这篇博客最初发布于 2019 年。我们重新发布此文,以致敬 LZ 系列算法的作者:Abraham Lempel 和 Jacob Ziv,他们最近去世了。
人们可能会倾向于认为每个新功能都是新颖的,每个新版本都将改变市场。然而,作为一个行业,我们是站在巨人的肩膀上的。Jacob 对信息论的贡献(除了压缩算法之外)一直是并将继续激励着一代又一代的从业者和研究人员。
简介
当您在 ClickHouse 中运行查询时,您可能会注意到性能分析器经常显示 LZ_decompress_fast 函数位于顶部附近。这是怎么回事?这个问题让我们想知道如何选择最佳的压缩算法。
ClickHouse 以压缩形式存储数据。在运行查询时,ClickHouse 尽量少做操作,以节省 CPU 资源。在许多情况下,所有可能耗时的计算都已经过很好的优化,加上用户编写了一个经过深思熟虑的查询。那么剩下的就是执行解压缩。

那么为什么 LZ4 解压缩会成为瓶颈呢?LZ4 看起来像是一个极其轻量级的算法:数据解压缩速率通常为每个处理器核心 1 到 3 GB/秒,具体取决于数据。这比典型的磁盘子系统快得多。此外,我们使用所有可用的 CPU 核心,并且解压缩在所有物理核心上线性扩展。
但是,有两点需要记住。首先,压缩数据是从磁盘读取的,但解压缩速度是以未压缩数据量来衡量的。如果压缩率足够大,那么从磁盘读取的内容几乎为零。但是会有大量的解压缩数据,这自然会影响 CPU 利用率:在 LZ4 的情况下,解压缩数据所需的工作量几乎与解压缩数据本身的体积成正比。
其次,如果数据被缓存,您可能根本不需要从磁盘读取数据。您可以依赖页面缓存或使用您自己的缓存。缓存对于面向列的数据库更有效,因为只有经常使用的列才会保留在缓存中。这就是为什么 LZ4 通常看起来是 CPU 负载的瓶颈。
这引出了另外两个问题。首先,如果解压缩拖慢了我们的速度,那么一开始压缩数据是否值得?但在实践中,这种推测是不相关的。ClickHouse 提供了几种压缩选项,主要是 LZ4 和 Zstandard。默认使用 LZ4。切换到 Zstandard 可以使压缩更强,但速度更慢。但是没有完全禁用压缩的选项,因为 LZ4 被认为提供了始终可以使用的合理的最小压缩。(这正是我喜欢 LZ4 的原因。)
但随后,一位神秘的陌生人出现在 ClickHouse 电报支持群中,他说他有一个非常快速的磁盘子系统(使用 NVMe SSD),解压缩是唯一拖慢他查询速度的东西,因此如果能够存储没有压缩的数据就好了。我回复说我们没有这个选项,但添加起来很容易。几天后,我们收到了一个实现无压缩方法(none)的 pull request。我要求贡献者反馈这个选项在加速查询方面有多大帮助。回复是,这个新功能在实践中被证明是无用的,因为未压缩的数据开始占用太多磁盘空间,并且无法容纳在那些 NVMe 驱动器中。
由此产生的第二个问题是,如果存在缓存,为什么不使用它来存储已经解压缩的数据呢?这是一种可行的可能性,可以在许多情况下消除解压缩的需要。ClickHouse 也有这样的缓存:解压缩块的缓存。但是在这上面浪费大量 RAM 是很可惜的。因此,通常只在小型、顺序查询中使用几乎相同的数据时才有意义。
因此,我们的结论是,始终最好以压缩格式存储数据。始终以压缩格式将数据写入磁盘。通过网络传输数据时也要进行压缩。在我看来,即使在没有过载的 10 GB 网络中的单个数据中心内传输数据时,默认压缩也是合理的,而在数据中心之间传输未压缩数据是不可接受的。
为什么选择 LZ4?
