SharedMergeTree 表引擎
* 仅在 ClickHouse Cloud(和第一方合作伙伴云服务)中可用
SharedMergeTree 表引擎系列是 ReplicatedMergeTree 引擎的云原生替代品,经过优化,可在共享存储(例如 Amazon S3、Google Cloud Storage、MinIO、Azure Blob Storage)之上工作。对于每种特定的 MergeTree 引擎类型,都有一个 SharedMergeTree 类似物,即 ReplacingSharedMergeTree 替换 ReplacingReplicatedMergeTree。
SharedMergeTree 表引擎系列为 ClickHouse Cloud 提供动力。对于最终用户而言,无需进行任何更改即可开始使用 SharedMergeTree 引擎系列而不是基于 ReplicatedMergeTree 的引擎。它提供以下附加优势
- 更高的插入吞吐量
- 改进的后台合并吞吐量
- 改进的 mutations 吞吐量
- 更快的向上和向下扩展操作
- 针对选择查询的更轻量级的强一致性
SharedMergeTree 带来的一个重大改进是,与 ReplicatedMergeTree 相比,它提供了更深层次的计算和存储分离。您可以在下面看到 ReplicatedMergeTree 如何分离计算和存储
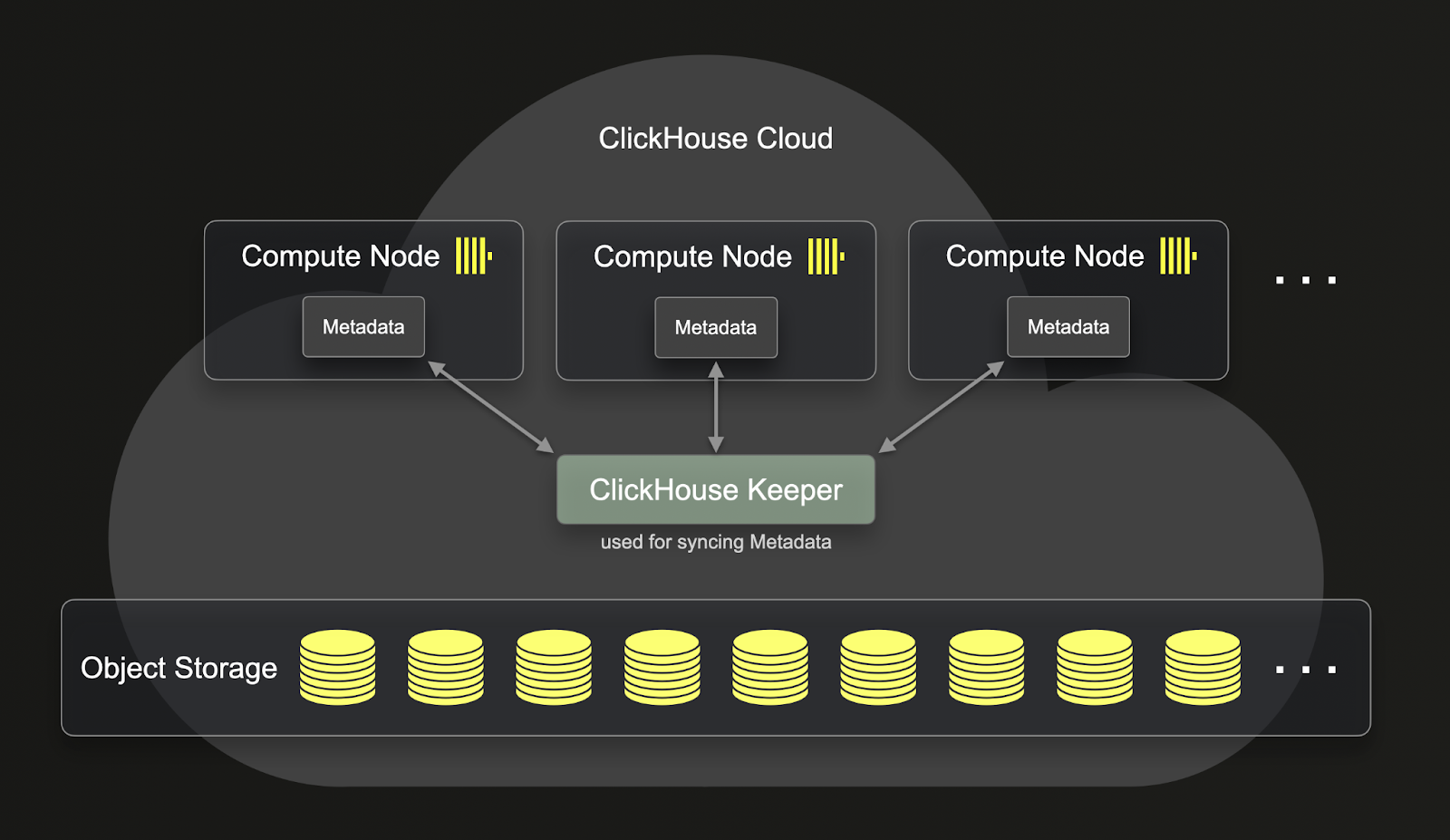
如您所见,即使 ReplicatedMergeTree 中存储的数据在对象存储中,元数据仍然驻留在每个 clickhouse-server 上。这意味着对于每个复制操作,元数据也需要在所有副本上复制。
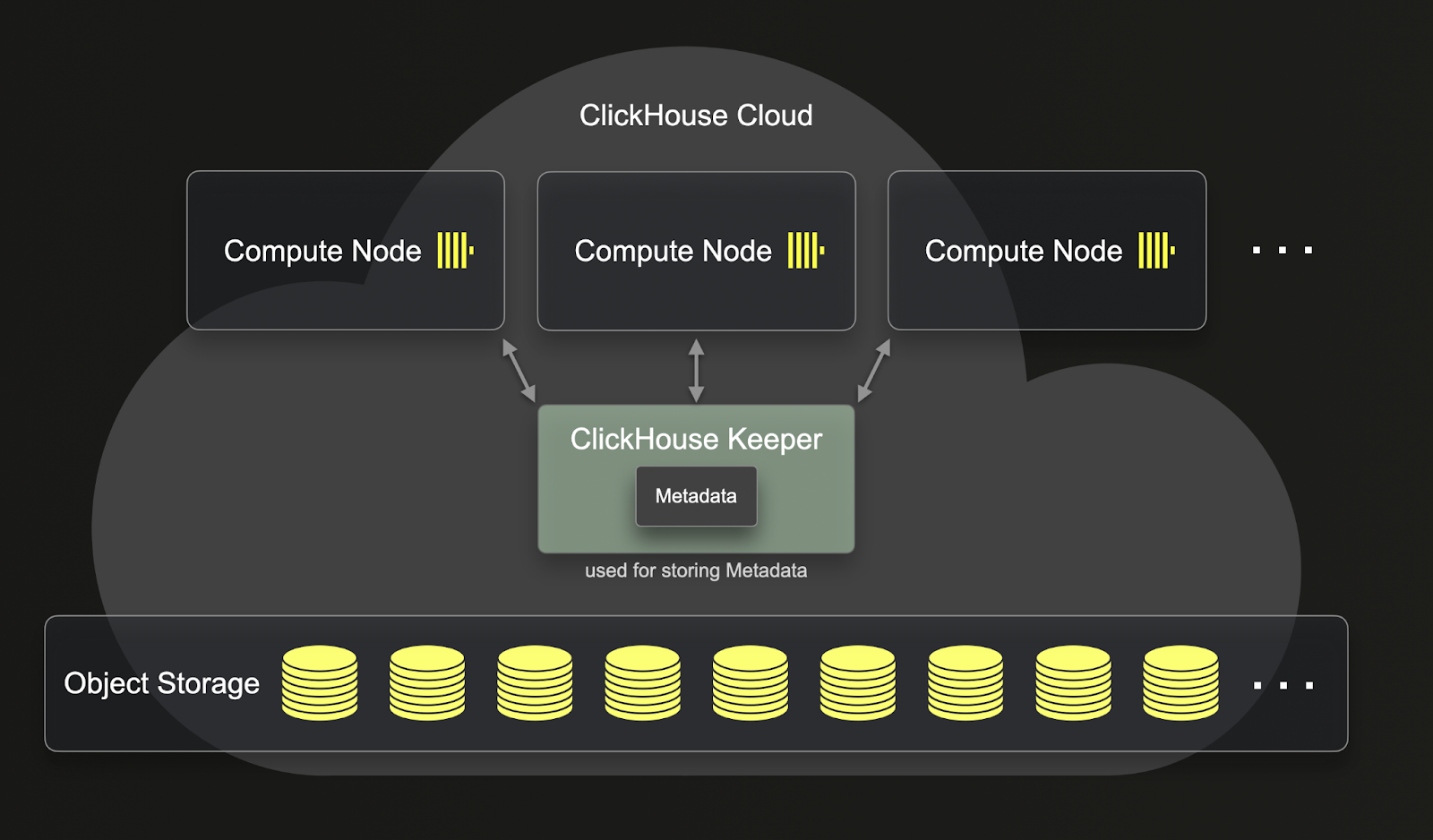
与 ReplicatedMergeTree 不同,SharedMergeTree 不需要副本相互通信。相反,所有通信都通过共享存储和 clickhouse-keeper 进行。SharedMergeTree 实现了异步无领导者复制,并使用 clickhouse-keeper 进行协调和元数据存储。这意味着元数据无需随着服务的扩展和缩减而复制。这使得复制、mutation、合并和扩展操作更快。SharedMergeTree 允许每个表有数百个副本,从而可以在不分片的情况下动态扩展。ClickHouse Cloud 中使用分布式查询执行方法来利用更多计算资源进行查询。
内省
