使用 Kafka 表引擎
Kafka 表引擎在 ClickHouse Cloud 上不受支持。请考虑 ClickPipes 或 Kafka Connect
Kafka 到 ClickHouse
要使用 Kafka 表引擎,您应该大致熟悉 ClickHouse 物化视图。
概述
最初,我们专注于最常见的用例:使用 Kafka 表引擎将数据从 Kafka 插入到 ClickHouse 中。
Kafka 表引擎允许 ClickHouse 直接从 Kafka 主题读取数据。虽然对于查看主题上的消息很有用,但该引擎的设计仅允许一次性检索,即当向表发出查询时,它会从队列中消费数据并在将结果返回给调用者之前增加消费者偏移量。实际上,如果不重置这些偏移量,数据就无法被重新读取。
为了持久化从表引擎读取的这些数据,我们需要一种捕获数据并将其插入到另一个表的方法。基于触发器的物化视图原生提供了此功能。物化视图启动对表引擎的读取,接收批量的文档。“TO”子句确定了数据的目的地 - 通常是 MergeTree 系列 的表。此过程可视化如下
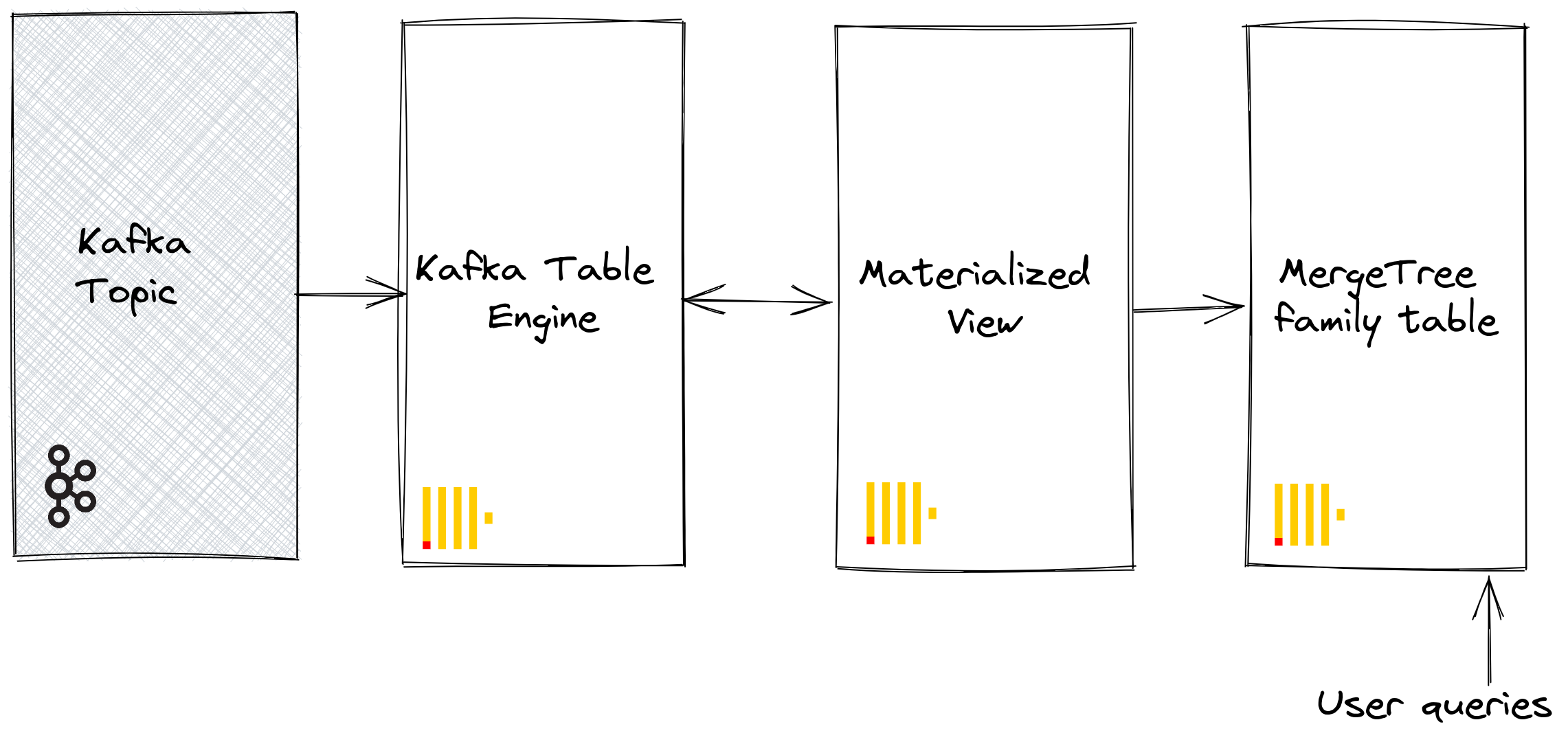
步骤
1. 准备
如果您的目标主题上已填充数据,您可以调整以下内容以用于您的数据集。或者,我们提供了一个示例 Github 数据集 此处。此数据集在以下示例中使用,并使用了缩减的模式和行的子集(具体来说,我们限制为关于 ClickHouse 仓库 的 Github 事件),与 此处 提供的完整数据集相比,为了简洁起见。这仍然足以让大多数 随数据集发布的查询 工作。
2. 配置 ClickHouse
如果您连接到安全的 Kafka,则需要执行此步骤。这些设置无法通过 SQL DDL 命令传递,必须在 ClickHouse config.xml 中配置。我们假设您正在连接到 SASL 安全的实例。这是与 Confluent Cloud 交互时最简单的方法。
<clickhouse>
<kafka>
<sasl_username>username</sasl_username>
<sasl_password>password</sasl_password>
<security_protocol>sasl_ssl</security_protocol>
<sasl_mechanisms>PLAIN</sasl_mechanisms>
</kafka>
</clickhouse>
将上述代码片段放置在 conf.d/ 目录下的新文件中,或将其合并到现有配置文件中。有关可以配置的设置,请参阅 此处。
我们还将创建一个名为 KafkaEngine 的数据库,在本教程中使用
CREATE DATABASE KafkaEngine;
创建数据库后,您需要切换到它
USE KafkaEngine;
3. 创建目标表
准备您的目标表。在下面的示例中,我们为了简洁起见使用了缩减的 GitHub 模式。请注意,尽管我们使用了 MergeTree 表引擎,但此示例可以轻松地适应 MergeTree 系列 的任何成员。
