processed 106.12 thousand rows, 1.38 MB (7.61 million rows/s., 98.65 MB/s.)
代码库中代码年龄的分布
我们将分析限制为当前文件。为了简洁起见,我们将结果限制为深度 2,每个根文件夹 5 个文件。根据需要进行调整。
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
concat(root, '/', sub_folder) AS folder,
round(avg(days_present)) AS avg_age_of_files,
min(days_present) AS min_age_files,
max(days_present) AS max_age_files,
count() AS c
FROM
(
SELECT
path,
dateDiff('day', min(time), toDate('2022-11-03')) AS days_present
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
)
GROUP BY
splitByChar('/', path)[1] AS root,
splitByChar('/', path)[2] AS sub_folder
ORDER BY
root ASC,
c DESC
LIMIT 5 BY root
┌─folder───────────────────────────┬─avg_age_of_files─┬─min_age_files─┬─max_age_files─┬────c─┐
│ base/base │ 387 │ 201 │ 397 │ 84 │
│ base/glibc-compatibility │ 887 │ 59 │ 993 │ 19 │
│ base/consistent-hashing │ 993 │ 993 │ 993 │ 5 │
│ base/widechar_width │ 993 │ 993 │ 993 │ 2 │
│ base/consistent-hashing-sumbur │ 993 │ 993 │ 993 │ 2 │
│ docker/test │ 1043 │ 1043 │ 1043 │ 1 │
│ programs/odbc-bridge │ 835 │ 91 │ 945 │ 25 │
│ programs/copier │ 587 │ 14 │ 945 │ 22 │
│ programs/library-bridge │ 155 │ 47 │ 608 │ 21 │
│ programs/disks │ 144 │ 62 │ 150 │ 14 │
│ programs/server │ 874 │ 709 │ 945 │ 10 │
│ rust/BLAKE3 │ 52 │ 52 │ 52 │ 1 │
│ src/Functions │ 752 │ 0 │ 944 │ 809 │
│ src/Storages │ 700 │ 8 │ 944 │ 736 │
│ src/Interpreters │ 684 │ 3 │ 944 │ 490 │
│ src/Processors │ 703 │ 44 │ 944 │ 482 │
│ src/Common │ 673 │ 7 │ 944 │ 473 │
│ tests/queries │ 674 │ -5 │ 945 │ 3777 │
│ tests/integration │ 656 │ 132 │ 945 │ 4 │
│ utils/memcpy-bench │ 601 │ 599 │ 605 │ 10 │
│ utils/keeper-bench │ 570 │ 569 │ 570 │ 7 │
│ utils/durability-test │ 793 │ 793 │ 793 │ 4 │
│ utils/self-extracting-executable │ 143 │ 143 │ 143 │ 3 │
│ utils/self-extr-exec │ 224 │ 224 │ 224 │ 2 │
└──────────────────────────────────┴──────────────────┴───────────────┴───────────────┴──────┘
24 rows in set. Elapsed: 0.129 sec. Processed 798.15 thousand rows, 15.11 MB (6.19 million rows/s., 117.08 MB/s.)
作者的代码被其他作者删除的百分比是多少?
