ClickHouse Kafka Connect Sink
如果您需要任何帮助,请在存储库中提交 issue或在ClickHouse 公共 Slack 中提出问题。
ClickHouse Kafka Connect Sink 是 Kafka 连接器,用于将数据从 Kafka 主题传递到 ClickHouse 表。
许可证
Kafka Connector Sink 根据 Apache 2.0 许可证 分发
环境要求
环境中应安装 Kafka Connect 框架 v2.7 或更高版本。
版本兼容性矩阵
| ClickHouse Kafka Connect 版本 | ClickHouse 版本 | Kafka Connect | Confluent 平台 |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
主要功能
- 附带开箱即用的精确一次语义。它由名为 KeeperMap(用作连接器的状态存储)的新 ClickHouse 核心功能提供支持,并允许极简架构。
- 支持第三方状态存储:当前默认为内存,但可以使用 KeeperMap(Redis 即将添加)。
- 核心集成:由 ClickHouse 构建、维护和支持。
- 针对 ClickHouse Cloud 进行持续测试。
- 使用声明的模式和无模式的数据插入。
- 支持 ClickHouse 的所有数据类型。
安装说明
收集您的连接详细信息
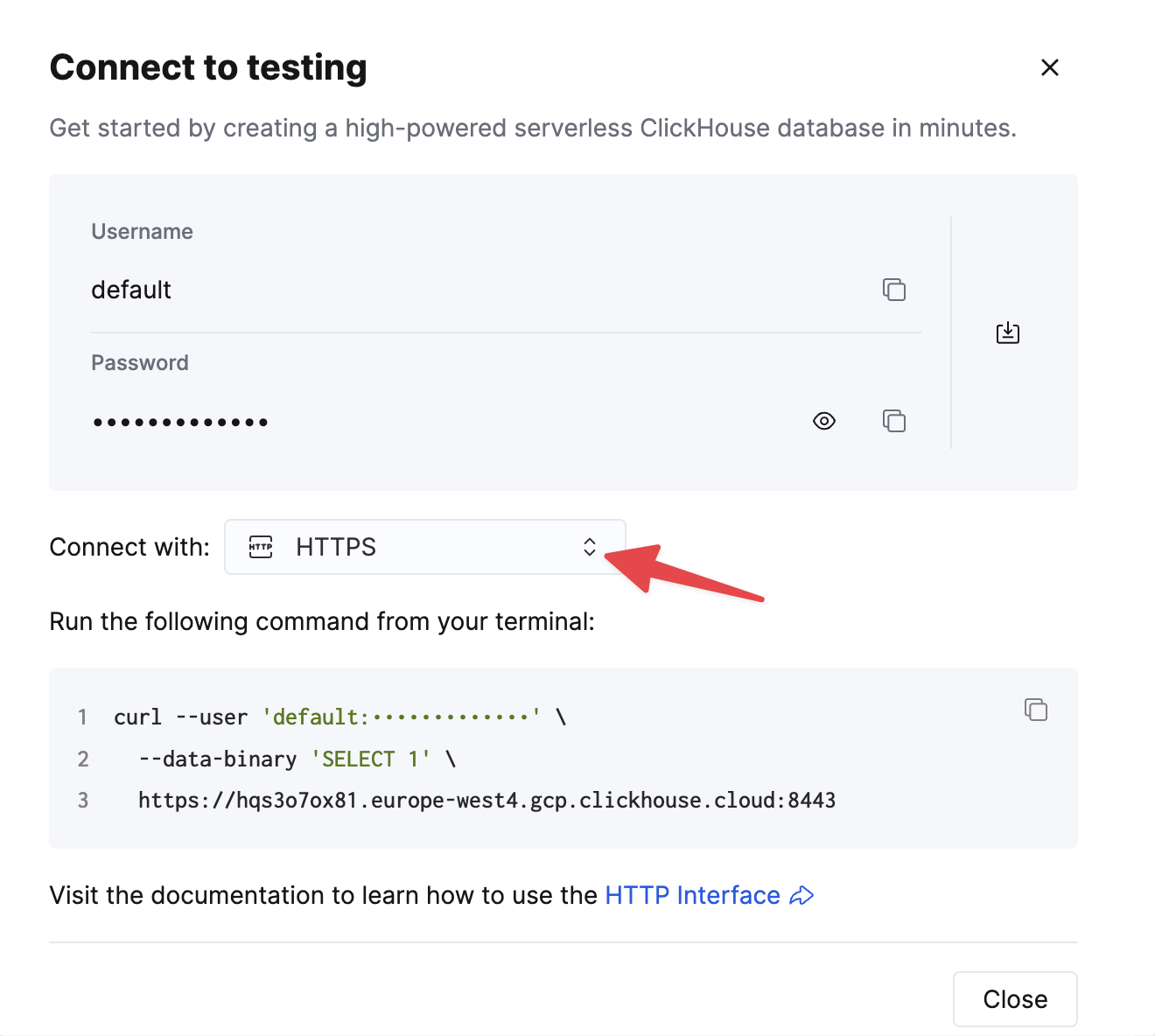
要使用 HTTP(S) 连接到 ClickHouse,您需要以下信息
-
HOST 和 PORT:通常,使用 TLS 时端口为 8443,不使用 TLS 时端口为 8123。
-
DATABASE NAME:开箱即用,有一个名为
default的数据库,请使用您要连接的数据库的名称。 -
USERNAME 和 PASSWORD:开箱即用,用户名是
default。使用适合您用例的用户名。
您的 ClickHouse Cloud 服务的详细信息可在 ClickHouse Cloud 控制台中找到。选择您将连接到的服务,然后单击 连接
选择 HTTPS,详细信息将在 curl 命令示例中提供。
如果您使用的是自托管 ClickHouse,则连接详细信息由您的 ClickHouse 管理员设置。
通用安装说明
连接器以单个 JAR 文件形式分发,其中包含运行插件所需的所有类文件。
要安装插件,请按照以下步骤操作
- 从 ClickHouse Kafka Connect Sink 存储库的 Releases 页面下载包含 Connector JAR 文件的 zip 压缩包。
- 解压 ZIP 文件内容并将其复制到所需位置。
- 在您的 Connect 属性文件中,将包含插件目录的路径添加到 plugin.path 配置,以允许 Confluent Platform 找到插件。
- 在配置中提供主题名称、ClickHouse 实例主机名和密码。
connector.class=com.clickhouse.kafka.connect.ClickHouseSinkConnector
tasks.max=1
topics=<topic_name>
ssl=true
jdbcConnectionProperties=?sslmode=STRICT
security.protocol=SSL
hostname=<hostname>
database=<database_name>
password=<password>
ssl.truststore.location=/tmp/kafka.client.truststore.jks
port=8443
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
exactlyOnce=true
username=default
schemas.enable=false
- 重启 Confluent Platform。
- 如果您使用 Confluent Platform,请登录 Confluent Control Center UI 以验证 ClickHouse Sink 是否在可用连接器列表中。
配置选项
要将 ClickHouse Sink 连接到 ClickHouse 服务器,您需要提供
- 连接详细信息:主机名(必需)和端口(可选)
- 用户凭据:密码(必需)和用户名(可选)