CREATE TABLE github
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)
4. 创建并填充主题
接下来,我们将创建一个主题。我们可以使用几种工具来做到这一点。如果我们在本地机器上或 Docker 容器中运行 Kafka,RPK 效果很好。我们可以通过运行以下命令创建一个名为 github 的主题,其中包含 5 个分区
rpk topic create -p 5 github --brokers <host>:<port>
如果我们在 Confluent Cloud 上运行 Kafka,我们可能更喜欢使用 Confluent CLI
confluent kafka topic create --if-not-exists github
现在我们需要用一些数据填充这个主题,我们将使用 kcat 来完成。如果我们在本地运行 Kafka 且禁用身份验证,我们可以运行类似于以下命令
cat github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
或者,如果我们的 Kafka 集群使用 SASL 进行身份验证,则使用以下命令
cat github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password> \
数据集包含 200,000 行,因此应该在几秒钟内被摄取。如果您想使用更大的数据集,请查看 大型数据集部分,该部分位于 ClickHouse/kafka-samples GitHub 仓库中。
5. 创建 Kafka 表引擎
以下示例创建了一个与 MergeTree 表具有相同模式的表引擎。这不是严格要求的,因为您可以在目标表中拥有别名或临时列。但是,设置很重要;请注意使用 JSONEachRow 作为从 Kafka 主题消费 JSON 的数据类型。值 github 和 clickhouse 分别表示主题名称和消费者组名称。主题实际上可以是值列表。
CREATE TABLE github_queue
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
)
ENGINE = Kafka('kafka_host:9092', 'github', 'clickhouse',
'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;
我们在下面讨论引擎设置和性能调优。此时,对表 github_queue 的简单选择应该读取一些行。请注意,这将向前移动消费者偏移量,从而阻止在没有 重置 的情况下重新读取这些行。请注意限制和必需参数 stream_like_engine_allow_direct_select.