对于这个问题,我们需要作者编写的行数除以他们被其他贡献者删除的总行数。
SELECT
k,
written_code.c,
removed_code.c,
removed_code.c / written_code.c AS remove_ratio
FROM
(
SELECT
author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY k
) AS written_code
INNER JOIN
(
SELECT
prev_author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author)
GROUP BY k
) AS removed_code USING (k)
WHERE written_code.c > 1000
ORDER BY remove_ratio DESC
LIMIT 10
┌─k──────────────────┬─────c─┬─removed_code.c─┬───────remove_ratio─┐
│ Marek Vavruša │ 1458 │ 1318 │ 0.9039780521262003 │
│ Ivan │ 32715 │ 27500 │ 0.8405930001528351 │
│ artpaul │ 3450 │ 2840 │ 0.8231884057971014 │
│ Silviu Caragea │ 1542 │ 1209 │ 0.7840466926070039 │
│ Ruslan │ 1027 │ 802 │ 0.7809152872444012 │
│ Tsarkova Anastasia │ 1755 │ 1364 │ 0.7772079772079772 │
│ Vyacheslav Alipov │ 3526 │ 2727 │ 0.7733976176971072 │
│ Marek Vavruša │ 1467 │ 1124 │ 0.7661895023858214 │
│ f1yegor │ 7194 │ 5213 │ 0.7246316374756742 │
│ kreuzerkrieg │ 3406 │ 2468 │ 0.724603640634175 │
└────────────────────┴───────┴────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.126 sec. Processed 15.07 million rows, 73.51 MB (119.97 million rows/s., 585.16 MB/s.)
列出被重写次数最多的文件?
对此问题的最简单方法可能是简单地计算每个路径的最多行修改次数(仅限于当前文件),例如
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─────c─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.160 sec. Processed 8.07 million rows, 98.99 MB (50.49 million rows/s., 619.49 MB/s.)
但这并没有捕捉到“重写”的概念,即在任何提交中文件的大部分内容都会发生变化。这需要更复杂的查询。如果我们认为重写是指当超过 50% 的文件被删除且添加了 50% 时。您可以根据自己对构成重写的理解来调整查询。
该查询仅限于当前文件。我们通过按 path 和 commit_hash 分组来列出所有文件更改,返回添加和删除的行数。使用窗口函数,我们通过执行累积总和并将任何更改对文件大小的影响估计为 添加的行数 - 删除的行数 来估计文件在任何时刻的总大小。使用此统计信息,我们可以计算每次更改添加或删除的文件百分比。最后,我们计算每个文件中构成重写的文件更改次数,即 (percent_add >= 0.5) AND (percent_delete >= 0.5) AND current_size > 50。请注意,我们要求文件超过 50 行,以避免将对文件的早期贡献计为重写。这也避免了对非常小的文件的偏差,这些文件可能更容易被重写。
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
changes AS
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
),
rewrites AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM changes
)
SELECT
path,
count() AS num_rewrites
FROM rewrites
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
GROUP BY path
ORDER BY num_rewrites DESC
LIMIT 10
┌─path──────────────────────────────────────────────────┬─num_rewrites─┐
│ src/Storages/WindowView/StorageWindowView.cpp │ 8 │
│ src/Functions/array/arrayIndex.h │ 7 │
│ src/Dictionaries/CacheDictionary.cpp │ 6 │
│ src/Dictionaries/RangeHashedDictionary.cpp │ 5 │
│ programs/client/Client.cpp │ 4 │
│ src/Functions/polygonPerimeter.cpp │ 4 │
│ src/Functions/polygonsEquals.cpp │ 4 │
│ src/Functions/polygonsWithin.cpp │ 4 │
│ src/Processors/Formats/Impl/ArrowColumnToCHColumn.cpp │ 4 │
│ src/Functions/polygonsSymDifference.cpp │ 4 │
└───────────────────────────────────────────────────────┴──────────────┘
10 rows in set. Elapsed: 0.299 sec. Processed 798.15 thousand rows, 31.52 MB (2.67 million rows/s., 105.29 MB/s.)
代码在存储库中停留的机会最高的星期几?
