环境传感器数据
Sensor.Community 是一个贡献者驱动的全球传感器网络,旨在创建开放环境数据。数据从全球各地的传感器收集。任何人都可以购买传感器并将其放置在他们喜欢的任何位置。下载数据的 API 在 GitHub 中,数据在 数据库内容许可 (DbCL) 下免费提供。
信息
该数据集有超过 200 亿条记录,因此请谨慎复制粘贴以下命令,除非您的资源可以处理这种类型的数据量。以下命令在 ClickHouse Cloud 的生产实例上执行。
- 数据在 S3 中,因此我们可以使用
s3表函数从文件创建表。我们也可以就地查询数据。让我们在尝试将其插入 ClickHouse 之前查看几行
SELECT *
FROM s3(
'https://clickhouse-public-datasets.s3.eu-central-1.amazonaws.com/sensors/monthly/2019-06_bmp180.csv.zst',
'CSVWithNames'
)
LIMIT 10
SETTINGS format_csv_delimiter = ';';
数据在 CSV 文件中,但使用分号作为分隔符。行看起来像
┌─sensor_id─┬─sensor_type─┬─location─┬────lat─┬────lon─┬─timestamp───────────┬──pressure─┬─altitude─┬─pressure_sealevel─┬─temperature─┐
│ 9119 │ BMP180 │ 4594 │ 50.994 │ 7.126 │ 2019-06-01T00:00:00 │ 101471 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.9 │
│ 21210 │ BMP180 │ 10762 │ 42.206 │ 25.326 │ 2019-06-01T00:00:00 │ 99525 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.3 │
│ 19660 │ BMP180 │ 9978 │ 52.434 │ 17.056 │ 2019-06-01T00:00:04 │ 101570 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 15.3 │
│ 12126 │ BMP180 │ 6126 │ 57.908 │ 16.49 │ 2019-06-01T00:00:05 │ 101802.56 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 8.07 │
│ 15845 │ BMP180 │ 8022 │ 52.498 │ 13.466 │ 2019-06-01T00:00:05 │ 101878 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 23 │
│ 16415 │ BMP180 │ 8316 │ 49.312 │ 6.744 │ 2019-06-01T00:00:06 │ 100176 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 14.7 │
│ 7389 │ BMP180 │ 3735 │ 50.136 │ 11.062 │ 2019-06-01T00:00:06 │ 98905 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 12.1 │
│ 13199 │ BMP180 │ 6664 │ 52.514 │ 13.44 │ 2019-06-01T00:00:07 │ 101855.54 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 19.74 │
│ 12753 │ BMP180 │ 6440 │ 44.616 │ 2.032 │ 2019-06-01T00:00:07 │ 99475 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17 │
│ 16956 │ BMP180 │ 8594 │ 52.052 │ 8.354 │ 2019-06-01T00:00:08 │ 101322 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 17.2 │
└───────────┴─────────────┴──────────┴────────┴────────┴─────────────────────┴───────────┴──────────┴───────────────────┴─────────────┘
- 我们将使用以下
MergeTree表在 ClickHouse 中存储数据
CREATE TABLE sensors
(
sensor_id UInt16,
sensor_type Enum('BME280', 'BMP180', 'BMP280', 'DHT22', 'DS18B20', 'HPM', 'HTU21D', 'PMS1003', 'PMS3003', 'PMS5003', 'PMS6003', 'PMS7003', 'PPD42NS', 'SDS011'),
location UInt32,
lat Float32,
lon Float32,
timestamp DateTime,
P1 Float32,
P2 Float32,
P0 Float32,
durP1 Float32,
ratioP1 Float32,
durP2 Float32,
ratioP2 Float32,
pressure Float32,
altitude Float32,
pressure_sealevel Float32,
temperature Float32,
humidity Float32,
date Date MATERIALIZED toDate(timestamp)
)
ENGINE = MergeTree
ORDER BY (timestamp, sensor_id);
- ClickHouse Cloud 服务有一个名为
default的集群。我们将使用s3Cluster表函数,它从集群中节点的并行读取 S3 文件。(如果您没有集群,只需使用s3函数并删除集群名称。)
此查询将花费一段时间 - 它大约是 1.67T 的未压缩数据
INSERT INTO sensors
SELECT *
FROM s3Cluster(
'default',
'https://clickhouse-public-datasets.s3.amazonaws.com/sensors/monthly/*.csv.zst',
'CSVWithNames',
$$ sensor_id UInt16,
sensor_type String,
location UInt32,
lat Float32,
lon Float32,
timestamp DateTime,
P1 Float32,
P2 Float32,
P0 Float32,
durP1 Float32,
ratioP1 Float32,
durP2 Float32,
ratioP2 Float32,
pressure Float32,
altitude Float32,
pressure_sealevel Float32,
temperature Float32,
humidity Float32 $$
)
SETTINGS
format_csv_delimiter = ';',
input_format_allow_errors_ratio = '0.5',
input_format_allow_errors_num = 10000,
input_format_parallel_parsing = 0,
date_time_input_format = 'best_effort',
max_insert_threads = 32,
parallel_distributed_insert_select = 1;
这是响应 - 显示行数和处理速度。它的输入速度超过每秒 600 万行!
