数据建模技术
这是从 PostgreSQL 迁移到 ClickHouse 指南的第 3 部分。此内容可以被认为是入门级的,旨在帮助用户部署符合 ClickHouse 最佳实践的初始功能系统。它避免了复杂的主题,不会产生完全优化的模式;相反,它为用户构建生产系统和奠定学习基础提供了坚实的基础。
我们建议从 Postgres 迁移的用户阅读ClickHouse 中数据建模指南。本指南使用相同的 Stack Overflow 数据集,并探讨了使用 ClickHouse 功能的多种方法。
分区
Postgres 用户将熟悉表分区的概念,通过将表划分为更小、更易于管理的部分(称为分区)来增强大型数据库的性能和可管理性。可以使用指定列上的范围(例如,日期)、定义的列表或键上的哈希来实现此分区。这允许管理员根据特定标准(如日期范围或地理位置)组织数据。分区通过启用分区修剪和更高效的索引来帮助提高查询性能,从而实现更快的数据访问。它还有助于维护任务,例如备份和数据清除,允许对单个分区而不是整个表进行操作。此外,分区可以通过在多个分区之间分配负载来显着提高 PostgreSQL 数据库的可扩展性。
在 ClickHouse 中,分区在表最初通过 PARTITION BY 子句定义时指定。此子句可以包含任何列上的 SQL 表达式,其结果将定义行发送到哪个分区。
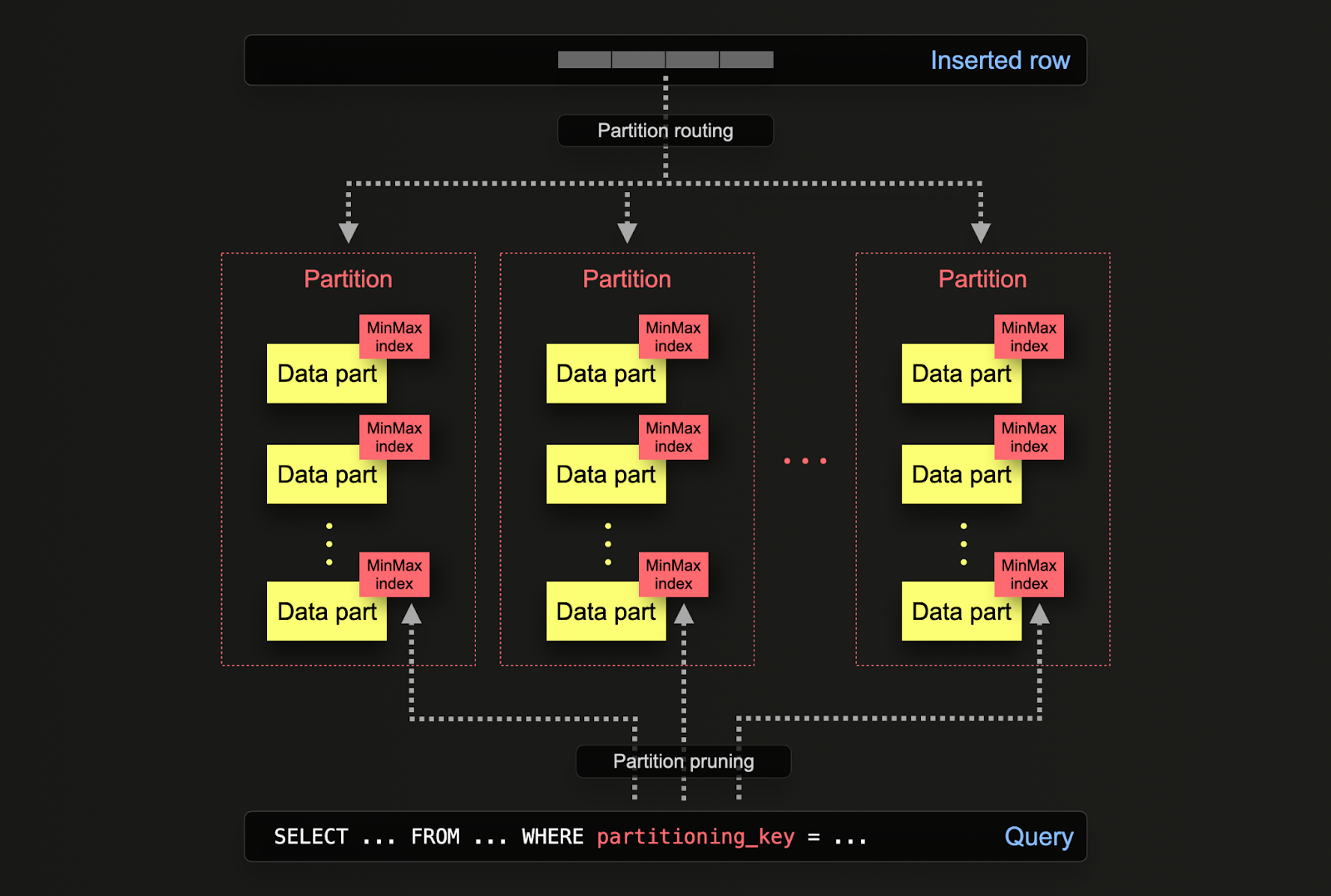
数据部分在逻辑上与磁盘上的每个分区关联,并且可以隔离查询。对于下面的示例,我们使用表达式 toYear(CreationDate) 按年份对 posts 表进行分区。当行插入到 ClickHouse 时,将针对每一行评估此表达式,并将路由到结果分区(如果存在)(如果该行是某一年的第一行,则将创建分区)。
CREATE TABLE posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
...
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CreationDate)
PARTITION BY toYear(CreationDate)
分区的应用
ClickHouse 中的分区与 Postgres 中的应用类似,但有一些细微的差异。更具体地说
- 数据管理 - 在 ClickHouse 中,用户主要应将分区视为数据管理功能,而不是查询优化技术。通过基于键在逻辑上分离数据,可以独立操作每个分区,例如删除。这允许用户在时间上或过期数据/从集群有效删除之间有效地在存储层之间移动分区,从而移动子集。在下面的示例中,我们删除了 2008 年的帖子。
SELECT DISTINCT partition
FROM system.parts
WHERE `table` = 'posts'
┌─partition─┐
│ 2008 │
│ 2009 │
│ 2010 │
│ 2011 │
│ 2012 │
│ 2013 │
│ 2014 │
│ 2015 │
│ 2016 │
│ 2017 │
│ 2018 │
│ 2019 │
│ 2020 │
│ 2021 │
│ 2022 │
│ 2023 │
│ 2024 │
└───────────┘
17 rows in set. Elapsed: 0.002 sec.
ALTER TABLE posts
(DROP PARTITION '2008')
Ok.
0 rows in set. Elapsed: 0.103 sec.