为此,我们需要唯一地标识一行代码。我们使用路径和行内容来估计这一点(因为同一行可能在文件中多次出现)。
我们查询添加的行,将其与删除的行连接起来 - 过滤到后者比前者发生得更晚的情况。这为我们提供了已删除的行,我们可以从中计算这两个事件之间的时间。
最后,我们汇总此数据集以计算行在存储库中停留的平均天数(按星期几)。
SELECT
day_of_week_added,
count() AS num,
avg(days_present) AS avg_days_present
FROM
(
SELECT
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE removed_code.time > added_code.time
)
GROUP BY dayOfWeek(added_day) AS day_of_week_added
┌─day_of_week_added─┬────num─┬───avg_days_present─┐
│ 1 │ 171879 │ 193.81759260875384 │
│ 2 │ 141448 │ 153.0931013517335 │
│ 3 │ 161230 │ 137.61553681076722 │
│ 4 │ 255728 │ 121.14149799787273 │
│ 5 │ 203907 │ 141.60181847606998 │
│ 6 │ 62305 │ 202.43449161383518 │
│ 7 │ 70904 │ 220.0266134491707 │
└───────────────────┴────────┴────────────────────┘
7 rows in set. Elapsed: 3.965 sec. Processed 15.07 million rows, 1.92 GB (3.80 million rows/s., 483.50 MB/s.)
按平均代码年龄排序的文件
此查询使用与代码在存储库中停留的机会最高的星期几相同的原理 - 通过旨在唯一地标识使用路径和行内容的代码行。这使我们能够识别行添加和删除之间的时间。但是,我们仅过滤到当前文件和代码,并平均每个文件中各行的时间。
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.clickhouse_file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
lines_removed AS
(
SELECT
added_code.path AS path,
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time,
any(file_extension) AS file_extension
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE (removed_code.time > added_code.time) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
)
SELECT
path,
avg(days_present) AS avg_code_age
FROM lines_removed
GROUP BY path
ORDER BY avg_code_age DESC
LIMIT 10
┌─path────────────────────────────────────────────────────────────┬──────avg_code_age─┐
│ utils/corrector_utf8/corrector_utf8.cpp │ 1353.888888888889 │
│ tests/queries/0_stateless/01288_shard_max_network_bandwidth.sql │ 881 │
│ src/Functions/replaceRegexpOne.cpp │ 861 │
│ src/Functions/replaceRegexpAll.cpp │ 861 │
│ src/Functions/replaceOne.cpp │ 861 │
│ utils/zookeeper-remove-by-list/main.cpp │ 838.25 │
│ tests/queries/0_stateless/01356_state_resample.sql │ 819 │
│ tests/queries/0_stateless/01293_create_role.sql │ 819 │
│ src/Functions/ReplaceStringImpl.h │ 810 │
│ src/Interpreters/createBlockSelector.cpp │ 795 │
└─────────────────────────────────────────────────────────────────┴───────────────────┘
10 rows in set. Elapsed: 3.134 sec. Processed 16.13 million rows, 1.83 GB (5.15 million rows/s., 582.99 MB/s.)
谁倾向于编写更多测试/ CPP 代码/注释?
我们可以通过几种方式解决这个问题。专注于代码与测试的比率,此查询相对简单 - 计算对包含 tests 的文件夹的贡献数,并计算与总贡献数的比率。
请注意,我们将用户限制为更改超过 20 次的用户,以关注常规提交者,并避免对一次性贡献的偏差。
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
┌─author───────────────┬─test─┬──code─┬─────────ratio_code─┐
│ Alexey Milovidov │ 6617 │ 41799 │ 0.8633303040317251 │
│ Nikolai Kochetov │ 916 │ 13361 │ 0.9358408629263851 │
│ alesapin │ 2408 │ 8796 │ 0.785076758300607 │
│ kssenii │ 869 │ 6769 │ 0.8862267609321812 │
│ Maksim Kita │ 799 │ 5862 │ 0.8800480408347096 │
│ Alexander Tokmakov │ 1472 │ 5727 │ 0.7955271565495208 │
│ Vitaly Baranov │ 1764 │ 5521 │ 0.7578586135895676 │
│ Ivan Lezhankin │ 843 │ 4698 │ 0.8478613968597726 │
│ Anton Popov │ 599 │ 4346 │ 0.8788675429726996 │
│ Ivan │ 2630 │ 4269 │ 0.6187853312074214 │
│ Azat Khuzhin │ 1664 │ 3697 │ 0.689610147360567 │
│ Amos Bird │ 400 │ 2901 │ 0.8788245986064829 │
│ proller │ 1207 │ 2377 │ 0.6632254464285714 │
│ chertus │ 453 │ 2359 │ 0.8389046941678521 │
│ alexey-milovidov │ 303 │ 2321 │ 0.8845274390243902 │
│ Alexey Arno │ 169 │ 2310 │ 0.9318273497377975 │
│ Vitaliy Lyudvichenko │ 334 │ 2283 │ 0.8723729461215132 │
│ Robert Schulze │ 182 │ 2196 │ 0.9234650967199327 │
│ CurtizJ │ 460 │ 2158 │ 0.8242933537051184 │
│ Alexander Kuzmenkov │ 298 │ 2092 │ 0.8753138075313808 │
└──────────────────────┴──────┴───────┴────────────────────┘
20 rows in set. Elapsed: 0.034 sec. Processed 266.05 thousand rows, 4.65 MB (7.93 million rows/s., 138.76 MB/s.)