0 rows in set. Elapsed: 3419.330 sec. Processed 20.69 billion rows, 1.67 TB (6.05 million rows/s., 488.52 MB/s.)
- 让我们看看
sensors表需要多少存储磁盘空间
SELECT
disk_name,
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
round(usize / size, 2) AS compr_rate,
sum(rows) AS rows,
count() AS part_count
FROM system.parts
WHERE (active = 1) AND (table = 'sensors')
GROUP BY
disk_name
ORDER BY size DESC;
1.67T 被压缩到 310 GiB,并且有 206.9 亿行
┌─disk_name─┬─compressed─┬─uncompressed─┬─compr_rate─┬────────rows─┬─part_count─┐
│ s3disk │ 310.21 GiB │ 1.30 TiB │ 4.29 │ 20693971809 │ 472 │
└───────────┴────────────┴──────────────┴────────────┴─────────────┴────────────┘
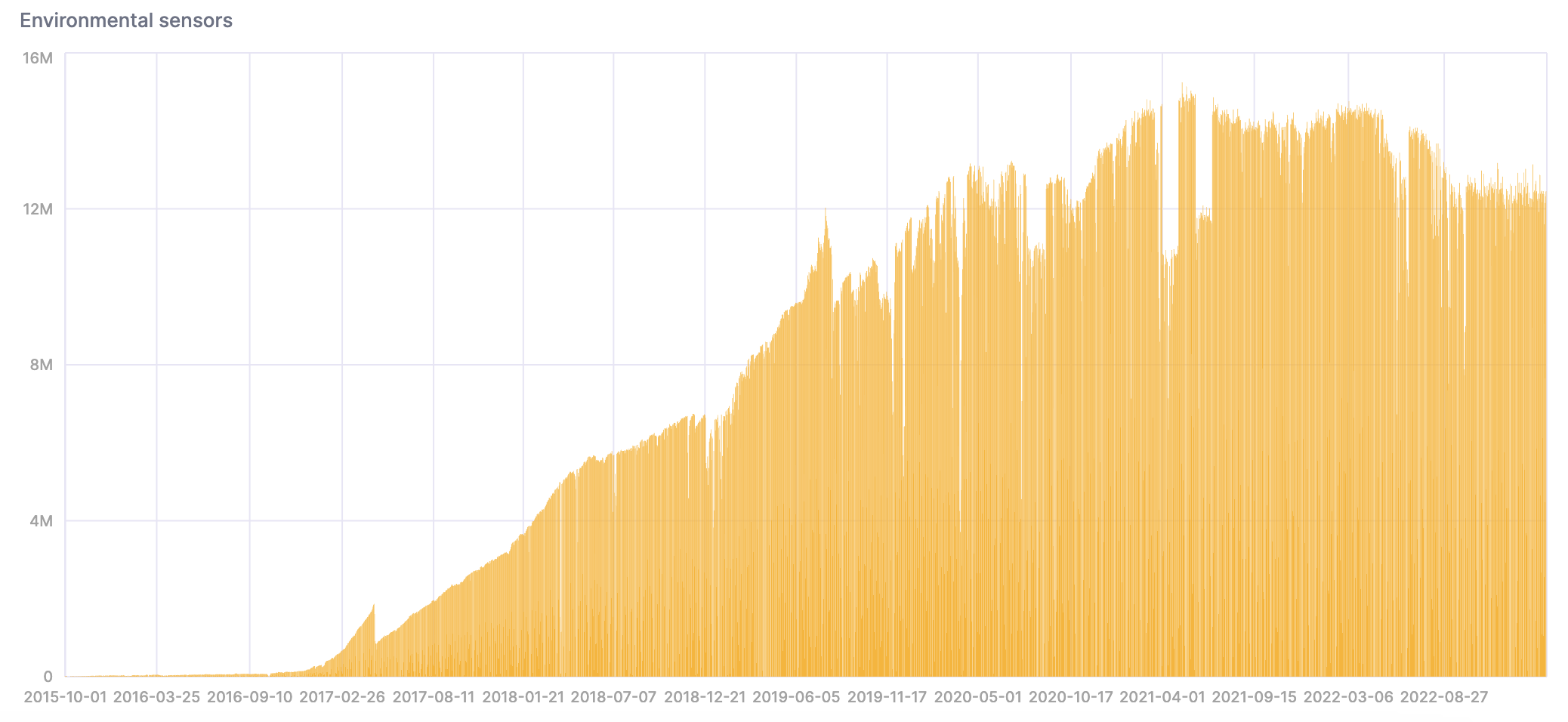
- 现在数据已在 ClickHouse 中,让我们分析数据。请注意,随着部署更多传感器,数据量随时间增加
SELECT
date,
count()
FROM sensors
GROUP BY date
ORDER BY date ASC;
我们可以在 SQL 控制台中创建一个图表来可视化结果
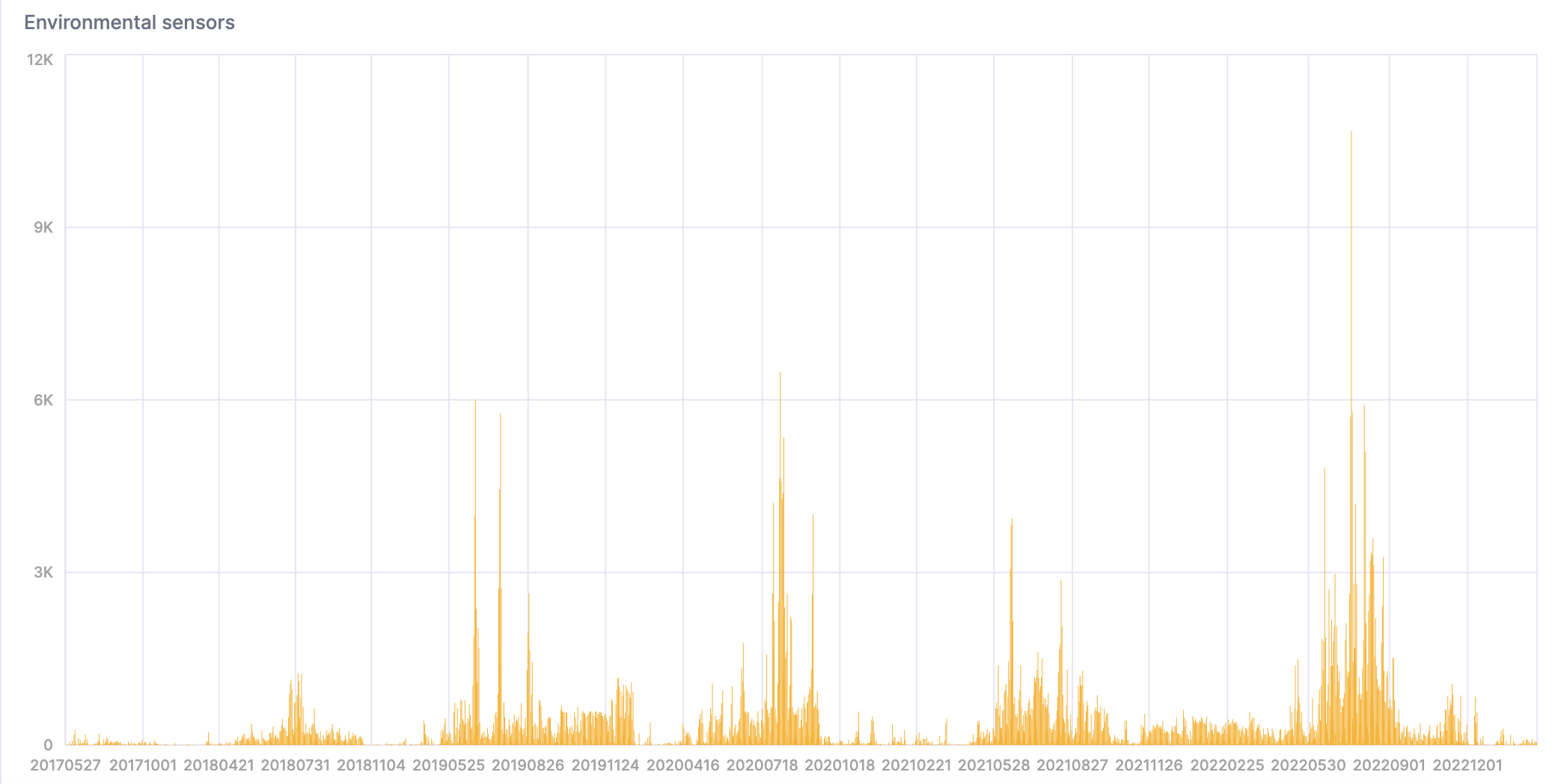
- 此查询计算过度炎热和潮湿的天数
WITH
toYYYYMMDD(timestamp) AS day
SELECT day, count() FROM sensors
WHERE temperature >= 40 AND temperature <= 50 AND humidity >= 90
GROUP BY day
ORDER BY day asc;
这是结果的可视化