6. 创建物化视图
物化视图将连接先前创建的两个表,从 Kafka 表引擎读取数据并将其插入到目标 MergeTree 表中。我们可以进行许多数据转换。我们将进行简单的读取和插入。使用 * 假设列名相同(区分大小写)。
CREATE MATERIALIZED VIEW github_mv TO github AS
SELECT *
FROM github_queue;
在创建时,物化视图连接到 Kafka 引擎并开始读取:将行插入到目标表中。此过程将无限期地继续,随后插入到 Kafka 的消息将被消费。随意重新运行插入脚本以将更多消息插入到 Kafka。
7. 确认行已插入
确认目标表中存在数据
SELECT count() FROM github;
您应该看到 200,000 行
┌─count()─┐
│ 200000 │
└─────────┘
常用操作
停止和重启消息消费
要停止消息消费,您可以分离 Kafka 引擎表
DETACH TABLE github_queue;
这不会影响消费者组的偏移量。要重启消费,并从之前的偏移量继续,请重新附加表。
ATTACH TABLE github_queue;
添加 Kafka 元数据
跟踪来自原始 Kafka 消息的元数据(在将其摄取到 ClickHouse 后)可能很有用。例如,我们可能想知道我们消费了特定主题或分区的多少。为此,Kafka 表引擎公开了几个虚拟列。通过修改我们的模式和物化视图的 select 语句,可以将这些列持久化为目标表中的列。
首先,在将列添加到目标表之前,我们执行上述停止操作。
DETACH TABLE github_queue;
下面我们添加信息列,以标识源主题和行来自的分区。
ALTER TABLE github
ADD COLUMN topic String,
ADD COLUMN partition UInt64;
接下来,我们需要确保虚拟列按需映射。虚拟列以 _ 为前缀。虚拟列的完整列表可以在 此处 找到。
要使用虚拟列更新我们的表,我们需要删除物化视图,重新附加 Kafka 引擎表,并重新创建物化视图。
DROP VIEW github_mv;
ATTACH TABLE github_queue;
CREATE MATERIALIZED VIEW github_mv TO github AS
SELECT *, _topic as topic, _partition as partition
