BigQuery 与 ClickHouse Cloud 对比:等效和不同的概念
资源组织
ClickHouse Cloud 中的资源组织方式类似于 BigQuery 的资源层级结构。我们将在下面的图中描述基于 ClickHouse Cloud 资源层级结构的具体差异
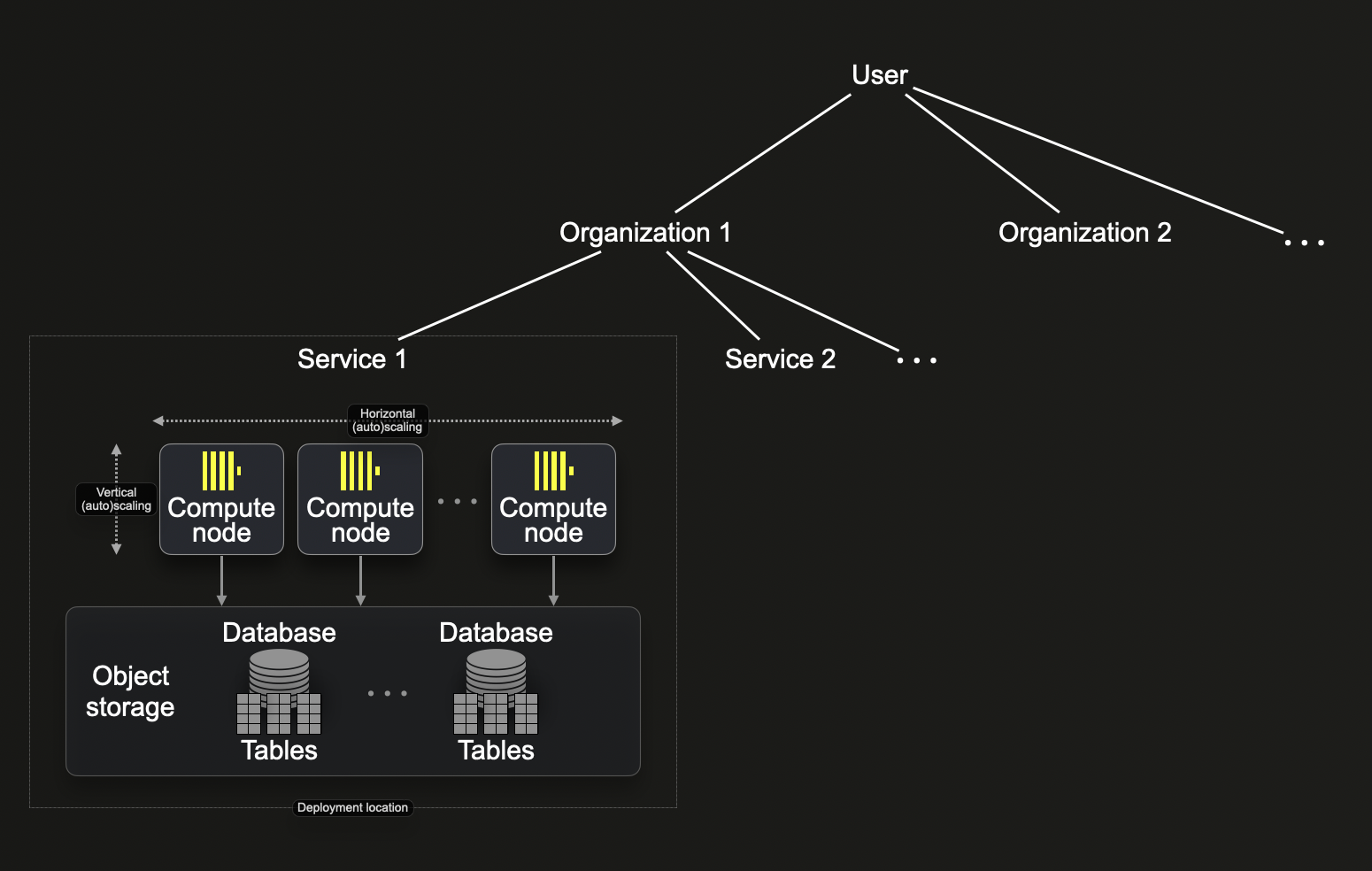
组织
与 BigQuery 类似,组织是 ClickHouse Cloud 资源层级结构中的根节点。您在 ClickHouse Cloud 账户中设置的第一个用户会自动分配到一个由该用户拥有的组织。用户可以邀请其他用户加入该组织。
BigQuery 项目 vs ClickHouse Cloud 服务
在组织内部,您可以创建服务,这些服务与 BigQuery 项目大致等效,因为 ClickHouse Cloud 中存储的数据与服务相关联。ClickHouse Cloud 中有几种服务类型可用。每个 ClickHouse Cloud 服务都部署在特定区域,并包括
- 一组计算节点(目前,开发层服务为 2 个节点,生产层服务为 3 个节点)。对于这些节点,ClickHouse Cloud 支持垂直和水平扩展,包括手动和自动扩展。
- 一个对象存储文件夹,服务在其中存储所有数据。
- 一个端点(或通过 ClickHouse Cloud UI 控制台创建的多个端点)- 您用于连接到服务的服务 URL(例如,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443)
BigQuery 数据集 vs ClickHouse Cloud 数据库
ClickHouse 在逻辑上将表分组到数据库中。与 BigQuery 数据集类似,ClickHouse 数据库是逻辑容器,用于组织和控制对表数据的访问。
BigQuery 文件夹
ClickHouse Cloud 目前没有与 BigQuery 文件夹等效的概念。
BigQuery 插槽预留和配额
与 BigQuery 插槽预留类似,您可以在 ClickHouse Cloud 中配置垂直和水平自动扩展。对于垂直自动扩展,您可以为服务的计算节点的内存和 CPU 核心设置最小和最大大小。然后,服务将根据需要在这些范围内扩展。这些设置在初始服务创建流程中也可用。服务中的每个计算节点都具有相同的大小。您可以使用水平扩展更改服务中计算节点的数量。
此外,与 BigQuery 配额类似,ClickHouse Cloud 提供并发控制、内存使用限制和 I/O 调度,使用户可以将查询隔离到工作负载类中。通过设置特定工作负载类别的共享资源(CPU 核心、DRAM、磁盘和网络 I/O)的限制,可以确保这些查询不会影响其他关键业务查询。并发控制可防止在高并发查询场景中出现线程过度订阅。
ClickHouse 跟踪服务器、用户和查询级别的内存分配字节大小,从而实现灵活的内存使用限制。内存过载允许查询使用超出保证内存的额外可用内存,同时确保其他查询的内存限制。此外,可以限制聚合、排序和连接子句的内存使用量,从而在超出内存限制时回退到外部算法。
最后,I/O 调度允许用户根据最大带宽、飞行中请求和策略来限制工作负载类别的本地和远程磁盘访问。
权限
ClickHouse Cloud 在两个位置控制用户访问,通过云控制台和通过数据库。控制台访问通过 clickhouse.cloud 用户界面进行管理。数据库访问通过数据库用户帐户和角色进行管理。此外,可以授予控制台用户在数据库中的角色,使控制台用户能够通过我们的SQL 控制台与数据库进行交互。
数据类型
ClickHouse 在数值方面提供更精细的精度。例如,BigQuery 提供数值类型 INT64、NUMERIC、BIGNUMERIC 和 FLOAT64。相比之下,ClickHouse 为十进制、浮点数和整数提供多种精度类型。借助这些数据类型,ClickHouse 用户可以优化存储和内存开销,从而加快查询速度并降低资源消耗。下面我们为每种 BigQuery 类型映射等效的 ClickHouse 类型
当有多个 ClickHouse 类型选项时,请考虑数据的实际范围并选择最低要求的类型。此外,考虑使用适当的编解码器以进一步压缩。
查询加速技术
主键和外键以及主索引
在 BigQuery 中,一个表可以具有主键和外键约束。通常,主键和外键用于关系数据库中,以确保数据完整性。主键值通常对于每一行都是唯一的,并且不能为 NULL。一行中的每个外键值必须存在于主键表的主键列中,或者为 NULL。在 BigQuery 中,这些约束不会强制执行,但查询优化器可以使用此信息来更好地优化查询。