- 连接器类:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(必需) - topics 或 topics.regex:要轮询的 Kafka 主题 - 主题名称必须与表名称匹配(必需)
- 键和值转换器:根据您的主题上的数据类型设置。如果工作配置中尚未定义,则为必需。
配置选项的完整表格
| 属性名称 | 描述 | 默认值 |
|---|---|---|
hostname(必需) | 服务器的主机名或 IP 地址 | N/A |
端口 | ClickHouse 端口 - 默认值为 8443(用于云中的 HTTPS),但对于 HTTP(自托管的默认值),应为 8123 | 8443 |
ssl | 启用与 ClickHouse 的 ssl 连接 | true |
jdbcConnectionProperties | 连接到 Clickhouse 时的连接属性。必须以 ? 开头,并在 param=value 之间用 & 连接 | "" |
username | ClickHouse 数据库用户名 | default |
password(必需) | ClickHouse 数据库密码 | N/A |
database | ClickHouse 数据库名称 | default |
connector.class(必需) | 连接器类(显式设置并保留为默认值) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | 连接器任务的数量 | "1" |
errors.retry.timeout | ClickHouse JDBC 重试超时 | "60" |
exactlyOnce | 启用精确一次 | "false" |
topics(必需) | 要轮询的 Kafka 主题 - 主题名称必须与表名称匹配 | "" |
key.converter(必需* - 请参阅描述) | 根据您的键的类型设置。如果您正在传递键(并且未在工作配置中定义),则此处为必需。 | "org.apache.kafka.connect.storage.StringConverter" |
value.converter(必需* - 请参阅描述) | 根据您的主题上的数据类型设置。支持:- JSON、String、Avro 或 Protobuf 格式。如果工作配置中未定义,则此处为必需。 | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | 连接器值转换器模式支持 | "false" |
errors.tolerance | 连接器错误容忍度。支持:none, all | "none" |
errors.deadletterqueue.topic.name | 如果设置(errors.tolerance=all),则 DLQ 将用于失败的批次(请参阅故障排除) | "" |
errors.deadletterqueue.context.headers.enable | 为 DLQ 添加其他标头 | "" |
clickhouseSettings | 以逗号分隔的 ClickHouse 设置列表(例如,“insert_quorum=2, etc...”) | "" |
topic2TableMap | 以逗号分隔的列表,将主题名称映射到表名称(例如,“topic1=table1, topic2=table2, etc...”) | "" |
tableRefreshInterval | 刷新表定义缓存的时间(以秒为单位) | 0 |
keeperOnCluster | 允许为自托管实例配置 ON CLUSTER 参数(例如,ON CLUSTER clusterNameInConfigFileDefinition),用于精确一次的 connect_state 表(请参阅分布式 DDL 查询 | "" |
bypassRowBinary | 允许禁用 RowBinary 和 RowBinaryWithDefaults 用于基于 Schema 的数据(Avro、Protobuf 等)- 仅应在数据缺少列且 Nullable/Default 不可接受时使用 | "false" |
dateTimeFormats | 用于解析 DateTime64 模式字段的日期时间格式,以 ; 分隔(例如,someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss)。 | "" |
