横向扩展
描述
此示例架构旨在提供可扩展性。它包括三个节点:两个组合的 ClickHouse 加协调(ClickHouse Keeper)服务器,以及第三个仅包含 ClickHouse Keeper 的服务器,以完成三个节点的法定数量。通过此示例,我们将创建一个数据库、表和一个分布式表,该表能够查询两个节点上的数据。
级别:基础
术语
副本 (Replica)
数据的副本。ClickHouse 始终至少有一个数据副本,因此**副本**的最小数量为一个。这是一个重要的细节,您可能不习惯将数据的原始副本算作副本,但这是 ClickHouse 代码和文档中使用的术语。添加数据的第二个副本可提供容错能力。
分片 (Shard)
数据的子集。ClickHouse 始终至少有一个数据分片,因此,如果您不跨多个服务器拆分数据,则数据将存储在一个分片中。如果超出单个服务器的容量,则可以使用跨多个服务器对数据进行分片来分担负载。目标服务器由**分片键**确定,并在创建分布式表时定义。分片键可以是随机的,也可以是哈希函数的输出。涉及分片的部署示例将使用 rand() 作为分片键,并将提供有关何时以及如何选择不同分片键的更多信息。
分布式协调
ClickHouse Keeper 为数据复制和分布式 DDL 查询执行提供协调系统。ClickHouse Keeper 与 Apache ZooKeeper 兼容。
环境
架构图
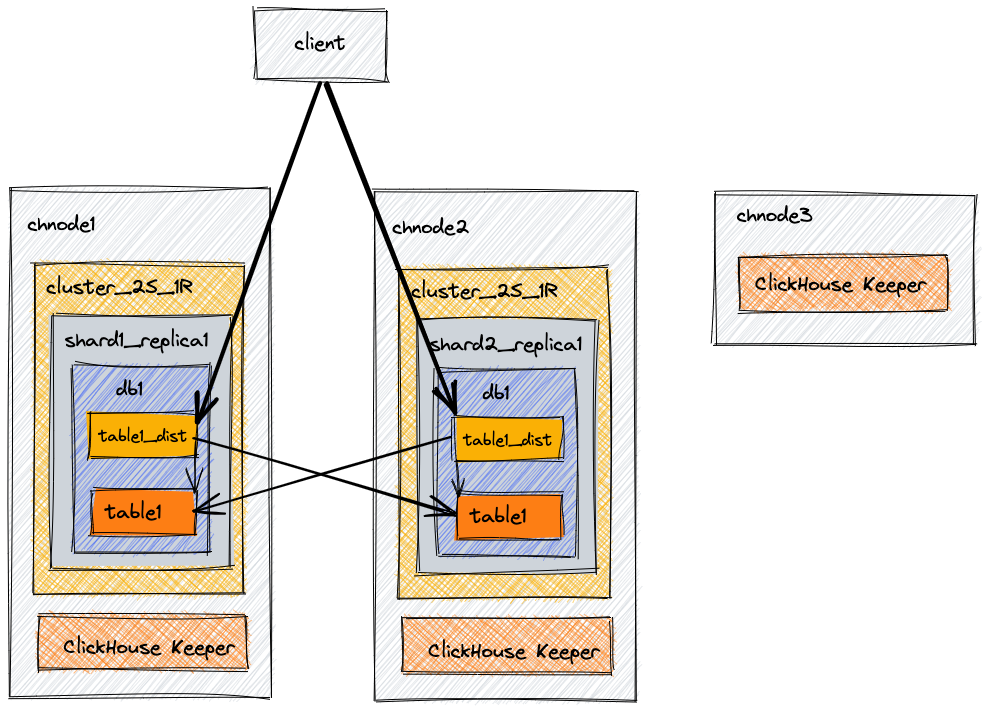
| 节点 | 描述 |
|---|---|
chnode1 | 数据 + ClickHouse Keeper |
chnode2 | 数据 + ClickHouse Keeper |
chnode3 | 用于 ClickHouse Keeper 法定数量 |
在生产环境中,我们强烈建议 ClickHouse Keeper 在专用主机上运行。此基本配置在 ClickHouse Server 进程中运行 Keeper 功能。有关独立部署 ClickHouse Keeper 的说明,请参见安装文档。
安装
按照适用于您的存档类型(.deb、.rpm、.tar.gz 等)的说明,在三台服务器上安装 ClickHouse。对于此示例,您将在所有三台机器上按照 ClickHouse Server 和 Client 的安装说明进行操作。
编辑配置文件
通过添加或编辑配置文件来配置 ClickHouse Server 时,您应该
- 将文件添加到
/etc/clickhouse-server/config.d/目录 - 将文件添加到
/etc/clickhouse-server/users.d/目录 - 保持
/etc/clickhouse-server/config.xml文件不变 - 保持
/etc/clickhouse-server/users.xml文件不变
chnode1 配置
对于 chnode1,有五个配置文件。您可以选择将这些文件合并为一个文件,但为了文档的清晰起见,分别查看它们可能更简单。当您阅读配置文件时,您会看到 chnode1 和 chnode2 之间的大部分配置是相同的;差异将被突出显示。
网络和日志配置
这些值可以根据您的需要进行自定义。此示例配置为您提供了一个调试日志,该日志将滚动 1000M 三次。ClickHouse 将监听 IPv4 网络上的端口 8123 和 9000,并将使用端口 9009 进行服务器间通信。
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper 配置
ClickHouse Keeper 为数据复制和分布式 DDL 查询执行提供协调系统。ClickHouse Keeper 与 Apache ZooKeeper 兼容。此配置在端口 9181 上启用 ClickHouse Keeper。突出显示的一行指定此 Keeper 实例的 server_id 为 1。这是三个服务器中 enable-keeper.xml 文件中唯一的区别。chnode2 的 server_id 将设置为 2,chnode3 的 server_id 将设置为 3。raft 配置部分在所有三个服务器上都是相同的,并且在下面突出显示,以向您展示 server_id 与 raft 配置中 server 实例之间的关系。
如果由于任何原因更换或重建 Keeper 节点,请勿重复使用现有的 server_id。例如,如果重建了 server_id 为 2 的 Keeper 节点,则为其指定 4 或更高的 server_id。
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>1</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
宏配置