我们可以将此分布绘制为直方图。
WITH (
SELECT histogram(10)(ratio_code) AS hist
FROM
(
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
)
) AS hist
SELECT
arrayJoin(hist).1 AS lower,
arrayJoin(hist).2 AS upper,
bar(arrayJoin(hist).3, 0, 100, 500) AS bar
┌──────────────lower─┬──────────────upper─┬─bar───────────────────────────┐
│ 0.6187853312074214 │ 0.6410053888179964 │ █████ │
│ 0.6410053888179964 │ 0.6764177968945693 │ █████ │
│ 0.6764177968945693 │ 0.7237343804750673 │ █████ │
│ 0.7237343804750673 │ 0.7740802855073157 │ █████▋ │
│ 0.7740802855073157 │ 0.807297655565091 │ ████████▋ │
│ 0.807297655565091 │ 0.8338381996094653 │ ██████▎ │
│ 0.8338381996094653 │ 0.8533566747727687 │ ████████▋ │
│ 0.8533566747727687 │ 0.871392376017531 │ █████████▍ │
│ 0.871392376017531 │ 0.904916108899021 │ ████████████████████████████▋ │
│ 0.904916108899021 │ 0.9358408629263851 │ █████████████████▌ │
└────────────────────┴────────────────────┴───────────────────────────────┘
10 rows in set. Elapsed: 0.051 sec. Processed 266.05 thousand rows, 4.65 MB (5.24 million rows/s., 91.64 MB/s.)
正如您所期望的那样,大多数贡献者编写的代码多于测试。
那么,谁在贡献代码时添加的注释最多呢?
SELECT
author,
avg(ratio_comments) AS avg_ratio_comments,
sum(code) AS code
FROM
(
SELECT
author,
commit_hash,
countIf(line_type = 'Comment') AS comments,
countIf(line_type = 'Code') AS code,
if(comments > 0, comments / (comments + code), 0) AS ratio_comments
FROM git.clickhouse_line_changes
GROUP BY
author,
commit_hash
)
GROUP BY author
ORDER BY code DESC
LIMIT 10
┌─author─────────────┬──avg_ratio_comments─┬────code─┐
│ Alexey Milovidov │ 0.1034915408309902 │ 1147196 │
│ s-kat │ 0.1361718900215362 │ 614224 │
│ Nikolai Kochetov │ 0.08722993407690126 │ 218328 │
│ alesapin │ 0.1040477684726504 │ 198082 │
│ Vitaly Baranov │ 0.06446875712939285 │ 161801 │
│ Maksim Kita │ 0.06863376297549255 │ 156381 │
│ Alexey Arno │ 0.11252677608033655 │ 146642 │
│ Vitaliy Zakaznikov │ 0.06199215397180561 │ 138530 │
│ kssenii │ 0.07455322590796751 │ 131143 │
│ Artur │ 0.12383737231074826 │ 121484 │
└────────────────────┴─────────────────────┴─────────┘
10 rows in set. Elapsed: 0.290 sec. Processed 7.54 million rows, 394.57 MB (26.00 million rows/s., 1.36 GB/s.)