tolerateStateMismatch | 允许连接器删除比存储在 AFTER_PROCESSING 中的当前偏移量“更早”的记录(例如,如果发送偏移量 5,而偏移量 250 是上次记录的偏移量) | "false" |
目标表
ClickHouse Connect Sink 从 Kafka 主题读取消息并将它们写入到适当的表。ClickHouse Connect Sink 将数据写入到现有表。请确保在 ClickHouse 中创建具有适当模式的目标表,然后再开始向其中插入数据。
每个主题都需要 ClickHouse 中的专用目标表。目标表名称必须与源主题名称匹配。
预处理
如果您需要在出站消息发送到 ClickHouse Kafka Connect Sink 之前对其进行转换,请使用 Kafka Connect Transformations。
支持的数据类型
使用声明的模式
| Kafka Connect 类型 | ClickHouse 类型 | 支持 | 原始类型 |
|---|---|---|---|
| STRING | String | ✅ | 是 |
| INT8 | Int8 | ✅ | 是 |
| INT16 | Int16 | ✅ | 是 |
| INT32 | Int32 | ✅ | 是 |
| INT64 | Int64 | ✅ | 是 |
| FLOAT32 | Float32 | ✅ | 是 |
| FLOAT64 | Float64 | ✅ | 是 |
| BOOLEAN | Boolean | ✅ | 是 |
| ARRAY | Array(T) | ✅ | 否 |
| MAP | Map(Primitive, T) | ✅ | 否 |
| STRUCT | Variant(T1, T2, …) | ✅ | 否 |
| STRUCT | Tuple(a T1, b T2, …) | ✅ | 否 |
| STRUCT | Nested(a T1, b T2, …) | ✅ | 否 |
| BYTES | String | ✅ | 否 |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | 否 |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | 否 |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | 否 |
没有声明的模式
记录被转换为 JSON 并以 JSONEachRow 格式作为值发送到 ClickHouse。
配置方案
这些是一些常见的配置方案,可让您快速入门。
基本配置
让您入门的最基本配置 - 它假定您在分布式模式下运行 Kafka Connect,并且 ClickHouse 服务器在启用了 SSL 的 localhost:8443 上运行,数据采用无模式 JSON 格式。
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
"tasks.max": "1",
"consumer.override.max.poll.records": "5000",
"consumer.override.max.partition.fetch.bytes": "5242880",
"database": "default",
"errors.retry.timeout": "60",
"exactlyOnce": "false",
"hostname": "localhost",
"port": "8443",
"ssl": "true",
"jdbcConnectionProperties": "?ssl=true&sslmode=strict",
"username": "default",
"password": "<PASSWORD>",
"topics": "<TOPIC_NAME>",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"clickhouseSettings": ""
}
}
具有多个主题的基本配置
连接器可以从多个主题消费数据
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"topics": "SAMPLE_TOPIC, ANOTHER_TOPIC, YET_ANOTHER_TOPIC",
...
