从 PostgreSQL 加载数据到 ClickHouse
这是关于从 PostgreSQL 迁移到 ClickHouse 指南的第一部分。此内容可以被认为是入门级的,旨在帮助用户部署一个符合 ClickHouse 最佳实践的初始功能系统。它避免了复杂的主题,不会产生完全优化的 schema;相反,它为用户构建生产系统和奠定学习基础提供了坚实的基础。
数据集
作为展示从 Postgres 迁移到 ClickHouse 典型案例的示例数据集,我们使用 此处 文档中记录的 Stack Overflow 数据集。这包含 2008 年到 2024 年 4 月期间 Stack Overflow 上发生的每条 post、vote、user、comment 和 badge。此数据的 PostgreSQL schema 如下所示
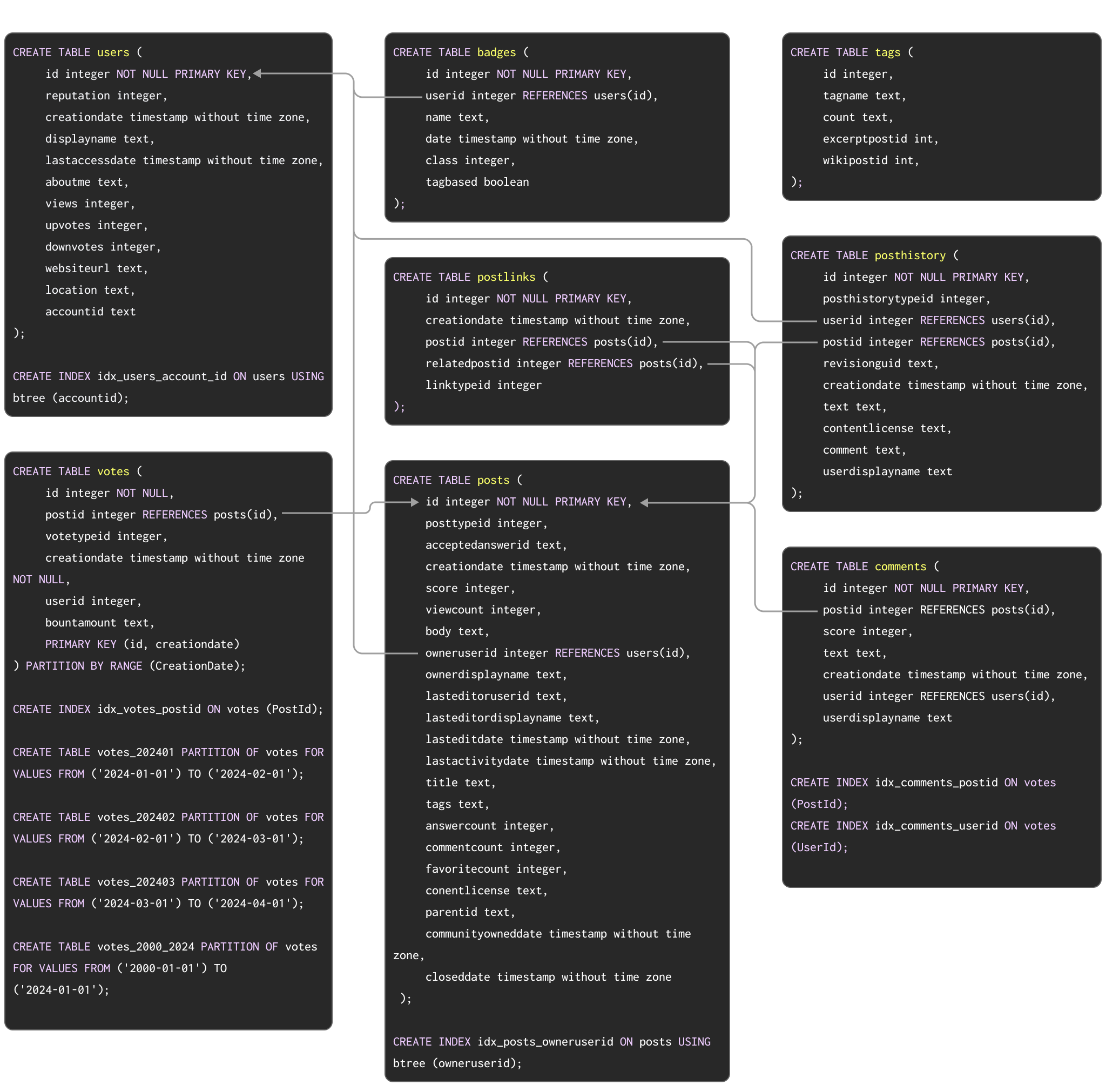
用于在 PostgreSQL 中创建表的 DDL 命令可在此处获取。
此 schema 虽然不一定是最佳的,但利用了许多流行的 PostgreSQL 功能,包括主键、外键、分区和索引。
我们将把这些概念中的每一个都迁移到其 ClickHouse 等效项。
对于希望将此数据集填充到 PostgreSQL 实例中以测试迁移步骤的用户,我们提供了 pg_dump 格式的数据,可与 DDL 一起下载,后续的数据加载命令如下所示
# users
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/users.sql.gz
gzip -d users.sql.gz
psql < users.sql
# posts
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posts.sql.gz
gzip -d posts.sql.gz
psql < posts.sql
# posthistory
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/posthistory.sql.gz
gzip -d posthistory.sql.gz
psql < posthistory.sql
# comments
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/comments.sql.gz
gzip -d comments.sql.gz
psql < comments.sql
# votes
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/votes.sql.gz
gzip -d votes.sql.gz
psql < votes.sql
# badges
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/badges.sql.gz
gzip -d badges.sql.gz
psql < badges.sql
# postlinks
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/pdump/2024/postlinks.sql.gz
gzip -d postlinks.sql.gz
psql < postlinks.sql
虽然对于 ClickHouse 来说这个数据集很小,但对于 Postgres 来说却很大。上面表示的是涵盖 2024 年前三个月的子集。
虽然我们的示例结果使用完整数据集来显示 Postgres 和 Clickhouse 之间的性能差异,但下面记录的所有步骤在功能上与较小的子集相同。想要将完整数据集加载到 Postgres 的用户请参阅 此处。由于上述 schema 施加的外键约束,PostgreSQL 的完整数据集仅包含满足引用完整性的行。如果需要,可以将没有此类约束的 Parquet 版本 轻松直接加载到 ClickHouse 中。
迁移数据
ClickHouse 和 Postgres 之间的数据迁移分为两种主要工作负载类型
- 初始批量加载和定期更新 - 必须迁移初始数据集,并按设定的时间间隔(例如,每天)进行定期更新。此处的更新通过重新发送已更改的行来处理 - 通过可用于比较的列(例如,日期)或 XMIN 值来识别。删除通过数据集的完整定期重新加载来处理。
