作为一家创立于开源的公司,我们乐于推广其他令我们印象深刻的 OSS 项目,因为它们在技术上令人赞叹,与我们对性能的执着产生共鸣,或者我们认为它们将真正帮助我们的用户。在发现 UI 库 Perspective 后,我们意识到它满足了所有这些要求,允许用户在 ClickHouse 数据之上构建真正的实时可视化!为了看看该库是否可以轻松地与 ClickHouse 集成,我们构建了一个简单的演示应用程序,通过使用 Apache Arrow 将 Forex 数据直接流式传输到浏览器,提供了丰富的可视化功能,而这一切仅用了 100 多行代码!
该示例应该很容易被改编,并允许用户可视化任何流式传输到 ClickHouse 的数据集。请告诉我们您的想法,并向 Perspective 致敬,感谢他们构建了如此酷的库!
如果您想运行示例 perspective 应用程序,我们为您提供了一个 ClickHouse 实例供您使用。或者,在此处 试用托管版本。最后,我们将探讨我们可以多快地流式传输数据,以及为什么当前的方法并不理想,以及未来 ClickHouse 功能的一些想法,这些功能将解决这些不足之处。
什么是 Perspective?
Perspective 库 是一种高性能数据分析和可视化工具,旨在高效处理实时和流式数据集。它提供交互式和可定制的可视化效果,例如热图、折线图和树状图。与 ClickHouse 一样,Perspective 的构建也考虑了性能。其核心是用 Rust 和 C++ 编写的,并编译成 WebAssembly。这使其能够在浏览器中处理数百万个数据点,并响应连续的数据流。
除了简单的渲染之外,Perspective 还提供快速操作,用于在浏览器或服务器端透视、过滤和聚合数据集,并使用 ExprTK 执行表达式。虽然这并非为 ClickHouse 中看到的 PB 级规模而设计,但它允许对交付给客户端的行进行第二级数据转换 - 如果所需数据已可用且仅需简单转换即可实现所需的可视化效果,则减少了对进一步查询的需求。
这使其成为由 ClickHouse 驱动的应用程序的理想选择,在这些应用程序中,实时洞察和流畅的交互性至关重要。凭借对 Python 和 JavaScript 的支持,它可以集成到后端分析管道和基于 Web 的界面中。
虽然 Perspective 完美地补充了 ClickHouse 的标准可视化需求,但我们特别感兴趣的是它处理流式数据的能力,通过仅保留最新的 N 行来保持恒定的内存开销。我们很好奇,跟踪不断更新的数据集有多容易,只需将新的增量加载到浏览器中,在浏览器中仅保留和汇总最新的点子集。
虽然我们专注于 Perspective 的 javascript 集成,但用户也可以在 Python 中使用 Perspective,配合 JupyterLab 小部件和客户端库,在笔记本中进行交互式数据分析。
ClickHouse 用于流式数据?
虽然 ClickHouse 不是流处理引擎,而是一个 OLAP 数据库,但它具有提供诸如 增量物化视图 等功能的特性,这些特性允许在诸如 Apache Flink 等技术中看到的大部分相同功能。这些视图是触发器,用于在插入数据块时对数据块执行查询(可以包括聚合),并将结果存储在不同的表中以供以后使用。
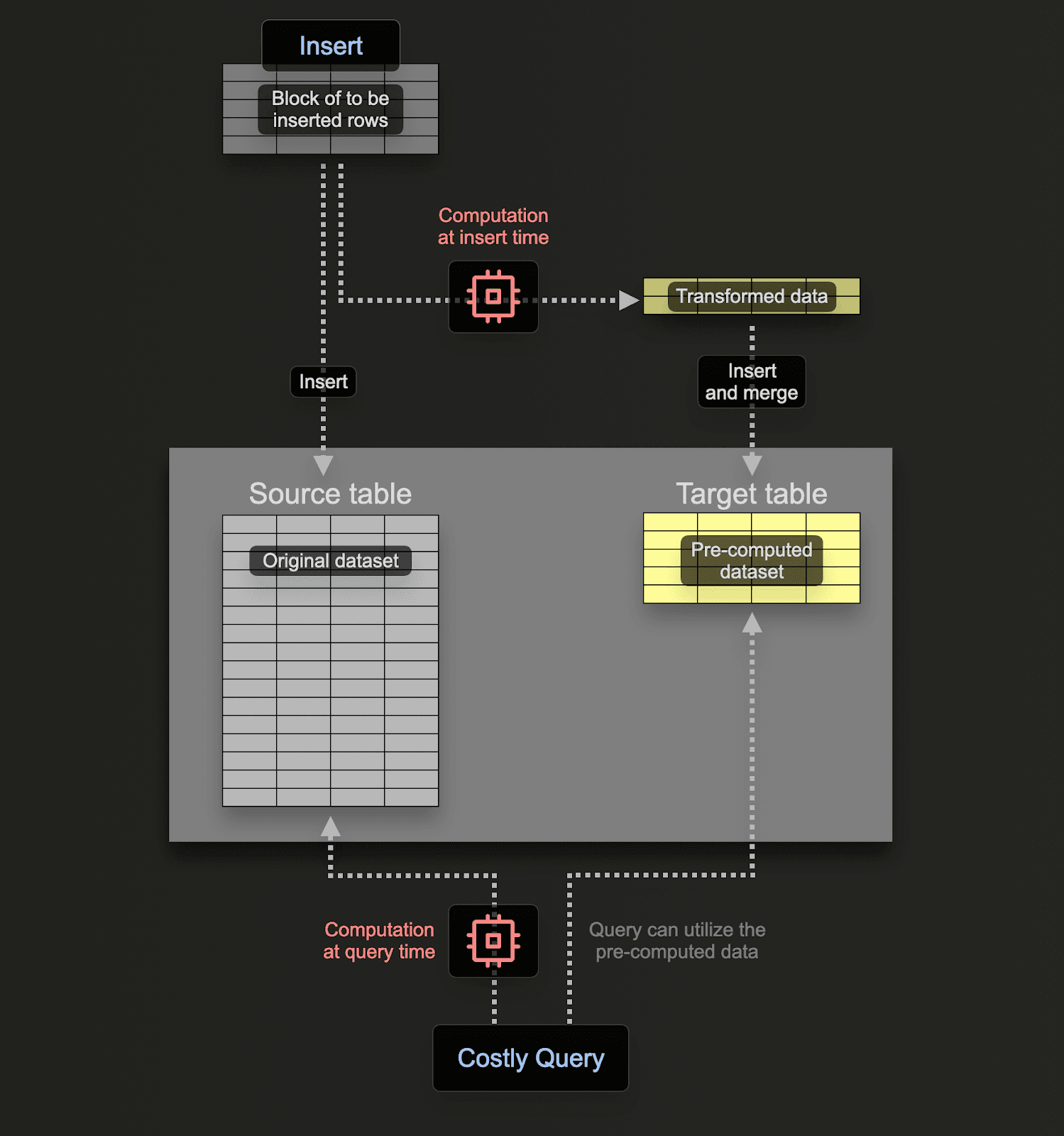
虽然许多简单的流处理功能可以复制人们在 Flink 等引擎中执行的更简单的转换和聚合,以简化架构,但我们承认这些技术协同工作,后者为高级用例提供了额外的功能。当用于流处理时,ClickHouse 还具有高效存储所有数据的额外好处 - 允许查询历史数据。
在我们的案例中,我们想尝试将 ClickHouse 中的最新行流式传输到 Perspective 以进行渲染。对于我们的示例,我们将粗略地模拟可视化外汇交易到达 ClickHouse 的需求。这可能对交易员最有用,如果需要,可以持久保存行以供将来的历史分析。
数据集 - 外汇
对于我们的示例,我们将使用外汇数据集。外汇交易是不同国家货币之间的交易,交易员可以从经纪商处购买以报价货币计价的基础货币(以卖出价),也可以出售基础货币并获得报价货币作为回报(以买入价)。数据集跟踪每种货币对随时间的价格变化——重要的是它们变化很快!
