Confluent HTTP Sink 连接器
HTTP Sink 连接器与数据类型无关,因此不需要 Kafka schema,并且支持 ClickHouse 特定的数据类型,例如 Maps 和 Arrays。这种额外的灵活性带来的是配置复杂性略有增加。
下面我们描述一个简单的安装,从单个 Kafka 主题中拉取消息并将行插入到 ClickHouse 表中。
HTTP 连接器根据 Confluent 企业许可证分发。
快速入门步骤
1. 收集您的连接详细信息
要使用 HTTP(S) 连接到 ClickHouse,您需要以下信息
-
主机和端口:通常,使用 TLS 时端口为 8443,不使用 TLS 时端口为 8123。
-
数据库名称:开箱即用,有一个名为
default的数据库,使用您要连接的数据库的名称。 -
用户名和密码:开箱即用,用户名是
default。使用适合您用例的用户名。
您的 ClickHouse Cloud 服务的详细信息在 ClickHouse Cloud 控制台中可用。选择您要连接的服务,然后单击**连接**
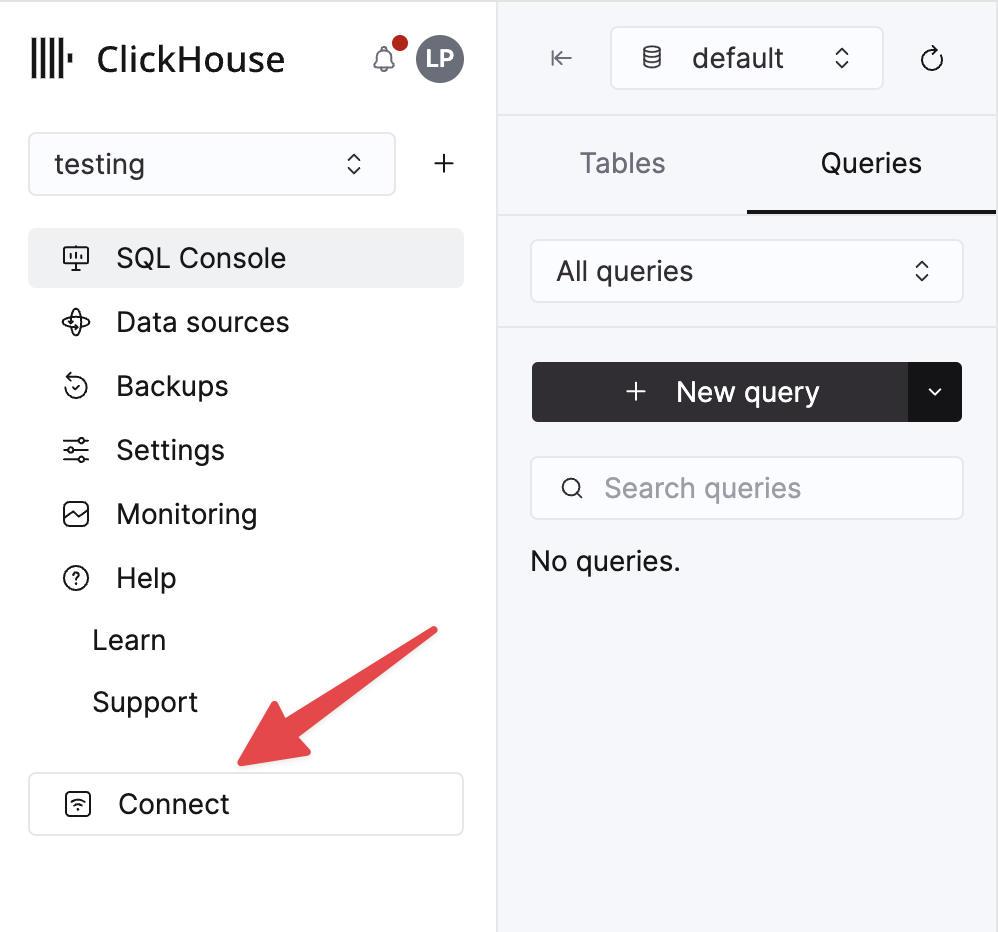
选择 **HTTPS**,详细信息在示例 curl 命令中提供。
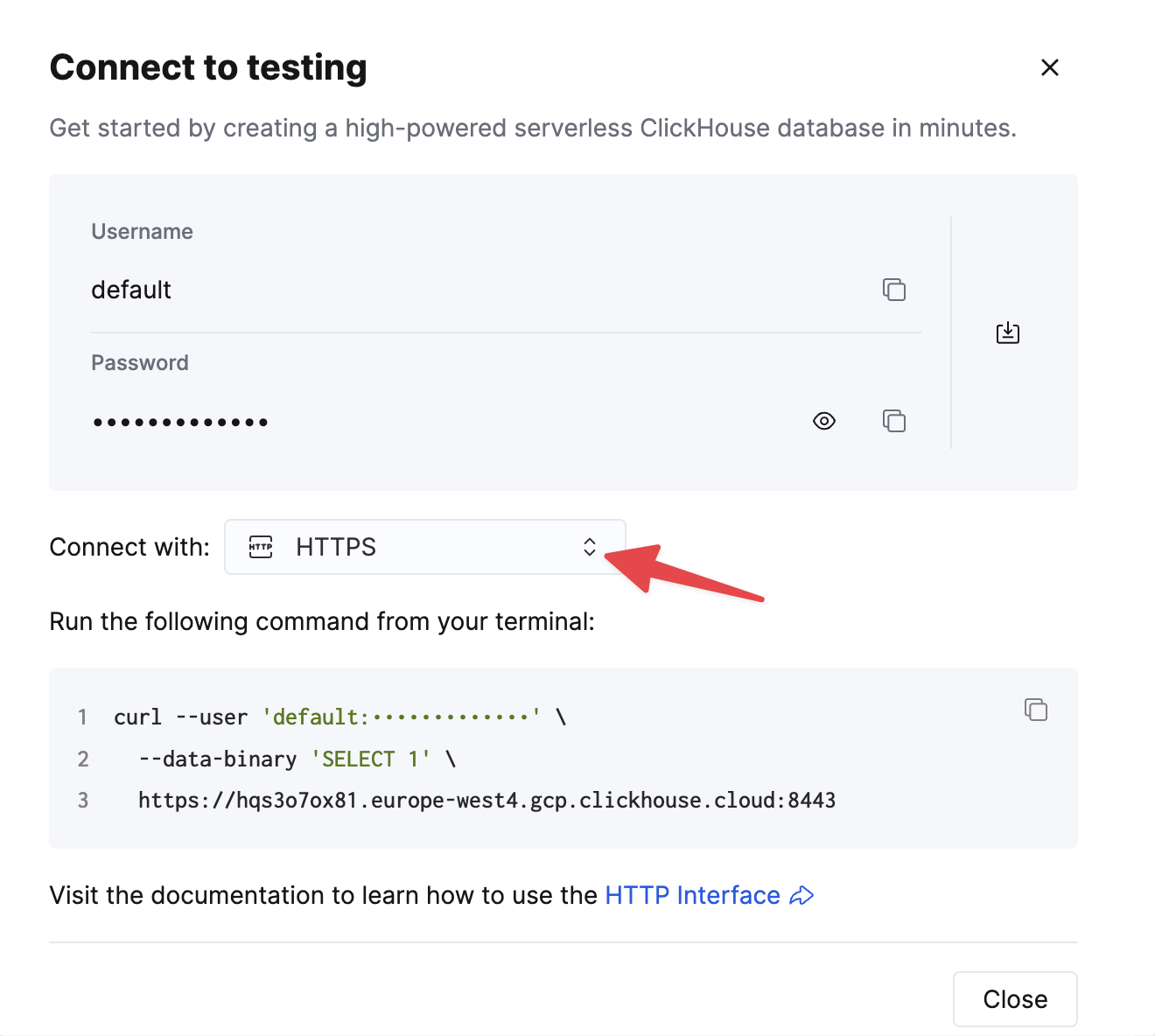
如果您使用的是自托管的 ClickHouse,则连接详细信息由您的 ClickHouse 管理员设置。
2. 运行 Kafka Connect 和 HTTP Sink 连接器
您有两个选项
-
自托管:下载 Confluent 包并在本地安装。按照此处记录的连接器安装说明进行安装。如果您使用 confluent-hub 安装方法,您的本地配置文件将被更新。
-