- 查询优化 - 虽然分区可以帮助提高查询性能,但这在很大程度上取决于访问模式。如果查询仅针对少数分区(理想情况下是一个),则性能可能会提高。仅当分区键不在主键中并且您按其进行过滤时,这通常才有用。但是,需要覆盖许多分区的查询可能比不使用分区时执行得更差(因为分区可能会导致更多部分)。如果分区键已经是主键中的早期条目,则针对单个分区的优势将变得不那么明显甚至不存在。如果每个分区中的值都是唯一的,则分区还可用于优化 GROUP BY 查询。但是,一般来说,用户应确保主键已优化,并且仅在访问模式访问特定可预测的子集(例如,按天分区,大多数查询在最近一天内)的特殊情况下才考虑将分区作为查询优化技术。
分区建议
用户应将分区视为数据管理技术。当需要从集群中过期数据以处理时间序列数据时,它是理想的选择,例如,可以简单地删除最旧的分区。
重要提示: 确保您的分区键表达式不会导致高基数集,即应避免创建超过 100 个分区。例如,不要按高基数列(例如客户端标识符或名称)对数据进行分区。相反,使客户端标识符或名称成为 ORDER BY 表达式中的第一列。
在内部,ClickHouse 为插入的数据创建部件。随着插入更多数据,部件的数量会增加。为了防止部件数量过多(这会降低查询性能(要读取的文件更多)),部件在后台异步进程中合并在一起。如果部件数量超过预配置的限制,则 ClickHouse 将在插入时抛出异常 - 作为“部件过多”错误。这在正常操作下不应发生,并且仅在 ClickHouse 配置错误或使用不正确(例如,许多小插入)时才会发生。
由于部件是按分区隔离创建的,因此增加分区数量会导致部件数量增加,即它是分区数量的倍数。因此,高基数分区键可能会导致此错误,应避免使用。
物化视图与投影
Postgres 允许在单个表上创建多个索引,从而为各种访问模式实现优化。这种灵活性使管理员和开发人员能够根据特定查询和操作需求定制数据库性能。ClickHouse 的投影概念虽然与此并不完全类似,但允许用户为表指定多个 ORDER BY 子句。
在 ClickHouse 数据建模文档中,我们探讨了如何在 ClickHouse 中使用物化视图来预计算聚合、转换行和优化不同访问模式的查询。
对于后者,我们提供了一个示例,其中物化视图将行发送到目标表,该目标表的排序键与接收插入的原始表不同。
例如,考虑以下查询
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.040 sec. Processed 90.38 million rows, 361.59 MB (2.25 billion rows/s., 9.01 GB/s.)
Peak memory usage: 201.93 MiB.
此查询需要扫描所有 9000 万行(当然很快),因为 UserId 不是排序键。以前,我们使用物化视图作为 PostId 的查找来解决此问题。同样的问题可以使用投影来解决。以下命令为 ORDER BY user_id 添加投影。
ALTER TABLE comments ADD PROJECTION comments_user_id (
SELECT * ORDER BY UserId
)
ALTER TABLE comments MATERIALIZE PROJECTION comments_user_id
请注意,我们必须首先创建投影,然后将其物化。后一个命令导致数据以两种不同的顺序在磁盘上存储两次。投影也可以在创建数据时定义,如下所示,并且将在插入数据时自动维护。
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String),
PROJECTION comments_user_id
(
SELECT *
ORDER BY UserId
)
)
ENGINE = MergeTree
ORDER BY PostId
如果投影是通过 ALTER 创建的,则当发出 MATERIALIZE PROJECTION 命令时,创建是异步的。用户可以使用以下查询确认此操作的进度,等待 is_done=1。
SELECT
parts_to_do,
is_done,
latest_fail_reason
FROM system.mutations
WHERE (`table` = 'comments') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
1. │ 1 │ 0 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.003 sec.
如果我们重复上述查询,我们可以看到性能显着提高,但代价是额外的存储空间。
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
1. │ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.008 sec. Processed 16.36 thousand rows, 98.17 KB (2.15 million rows/s., 12.92 MB/s.)
Peak memory usage: 4.06 MiB.
使用 EXPLAIN 命令,我们还可以确认投影已用于服务此查询
EXPLAIN indexes = 1
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Filter │
4. │ ReadFromMergeTree (comments_user_id) │
5. │ Indexes: │
6. │ PrimaryKey │
7. │ Keys: │
8. │ UserId │
9. │ Condition: (UserId in [8592047, 8592047]) │
10. │ Parts: 2/2 │
11. │ Granules: 2/11360 │
└─────────────────────────────────────────────────────┘
11 rows in set. Elapsed: 0.004 sec.