对于那些不熟悉外汇交易的人,我们建议阅读这篇早期文章的简短章节,其中我们总结了这些概念。
完整数据集可在公共 S3 存储桶中获取,从 www.histdata.com 下载,涵盖 2000 年至 2022 年。它有 115 亿行和 66 个货币对(解压缩后约 600GB)。
虽然很简单,但此数据集的模式非常适合我们的示例。每一行代表一个变动价位。这里的时间戳精度为毫秒,列指示基础货币和报价货币以及卖出价和买入价。
CREATE TABLE forex
(
`datetime` DateTime64(3),
`bid` Decimal(11, 5),
`ask` Decimal(11, 5),
`base` LowCardinality(String),
`quote` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY (datetime, base, quote)
变动价位记录股票或商品价格何时以预定金额或分数变化,即,当价格以特定金额或分数变化向上或向下移动时,就会发生变动价位。外汇中的变动价位将在买入价或报价价格发生变化时发生。
由于外汇的流式馈送不可用,我们将通过从 parquet 格式加载一年的数据并将其偏移到当前时间来模拟这一点。如果他们希望在本地实例上试用该应用程序,您可以复制此数据集 - 请参阅此处。
请注意,变动价位数据不代表实际的交易/兑换。每秒的交易/兑换次数要高得多!它也不捕获商定的价格或兑换货币的量(在源数据中逻辑上为 0,因此被忽略)。相反,它只是标记价格何时以称为 点 的单位变化。
使用 Arrow 将 Perspective 连接到 ClickHouse
一些样板代码
设置和配置 perspective 需要导入几个包,并使用一些样板代码。公共示例 非常出色,但总而言之,我们创建了一个 worker 和一个 table。worker 代表一个 Web worker 进程,它从浏览器的主渲染器线程卸载繁重的操作(例如更新)- 即使在流式传输大型实时数据集时,也能确保界面保持响应。table 代表可以使用新数据动态更新的主数据结构。
import perspective from "https://cdn.jsdelivr.net.cn/npm/@finos/[email protected]/dist/cdn/perspective.js";
const forex_worker = await perspective.worker();
// fetch some rows...
const forex_table = await market_worker.table(rows, { limit: 20000 })
我们使示例尽可能简单,通过 CDN 导入包,并避免除 perspective 之外的任何依赖项。建议将 Perspective 集成到现有应用程序或构建生产应用程序的用户浏览 常见 JS 框架和构建工具 的示例。
Perspective 提供了许多 部署模型),这些模型决定了数据的加载和绑定方式,每种模型都有各自的优缺点。对于我们的示例,我们将使用 仅客户端 方法,将数据流式传输到浏览器,几行 Javascript 代码通过 HTTP 从 ClickHouse 获取数据,WebAssembly 库运行所有计算和 UI 交互。
流式传输最新交易
创建表时,如下所示,我们限制了保留的行数,以限制内存开销。
const forex_table = await market_worker.table(rows, { limit: 20000 });
对于我们的示例,我们将随着新交易的出现不断向此表添加新行,依靠 Perspective 仅保留最新的 2 万行。
截至撰写本文时,ClickHouse 不支持 Web 套接字或将更改的行流式传输到客户端的方式。因此,我们使用轮询方法通过 HTTP 获取最新行。由于 Perspective 更喜欢 Apache Arrow 格式的数据,因此我们利用 ClickHouse 以这种格式返回数据的能力,这具有最大限度地减少数据传输的额外好处。
外汇变动价位发生得很快,对于交易量最高的货币对,每秒高达 35 个。我们希望尽可能快地获取这些变动价位 - 理想情况下每 30-50 毫秒,以确保所有值都可视化。因此,我们的查询需要快速执行,每个连接的客户端每秒发出 10 多个查询。对于所有连接的客户端,我们预计每秒有数百个查询 - 与某些误解相反,ClickHouse 可以轻松地处理这种情况。
我们的查询只是根据事件的时间戳进行过滤,这是我们主键中的第一个条目,因此确保了过滤得到优化。由于所有客户端都在请求大致相同的时间段,即现在,并且单调递增,因此我们的查询应该是缓存友好的。测试表明,即使在完整的 110 亿行数据集上,我们的查询执行时间也少于 10 毫秒,但到 ClickHouse 实例的 HTTP 往返时间乐观地估计(同一区域)为 20-30 毫秒。因此,我们只是使用从当前时间到上次获取时间的简单滑动窗口。这将持续执行,以 ClickHouse 可以服务它们的速度尽可能快地检索行。
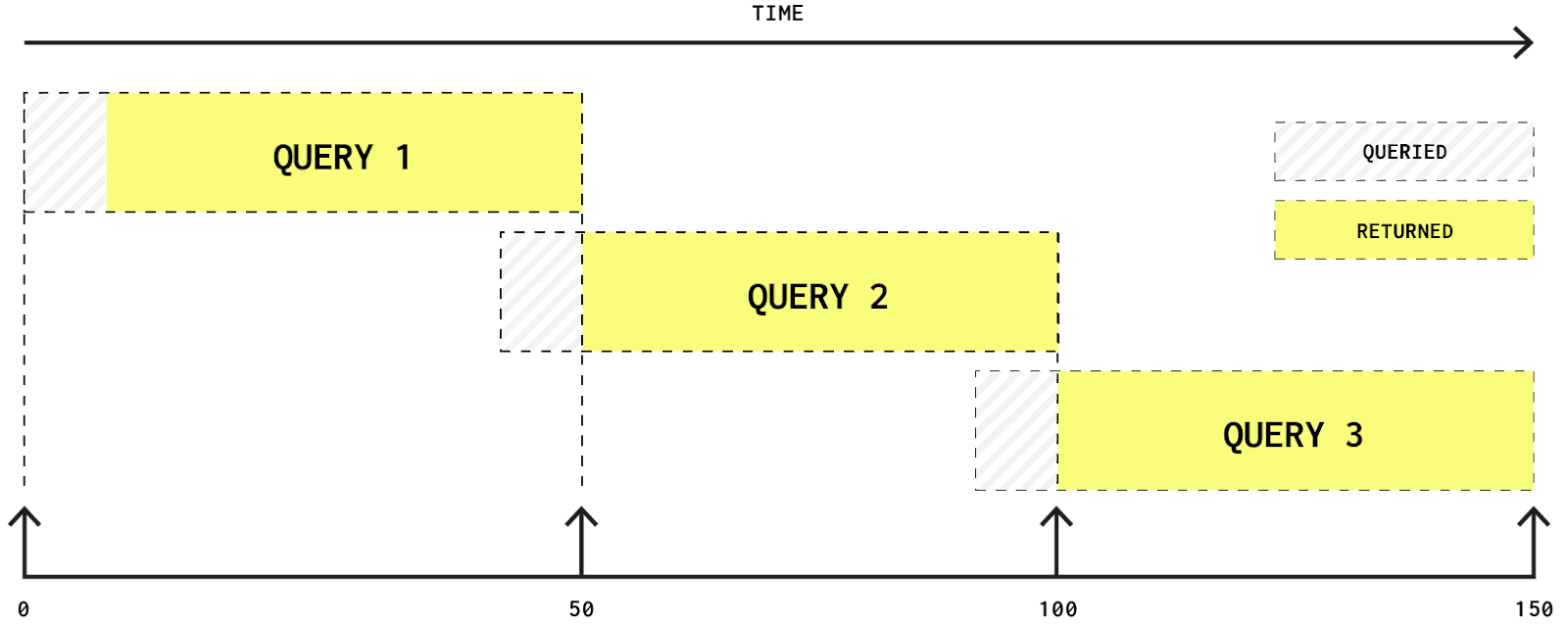
上面的简化图假设每个查询执行正好需要 50 毫秒。我们的查询获取所有列,并计算点差(卖出价和买入价之间的差值)。理想情况下,我们还希望显示当前买入价的变化 - 这在交易中很有用。为了确保每对货币对的第一个值都具有正确的变化值,我们需要确保我们拥有每个货币对当前窗口之外的最后一个价格。为此,我们查询的数据略多于我们返回的数据,如上图和下面的最终查询所示。
SELECT *
FROM
(
SELECT
concat(base, '.', quote) AS base_quote,
datetime AS last_update,
bid,
ask,
ask - bid AS spread,
ask - any(ask) OVER (PARTITION BY base_quote ORDER BY base_quote ASC, datetime ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS chg
FROM forex
WHERE datetime > {prev_lower_bound:DateTime64(3)} AND datetime <= {upper_bound:DateTime64(3)}
ORDER BY
base_quote ASC,
datetime ASC
)
WHERE datetime > {lower_bound:DateTime64(3)} AND datetime <= {upper_bound:DateTime64(3)}
ORDER BY last_update ASC
┌─base_quote─┬─────────────last_update─┬─────bid─┬────────ask─┬──spread─┬──────chg─┐
│ AUD.CAD │ 2024-09-19 13:25:30.840 │ 0.97922 │ 0.97972 │ 0.0005 │ -0.00002 │
│ XAG.USD │ 2024-09-19 13:25:30.840 │ 17.858 │ 17.90299 │ 0.04499 │ 0.00499 │
│ AUD.JPY │ 2024-09-19 13:25:30.840 │ 97.28 │ 97.31 │ 0.03 │ -0.001 │
│ AUD.NZD │ 2024-09-19 13:25:30.840 │ 1.09886 │ 1.09946 │ 0.0006 │ 0.00004 │
...