FROM github_queue;
新消费的行应具有元数据。
SELECT actor_login, event_type, created_at, topic, partition
FROM github
LIMIT 10;
结果看起来像
| actor_login | event_type | created_at | topic | partition |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
修改 Kafka 引擎设置
我们建议删除 Kafka 引擎表并使用新设置重新创建它。在此过程中,不需要修改物化视图 - 一旦重新创建 Kafka 引擎表,消息消费将恢复。
调试问题
身份验证问题等错误不会在 Kafka 引擎 DDL 的响应中报告。为了诊断问题,我们建议使用主 ClickHouse 日志文件 clickhouse-server.err.log。可以通过配置启用底层 Kafka 客户端库 librdkafka 的进一步跟踪日志记录。
<kafka>
<debug>all</debug>
</kafka>
处理格式错误的消息
Kafka 通常用作数据的“倾倒场”。这导致主题包含混合的消息格式和不一致的字段名称。避免这种情况,并利用 Kafka 功能(如 Kafka Streams 或 ksqlDB)来确保消息在插入 Kafka 之前格式良好且一致。如果这些选项不可行,ClickHouse 有一些功能可以提供帮助。
- 将消息字段视为字符串。如果需要,可以在物化视图语句中使用函数来执行清理和类型转换。这不应代表生产解决方案,但可能有助于一次性摄取。
- 如果您从主题中消费 JSON,使用 JSONEachRow 格式,请使用设置
input_format_skip_unknown_fields。写入数据时,默认情况下,如果输入数据包含目标表中不存在的列,ClickHouse 会抛出异常。但是,如果启用此选项,这些多余的列将被忽略。同样,这也不是生产级别的解决方案,可能会使其他人感到困惑。 - 考虑设置
kafka_skip_broken_messages。这要求用户为每个块指定格式错误消息的容忍度级别 - 在 kafka_max_block_size 的上下文中考虑。如果超过此容忍度(以绝对消息数衡量),通常的异常行为将恢复,并且将跳过其他消息。