在 ClickHouse 中,一个表也可以具有主键。与 BigQuery 类似,ClickHouse 不强制表的主键列值的唯一性。与 BigQuery 不同,表的数据存储在磁盘上,按主键列排序。查询优化器利用此排序顺序来防止重新排序,最大限度地减少连接的内存使用量,并为 limit 子句启用短路。与 BigQuery 不同,ClickHouse 会自动根据主键列值创建一个(稀疏)主索引。此索引用于加速所有包含主键列过滤器的查询。ClickHouse 目前不支持外键约束。
二级索引(仅在 ClickHouse 中可用)
除了从表的主键列的值创建的主索引之外,ClickHouse 还允许您在主键列以外的列上创建二级索引。ClickHouse 提供多种类型的二级索引,每种索引都适用于不同类型的查询
- 布隆过滤器索引:
- 用于加速具有相等条件(例如,=、IN)的查询。
- 使用概率数据结构来确定数据块中是否存在值。
- Token 布隆过滤器索引:
- 类似于布隆过滤器索引,但用于分词字符串,适用于全文搜索查询。
- Min-Max 索引:
- 维护每个数据部分列的最小值和最大值。
- 帮助跳过读取不属于指定范围的数据部分。
搜索索引
类似于 BigQuery 中的搜索索引,可以为 ClickHouse 表的字符串值列创建全文索引。
向量索引
BigQuery 最近推出了向量索引作为 Pre-GA 功能。同样,ClickHouse 也对加速向量搜索用例的索引提供实验性支持。
分区
与 BigQuery 类似,ClickHouse 使用表分区来增强大型表的性能和可管理性,方法是将表划分为更小、更易于管理的部分,称为分区。我们在此处详细描述 ClickHouse 分区。
聚簇
通过聚簇,BigQuery 根据几个指定列的值自动对表数据进行排序,并将它们共置于最佳大小的块中。聚簇提高了查询性能,使 BigQuery 能够更好地估计运行查询的成本。使用聚簇列,查询还可以消除不必要的数据扫描。
在 ClickHouse 中,数据基于表的主键列自动在磁盘上聚簇,并在逻辑上组织在块中,查询可以利用主索引数据结构快速定位或修剪这些块。
物化视图
BigQuery 和 ClickHouse 都支持物化视图——基于针对基础表的转换查询结果预先计算的结果,以提高性能和效率。
查询物化视图
BigQuery 物化视图可以直接查询,也可以由优化器用来处理对基础表的查询。如果对基础表的更改可能会使物化视图失效,则直接从基础表读取数据。如果对基础表的更改不会使物化视图失效,则其余数据从物化视图读取,只有更改从基础表读取。
在 ClickHouse 中,物化视图只能直接查询。但是,与 BigQuery 相比(BigQuery 中物化视图会在基础表更改后 5 分钟内自动刷新,但频率不高于每 30 分钟一次),物化视图始终与基础表同步。
更新物化视图
BigQuery 通过针对基础表运行视图的转换查询来定期完全刷新物化视图。在刷新之间,BigQuery 将物化视图的数据与新的基础表数据结合起来,以提供一致的查询结果,同时仍使用物化视图。
在 ClickHouse 中,物化视图是增量更新的。这种增量更新机制提供了高可扩展性和低计算成本:增量更新的物化视图专为基础表包含数十亿或数万亿行的场景而设计。ClickHouse 不会重复查询不断增长的基础表来刷新物化视图,而是简单地从(仅)新插入的基础表行的值计算部分结果。此部分结果会在后台与先前计算的部分结果增量合并。与从整个基础表重复刷新物化视图相比,这大大降低了计算成本。
事务
与 ClickHouse 相比,BigQuery 支持单个查询内的多语句事务,或者在使用会话时跨多个查询的事务。多语句事务允许您执行变异操作,例如在一个或多个表上插入或删除行,并原子地提交或回滚更改。多语句事务已列入 ClickHouse 2024 年的路线图。
聚合函数
与 BigQuery 相比,ClickHouse 附带的内置聚合函数明显更多
- BigQuery 附带 18 个聚合函数 和 4 个近似聚合函数。
- ClickHouse 拥有超过 150 个预构建的聚合函数,外加强大的 聚合组合器,用于扩展预构建聚合函数的行为。例如,您可以通过使用 -Array 后缀 调用它们,将超过 150 个预构建的聚合函数应用于数组而不是表行。使用 -Map 后缀,您可以将任何聚合函数应用于 map。使用 -ForEach 后缀,您可以将任何聚合函数应用于嵌套数组。
数据源和文件格式
与 BigQuery 相比,ClickHouse 支持的文件格式和数据源明显更多
- ClickHouse 原生支持从几乎任何数据源加载 90 多种文件格式的数据