为什么要选择 LZ4?难道我们不能选择更轻量级的东西吗?理论上,我们可以,这是一个很好的想法。但让我们看看 LZ4 所属的算法类别。
首先,它是通用的,不适应数据类型。例如,如果您预先知道您将拥有一个整数数组,则可以使用 VarInt 算法之一,这将更有效地利用 CPU。其次,LZ4 并不过度依赖数据模型假设。假设您有一个传感器值的有序时间序列和一个浮点数数组。如果您考虑这一点,您可以计算这些数字之间的增量,然后使用通用算法压缩它们,这将导致更高的压缩率。
使用 LZ4 处理任何字节数组或文件都不会有任何问题。当然,它确实有其专业化(稍后会详细介绍),在某些情况下,使用它是没有意义的。但是,如果我们将其称为通用算法,那就相当接近事实了。我们应该注意到,由于其内部设计,LZ4 自动实现了 RLE 算法作为一种特殊情况。
然而,更重要的问题是,就整体速度和压缩强度而言,LZ4 是否是此类算法中最优的算法。最优算法被称为帕累托前沿,这意味着没有其他算法在某一方面绝对更好,而在其他方面又不差(并且在各种数据集上也是如此)。有些算法速度更快,但压缩率较低,而另一些算法具有更强的压缩率,但压缩或解压缩速度较慢。
老实说,LZ4 并不是真正的帕累托前沿——有一些选项稍微好一点。例如,看看开发者昵称为 powturbo 的 LZTURBO。结果的可靠性毋庸置疑,这要归功于 encode.su 社区(最大且可能是唯一的数据压缩论坛)。不幸的是,开发者不分发源代码或二进制文件;它们仅供少数人用于测试或高价购买。另外,看看 Lizard(以前称为 LZ5)和 Density。当您选择某个压缩级别时,它们可能会比 LZ4 稍好一些。另一个非常有趣的选项是 LZSSE。但在您查看它之前,请先读完这篇文章。
LZ4 的工作原理
让我们看看 LZ4 的总体工作原理。这是 LZ77 算法的实现之一。L 和 Z 代表开发者的名字(Lempel 和 Ziv),77 代表 1977 年,算法发布的时间。它还有许多其他实现:QuickLZ、FastLZ、BriefLZ、LZF、LZO,以及低压缩级别的 gzip 和 zip。
使用 LZ4 压缩的数据块包含两种类型的条目(命令或指令)序列
- 字面量:“按原样获取以下 N 个字节,并将它们复制到结果中”。
- 匹配:“从解压缩结果中,从相对于当前位置的偏移值开始,获取 N 个字节”。
示例。压缩前
Hello world Hello
压缩后
literals 12 "Hello world " match 5 12
如果我们获取一个压缩块并在运行这些命令时迭代光标遍历它,我们将获得原始的未压缩数据作为结果。
这就是数据解压缩的基本原理。基本思想很明确:为了执行压缩,该算法使用匹配对重复的字节序列进行编码。
一些特性也很明确。这种面向字节的算法不会剖析单个字节;它只会完整地复制它们。这就是它与熵编码的不同之处。例如,zstd 是 LZ77 和熵编码的组合。
请注意,压缩块的大小不应太大。选择大小是为了避免在解压缩期间浪费大量 RAM,避免在压缩文件中(由大量压缩块组成)过多地减慢随机访问速度,有时是为了使块适合 CPU 缓存。例如,您可以选择 64 KB,以便压缩和未压缩数据的缓冲区可以容纳在 L2 缓存中,并且仍然有一半空闲。
如果我们需要压缩更大的文件,我们可以连接压缩块。这也便于为每个压缩块存储附加数据(如校验和)。
匹配的最大偏移量是有限制的。在 LZ4 中,限制为 64 KB。这个量称为滑动窗口。这意味着可以在光标之前的 64 KB 窗口中找到匹配项,该窗口随着光标向前移动而滑动。
现在让我们看看如何压缩数据,或者换句话说,如何在文件中查找匹配的序列。您可以始终使用后缀树(如果您听说过这个,那就太好了)。有些方法可以保证最长的匹配项位于压缩后的前导字节中。这称为最佳解析,它为固定格式的压缩块提供了接近最佳的压缩率。但还有更好的方法,例如找到一个足够好的匹配项,而不一定是最佳匹配项。找到它的最有效方法是使用哈希表。