交付语义和重复项挑战
Kafka 表引擎具有至少一次语义。在几种已知的罕见情况下,可能会出现重复项。例如,可以从 Kafka 读取消息并成功插入到 ClickHouse 中。在新偏移量可以提交之前,与 Kafka 的连接丢失。在这种情况下,需要重试该块。可以使用分布式表或 ReplicatedMergeTree 作为目标表 去重 该块。虽然这减少了重复行的机会,但它依赖于相同的块。Kafka 重新平衡等事件可能会使此假设失效,从而在极少数情况下导致重复项。
基于仲裁的插入
对于 ClickHouse 中需要更高交付保证的情况,您可能需要 基于仲裁的插入。这不能在物化视图或目标表上设置。但是,可以为用户配置文件设置它,例如
<profiles>
<default>
<insert_quorum>2</insert_quorum>
</default>
</profiles>
ClickHouse 到 Kafka
虽然用例较少见,但 ClickHouse 数据也可以持久化在 Kafka 中。例如,我们将手动将行插入到 Kafka 表引擎中。此数据将由相同的 Kafka 引擎读取,其物化视图会将数据放入 MergeTree 表中。最后,我们演示了物化视图在插入 Kafka 中以从现有源表读取表的应用。
步骤
我们的初始目标最好通过下图说明
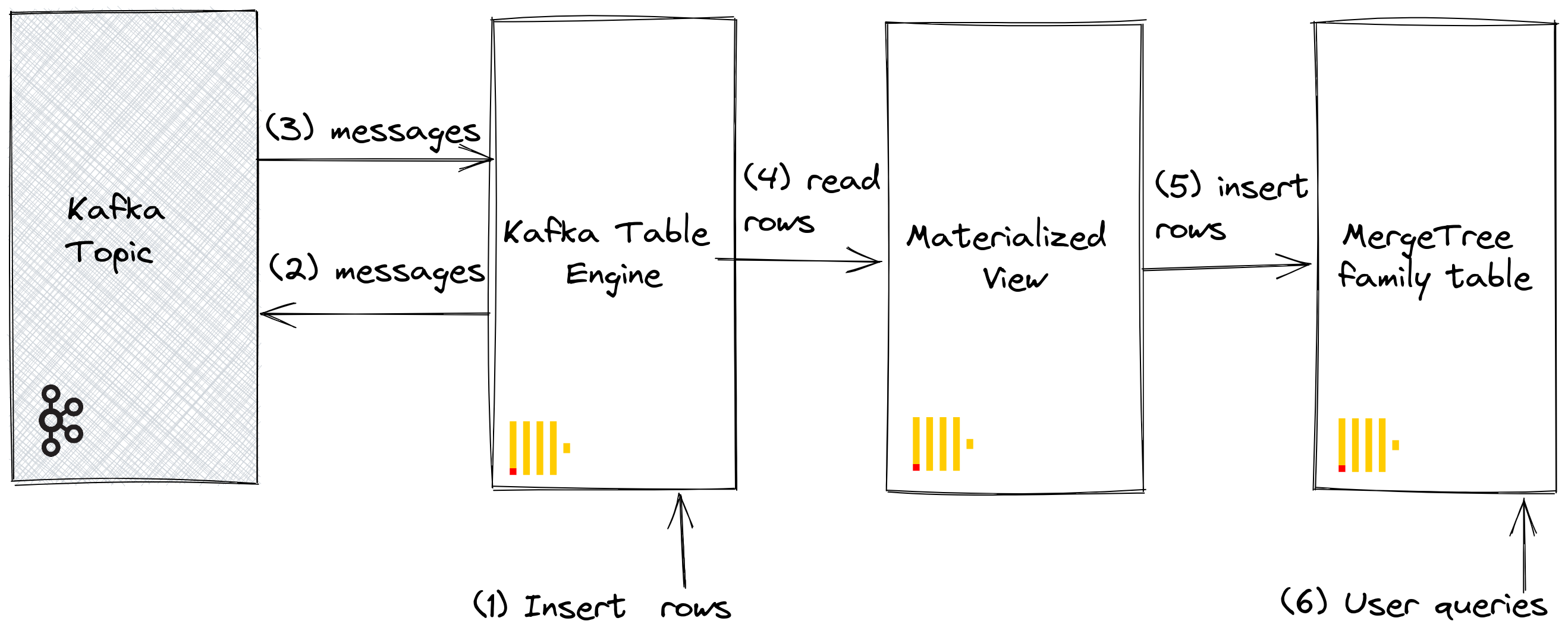
我们假设您已创建了 Kafka 到 ClickHouse 的步骤下的表和视图,并且主题已完全消费。
1. 直接插入行
首先,确认目标表的计数。
SELECT count() FROM github;
您应该有 200,000 行
┌─count()─┐
│ 200000 │
└─────────┘
现在将行从 GitHub 目标表插回 Kafka 表引擎 github_queue。请注意我们如何利用 JSONEachRow 格式并 LIMIT 选择为 100。
INSERT INTO github_queue SELECT * FROM github LIMIT 100 FORMAT JSONEachRow
重新计算 GitHub 中的行,以确认它增加了 100 行。如上图所示,行已通过 Kafka 表引擎插入到 Kafka 中,然后再由同一引擎重新读取,并通过我们的物化视图插入到 GitHub 目标表中!