Confluent Cloud:对于那些使用 Confluent Cloud 进行 Kafka 托管的用户,可以使用完全托管版本的 HTTP Sink。这要求您的 ClickHouse 环境可以从 Confluent Cloud 访问。
以下示例使用 Confluent Cloud。
3. 在 ClickHouse 中创建目标表
在连接测试之前,让我们首先在 ClickHouse Cloud 中创建一个测试表,该表将接收来自 Kafka 的数据
CREATE TABLE default.my_table
(
`side` String,
`quantity` Int32,
`symbol` String,
`price` Int32,
`account` String,
`userid` String
)
ORDER BY tuple()
4. 配置 HTTP Sink
创建一个 Kafka 主题和一个 HTTP Sink 连接器实例
配置 HTTP Sink 连接器
- 提供您创建的主题名称
- 身份验证
HTTP Url- ClickHouse Cloud URL,其中指定了 INSERT 查询<protocol>://<clickhouse_host>:<clickhouse_port>?query=INSERT%20INTO%20<database>.<table>%20FORMAT%20JSONEachRow。 注意:查询必须进行编码。Endpoint Authentication type- BASICAuth username- ClickHouse 用户名Auth password- ClickHouse 密码
此 HTTP Url 容易出错。确保精确转义以避免问题。
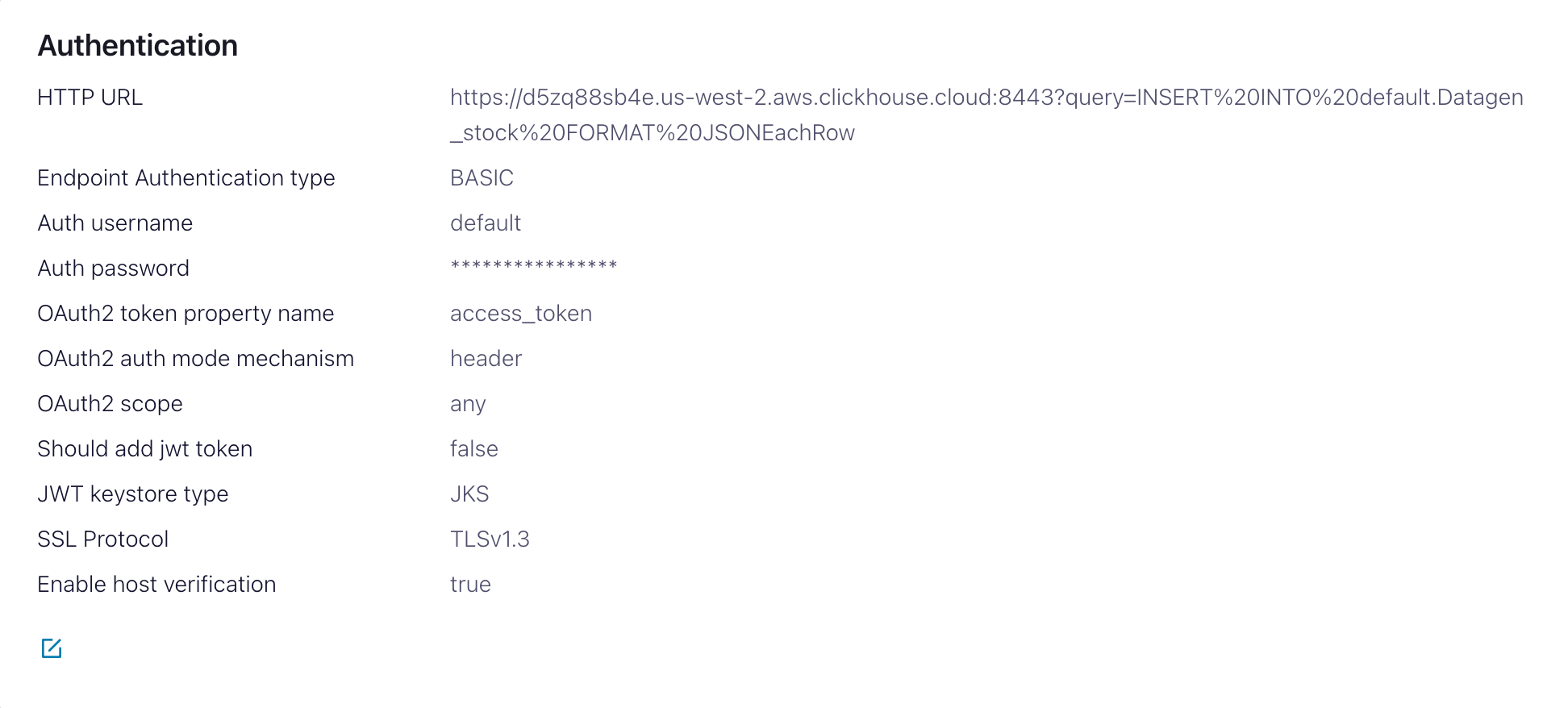