为此,我们迭代光标遍历原始数据块,并在光标后获取几个字节(例如 4 个字节)。我们对它们进行哈希处理,并将从块开始处的偏移量(从那里获取 4 个字节)放入哈希表中。值 4 称为“最小匹配”——使用此哈希表,我们可以找到至少 4 个字节的匹配项。
如果我们查看哈希表,并且它已经有匹配的记录,并且偏移量不超过滑动窗口,我们会检查在那 4 个字节之后有多少字节匹配。可能还有更多匹配项。哈希表中也可能发生冲突,并且没有任何匹配项,但这没什么大不了的。您可以只使用新值替换哈希表中的值。哈希表中的冲突只会导致压缩率降低,因为匹配项会减少。顺便说一句,这种类型的哈希表(具有固定大小且不解决冲突)称为“缓存表”。这个名称是有道理的,因为在发生冲突时,缓存表只会忘记旧条目。
给细心读者的一个挑战。假设数据是一个小端格式的 UInt32 数字数组,它表示自然数序列的一部分:0、1、2… 解释一下为什么在使用 LZ4 时,此数据没有被压缩(压缩数据的大小与未压缩数据的大小相比没有缩小)。
如何加速一切
所以我想加速 LZ4 解压缩。让我们看看解压缩循环是什么样的。这是伪代码
while (...)
{
read(input_pos, literal_length, match_length);
copy(output_pos, input_pos, literal_length);
output_pos += literal_length;
read(input_pos, match_offset);
copy(output_pos, output_pos - match_offset,
match_length);
output_pos += match_length;
}
LZ4 格式的设计使得字面量和匹配项在压缩文件中交替出现。显然,字面量总是先出现(因为在最开始时无处可取匹配项)。因此,它们的长度被一起编码。
实际上,这比这稍微复杂一些。从文件中读取一个字节,然后将其拆分为两个半字节(半字节),其中包含编码数字 0 到 15。如果相应的数字不是 15,则假定它分别是字面量和匹配项的长度。如果它是 15,则长度更长,并在以下字节中编码。然后读取下一个字节,并将其值添加到长度中。如果它等于 255,则对下一个字节执行相同的操作。
请注意,LZ4 格式的最大压缩率达不到 255。另一个无用的观察结果是,如果您的数据非常冗余,则使用两次 LZ4 将提高压缩率。
当我们读取字面量的长度(然后是匹配长度和匹配偏移量)时,只需复制两个内存块就足以解压缩它。
如何复制内存块
似乎您可以使用 memcpy 函数,该函数旨在复制内存块。但这并不是最佳方法,也不是真正合适的。
使用 memcpy 不是最佳选择,因为
- 它通常位于 libc 库中(并且 libc 库通常是动态链接的,因此 memcpy 调用将通过 PLT 间接进行)。
- 如果 size 参数在编译时未知,则编译器不会内联它。
- 它付出了很多努力来正确处理不是机器字长或寄存器长度倍数的内存块的剩余部分。
最后一点是最重要的。假设我们要求 memcpy 函数精确复制 5 个字节。最好立即复制 8 个字节,使用两条 movq 指令。
Hello world Hello wo...
^^^^^^^^ - src
^^^^^^^^ - dst
但是这样我们就会复制三个额外的字节,因此我们将写入缓冲区边界之外。memcpy 函数无权执行此操作,因为它可能会覆盖我们程序中的某些数据并导致内存踩踏错误。如果我们写入未对齐的地址,这些额外的字节可能会落在虚拟内存的未分配页面或没有写入权限的页面上。这将给我们一个段错误(这很好)。
但在我们的例子中,我们几乎总是可以写入额外的字节。只要额外的字节完全位于输入缓冲区内,我们就可以在输入缓冲区中读取额外的字节。在相同的条件下,我们也可以将额外的字节写入输出缓冲区,因为我们仍然会在下一次迭代中覆盖它们。
此优化已在 LZ4 的原始实现中
inline void copy8(UInt8 * dst, const UInt8 * src)
{
memcpy(dst, src, 8); /// Note that memcpy isn't actually called here.