请注意,我们按代码贡献排序。对于我们所有最大的贡献者来说,百分比都出奇地高,这也是我们的代码如此可读的原因之一。
作者的提交如何随时间变化(关于代码/注释百分比)?
按作者计算这个很简单,
SELECT
author,
countIf(line_type = 'Code') AS code_lines,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
code_lines / (comments + code_lines) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
GROUP BY
time,
author
ORDER BY
author ASC,
time ASC
LIMIT 10
┌─author──────────────────────┬─code_lines─┬─comments─┬─────────ratio_code─┬───────week─┐
│ 1lann │ 8 │ 0 │ 1 │ 2022-03-06 │
│ 20018712 │ 2 │ 0 │ 1 │ 2020-09-13 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 2 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 112 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 14 │ 0 │ 2020-12-06 │
│ 3ldar-nasyrov │ 2 │ 0 │ 1 │ 2021-03-14 │
│ 821008736@qq.com │ 27 │ 2 │ 0.9310344827586207 │ 2019-04-21 │
│ ANDREI STAROVEROV │ 182 │ 60 │ 0.7520661157024794 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 7 │ 0 │ 1 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 32 │ 12 │ 0.7272727272727273 │ 2021-05-09 │
└─────────────────────────────┴────────────┴──────────┴────────────────────┴────────────┘
10 rows in set. Elapsed: 0.145 sec. Processed 7.54 million rows, 51.09 MB (51.83 million rows/s., 351.44 MB/s.)
但是,理想情况下,我们希望看到从所有作者开始提交的第一天起,这种情况如何在所有作者中汇总变化。他们是否慢慢减少他们编写的注释数量?
为了计算这个,我们首先计算每位作者随时间推移的评论比率 - 类似于谁倾向于编写更多的测试/CPP代码/注释?。这与每位作者的开始日期结合,使我们能够计算每周偏移量的评论比率。
在计算所有作者的每周偏移量的平均值后,我们通过选择每 10 周对这些结果进行抽样。
WITH author_ratios_by_offset AS
(
SELECT
author,
dateDiff('week', start_dates.start_date, contributions.week) AS week_offset,
ratio_code
FROM
(
SELECT
author,
toStartOfWeek(min(time)) AS start_date
FROM git.line_changes
WHERE file_extension IN ('h', 'cpp', 'sql')
GROUP BY author AS start_dates
) AS start_dates
INNER JOIN
(
SELECT
author,
countIf(line_type = 'Code') AS code,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
comments / (comments + code) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (sign = 1)
GROUP BY
time,
author
HAVING code > 20
ORDER BY
author ASC,
time ASC
) AS contributions USING (author)
)
SELECT
week_offset,
avg(ratio_code) AS avg_code_ratio
FROM author_ratios_by_offset
GROUP BY week_offset
HAVING (week_offset % 10) = 0
ORDER BY week_offset ASC
LIMIT 20
┌─week_offset─┬──────avg_code_ratio─┐
│ 0 │ 0.21626798253005078 │
│ 10 │ 0.18299433892099454 │
│ 20 │ 0.22847255749045017 │
│ 30 │ 0.2037816688365288 │
│ 40 │ 0.1987063517030308 │
│ 50 │ 0.17341406302829748 │
│ 60 │ 0.1808884776496144 │
│ 70 │ 0.18711773536450496 │
│ 80 │ 0.18905573684766458 │
│ 90 │ 0.2505147771581594 │
│ 100 │ 0.2427673990917429 │
│ 110 │ 0.19088569009169926 │
│ 120 │ 0.14218574654598348 │
│ 130 │ 0.20894252550489317 │
│ 140 │ 0.22316626978848397 │
│ 150 │ 0.1859507592277053 │
│ 160 │ 0.22007759757363546 │
│ 170 │ 0.20406936638195144 │
│ 180 │ 0.1412102467834332 │
│ 190 │ 0.20677550885049117 │
└─────────────┴─────────────────────┘
20 rows in set. Elapsed: 0.167 sec. Processed 15.07 million rows, 101.74 MB (90.51 million rows/s., 610.98 MB/s.)