- BigQuery 支持 5 种文件格式和 19 个数据源
SQL 语言功能
ClickHouse 提供标准 SQL,并进行了许多扩展和改进,使其对分析任务更加友好。例如,ClickHouse SQL 支持 lambda 函数 和高阶函数,因此在应用转换时不必取消嵌套/展开数组。与 BigQuery 等其他系统相比,这是一个很大的优势。
数组
与 BigQuery 的 8 个数组函数相比,ClickHouse 拥有 80 多个 内置数组函数,用于优雅而简单地建模和解决各种问题。
ClickHouse 中的典型设计模式是使用 groupArray 聚合函数将表的特定行值(临时)转换为数组。然后可以通过数组函数方便地处理它,并且可以通过 arrayJoin 聚合函数将结果转换回单个表行。
由于 ClickHouse SQL 支持 高阶 lambda 函数,因此许多高级数组操作可以通过简单地调用其中一个高阶内置数组函数来实现,而不是像在 BigQuery 中那样经常要求的那样,临时将数组转换回表,例如用于过滤或压缩数组。在 ClickHouse 中,这些操作只是高阶函数 arrayFilter 和 arrayZip 的一个简单函数调用。
在下面,我们提供了从 BigQuery 到 ClickHouse 的数组操作映射
| BigQuery | ClickHouse |
|---|---|
| ARRAY_CONCAT | arrayConcat |
| ARRAY_LENGTH | length |
| ARRAY_REVERSE | arrayReverse |
| ARRAY_TO_STRING | arrayStringConcat |
| GENERATE_ARRAY | range |
为子查询中的每一行创建一个包含一个元素的数组
BigQuery
SELECT ARRAY
(SELECT 1 UNION ALL
SELECT 2 UNION ALL
SELECT 3) AS new_array;
/*-----------*
| new_array |
+-----------+
| [1, 2, 3] |
*-----------*/
ClickHouse
groupArray 聚合函数
SELECT groupArray(*) AS new_array
FROM
(
SELECT 1
UNION ALL
SELECT 2
UNION ALL
SELECT 3
)
┌─new_array─┐
1. │ [1,2,3] │
└───────────┘
将数组转换为一组行
BigQuery
UNNEST 运算符
SELECT *
FROM UNNEST(['foo', 'bar', 'baz', 'qux', 'corge', 'garply', 'waldo', 'fred'])
AS element
WITH OFFSET AS offset
ORDER BY offset;
/*----------+--------*
| element | offset |
+----------+--------+
| foo | 0 |
| bar | 1 |
| baz | 2 |
| qux | 3 |
| corge | 4 |
| garply | 5 |
| waldo | 6 |
| fred | 7 |
*----------+--------*/
ClickHouse
ARRAY JOIN 子句
WITH ['foo', 'bar', 'baz', 'qux', 'corge', 'garply', 'waldo', 'fred'] AS values
SELECT element, num-1 AS offset
FROM (SELECT values AS element) AS subquery
ARRAY JOIN element, arrayEnumerate(element) AS num;
/*----------+--------*
| element | offset |
+----------+--------+
| foo | 0 |
| bar | 1 |
| baz | 2 |
| qux | 3 |
| corge | 4 |
| garply | 5 |
| waldo | 6 |
| fred | 7 |
*----------+--------*/
返回日期数组
BigQuery
SELECT GENERATE_DATE_ARRAY('2016-10-05', '2016-10-08') AS example;
/*--------------------------------------------------*