- 配置
Input Kafka record value format- 取决于您的源数据,但在大多数情况下为 JSON 或 Avro。我们在以下设置中假设为JSON。- 在
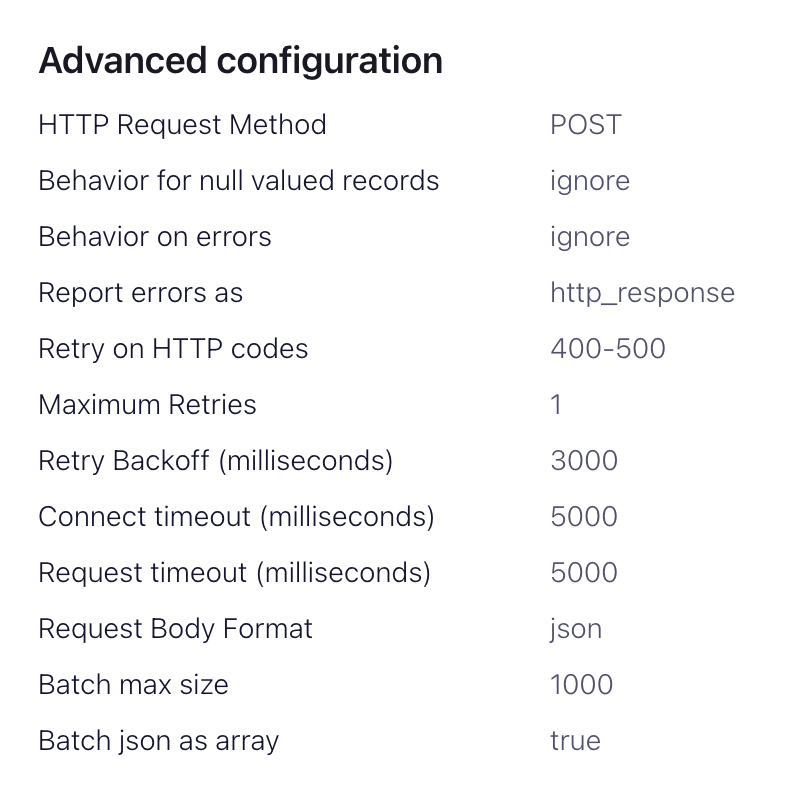
advanced configurations部分HTTP Request Method- 设置为 POSTRequest Body Format- jsonBatch batch size- 根据 ClickHouse 建议,将其设置为至少 1000。Batch json as array- trueRetry on HTTP codes- 400-500,但根据需要进行调整,例如,如果您在 ClickHouse 前面有一个 HTTP 代理,则可能会更改。Maximum Reties- 默认值 (10) 是合适的,但可以根据需要进行调整以获得更强大的重试。
5. 测试连接性
在您的 HTTP Sink 配置的主题中创建一个消息
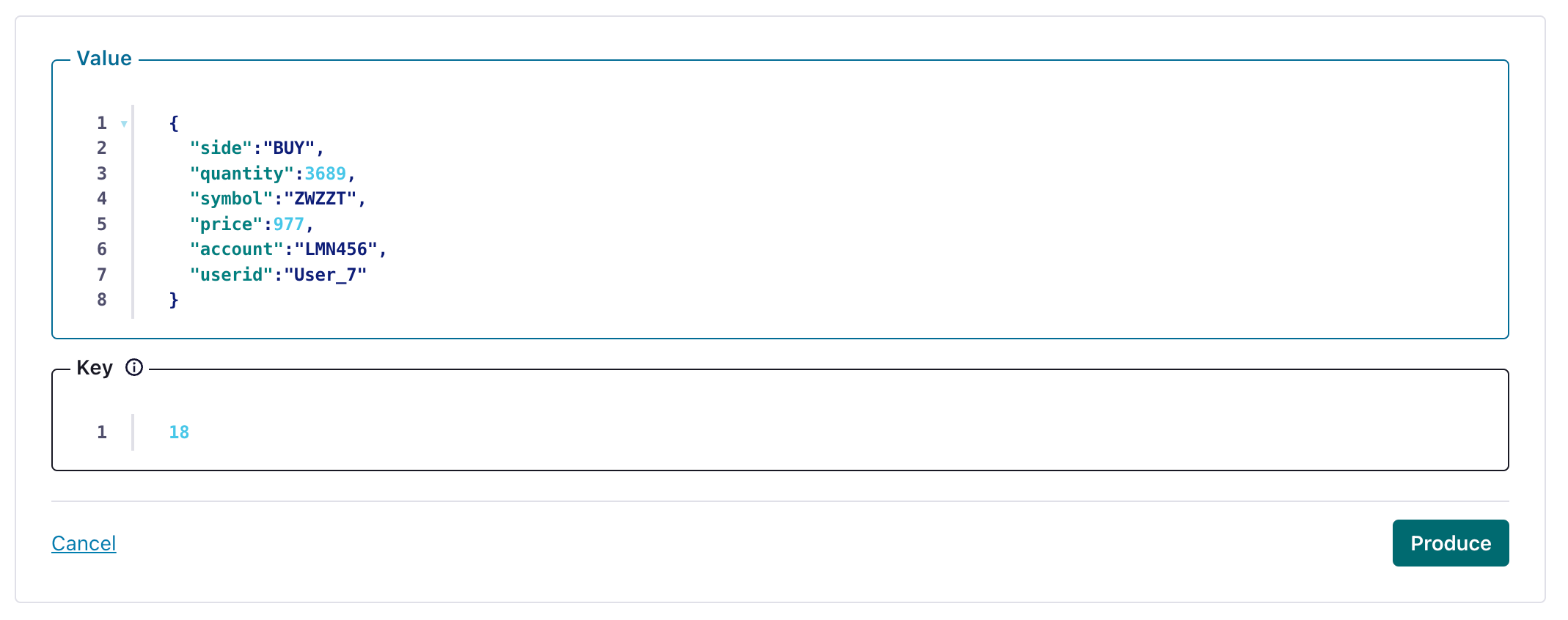
并验证创建的消息已写入您的 ClickHouse 实例。
故障排除
HTTP Sink 不批量处理消息
来自 Sink 文档
对于包含不同 Kafka 标头值的消息,HTTP Sink 连接器不会批量处理请求。
- 验证您的 Kafka 记录是否具有相同的键。
- 当您向 HTTP API URL 添加参数时,每个记录都可能导致唯一的 URL。因此,当使用额外的 URL 参数时,批量处理将被禁用。
400 错误请求
无法解析带引号的字符串
如果 HTTP Sink 在将 JSON 对象插入到 String 列时失败并显示以下消息