令人鼓舞的是,我们的评论百分比相当稳定,并且不会随着作者贡献时间的增加而降低。
代码被重写之前的平均时间以及中位数(代码衰减的半衰期)是多少?
我们可以使用与列出被重写次数最多或被最多作者重写的文件相同的原则来识别重写,但要考虑所有文件。窗口函数用于计算每个文件的重写之间的时间。由此,我们可以计算所有文件的平均值和中位数。
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
avgIf(rewrite_days, rewrite_days > 0) AS avg_rewrite_time,
quantilesTimingIf(0.5)(rewrite_days, rewrite_days > 0) AS half_life
FROM rewrites
┌─avg_rewrite_time─┬─half_life─┐
│ 122.2890625 │ [23] │
└──────────────────┴───────────┘
1 row in set. Elapsed: 0.388 sec. Processed 266.05 thousand rows, 22.85 MB (685.82 thousand rows/s., 58.89 MB/s.)
从代码最有可能被重写的意义上来说,最糟糕的编写代码时间是什么时候?
类似于代码被重写之前的平均时间以及中位数(代码衰减的半衰期)是多少?和列出被重写次数最多或被最多作者重写的文件,除了我们按星期几聚合。根据需要调整,例如月份。
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
dayOfWeek(previous_rewrite) AS dayOfWeek,
count() AS num_re_writes
FROM rewrites
GROUP BY dayOfWeek
┌─dayOfWeek─┬─num_re_writes─┐
│ 1 │ 111 │
│ 2 │ 121 │
│ 3 │ 91 │
│ 4 │ 111 │
│ 5 │ 90 │
│ 6 │ 64 │
│ 7 │ 46 │
└───────────┴───────────────┘
7 rows in set. Elapsed: 0.466 sec. Processed 7.54 million rows, 701.52 MB (16.15 million rows/s., 1.50 GB/s.)
哪位作者的代码最具“粘性”?
我们将“粘性”定义为作者的代码在被重写之前停留的时间。类似于之前的问题代码被重写之前的平均时间以及中位数(代码衰减的半衰期)是多少? - 使用相同的重写指标,即对文件进行 50% 的添加和 50% 的删除。我们计算每位作者的平均重写时间,并且仅考虑贡献超过两个文件的贡献者。
WITH
changes AS
(
SELECT
path,
author,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
any(author) AS author,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days,
any(author) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS prev_author
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
prev_author,
avg(rewrite_days) AS c,
uniq(path) AS num_files
FROM rewrites
GROUP BY prev_author
HAVING num_files > 2
ORDER BY c DESC
LIMIT 10
┌─prev_author─────────┬──────────────────c─┬─num_files─┐
│ Michael Kolupaev │ 304.6 │ 4 │
│ alexey-milovidov │ 81.83333333333333 │ 4 │
│ Alexander Kuzmenkov │ 64.5 │ 5 │
│ Pavel Kruglov │ 55.8 │ 6 │
│ Alexey Milovidov │ 48.416666666666664 │ 90 │
│ Amos Bird │ 42.8 │ 4 │
│ alesapin │ 38.083333333333336 │ 12 │
│ Nikolai Kochetov │ 33.18421052631579 │ 26 │
│ Alexander Tokmakov │ 31.866666666666667 │ 12 │
│ Alexey Zatelepin │ 22.5 │ 4 │
└─────────────────────┴────────────────────┴───────────┘
10 rows in set. Elapsed: 0.555 sec. Processed 7.54 million rows, 720.60 MB (13.58 million rows/s., 1.30 GB/s.)