用于内省 ReplicatedMergeTree 的大多数系统表都存在于 SharedMergeTree 中,但 system.replication_queue 和 system.replicated_fetches 除外,因为没有发生数据和元数据的复制。但是,SharedMergeTree 为这两个表提供了相应的替代方案。
system.virtual_parts
此表充当 SharedMergeTree 的 system.replication_queue 的替代方案。它存储有关最新的一组当前部件以及正在进行的未来部件(例如合并、mutation 和已删除分区)的信息。
system.shared_merge_tree_fetches
此表是 SharedMergeTree 的 system.replicated_fetches 的替代方案。它包含有关当前正在进行的将主键和校验和提取到内存中的信息。
启用 SharedMergeTree
SharedMergeTree 默认启用。
对于支持 SharedMergeTree 表引擎的服务,您无需手动启用任何内容。您可以像以前一样创建表,它将自动使用与 CREATE TABLE 查询中指定的引擎相对应的基于 SharedMergeTree 的表引擎。
CREATE TABLE my_table(
key UInt64,
value String
)
ENGINE = MergeTree
ORDER BY key
这将使用 SharedMergeTree 表引擎创建表 my_table 。
您无需在 ClickHouse Cloud 中指定 ENGINE=MergeTree,因为 default_table_engine=MergeTree。以下查询与上述查询相同。
CREATE TABLE my_table(
key UInt64,
value String
)
ORDER BY key
如果您使用 Replacing、Collapsing、Aggregating、Summing、VersionedCollapsing 或 Graphite MergeTree 表,它将自动转换为相应的基于 SharedMergeTree 的表引擎。
CREATE TABLE myFirstReplacingMT
(
`key` Int64,
`someCol` String,
`eventTime` DateTime
)
ENGINE = ReplacingMergeTree
ORDER BY key;
对于给定的表,您可以使用带有 SHOW CREATE TABLE 的 CREATE TABLE 语句检查使用了哪个表引擎