- 实时复制或 CDC - 必须迁移初始数据集。对此数据集的更改必须以接近实时的速度反映在 ClickHouse 中,仅可接受几秒钟的延迟。这实际上是一个变更数据捕获 (CDC) 过程,其中 Postgres 中的表必须与 ClickHouse 同步,即 Postgres 表中的插入、更新和删除必须应用于 ClickHouse 中的等效表。
初始批量加载和定期更新
此工作负载代表了上述工作负载中较简单的一种,因为可以定期应用更改。可以通过以下方式实现数据集的初始批量加载
- 表函数 - 使用 ClickHouse 中的 Postgres 表函数从 Postgres
SELECT数据并将其INSERT到 ClickHouse 表中。适用于高达数百 GB 数据集的批量加载。 - 导出 - 导出为中间格式,例如 CSV 或 SQL 脚本文件。然后,可以通过客户端使用
INSERT FROM INFILE子句或使用对象存储及其关联函数(即 s3、gcs)将这些文件加载到 ClickHouse 中。
反过来,可以安排增量加载。如果 Postgres 表仅接收插入,并且存在递增的 id 或时间戳,则用户可以使用上述表函数方法来加载增量,即可以将 WHERE 子句应用于 SELECT。如果保证这些更新会更新同一列,则此方法也可用于支持更新。但是,支持删除将需要完全重新加载,这可能随着表的增长而难以实现。
我们演示了使用 CreationDate 的初始加载和增量加载(我们假设如果行被更新,则 CreationDate 会被更新)。
-- initial load
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password')
INSERT INTO stackoverflow.posts SELECT * FROM postgresql('<host>', 'postgres', 'posts', 'postgres', '<password') WHERE CreationDate > ( SELECT (max(CreationDate) FROM stackoverflow.posts)
ClickHouse 会将简单的
WHERE子句(例如=、!=、>、>=、<、<=和 IN)下推到 PostgreSQL 服务器。因此,通过确保在用于标识变更集的列上存在索引,可以提高增量加载的效率。
使用查询复制时检测
UPDATE操作的一种可能方法是使用XMIN系统列(事务 ID)作为水印 - 此列中的更改表示发生了更改,因此可以应用于目标表。采用此方法的用户应注意,XMIN值可能会回绕,并且比较需要完整的表扫描,这使得跟踪更改更加复杂。有关此方法的更多详细信息,请参阅“变更数据捕获 (CDC)”。
实时复制或 CDC
变更数据捕获 (CDC) 是指保持两个数据库之间表同步的过程。如果要以接近实时的速度处理更新和删除,这将变得非常复杂。目前有几种解决方案
- ClickHouse 的 PeerDB - PeerDB 提供了一个开源的专业 Postgres CDC 解决方案,用户可以自行管理或通过 SaaS 解决方案运行,该解决方案已证明在 Postgres 和 ClickHouse 的大规模应用中表现良好。该解决方案专注于底层优化,以实现 Postgres 和 ClickHouse 之间的高性能数据传输和可靠性保证。它支持在线和离线加载。
PeerDB 现在以原生方式在 ClickHouse Cloud 中提供 - 通过我们新的 ClickPipe 连接器实现闪电般快速的 Postgres 到 ClickHouse CDC - 现在处于私有预览阶段。请在此处注册
- 构建您自己的解决方案 - 这可以通过 Debezium + Kafka 来实现 - Debezium 提供了捕获 Postgres 表上所有更改的能力,并将这些更改作为事件转发到 Kafka 队列。然后,这些事件可以由 ClickHouse Kafka 连接器或 ClickHouse Cloud 中的 ClickPipes 消费,以便插入到 ClickHouse 中。这代表了变更数据捕获 (CDC),因为 Debezium 不仅会执行表的初始复制,还会确保检测到 Postgres 上的所有后续更新、删除和插入,从而产生下游事件。这需要仔细配置 Postgres、Debezium 和 ClickHouse。示例可以在 此处 找到。
对于本指南中的示例,我们仅假设初始批量加载,重点是数据探索和轻松迭代到可用于其他方法的生产 schema。