作者提交的最长连续天数
此查询首先需要我们计算作者提交代码的天数。使用窗口函数,按作者分区,我们可以计算他们提交代码之间的天数。对于每次提交,如果自上次提交以来的时间为 1 天,我们将其标记为连续 (1),否则标记为 0 - 将此结果存储在 consecutive_day 中。
我们随后的数组函数计算每位作者最长的连续 1 序列。首先,groupArray 函数用于整理作者的所有 consecutive_day 值。然后,这个由 1 和 0 组成的数组,在 0 值处拆分为子数组。最后,我们计算最长的子数组。
WITH commit_days AS
(
SELECT
author,
day,
any(day) OVER (PARTITION BY author ORDER BY day ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_commit,
dateDiff('day', previous_commit, day) AS days_since_last,
if(days_since_last = 1, 1, 0) AS consecutive_day
FROM
(
SELECT
author,
toStartOfDay(time) AS day
FROM git.commits
GROUP BY
author,
day
ORDER BY
author ASC,
day ASC
)
)
SELECT
author,
arrayMax(arrayMap(x -> length(x), arraySplit(x -> (x = 0), groupArray(consecutive_day)))) - 1 AS max_consecutive_days
FROM commit_days
GROUP BY author
ORDER BY max_consecutive_days DESC
LIMIT 10
┌─author───────────┬─max_consecutive_days─┐
│ kssenii │ 32 │
│ Alexey Milovidov │ 30 │
│ alesapin │ 26 │
│ Azat Khuzhin │ 23 │
│ Nikolai Kochetov │ 15 │
│ feng lv │ 11 │
│ alexey-milovidov │ 11 │
│ Igor Nikonov │ 11 │
│ Maksim Kita │ 11 │
│ Nikita Vasilev │ 11 │
└──────────────────┴──────────────────────┘
10 rows in set. Elapsed: 0.025 sec. Processed 62.78 thousand rows, 395.47 KB (2.54 million rows/s., 16.02 MB/s.)
文件的逐行提交历史记录
文件可以重命名。当这种情况发生时,我们会得到一个重命名事件,其中 path 列设置为文件的新路径,而 old_path 表示以前的位置,例如:
SELECT
time,
path,
old_path,
commit_hash,
commit_message
FROM git.file_changes
WHERE (path = 'src/Storages/StorageReplicatedMergeTree.cpp') AND (change_type = 'Rename')
┌────────────────time─┬─path────────────────────────────────────────┬─old_path─────────────────────────────────────┬─commit_hash──────────────────────────────┬─commit_message─┐
│ 2020-04-03 16:14:31 │ src/Storages/StorageReplicatedMergeTree.cpp │ dbms/Storages/StorageReplicatedMergeTree.cpp │ 06446b4f08a142d6f1bc30664c47ded88ab51782 │ dbms/ → src/ │
└─────────────────────┴─────────────────────────────────────────────┴──────────────────────────────────────────────┴──────────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.135 sec. Processed 266.05 thousand rows, 20.73 MB (1.98 million rows/s., 154.04 MB/s.)
这使得查看文件的完整历史记录变得具有挑战性,因为我们没有一个连接所有行或文件更改的单个值。
为了解决这个问题,我们可以使用用户自定义函数 (UDF)。这些函数目前不能是递归的,因此为了识别文件的历史记录,我们必须定义一系列显式相互调用的 UDF。
这意味着我们只能跟踪最大深度的重命名 - 下面的示例为 5 层深度。文件不太可能被重命名超过此次数,因此目前,这已足够。
CREATE FUNCTION file_path_history AS (n) -> if(empty(n), [], arrayConcat([n], file_path_history_01((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_01 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_02((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_02 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_03((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_03 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_04((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_04 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_05((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_05 AS (n) -> if(isNull(n), [], [n]);
通过调用 file_path_history('src/Storages/StorageReplicatedMergeTree.cpp'),我们递归遍历重命名历史记录,每个函数都使用 old_path 调用下一层。结果使用 arrayConcat 组合。
例如,
SELECT file_path_history('src/Storages/StorageReplicatedMergeTree.cpp') AS paths
┌─paths─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['src/Storages/StorageReplicatedMergeTree.cpp','dbms/Storages/StorageReplicatedMergeTree.cpp','dbms/src/Storages/StorageReplicatedMergeTree.cpp'] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.074 sec. Processed 344.06 thousand rows, 6.27 MB (4.65 million rows/s., 84.71 MB/s.)