| example |
+--------------------------------------------------+
| [2016-10-05, 2016-10-06, 2016-10-07, 2016-10-08] |
*--------------------------------------------------*/
ClickHouse
SELECT arrayMap(x -> (toDate('2016-10-05') + x), range(toUInt32((toDate('2016-10-08') - toDate('2016-10-05')) + 1))) AS example
┌─example───────────────────────────────────────────────┐
1. │ ['2016-10-05','2016-10-06','2016-10-07','2016-10-08'] │
└───────────────────────────────────────────────────────┘
返回时间戳数组
BigQuery
SELECT GENERATE_TIMESTAMP_ARRAY('2016-10-05 00:00:00', '2016-10-07 00:00:00',
INTERVAL 1 DAY) AS timestamp_array;
/*--------------------------------------------------------------------------*
| timestamp_array |
+--------------------------------------------------------------------------+
| [2016-10-05 00:00:00+00, 2016-10-06 00:00:00+00, 2016-10-07 00:00:00+00] |
*--------------------------------------------------------------------------*/
ClickHouse
SELECT arrayMap(x -> (toDateTime('2016-10-05 00:00:00') + toIntervalDay(x)), range(dateDiff('day', toDateTime('2016-10-05 00:00:00'), toDateTime('2016-10-07 00:00:00')) + 1)) AS timestamp_array
Query id: b324c11f-655b-479f-9337-f4d34fd02190
┌─timestamp_array─────────────────────────────────────────────────────┐
1. │ ['2016-10-05 00:00:00','2016-10-06 00:00:00','2016-10-07 00:00:00'] │
└─────────────────────────────────────────────────────────────────────┘
过滤数组
BigQuery
需要通过 UNNEST 运算符将数组临时转换回表
WITH Sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT
ARRAY(SELECT x * 2
FROM UNNEST(some_numbers) AS x
WHERE x < 5) AS doubled_less_than_five
FROM Sequences;
/*------------------------*
| doubled_less_than_five |
+------------------------+
| [0, 2, 2, 4, 6] |
| [4, 8] |
| [] |
*------------------------*/
ClickHouse
arrayFilter 函数
WITH Sequences AS
(
SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL
SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL
SELECT [5, 10] AS some_numbers
)
