仓库
(此功能处于 Private Preview 阶段,请联系支持以在您的 ClickHouse Cloud 组织中启用此功能)
什么是计算-计算分离?
每个 ClickHouse Cloud 服务都包含
- 一组 ClickHouse 节点(或副本)- 开发层服务为 2 个节点,生产层服务为 3 个节点
- 一个端点(或通过 ClickHouse Cloud UI 控制台创建的多个端点),这是一个服务 URL,您可以使用它连接到服务(例如,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443) - 一个对象存储文件夹,服务在其中存储所有数据和部分元数据
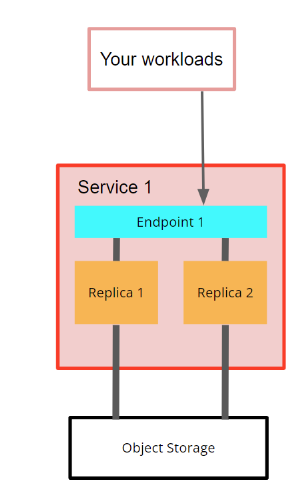
图 1 - ClickHouse Cloud 中的当前服务
计算-计算分离允许用户创建多个计算节点组,每个组都有自己的端点,它们使用相同的对象存储文件夹,因此具有相同的表、视图等。
每个计算节点组都将有自己的端点,因此您可以选择使用哪组副本用于您的工作负载。您的一些工作负载可能仅需要一个小型副本即可满足,而另一些工作负载可能需要完整的高可用性 (HA) 和数百 GB 的内存。计算-计算分离还允许您将读取操作与写入操作分开,以便它们互不干扰
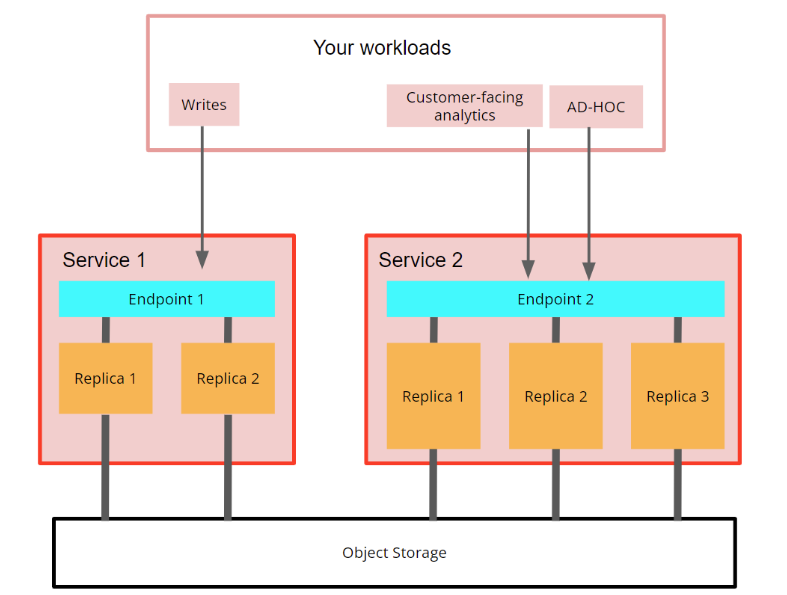
图 2 - 计算 ClickHouse Cloud
在此私有预览计划中,您将能够创建额外的服务,这些服务与您现有的服务共享相同的数据,或者创建一个全新的设置,其中多个服务共享相同的数据。
什么是仓库?