│ EUR.AUD │ 2024-09-19 13:25:30.840 │ 1.43734 │ 1.43774 │ 0.0004 │ -0.00002 │
└────────────┴─────────────────────────┴─────────┴────────────┴─────────┴──────────┘
25 rows in set. Elapsed: 0.012 sec. Processed 24.57 thousand rows, 638.82 KB (2.11 million rows/s., 54.98 MB/s.)
Peak memory usage: 5.10 MiB.
请注意,我们如何将时间范围过滤器应用于 argMax,这样我们就不需要对时间 < 下限的所有行执行完整扫描(而是 下限 - 5 分钟 < 时间 < 下限)。
我们用于获取下一行的最终函数可以在 此处 找到。这使用了上述查询,以 Arrow 格式请求数据,并将响应读取到 Perspective 所需的 ArrayBuffer 中。
我们没有使用 ClickHouse JS 库,主要是为了最大限度地减少依赖项,但也因为我们的代码非常简单。我们建议复杂的应用程序使用它。
初始应用程序
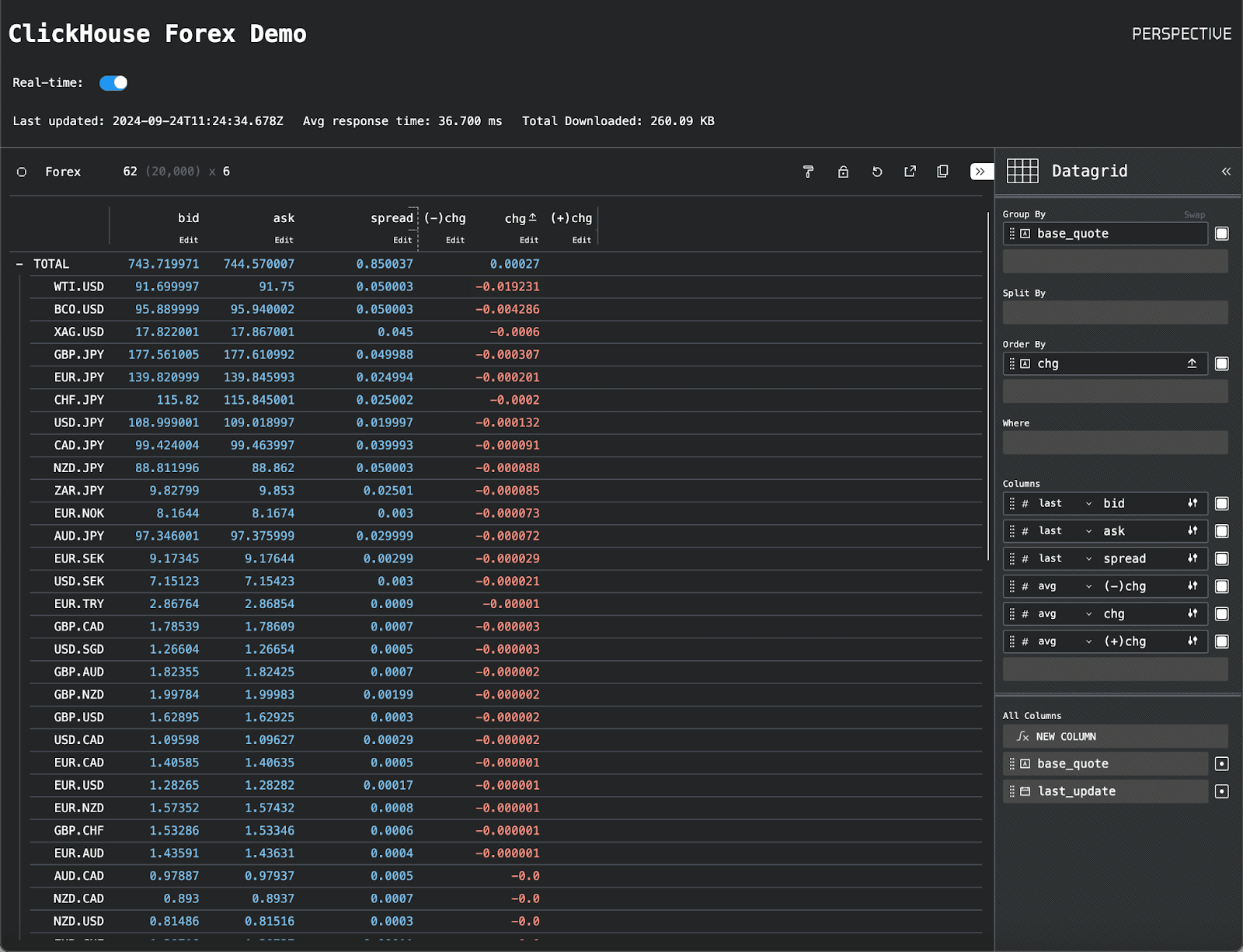
我们的应用程序(如下所示)调用上述函数 在一个连续循环中获取行
我们的 循环还计算平均获取时间(在最新的 10 个请求中取平均值)。此处的性能将取决于您与 ClickHouse 集群的距离,延迟主要受 HTTP 获取时间的影响。在与 ClickHouse 服务相当接近的情况下,我们能够将此时间减少到大约 30 毫秒。