宏 shard 和 replica 降低了分布式 DDL 的复杂性。配置的值会自动替换到您的 DDL 查询中,从而简化了您的 DDL。此配置的宏指定了每个节点的分片和副本编号。
在此 2 分片 1 副本示例中,副本宏在 chnode1 和 chnode2 上均为 replica_1,因为只有一个副本。分片宏在 chnode1 上为 1,在 chnode2 上为 2。
<clickhouse>
<macros>
<shard>1</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
复制和分片配置
从顶部开始
- XML 的
remote_servers部分指定了环境中的每个集群。属性replace=true将默认 ClickHouse 配置中的示例remote_servers替换为此文件中指定的remote_servers配置。如果没有此属性,则此文件中的远程服务器将附加到默认配置中的示例列表中。 - 在此示例中,有一个名为
cluster_2S_1R的集群。 - 为名为
cluster_2S_1R的集群创建了一个密钥,其值为mysecretphrase。该密钥在环境中的所有远程服务器之间共享,以确保正确的服务器连接在一起。 - 集群
cluster_2S_1R有两个分片,并且每个分片都有一个副本。查看本文档开头的架构图,并将其与下面 XML 中的两个shard定义进行比较。在每个分片定义中,都有一个副本。该副本用于该特定分片。指定了该副本的主机和端口。配置中第一个分片的副本存储在chnode1上,配置中第二个分片的副本存储在chnode2上。 - 分片的内部复制设置为 true。每个分片都可以在配置文件中定义
internal_replication参数。如果此参数设置为 true,则写入操作将选择第一个健康的副本并将数据写入其中。
<clickhouse>
<remote_servers replace="true">
<cluster_2S_1R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_2S_1R>
</remote_servers>
</clickhouse>
配置 Keeper 的使用
在上面的一些文件中,配置了 ClickHouse Keeper。此配置文件 use-keeper.xml 配置 ClickHouse Server 使用 ClickHouse Keeper 来协调复制和分布式 DDL。此文件指定 ClickHouse Server 应在端口 9181 上使用节点 chnode1 - 3 上的 Keeper,并且该文件在 chnode1 和 chnode2 上是相同的。
<clickhouse>
<zookeeper>
<node index="1">
<host>chnode1</host>
<port>9181</port>
</node>
<node index="2">
<host>chnode2</host>
<port>9181</port>
</node>
<node index="3">
<host>chnode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
chnode2 配置
由于 chnode1 和 chnode2 上的配置非常相似,因此此处仅指出差异。
网络和日志配置
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper 配置
此文件包含 chnode1 和 chnode2 之间的两个差异之一。在 Keeper 配置中,server_id 设置为 2。
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>2</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
宏配置
宏配置具有 chnode1 和 chnode2 之间的差异之一。在此节点上,shard 设置为 2。
<clickhouse>
<macros>
<shard>2</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
复制和分片配置
<clickhouse>
<remote_servers replace="true">
<cluster_2S_1R>
<secret>mysecretphrase</secret>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_2S_1R>
</remote_servers>
</clickhouse>
配置 Keeper 的使用
<clickhouse>
<zookeeper>
<node index="1">
<host>chnode1</host>
<port>9181</port>