Code: 26. DB::ParsingException: Cannot parse JSON string: expected opening quote: (while reading the value of key key_name): While executing JSONEachRowRowInputFormat: (at row 1). (CANNOT_PARSE_QUOTED_STRING)
在 URL 中将 input_format_json_read_objects_as_strings=1 设置为编码字符串 SETTINGS%20input_format_json_read_objects_as_strings%3D1
加载 GitHub 数据集(可选)
请注意,此示例保留了 Github 数据集的 Array 字段。我们假设您在示例中有一个空的 github 主题,并使用 kcat 将消息插入到 Kafka。
1. 准备配置
按照这些说明设置与您的安装类型相关的 Connect,注意独立集群和分布式集群之间的差异。如果使用 Confluent Cloud,则分布式设置是相关的。
最重要的参数是 http.api.url。ClickHouse 的 HTTP 接口要求您将 INSERT 语句编码为 URL 中的参数。这必须包括格式(在本例中为 JSONEachRow)和目标数据库。格式必须与 Kafka 数据一致,Kafka 数据将在 HTTP payload 中转换为字符串。这些参数必须进行 URL 转义。下面显示了 Github 数据集(假设您在本地运行 ClickHouse)的此格式示例
<protocol>://<clickhouse_host>:<clickhouse_port>?query=INSERT%20INTO%20<database>.<table>%20FORMAT%20JSONEachRow