虽然我们显示了数据网格以进行开箱即用的可视化,但用户可以轻松修改可视化类型并应用转换。在下面的示例中,我们切换到散点可视化,以绘制 EUR-GBP 货币对的买入价和卖出价。
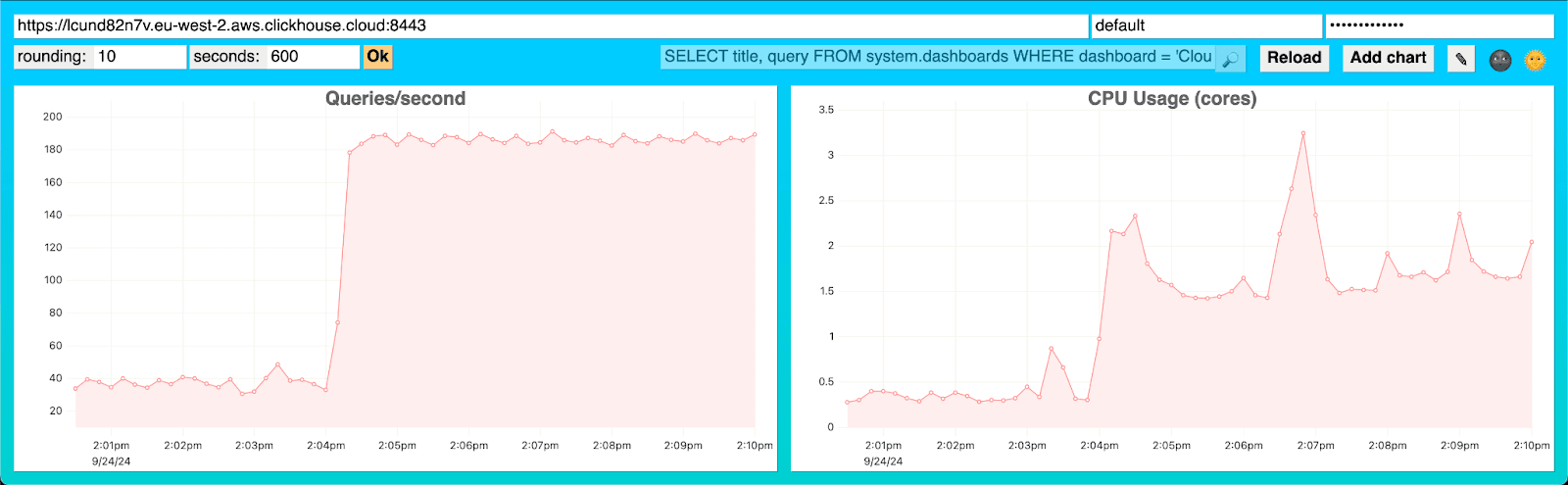
为了测试 CPU 负载,我们启动了 20 个并发客户端,导致每秒几乎有 200 个查询。即使在这种负载下,ClickHouse 也只使用了不到 2 个核心。
还不是真正的流式传输
实际上,在真实场景中,如果由于 ClickHouse 的最终一致性模型而跟踪当前时间,则上述方法可能会遗漏行。即使可以通过仔细配置来缓解这种情况,但这也不是最佳选择。行也可能产生一些插入延迟,因此我们希望将查询从当前时间偏移,而不是仅仅使用 now()。
我们承认这些不足之处,并已开始 探索流式查询的概念,这将可靠地仅返回与指定查询匹配的新行。这将消除轮询的需要,客户端只需使用查询打开 HTTP 连接,并在行到达时接收行。
速度测试 - 使用 Arrow Stream
虽然实时跟踪变动价位可能是最有用的,但我们很好奇 Perspective 实际上可以多快地处理数据。为此,我们希望以升序日期顺序将整个数据集流式传输到 Perspective,再次仅保留最后的 N 个数据点。在这种情况下,我们的查询变为
SELECT concat(base, '.', quote) AS base_quote,
datetime AS last_update,
CAST(bid, 'Float32') AS bid,
CAST(ask, 'Float32') AS ask,
ask - bid AS spread
FROM forex
ORDER BY datetime ASC