}
inline void wildCopy8(UInt8 * dst, const UInt8 * src, UInt8 * dst_end)
{
do
{
copy8(dst, src);
dst += 8;
src += 8;
} while (dst < dst_end);
}
为了利用这种优化,我们只需要确保我们离缓冲区边界足够远。这不应该花费任何代价,因为我们已经在检查缓冲区溢出。并且处理最后几个字节,即“剩余”数据,可以在主循环之后完成。
但是,仍然有一些细微之处。复制在循环中发生两次:使用字面量和匹配项。但是,当使用 LZ4_decompress_fast 函数(而不是 LZ4_decompress_safe)时,仅在我们需要复制字面量时才执行检查。复制匹配项时不执行检查,但 LZ4 格式的规范具有允许您避免它的条件
- 最后 5 个字节始终是字面量。
- 最后一个匹配项必须在块结束前至少 12 个字节处开始。
- 因此,少于 13 个字节的块无法压缩。
专门选择的输入数据可能会导致内存损坏。如果您使用 LZ4_decompress_fast 函数,则需要防止坏数据。至少,您应该计算压缩数据的校验和。如果您需要防止黑客攻击,请使用 LZ4_decompress_safe 函数。其他选项:将加密哈希函数作为校验和(尽管这可能会破坏性能);为缓冲区分配更多内存;使用单独的 mmap 调用分配缓冲区内存并创建保护页。
当我看到复制 8 个字节数据的代码时,我立即想知道为什么正好是 8 个字节。您可以使用 SSE 寄存器复制 16 个字节
inline void copy16(UInt8 * dst, const UInt8 * src)
{
#if __SSE2__
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
#else
memcpy(dst, src, 16);
#endif
}
inline void wildCopy16(UInt8 * dst, const UInt8 * src, UInt8 * dst_end)
{
do
{
copy16(dst, src);
dst += 16;
src += 16;
} while (dst < dst_end);
}
同样的方法适用于使用 AVX 复制 32 个字节和使用 AVX-512 复制 64 个字节。此外,您可以多次展开循环。如果您曾经看过 memcpy 是如何实现的,这正是使用的方法。(顺便说一句,在这种情况下,编译器不会展开或向量化循环,因为这将需要插入笨重的检查。)
为什么原始的 LZ4 实现没有这样做?首先,尚不清楚这样做是更好还是更差。结果增益取决于要复制的块的大小,因此如果它们都很短,那将是无缘无故地创建额外的工作。其次,它破坏了 LZ4 格式中的规定,这些规定有助于避免内部循环中不必要的分支。
但是,我们暂时记住这个选项。
棘手的复制
让我们回到是否总是可以这样复制数据的问题。假设我们需要复制一个匹配项,也就是说,从输出缓冲区中获取一块内存,该内存位于光标后面的某个偏移量处,并将其复制到光标位置。
想象一个简单的案例,当您需要以 12 的偏移量复制 5 个字节时
Hello world ...........
^^^^^ - src
^^^^^ - dst
Hello world Hello wo...
^^^^^ - src
^^^^^ - dst
但有一种更困难的情况,当我们需要复制的内存块比偏移量更长时。换句话说,它包含一些尚未写入输出缓冲区的数据。
以 3 的偏移量复制 10 个字节
abc.............
^^^^^^^^^^ - src
^^^^^^^^^^ - dst
abcabcabcabca...
^^^^^^^^^^ - src
^^^^^^^^^^ - dst
我们在压缩过程中拥有所有数据,并且很可能会找到这样的匹配项。memcpy 函数不适合复制它,因为它不支持内存块范围重叠的情况。memmove 函数也无法工作,因为应该从中获取数据的内存块尚未完全初始化。我们需要像逐字节复制一样进行复制。
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
...