</node>
<node index="2">
<host>chnode2</host>
<port>9181</port>
</node>
<node index="3">
<host>chnode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
chnode3 配置
由于 chnode3 不存储数据,仅用于 ClickHouse Keeper 以提供法定数量中的第三个节点,因此 chnode3 只有两个配置文件,一个用于配置网络和日志记录,另一个用于配置 ClickHouse Keeper。
网络和日志配置
<clickhouse>
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
</clickhouse>
ClickHouse Keeper 配置
<clickhouse>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>chnode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>chnode2</hostname>
<port>9234</port>
</server>
<server>
<id>3</id>
<hostname>chnode3</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
测试
- 连接到
chnode1并验证上面配置的集群cluster_2S_1R是否存在
SHOW CLUSTERS
┌─cluster───────┐
│ cluster_2S_1R │
└───────────────┘
- 在集群上创建数据库
CREATE DATABASE db1 ON CLUSTER cluster_2S_1R
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode2 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode1 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- 在集群上使用 MergeTree 表引擎创建表。
我们不需要在表引擎上指定参数,因为这些参数将根据我们的宏自动定义
CREATE TABLE db1.table1 ON CLUSTER cluster_2S_1R
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode1 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode2 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- 连接到
chnode1并插入一行
INSERT INTO db1.table1 (id, column1) VALUES (1, 'abc');
- 连接到
chnode2并插入一行
INSERT INTO db1.table1 (id, column1) VALUES (2, 'def');
- 连接到任一节点
chnode1或chnode2,您将只看到插入到该节点上表中的行。例如,在chnode2上
SELECT * FROM db1.table1;
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
- 创建一个分布式表以查询两个节点上的两个分片。(在此示例中,
rand()函数设置为分片键,以便随机分配每个插入)
CREATE TABLE db1.table1_dist ON CLUSTER cluster_2S_1R
(
`id` UInt64,
`column1` String
)
ENGINE = Distributed('cluster_2S_1R', 'db1', 'table1', rand())
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode2 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode1 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
- 连接到
chnode1或chnode2中的任何一个并查询分布式表以查看两行。
SELECT * FROM db1.table1_dist;
┌─id─┬─column1─┐
│ 2 │ def │
└────┴─────────┘
┌─id─┬─column1─┐
│ 1 │ abc │
└────┴─────────┘