FORMAT ArrowStream
SETTINGS output_format_arrow_compression_method='none'
请注意,我们如何取消了每个货币对的变化计算。这需要一个窗口函数,该函数不利用 optimize_read_in_order,并阻止结果的立即流式传输。
为此,您会注意到我们不仅仅使用 Arrow 格式。这将要求我们下载 ClickHouse 中压缩的整个数据集(>60GB),并将其转换为 Perspective 的表。即使是 Arrow 格式,对于浏览器来说也有点大!
相反,我们利用 ClickHouse 对 Arrow Stream 格式的支持,以块读取数据并将其传递给 perspective。虽然以前我们可以在没有依赖项的情况下完成所有工作,但为此我们需要 Arrow js lib。虽然这使得使用 Arrow 文件变得很简单,但为了支持流式传输,我们需要更多 JS 代码。下面显示了我们一次批量流式传输整个数据集的最终函数。
async function get_all_rows(table, lower_bound) {
const view = await table.view({ // Create a view with aggregation to get the maximum datetime value
columns: ["last_update"], // Column you're interested in
aggregates: { last_update: "max" } // Aggregate by the maximum of datetime
});
const response = await fetch(clickhouse_url, {
method: 'POST',
body: `SELECT concat(base, '.', quote) AS base_quote, datetime AS last_update, bid::Float32 as bid, ask::Float32 as ask, ask - bid AS spread
FROM forex WHERE datetime > ${lower_bound}::DateTime64(3) ORDER BY datetime ASC FORMAT ArrowStream SETTINGS output_format_arrow_compression_method='none'`,
headers: { 'Authorization': `Basic ${credentials}` }
});
const reader = await RecordBatchReader.from(response);
await reader.open();
for await (const recordBatch of reader) { // Continuously read from the stream
if (real_time) { // set to false if we want to stop the stream
await view.delete();
return;
}
const batchTable = new Table(recordBatch); // currently required, see https://github.com/finos/perspective/issues/1157