SELECT arrayMap(x -> (x * 2), arrayFilter(x -> (x < 5), some_numbers)) AS doubled_less_than_five
FROM Sequences;
┌─doubled_less_than_five─┐
1. │ [0,2,2,4,6] │
└────────────────────────┘
┌─doubled_less_than_five─┐
2. │ [] │
└────────────────────────┘
┌─doubled_less_than_five─┐
3. │ [4,8] │
└────────────────────────┘
压缩数组
BigQuery
需要通过 UNNEST 运算符将数组临时转换回表
WITH
Combinations AS (
SELECT
['a', 'b'] AS letters,
[1, 2, 3] AS numbers
)
SELECT
ARRAY(
SELECT AS STRUCT
letters[SAFE_OFFSET(index)] AS letter,
numbers[SAFE_OFFSET(index)] AS number
FROM Combinations
CROSS JOIN
UNNEST(
GENERATE_ARRAY(
0,
LEAST(ARRAY_LENGTH(letters), ARRAY_LENGTH(numbers)) - 1)) AS index
ORDER BY index
);
/*------------------------------*
| pairs |
+------------------------------+
| [{ letter: "a", number: 1 }, |
| { letter: "b", number: 2 }] |
*------------------------------*/
ClickHouse
arrayZip 函数
WITH Combinations AS
(
SELECT
['a', 'b'] AS letters,
[1, 2, 3] AS numbers
)
SELECT arrayZip(letters, arrayResize(numbers, length(letters))) AS pairs
FROM Combinations;
┌─pairs─────────────┐
1. │ [('a',1),('b',2)] │
└───────────────────┘
聚合数组
BigQuery
需要通过 UNNEST 运算符将数组转换回表
WITH Sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
(SELECT SUM(x)
FROM UNNEST(s.some_numbers) AS x) AS sums
FROM Sequences AS s;
/*--------------------+------*
| some_numbers | sums |
+--------------------+------+
| [0, 1, 1, 2, 3, 5] | 12 |
| [2, 4, 8, 16, 32] | 62 |
| [5, 10] | 15 |
*--------------------+------*/
ClickHouse
arraySum, arrayAvg, … 函数,或超过 90 个现有聚合函数名称中的任何一个作为 arrayReduce 函数的参数
WITH Sequences AS
(
SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL
SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL
SELECT [5, 10] AS some_numbers
)
SELECT
some_numbers,
arraySum(some_numbers) AS sums
FROM Sequences;
┌─some_numbers──┬─sums─┐
1. │ [0,1,1,2,3,5] │ 12 │
└───────────────┴──────┘
┌─some_numbers──┬─sums─┐
2. │ [2,4,8,16,32] │ 62 │
└───────────────┴──────┘
┌─some_numbers─┬─sums─┐
3. │ [5,10] │ 15 │
└──────────────┴──────┘