SHOW CREATE TABLE myFirstReplacingMT;
CREATE TABLE default.myFirstReplacingMT
( `key` Int64, `someCol` String, `eventTime` DateTime )
ENGINE = SharedReplacingMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
ORDER BY key
SETTINGS index_granularity = 8192
设置
某些设置行为已发生重大变化
insert_quorum-- 所有插入到 SharedMergeTree 的插入都是仲裁插入(写入共享存储),因此在使用 SharedMergeTree 表引擎时不需要此设置。insert_quorum_parallel-- 所有插入到 SharedMergeTree 的插入都是仲裁插入(写入共享存储),因此在使用 SharedMergeTree 表引擎时不需要此设置。select_sequential_consistency-- 不需要仲裁插入,将在SELECT查询时触发 clickhouse-keeper 的额外负载
一致性
SharedMergeTree 提供比 ReplicatedMergeTree 更好的轻量级一致性。当插入到 SharedMergeTree 时,您无需提供诸如 insert_quorum 或 insert_quorum_parallel 之类的设置。插入是仲裁插入,这意味着元数据将存储在 ClickHouse-Keeper 中,并且元数据至少复制到仲裁数量的 ClickHouse-keeper。集群中的每个副本都将从 ClickHouse-Keeper 异步获取新信息。
大多数情况下,您不应使用 select_sequential_consistency 或 SYSTEM SYNC REPLICA LIGHTWEIGHT。异步复制应涵盖大多数场景,并且延迟非常低。在极少数情况下,如果您绝对需要防止陈旧读取,请按照优先顺序遵循以下建议
-
如果您在同一会话或同一节点中执行读取和写入查询,则无需使用
select_sequential_consistency,因为您的副本已经具有最新的元数据。 -
如果您写入一个副本并从另一个副本读取,则可以使用
SYSTEM SYNC REPLICA LIGHTWEIGHT强制副本从 ClickHouse-Keeper 获取元数据。 -
在查询中使用
select_sequential_consistency作为设置。