const ipcStream = tableToIPC(batchTable, 'stream');
const bytes = new Uint8Array(ipcStream);
table.update(bytes);
const result = await view.to_columns();
const maxDateTime = result["last_update"][0];
document.getElementById("last_updated").textContent = `Last updated: ${new Date(maxDateTime).toISOString()}`;
total_size += (bytes.length);
document.getElementById("total_download").textContent = `Total Downloaded: ${prettyPrintSize(total_size,2)}`;
}
}
此代码可能比现在更高效 - 主要是因为 Perspective 目前需要字节数组才能进行更新调用。这迫使我们将批处理转换为表,并将表流式传输到数组。我们还使用 Perspective 视图,在概念上类似于 ClickHouse 中的物化视图 - 在加载表数据时对其执行聚合。在本例中,我们使用视图来简单地计算最大流式传输日期,这将在最终 UI 中显示。
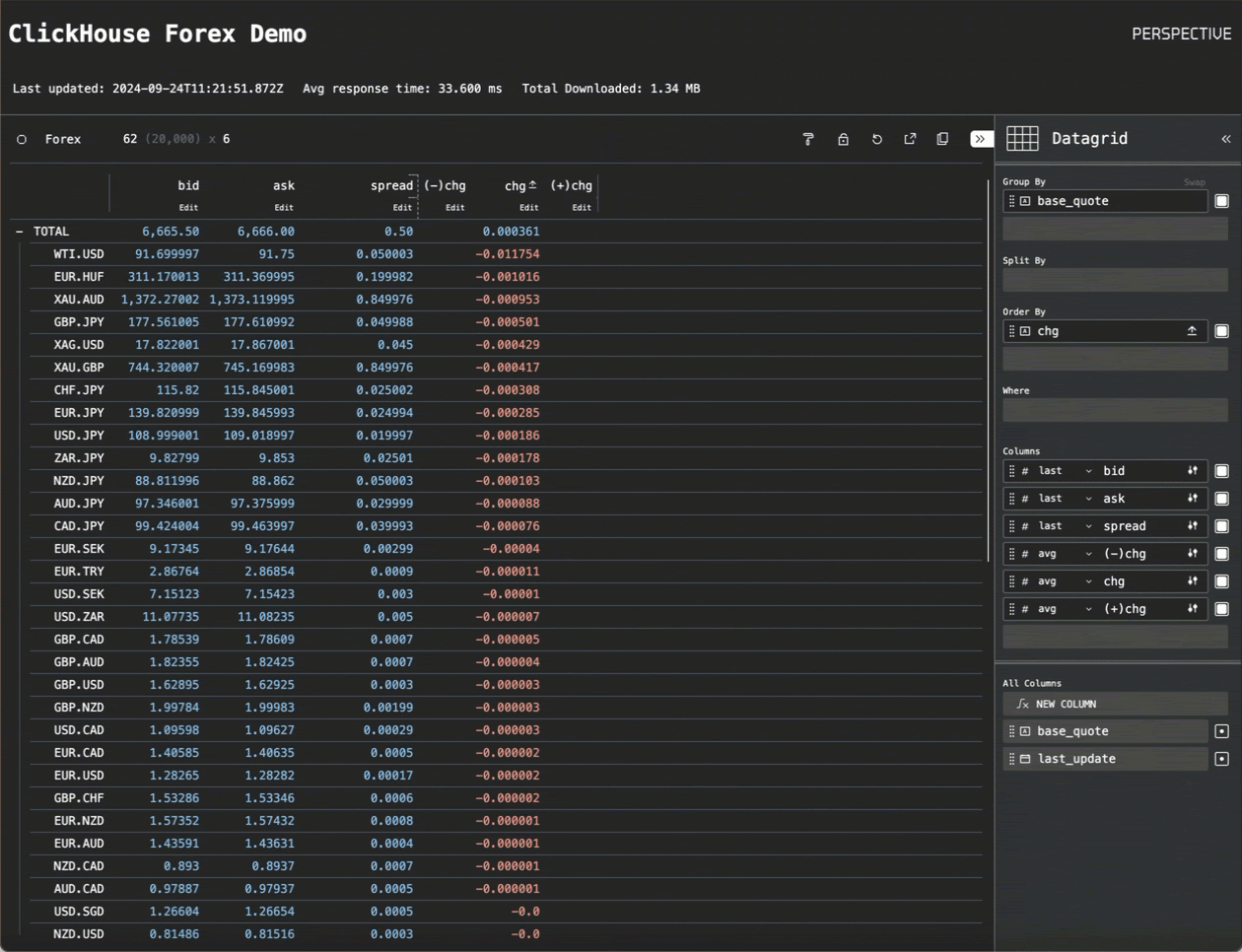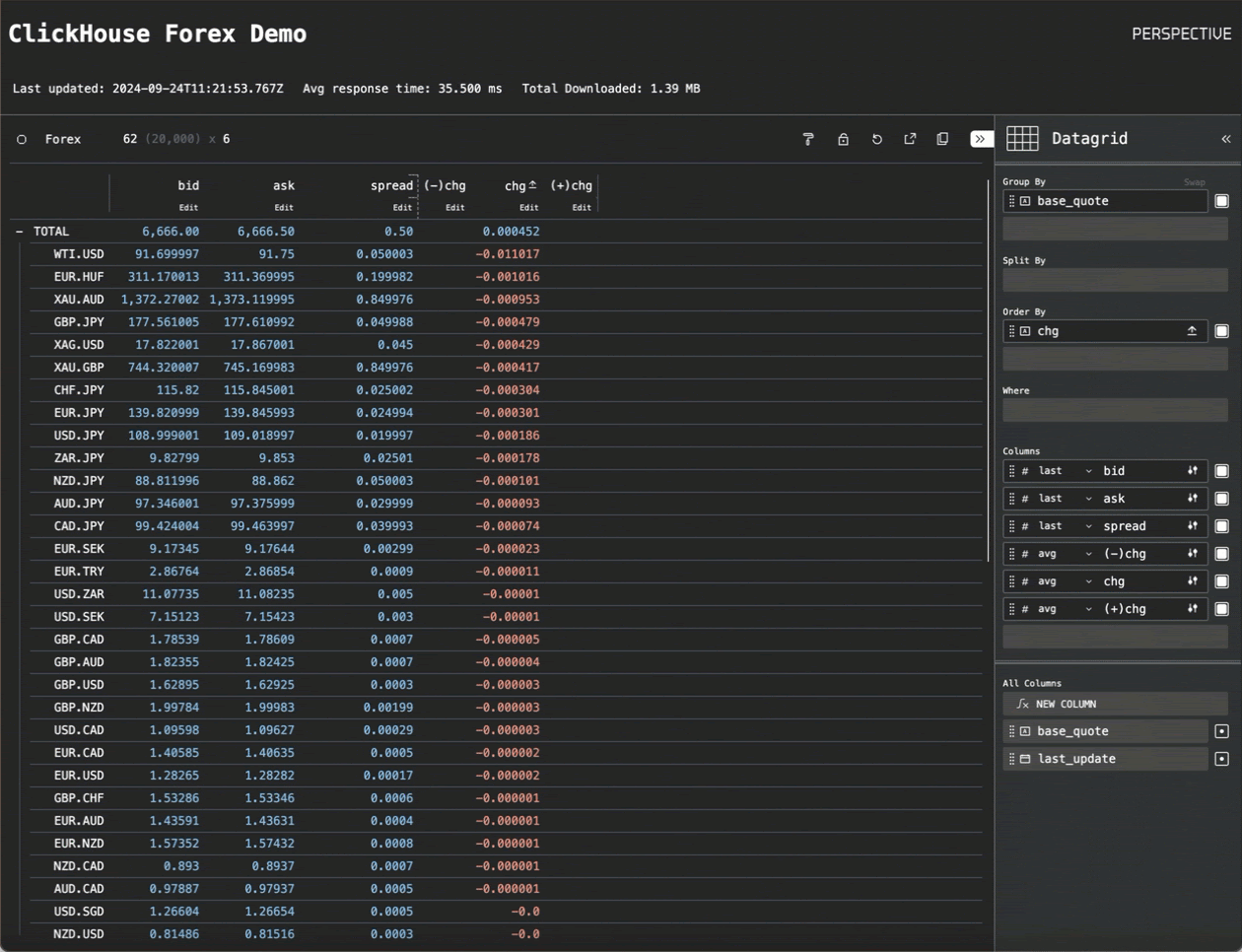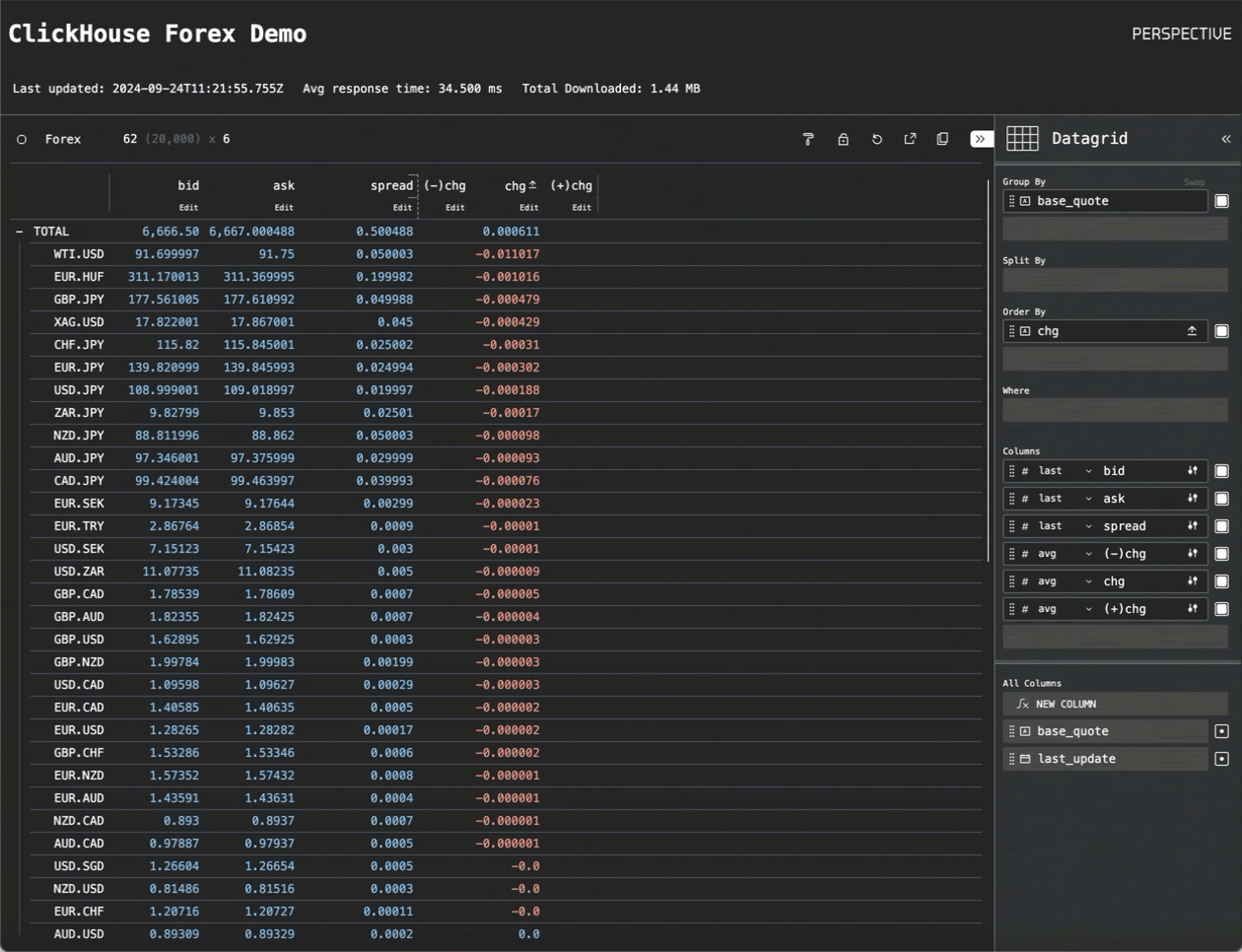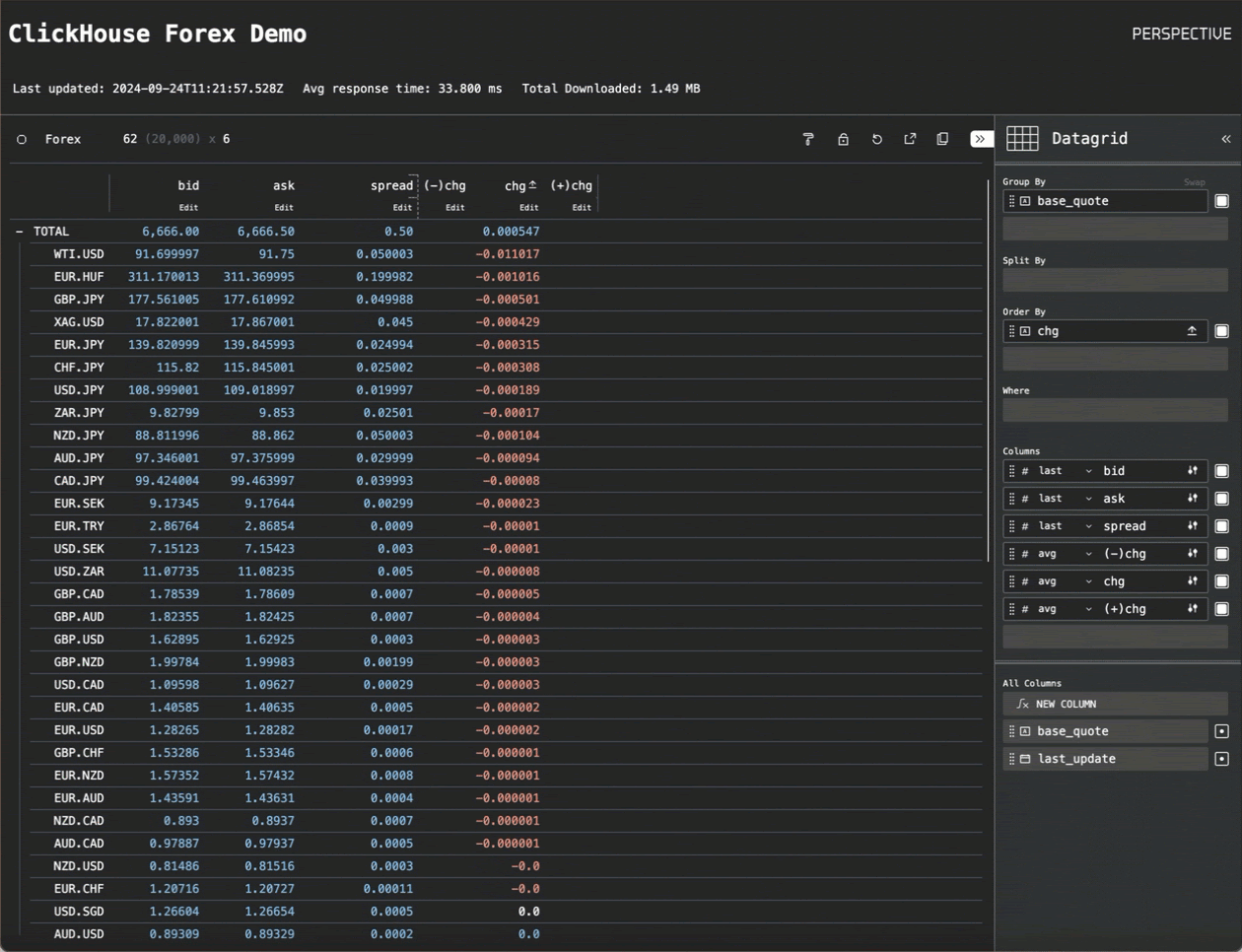