SELECT count() FROM github;
您应该看到另外 100 行
┌─count()─┐
│ 200100 │
└─────────┘
2. 使用物化视图
当文档插入到表中时,我们可以利用物化视图将消息推送到 Kafka 引擎(和一个主题)。当行插入到 GitHub 表中时,会触发物化视图,这会导致行被插回 Kafka 引擎并插入到一个新主题中。同样,最好通过下图说明
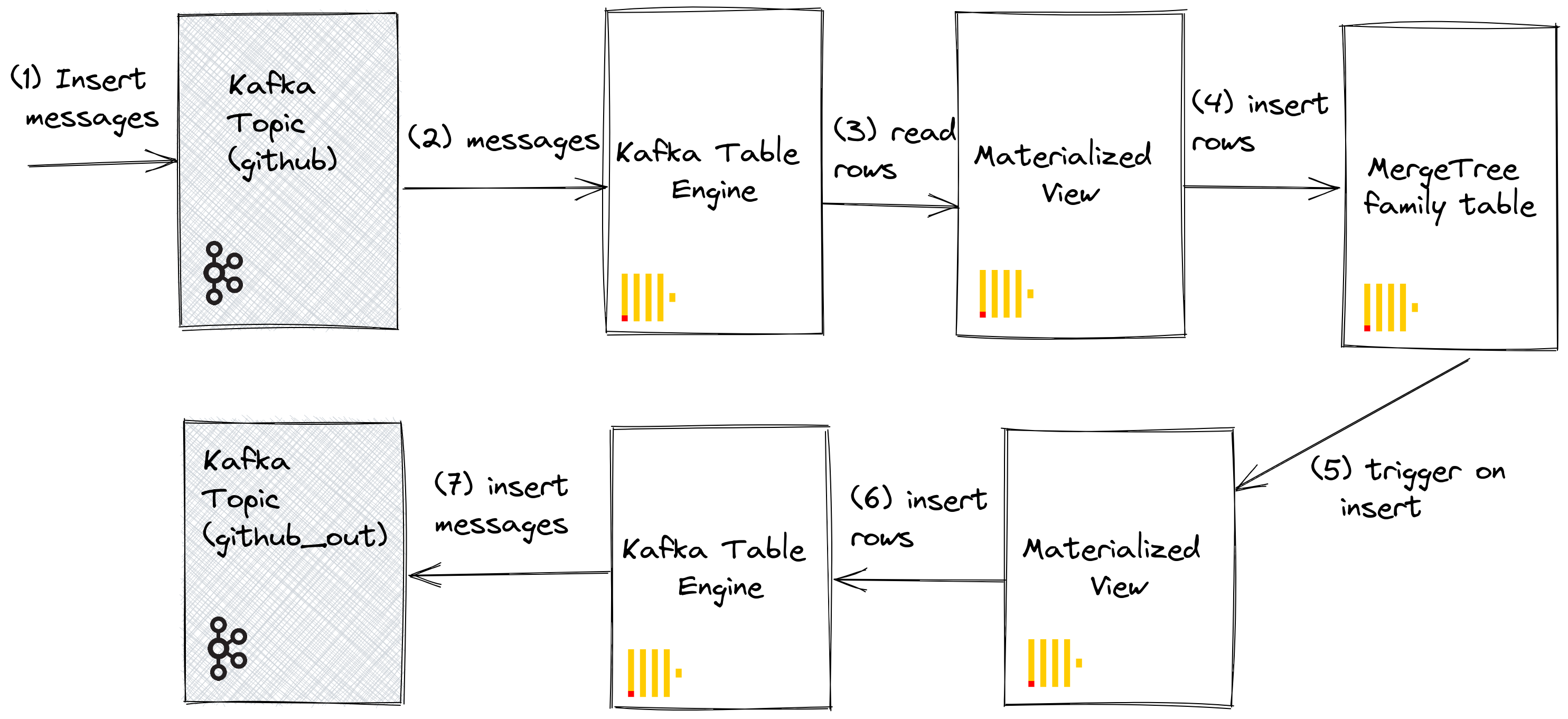
创建一个新的 Kafka 主题 github_out 或等效主题。确保 Kafka 表引擎 github_out_queue 指向此主题。
CREATE TABLE github_out_queue
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
)
ENGINE = Kafka('host:port', 'github_out', 'clickhouse_out',
'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;
现在创建一个新的物化视图 github_out_mv 以指向 GitHub 表,当它触发时将行插入到上述引擎。因此,添加到 GitHub 表的内容将被推送到我们的新 Kafka 主题。
CREATE MATERIALIZED VIEW github_out_mv TO github_out_queue AS
SELECT file_time, event_type, actor_login, repo_name,
created_at, updated_at, action, comment_id, path,
ref, ref_type, creator_user_login, number, title,
labels, state, assignee, assignees, closed_at, merged_at,
merge_commit_sha, requested_reviewers, merged_by,
review_comments, member_login
FROM github
FORMAT JsonEachRow;