何时使用投影
对于新用户来说,投影是一个很有吸引力的功能,因为它们会在插入数据时自动维护。此外,查询只需发送到单个表,在可能的情况下会利用投影来加快响应时间。
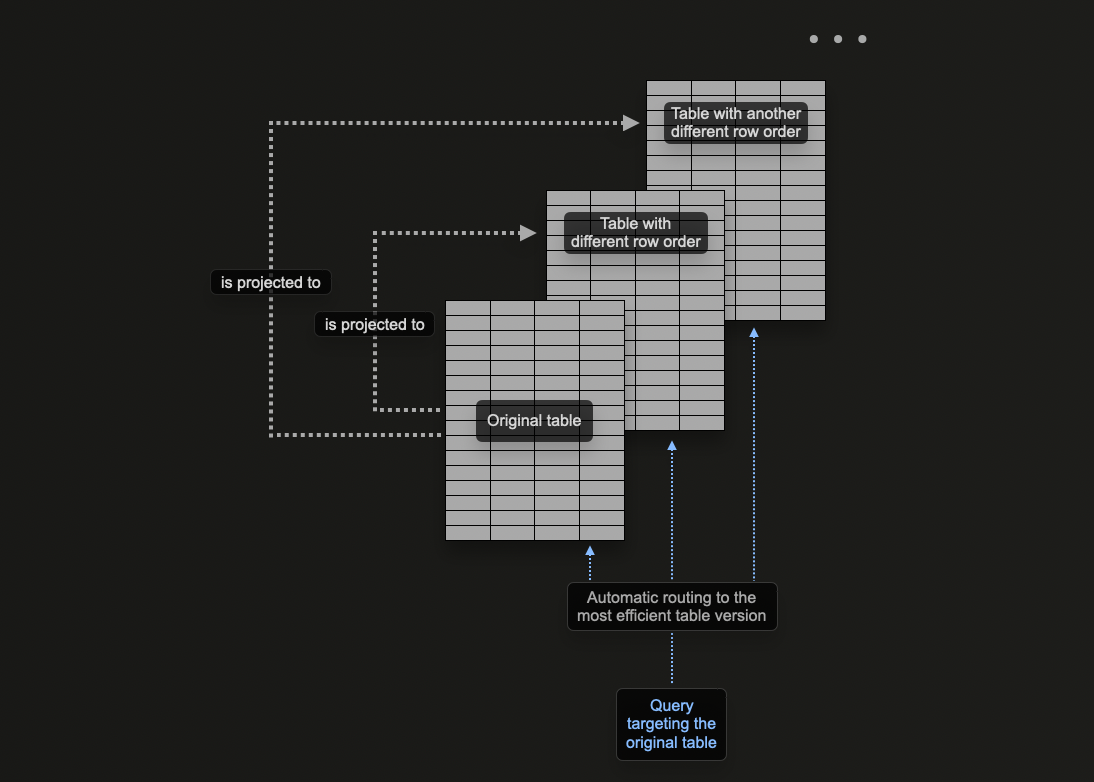
这与物化视图形成对比,在物化视图中,用户必须选择适当的优化目标表或重写其查询,具体取决于过滤器。这更加强调用户应用程序,并增加了客户端复杂性。
尽管有这些优点,但投影也存在一些固有的局限性,用户应注意这些局限性,因此应谨慎部署。
- 投影不允许为源表和(隐藏的)目标表使用不同的 TTL,而物化视图允许不同的 TTL。
- 投影当前不支持(隐藏的)目标表的
optimize_read_in_order。 - 轻量级更新和删除不支持带有投影的表。
- 物化视图可以链接:一个物化视图的目标表可以是另一个物化视图的源表,依此类推。投影不可能实现这一点。
- 投影不支持连接;物化视图支持。
- 投影不支持过滤器(WHERE 子句);物化视图支持。
我们建议在以下情况下使用投影
- 需要完全重新排序数据。虽然理论上投影中的表达式可以使用
GROUP BY,,但物化视图对于维护聚合更有效。查询优化器也更可能利用使用简单重新排序的投影,即SELECT * ORDER BY x。用户可以在此表达式中选择列的子集以减少存储占用空间。 - 用户可以接受相关的存储占用空间增加以及写入两次数据的开销。测试对插入速度的影响并评估存储开销。