在 ClickHouse Cloud 中,仓库是一组共享相同数据的服务。每个仓库都有一个主服务(此服务首先创建)和辅助服务。例如,在下面的屏幕截图中,您可以看到一个包含两个服务的仓库“DWH Prod”
- 主服务 “DWH Prod”
- 辅助服务 “DWH Prod Subservice”

图 3 - 仓库示例
仓库中的所有服务共享相同的
- 区域(例如,us-east1)
- 云服务提供商(AWS、GCP 或 Azure)
- ClickHouse 数据库版本
您可以按服务所属的仓库对服务进行排序。
访问控制
数据库凭据
由于仓库中的所有服务共享相同的表集,因此它们也共享对其他服务的访问控制。这意味着在服务 1 中创建的所有数据库用户也能够使用服务 2,并具有相同的权限(表、视图等的授权),反之亦然。用户将为每个服务使用另一个端点,但将使用相同的用户名和密码。换句话说,用户在处理相同存储的服务之间共享:
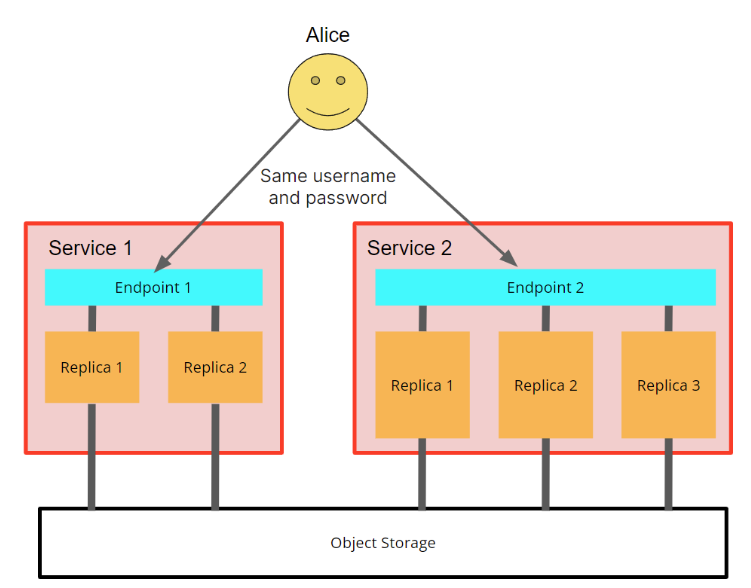
图 4 - 用户 Alice 在服务 1 中创建,但她可以使用相同的凭据访问共享相同数据的所有服务
网络访问控制
通常,限制特定服务被其他应用程序或临时用户使用非常有用。这可以通过使用网络限制来完成,类似于当前为常规服务配置的方式(导航到 ClickHouse Cloud 控制台中特定服务中的设置选项卡)。
您可以分别将 IP 过滤设置应用于每个服务,这意味着您可以控制哪个应用程序可以访问哪个服务。这允许您限制用户使用特定服务
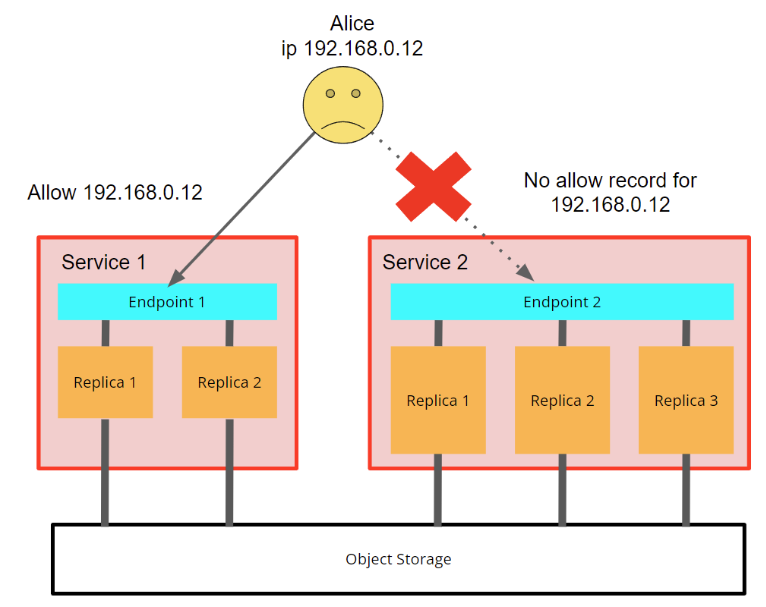
图 5 - 由于网络设置,Alice 被限制访问服务 2
读与读写
有时,限制对特定服务的写入访问,并仅允许仓库中一部分服务进行写入是很有用的。这可以在创建第二个和第 n 个服务时完成(第一个服务应始终为读写)
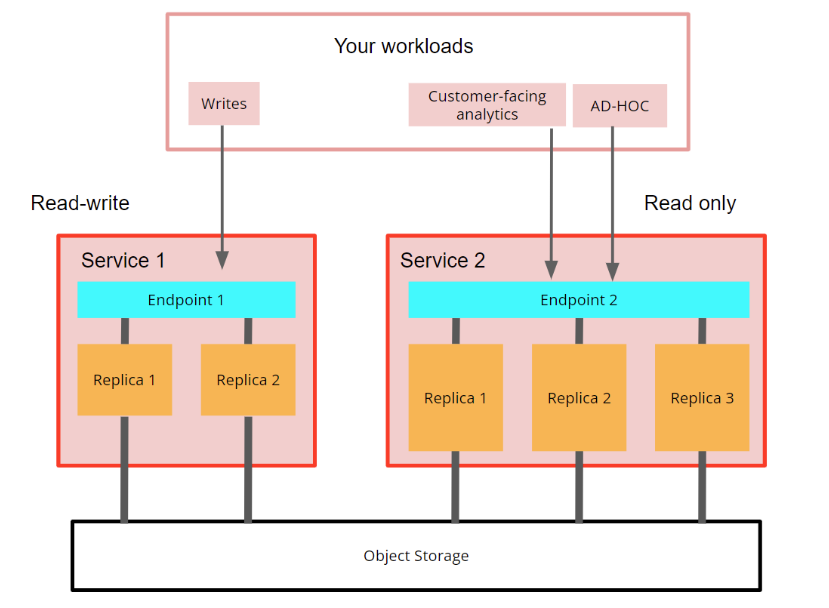
图 6 - 仓库中的读写和只读服务
扩展
仓库中的每个服务都可以根据您的工作负载进行调整,包括
- 节点(副本)数量。目前,最少节点(副本)数量为 2。
- 节点(副本)大小
- 服务是否应自动扩展
- 服务是否应在不活动时闲置(不能应用于组中的第一个服务 - 请参阅限制部分)
行为变更