}
}
具有 DLQ 的基本配置
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "<DLQ_TOPIC>",
"errors.deadletterqueue.context.headers.enable": "true",
}
}
与不同的数据格式一起使用
Avro 模式支持
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
Protobuf 模式支持
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.protobuf.ProtobufConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
请注意:如果您遇到缺少类的问题,并非每个环境都附带 protobuf 转换器,您可能需要捆绑依赖项的 jar 的备用版本。
JSON 模式支持
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
}
}
String 支持
连接器在不同的 ClickHouse 格式中支持 String Converter:JSON、CSV 和 TSV。
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"customInsertFormat": "true",
"insertFormat": "CSV"
}
}
日志记录
日志记录由 Kafka Connect Platform 自动提供。日志记录目标和格式可以通过 Kafka connect 配置文件 进行配置。
如果使用 Confluent Platform,则可以通过运行 CLI 命令查看日志
confluent local services connect log
有关更多详细信息,请查看官方教程。
监控
ClickHouse Kafka Connect 通过 Java Management Extensions (JMX) 报告运行时指标。JMX 默认在 Kafka Connector 中启用。
ClickHouse Connect MBeanName
com.clickhouse:type=ClickHouseKafkaConnector,name=SinkTask{id}
ClickHouse Kafka Connect 报告以下指标
| 名称 | 类型 | 描述 |
|---|---|---|
receivedRecords | long | 接收到的记录总数。 |
recordProcessingTime | long | 用于对记录进行分组和转换为统一结构的总时间(以纳秒为单位)。 |
taskProcessingTime | long | 用于处理并将数据插入 ClickHouse 的总时间(以纳秒为单位)。 |
限制
- 不支持删除。
- 批处理大小继承自 Kafka Consumer 属性。
- 当使用 KeeperMap 进行精确一次,并且偏移量已更改或重新绕回时,您需要删除 KeeperMap 中针对该特定主题的内容。(有关更多详细信息,请参阅下面的故障排除指南)
性能调优
如果您曾经想过“我想调整 sink 连接器的批处理大小”,那么本节适合您。
Connect Fetch 与 Connector Poll
Kafka Connect(我们的 sink 连接器构建于其上的框架)将在后台从 kafka 主题中获取消息(独立于连接器)。
您可以使用 fetch.min.bytes 和 fetch.max.bytes 控制此过程 - 虽然 fetch.min.bytes 设置了框架将值传递给连接器之前所需的最小量(最长为 fetch.max.wait.ms 设置的时间限制),但 fetch.max.bytes 设置了上限大小限制。如果您想将更大的批次传递给连接器,一种选择可能是增加最小获取量或最大等待时间以构建更大的数据包。
然后,此获取的数据由连接器客户端轮询消息来消费,其中每次轮询的数量由 max.poll.records 控制 - 请注意,获取独立于轮询!
在调整这些设置时,用户应以其获取大小产生多个 max.poll.records 批次为目标(并记住,设置 fetch.min.bytes 和 fetch.max.bytes 表示压缩数据)- 这样,每个连接器任务都插入尽可能大的批次。
ClickHouse 针对较大的批次进行了优化,即使有轻微的延迟,也优于频繁但较小的批次 - 批次越大越好。
consumer.max.poll.records=5000
consumer.max.partition.fetch.bytes=5242880
更多详细信息可以在 Confluent 文档 或 Kafka 文档 中找到。
多个高吞吐量主题
如果您的连接器配置为订阅多个主题,您正在使用 topics2TableMap 将主题映射到表,并且您在插入时遇到瓶颈,导致消费者滞后,请考虑为每个主题创建一个连接器。发生这种情况的主要原因是,目前批次是串行插入到每个表中的。
为每个主题创建一个连接器是一种解决方法,可确保您获得最快的插入速率。
故障排除
“主题 [someTopic] 分区 [0] 的状态不匹配”
当 KeeperMap 中存储的偏移量与 Kafka 中存储的偏移量不同时,通常在主题已删除或偏移量已手动调整时,会发生这种情况。要解决此问题,您需要删除为给定主题 + 分区存储的旧值。
注意:此调整可能具有精确一次的含义。
“连接器将重试哪些错误?”
目前,重点是识别瞬态且可以重试的错误,包括
ClickHouseException- 这是 ClickHouse 可能抛出的通用异常。通常在服务器过载时抛出,以下错误代码被认为是特别瞬态的- 3 - UNEXPECTED_END_OF_FILE
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
- 1002 - UNKNOWN_EXCEPTION
SocketTimeoutException- 当套接字超时时抛出此异常。UnknownHostException- 当无法解析主机时抛出此异常。IOException- 当网络出现问题时抛出此异常。
“我的所有数据都是空白/零”
可能是您数据中的字段与表中的字段不匹配 - 这在 CDC(和 Debezium 格式)中尤其常见。一种常见的解决方案是将 flatten 转换添加到您的连接器配置中
transforms=flatten
transforms.flatten.type=org.apache.kafka.connect.transforms.Flatten$Value
transforms.flatten.delimiter=_
这会将您的数据从嵌套 JSON 转换为扁平化 JSON(使用 _ 作为分隔符)。然后,表中的字段将遵循“field1_field2_field3”格式(即“before_id”、“after_id”等)。
“我想在 ClickHouse 中使用我的 Kafka 键”
默认情况下,Kafka 键不存储在值字段中,但您可以使用 KeyToValue 转换将键移动到值字段(在新的 _key 字段名称下)
transforms=keyToValue
transforms.keyToValue.type=com.clickhouse.kafka.connect.transforms.KeyToValue
transforms.keyToValue.field=_key