如果您插入到作为 Kafka 到 ClickHouse 一部分创建的原始 github 主题,文档将神奇地出现在“github_clickhouse”主题中。使用原生 Kafka 工具确认这一点。例如,在下面,我们使用 kcat 为 Confluent Cloud 托管的主题将 100 行插入到 github 主题上
head -n 10 github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password>
对 github_out 主题的读取应确认消息的交付。
kcat -C \
-b <host>:<port> \
-t github_out \
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password> \
-e -q |
wc -l
虽然这是一个详尽的示例,但它说明了物化视图与 Kafka 引擎结合使用时的强大功能。
集群和性能
使用 ClickHouse 集群
通过 Kafka 消费者组,多个 ClickHouse 实例可以潜在地从同一主题读取数据。每个消费者将在 1:1 映射中分配给主题分区。当使用 Kafka 表引擎扩展 ClickHouse 消费时,请考虑集群内的消费者总数不能超过主题上的分区数。因此,请提前确保为主题正确配置分区。
可以使用在 Kafka 表引擎创建期间指定的相同消费者组 ID,将多个 ClickHouse 实例配置为从主题读取数据。因此,每个实例将从一个或多个分区读取数据,并将段插入到其本地目标表中。反过来,目标表可以配置为使用 ReplicatedMergeTree 来处理数据的重复。如果 Kafka 分区充足,则此方法允许使用 ClickHouse 集群扩展 Kafka 读取。
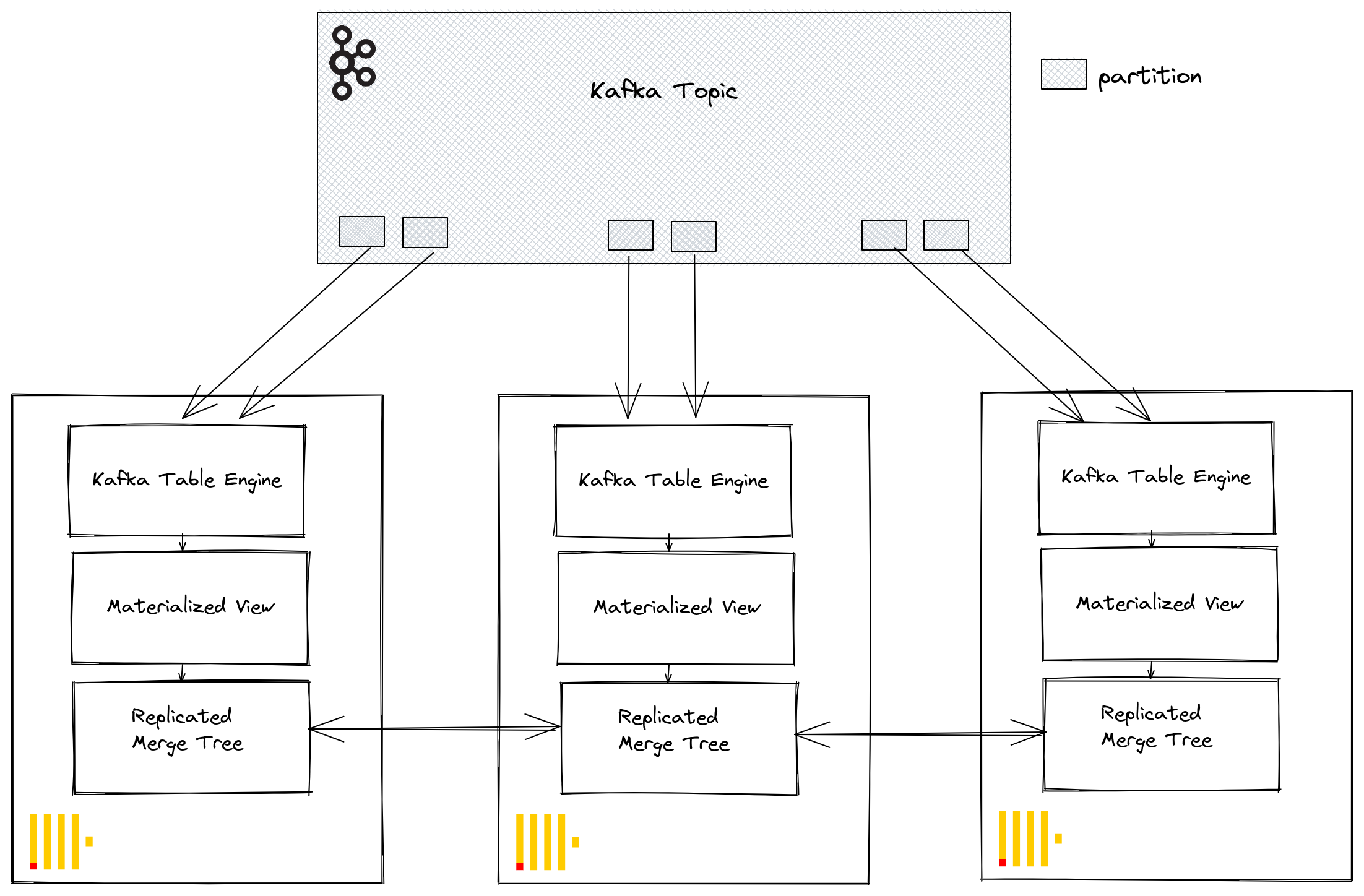
调优性能
在寻求提高 Kafka 引擎表吞吐量性能时,请考虑以下事项
- 性能将因消息大小、格式和目标表类型而异。在单个表引擎上,10 万行/秒的吞吐量应被认为是可实现的。默认情况下,消息以块读取,由参数 kafka_max_block_size 控制。默认情况下,此参数设置为 max_insert_block_size,默认为 1,048,576。除非消息非常大,否则几乎总是应该增加此值。50 万到 100 万之间的值并不少见。测试并评估对吞吐量性能的影响。