一旦为服务启用了计算-计算分离(至少创建了一个辅助服务),使用 default 集群名称调用 clusterAllReplicas() 函数将仅利用调用它的服务中的副本。这意味着,如果有两个服务连接到同一数据集,并且从服务 1 调用 clusterAllReplicas(default, system, processes),则只会显示在服务 1 上运行的进程。如果需要,您仍然可以调用 clusterAllReplicas('all_groups.default', system, processes) 等来访问所有副本。
限制
由于此计算-计算分离目前处于私有预览阶段,因此使用此功能存在一些限制。一旦该功能发布到 GA(全面可用),大多数这些限制将被删除
-
主服务应始终保持运行状态,并且不应闲置(限制将在 GA 后一段时间内删除)。在私有预览期间以及 GA 后一段时间内,主服务(通常是您想要通过添加其他服务来扩展的现有服务)将始终保持运行状态,并且将禁用空闲设置。如果至少有一个辅助服务,您将无法停止或闲置主服务。一旦所有辅助服务都被删除,您可以再次停止或闲置原始服务。
-
有时工作负载无法隔离。尽管目标是让您可以选择将数据库工作负载彼此隔离,但在某些极端情况下,一个服务中的一个工作负载会影响共享相同数据的另一个服务。这些是非常罕见的情况,主要与类似 OLTP 的工作负载有关。
-
所有读写服务都在执行后台合并操作。当向 ClickHouse 插入数据时,数据库首先将数据插入到一些暂存分区,然后在后台执行合并。这些合并可能会消耗内存和 CPU 资源。当两个读写服务共享相同的存储时,它们都在执行后台操作。这意味着可能会出现以下情况:服务 1 中存在
INSERT查询,但合并操作由服务 2 完成。请注意,只读服务不执行后台合并,因此它们不会在此操作上花费资源。 -
如果启用了空闲,则一个读写服务中的插入可能会阻止另一个读写服务进入空闲状态。由于前一点,第二个服务为第一个服务执行后台合并操作。这些后台操作可能会阻止第二个服务在空闲时进入休眠状态。一旦后台操作完成,服务将进入空闲状态。只读服务不受影响,并将立即进入空闲状态。
-
默认情况下,CREATE/RENAME/DROP DATABASE 查询可能会被闲置/停止的服务阻止(限制将在 GA 中删除)。这些查询可能会挂起。要绕过此问题,您可以使用
settings distributed_ddl_task_timeout=0在会话或每个查询级别运行数据库管理查询。例如
create database db_test_ddl_single_query_setting