我们现在可以使用此功能来组装文件的整个历史记录的提交。在此示例中,我们显示每个 path 值的一个提交。
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
commit_message
FROM git.file_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
ORDER BY time DESC
LIMIT 1 BY path
FORMAT PrettyCompactMonoBlock
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path─────────────────────────────────────────────┬─commit_message──────────────────────────────────────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ fix accessing part in Deleting state │
│ 2020-04-03 15:21:24 │ 38a50f44d34 │ Modify │ alesapin │ dbms/Storages/StorageReplicatedMergeTree.cpp │ Remove empty line │
│ 2020-04-01 19:21:27 │ 1d5a77c1132 │ Modify │ alesapin │ dbms/src/Storages/StorageReplicatedMergeTree.cpp │ Tried to add ability to rename primary key columns but just banned this ability │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴──────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────────┘
3 rows in set. Elapsed: 0.170 sec. Processed 611.53 thousand rows, 41.76 MB (3.60 million rows/s., 246.07 MB/s.)
未解决的问题
Git blame
由于目前无法在数组函数中保持状态,因此很难获得精确的结果。这将可以通过 arrayFold 或 arrayReduce 实现,它们允许在每次迭代时保持状态。
一个近似的解决方案,足以进行高级分析,可能如下所示
SELECT
line_number_new,
argMax(author, time),
argMax(line, time)
FROM git.line_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
GROUP BY line_number_new
ORDER BY line_number_new ASC
LIMIT 20
┌─line_number_new─┬─argMax(author, time)─┬─argMax(line, time)────────────────────────────────────────────┐
│ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 3 │ Anton Popov │ #include <cstddef> │
│ 4 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 6 │ Alexander Burmak │ #include <Common/DiskSpaceMonitor.h> │
│ 7 │ Alexander Burmak │ #include <Common/ZooKeeper/Types.h> │
│ 8 │ Alexander Burmak │ #include <Common/escapeForFileName.h> │
│ 9 │ Alexander Burmak │ #include <Common/formatReadable.h> │
│ 10 │ Alexander Burmak │ #include <Common/thread_local_rng.h> │
│ 11 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
│ 13 │ alesapin │ #include <Disks/ObjectStorages/IMetadataStorage.h> │
│ 14 │ alesapin │ │
│ 15 │ Alexey Milovidov │ #include <DB/Databases/IDatabase.h> │
│ 16 │ Alexey Zatelepin │ #include <Storages/MergeTree/ReplicatedMergeTreePartHeader.h> │
│ 17 │ CurtizJ │ #include <Storages/MergeTree/MergeTreeDataPart.h> │
│ 18 │ Kirill Shvakov │ #include <Parsers/ASTDropQuery.h> │
│ 19 │ s-kat │ #include <Storages/MergeTree/PinnedPartUUIDs.h> │
│ 20 │ Nikita Mikhaylov │ #include <Storages/MergeTree/MergeMutateExecutor.h> │
└─────────────────┴──────────────────────┴───────────────────────────────────────────────────────────────┘
20 rows in set. Elapsed: 0.547 sec. Processed 7.88 million rows, 679.20 MB (14.42 million rows/s., 1.24 GB/s.)
我们欢迎此处提供精确和改进的解决方案。