- 可以使用 kafka_num_consumers 增加表引擎的消费者数量。但是,默认情况下,除非将 kafka_thread_per_consumer 从默认值 1 更改,否则插入将在单个线程中线性化。将其设置为 1 以确保并行执行刷新。请注意,创建具有 N 个消费者(和 kafka_thread_per_consumer=1)的 Kafka 引擎表在逻辑上等同于创建 N 个 Kafka 引擎,每个引擎都具有物化视图和 kafka_thread_per_consumer=0。
- 增加消费者数量不是免费操作。每个消费者都维护自己的缓冲区和线程,从而增加服务器的开销。注意消费者的开销,并尽可能首先在集群中线性扩展,如果可能的话。
- 如果 Kafka 消息的吞吐量是可变的并且延迟是可接受的,请考虑增加 stream_flush_interval_ms 以确保刷新更大的块。
- background_message_broker_schedule_pool_size 设置执行后台任务的线程数。这些线程用于 Kafka 流式传输。此设置在 ClickHouse 服务器启动时应用,并且无法在用户会话中更改,默认为 16。如果您在日志中看到超时,则可能需要增加此值。
- 对于与 Kafka 的通信,使用了 librdkafka 库,该库本身会创建线程。因此,大量的 Kafka 表或消费者可能会导致大量的上下文切换。要么在集群中分配此负载,仅在可能的情况下复制目标表,要么考虑使用表引擎从多个主题读取数据 - 支持值列表。可以从单个表读取多个物化视图,每个物化视图都过滤来自特定主题的数据。
任何设置更改都应经过测试。我们建议监控 Kafka 消费者滞后,以确保您已正确扩展。
其他设置
除了上面讨论的设置外,以下设置可能也很有趣
- Kafka_max_wait_ms - 从 Kafka 读取消息后重试的等待时间(以毫秒为单位)。在用户配置文件级别设置,默认为 5000。
来自底层 librdkafka 的所有设置 也可以放置在 ClickHouse 配置文件中的 kafka 元素内 - 设置名称应为 XML 元素,句点替换为下划线,例如
<clickhouse>
<kafka>
<enable_ssl_certificate_verification>false</enable_ssl_certificate_verification>
</kafka>
</clickhouse>
这些是专家设置,我们建议您参考 Kafka 文档以获得深入解释。