settings distributed_ddl_task_timeout=0
-
原始服务应足够新,或已迁移 遗憾的是,并非所有现有服务都可以与其他服务共享其存储。在过去一年中,我们发布了一些服务需要支持的功能(如 Shared Merge Tree 引擎),因此旧服务大多无法与其他服务共享其数据。这与 ClickHouse 版本无关。好消息是,我们可以将旧服务迁移到新引擎,以便它可以支持创建额外的服务。如果您的服务无法启用计算-计算分离,请联系支持部门以获得迁移帮助。
-
单节点辅助服务在升级期间可能长达 1 小时不可用 创建数据库服务时,您可以选择副本数量。创建辅助服务时,您可以选择创建单节点服务,这意味着此特定服务将不具有高可用性。目前,在对此类服务执行升级时,无法执行通常的滚动升级,这意味着单节点服务在升级期间将不可用。虽然通常升级仅需几分钟,但在某些情况下,如果存在长时间运行的查询,则可能需要长达一小时。单节点服务在此期间将不可用。如果这是不可接受的,请考虑创建至少两个节点的服务 - 在这种情况下,将不会有任何停机时间。我们正在努力消除此限制。
定价
在私有预览期间创建的额外服务照常计费。仓库(主服务和辅助服务)中所有服务的计算价格相同。存储仅计费一次 - 它包含在第一个(原始)服务中。
备份
- 由于单个仓库中的所有服务共享相同的存储,因此备份仅在主(初始)服务上进行。这样,仓库中所有服务的数据都会被备份。
- 如果您从仓库的主服务还原备份,它将被还原到一个全新的服务,而不是连接到现有仓库。然后在还原完成后,您可以立即向新服务添加更多服务。
使用仓库
创建仓库
要创建仓库,您需要创建第二个服务,该服务将与现有服务共享数据。这可以通过单击任何现有服务上的加号来完成
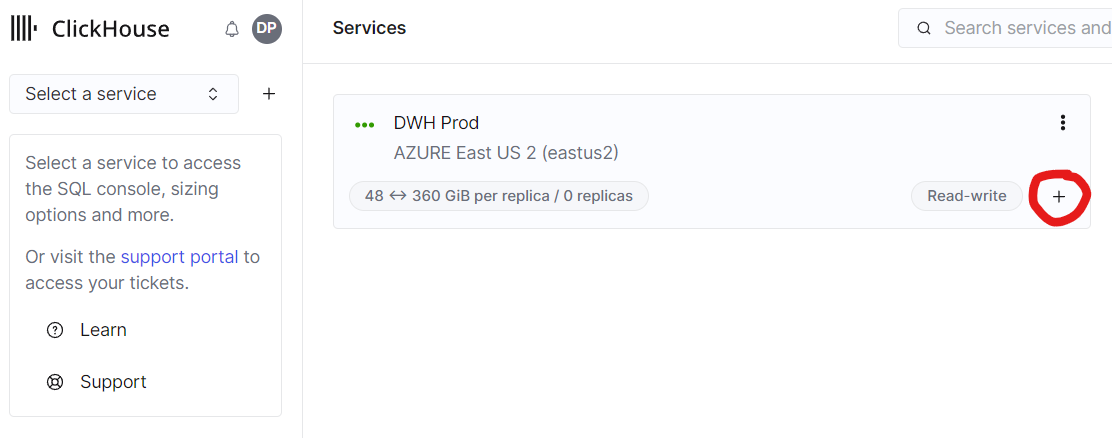
图 7 - 单击加号以在仓库中创建新服务
在服务创建屏幕上,原始服务将在下拉列表中被选为新服务的数据源。创建后,这两个服务将形成一个仓库。
重命名仓库
有两种方法可以重命名仓库
- 您可以选择服务页面右上角的“按仓库排序”,然后单击仓库名称附近的铅笔图标
- 您可以单击任何服务上的仓库名称并在那里重命名仓库
删除仓库
删除仓库意味着删除所有计算服务和数据(表、视图、用户等)。此操作无法撤消。您只能通过删除第一个创建的服务来删除仓库。为此
- 删除除第一个创建的服务之外的所有服务;
- 删除第一个服务(警告:此步骤将删除所有仓库的数据)。