https://:8123?query=INSERT%20INTO%20default.github%20FORMAT%20JSONEachRow
以下附加参数与将 HTTP Sink 与 ClickHouse 一起使用相关。完整的参数列表可以在此处找到
request.method- 设置为 POSTretry.on.status.codes- 设置为 400-500 以重试任何错误代码。根据数据中预期的错误进行优化。request.body.format- 在大多数情况下,这将是 JSON。auth.type- 如果您使用 ClickHouse 进行安全设置,请设置为 BASIC。目前不支持其他 ClickHouse 兼容的身份验证机制。ssl.enabled- 如果使用 SSL,则设置为 true。connection.user- ClickHouse 的用户名。connection.password- ClickHouse 的密码。batch.max.size- 单个批次中要发送的行数。确保此设置设置为适当的较大数字。根据 ClickHouse 建议,1000 的值应被视为最小值。tasks.max- HTTP Sink 连接器支持运行一个或多个任务。这可以用于提高性能。与批量大小一起,这代表了您提高性能的主要手段。key.converter- 根据您的键的类型进行设置。value.converter- 根据您的主题上的数据类型进行设置。此数据不需要 schema。此处的格式必须与参数http.api.url中指定的 FORMAT 一致。这里最简单的是使用 JSON 和 org.apache.kafka.connect.json.JsonConverter 转换器。通过 org.apache.kafka.connect.storage.StringConverter 转换器将值视为字符串也是可能的 - 尽管这将要求用户使用函数在 insert 语句中提取值。Avro 格式 如果使用 io.confluent.connect.avro.AvroConverter 转换器,ClickHouse 也支持 Avro 格式。
完整的设置列表,包括如何配置代理、重试和高级 SSL,可以在此处找到。
Github 示例数据的示例配置文件可以在此处找到,假设 Connect 以独立模式运行,并且 Kafka 托管在 Confluent Cloud 中。
2. 创建 ClickHouse 表
确保已创建表。下面显示了使用标准 MergeTree 的最小 github 数据集的示例。
CREATE TABLE github
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)
3. 向 Kafka 添加数据
将消息插入到 Kafka。下面我们使用 kcat 插入 1 万条消息。
head -n 10000 github_all_columns.ndjson | kcat -b <host>:<port> -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN -X sasl.username=<username> -X sasl.password=<password> -t github
对目标表 “Github” 的简单读取应确认数据的插入。
SELECT count() FROM default.github;
| count\(\) |
| :--- |
| 10000 |