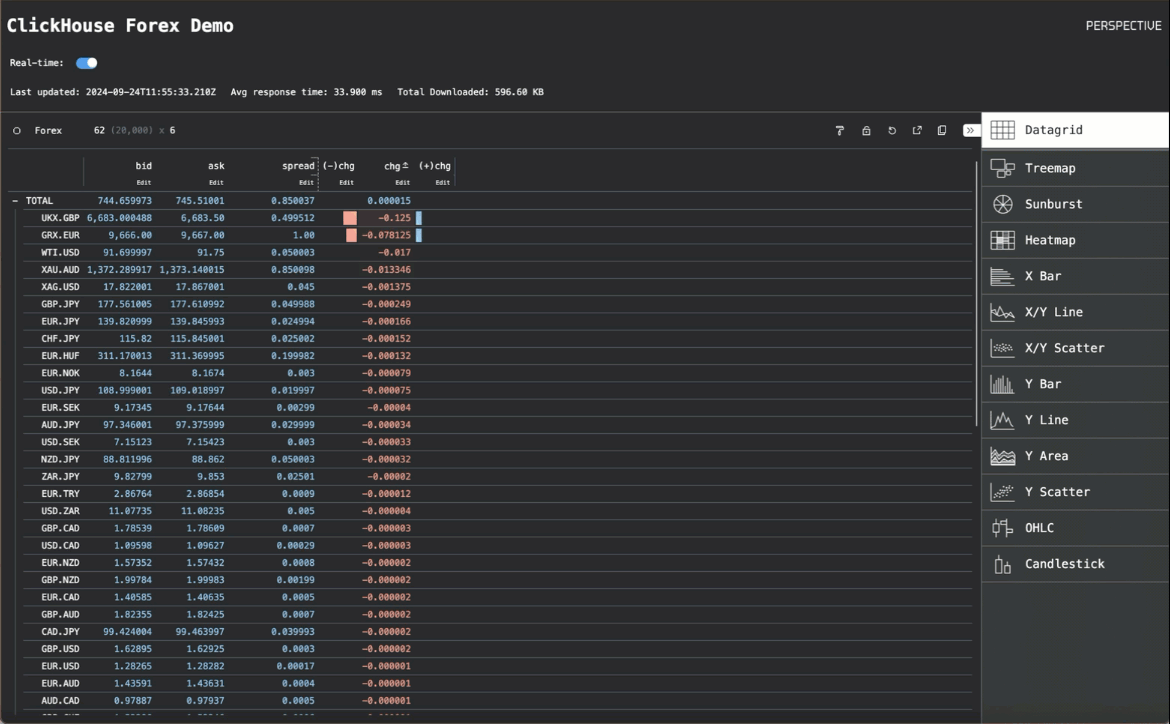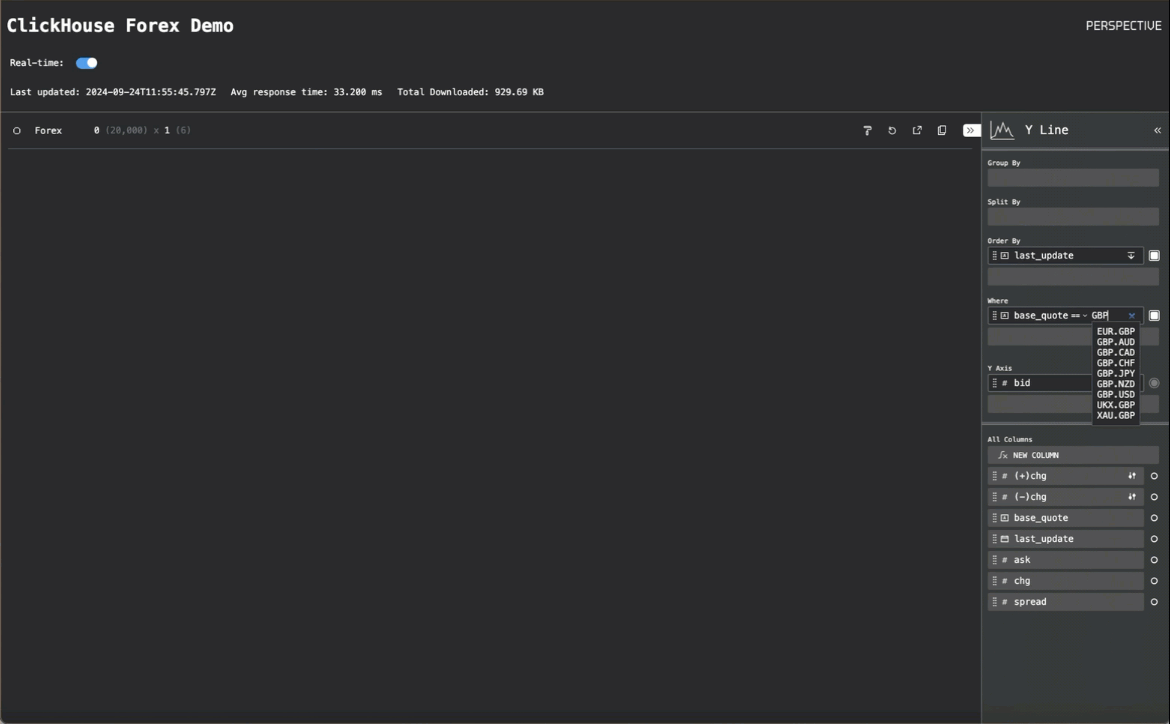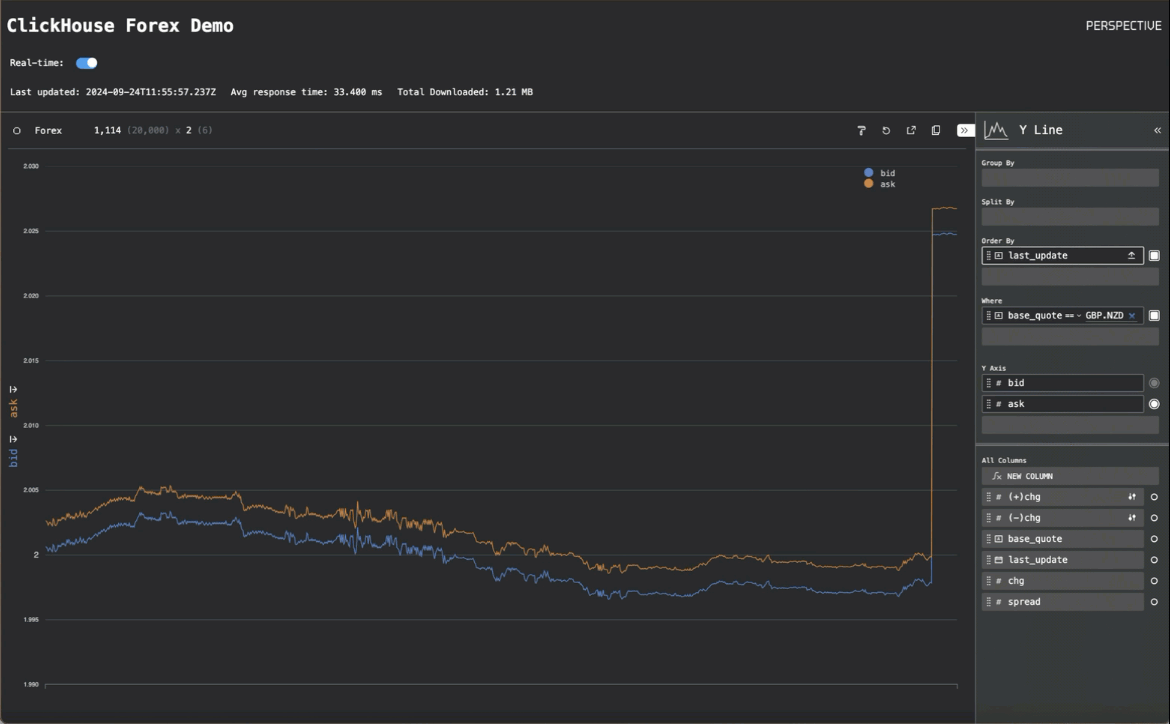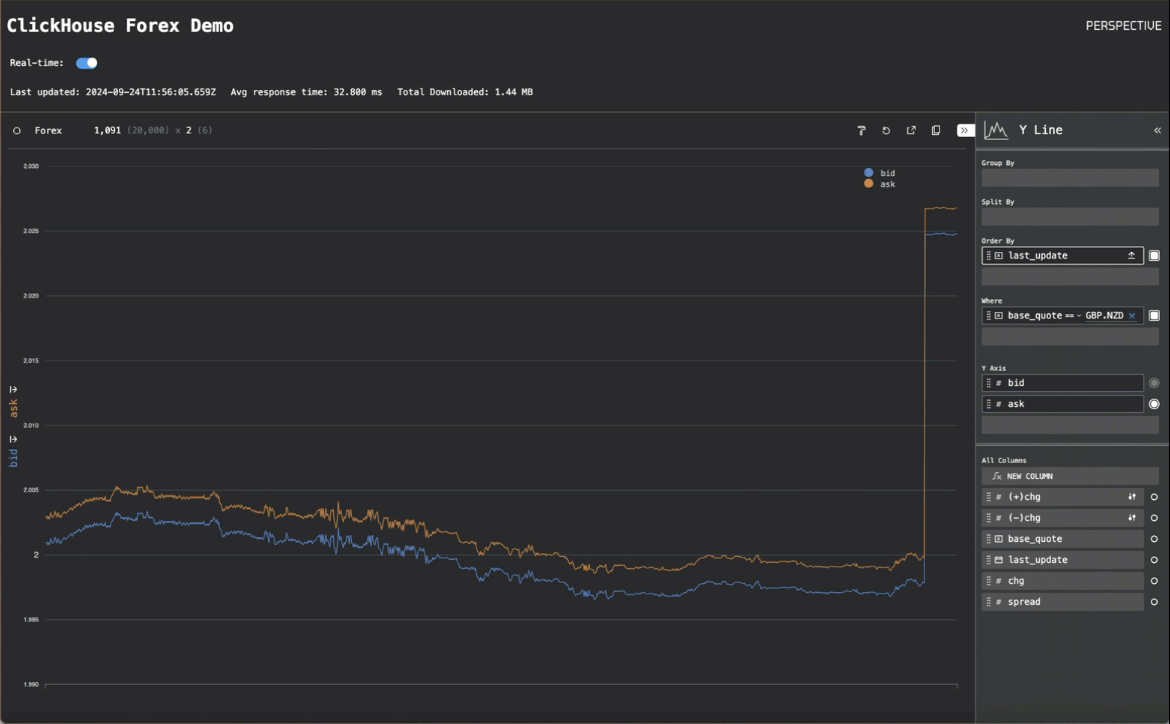
通过一些额外的代码在早期的“实时”轮询模式和此“流式传输模式”之间切换,我们就有了最终的应用程序。切换到流式传输模式显示了 Perspective 的性能
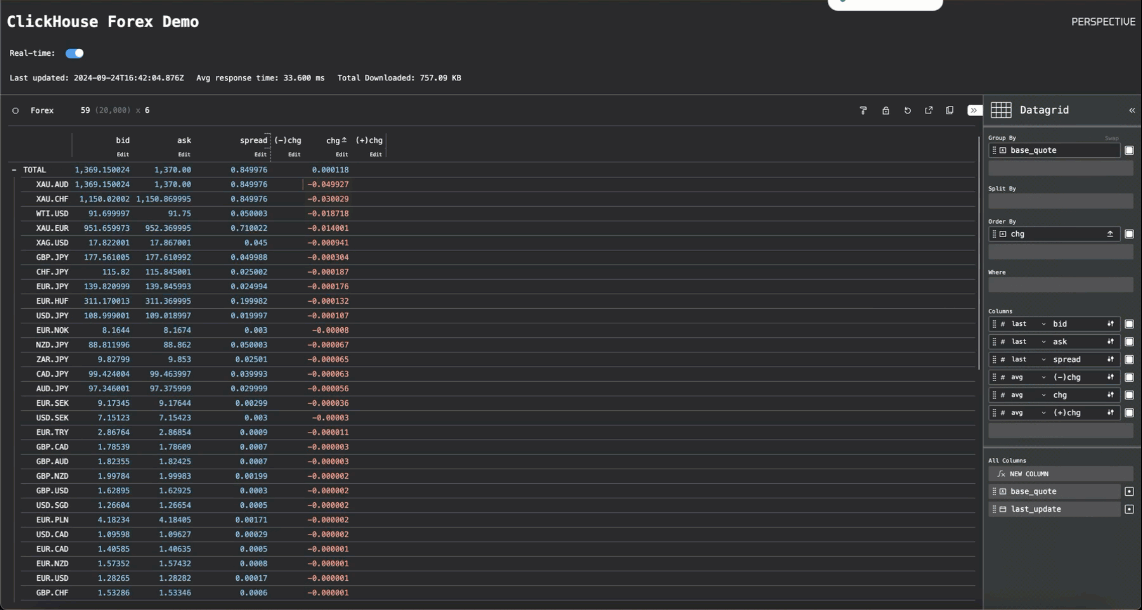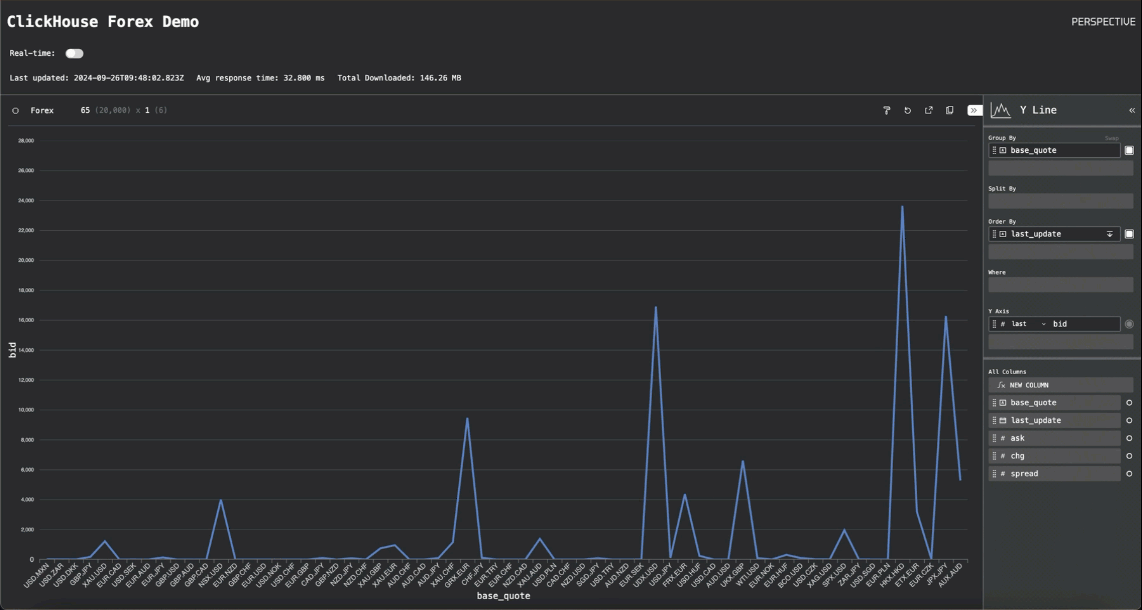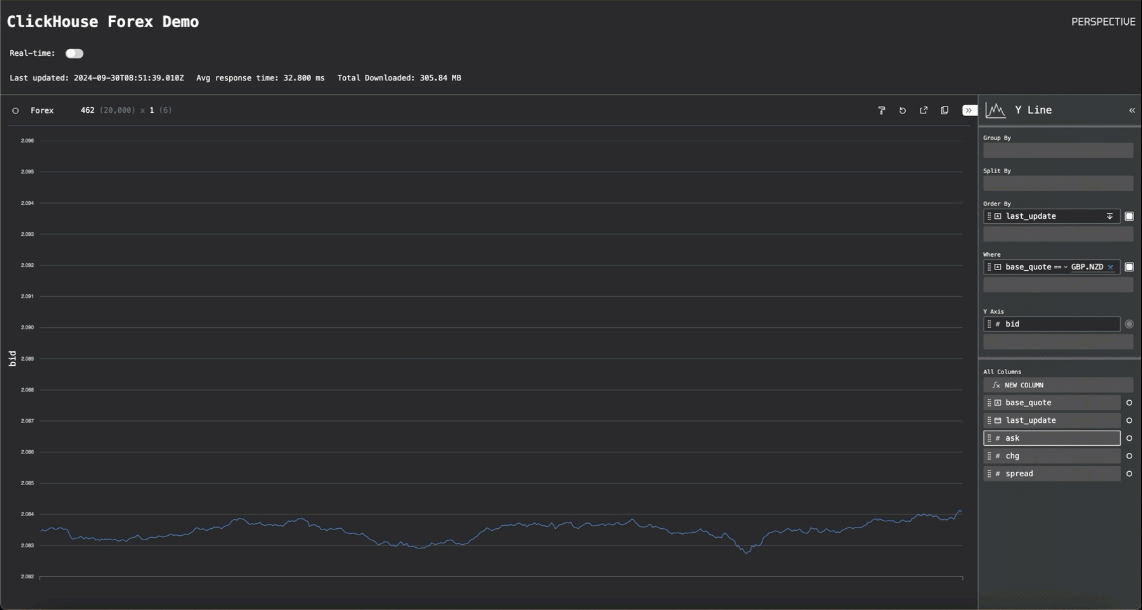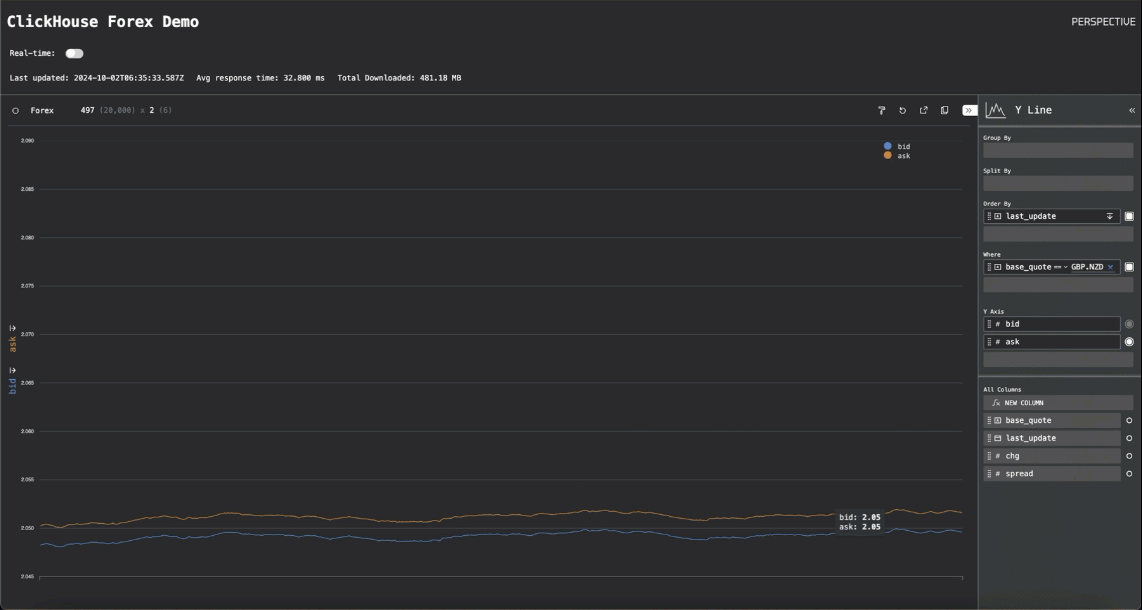
货币对的折线图显示了我们如何能够每秒渲染数千个数据点,并且至少以 25MiB/秒的速度流式传输到浏览器。
您可以在 此处 试用最终应用程序。
结论
我们使用这篇博客来探索一个流行的开源可视化库 Perspective,它在性能和处理快速到达的大量数据的能力方面与 ClickHouse 具有协同作用,因此对于 ClickHouse 具有有用的应用!感谢 Apache Arrow,我们只需几行 JavaScript 代码即可将 ClickHouse 与 Perspective 集成。在此过程中,我们还发现了 ClickHouse 处理流式数据能力的一些限制,并重点介绍了我们希望解决这些限制的当前工作。