这是它的工作原理
abca............
^ - src
^ - dst
abcab...........
^ - src
^ - dst
abcabc..........
^ - src
^ - dst
abcabca.........
^ - src
^ - dst
abcabcab........
^ - src
^ - dst
换句话说,我们必须创建一个重复序列。LZ4 的原始实现使用了一些非常奇怪的代码来做到这一点
const unsigned dec32table[] = {0, 1, 2, 1, 4, 4, 4, 4};
const int dec64table[] = {0, 0, 0, -1, 0, 1, 2, 3};
const int dec64 = dec64table[offset];
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += dec32table[offset];
memcpy(op+4, match, 4);
match -= dec64;
它逐个复制前 4 个字节,向前跳过一些魔术数字,完全复制接下来的 4 个字节,并使用另一个魔术数字将光标移动到匹配项。代码的作者 (Yan Collet) 不知何故忘记留下关于这意味着什么的注释。此外,变量名称令人困惑。它们都名为 dec...table,但一个是添加的,另一个是减去的。此外,其中一个是无符号的,另一个是 int。但是,作者最近改进了代码中的这个位置。
这是它的实际工作原理。我们逐个复制前 4 个字节
abcabca.........
^^^^ - src
^^^^ - dst
现在我们可以一次复制 4 个字节
abcabcabcab.....
^^^^ - src
^^^^ - dst
我们可以像往常一样继续,一次复制 8 个字节
abcabcabcabcabcabca.....
^^^^^^^^ - src
^^^^^^^^ - dst
正如我们从经验中都知道的那样,有时理解代码的最佳方法是重写它。这是我们提出的
inline void copyOverlap8(UInt8 * op, const UInt8 *& match, const size_t offset)
{
/// 4 % n.
/// Or if 4 % n is zero, we use n.
/// It gives an equivalent result, but is more CPU friendly for unknown reasons.
static constexpr int shift1[] = { 0, 1, 2, 1, 4, 4, 4, 4 };
/// 8 % n - 4 % n
static constexpr int shift2[] = { 0, 0, 0, 1, 0, -1, -2, -3 };
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += shift1[offset];
memcpy(op + 4, match, 4);
match += shift2[offset];
}
正如预期的那样,这根本不会改变性能。我只是真的很想尝试优化一次复制 16 个字节。
然而,这使“特殊情况”变得复杂,并导致更频繁地调用它(offset < 16 条件的执行频率至少与 offset < 8 一样高)。使用 16 字节复制的重叠范围复制看起来像这样(仅显示开头)
inline void copyOverlap16(UInt8 * op, const UInt8 *& match, const size_t offset)
{
/// 4 % n.
static constexpr int shift1[]
= { 0, 1, 2, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4 };
/// 8 % n - 4 % n
static constexpr int shift2[]
= { 0, 0, 0, 1, 0, -1, -2, -3, -4, 4, 4, 4, 4, 4, 4, 4 };
/// 16 % n - 8 % n
static constexpr int shift3[]
= { 0, 0, 0, -1, 0, -2, 2, 1, 8, -1, -2, -3, -4, -5, -6, -7 };
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += shift1[offset];
memcpy(op + 4, match, 4);
match += shift2[offset];
memcpy(op + 8, match, 8);
match += shift3[offset];
}
这个函数可以更有效地实现吗?我们希望为如此复杂的代码找到一个神奇的 SIMD 指令,因为我们只想写入 16 个字节,这些字节完全由输入数据的几个字节(从 1 到 15)组成。然后它们只需要以正确的顺序重复。
有一个这样的指令称为 pshufb(packed shuffle bytes),它是 SSSE3(三个 S)的一部分。它接受两个 16 字节寄存器。其中一个寄存器包含源数据。另一个寄存器具有“选择器”:每个字节包含一个从 0 到 15 的数字,具体取决于从源寄存器的哪个字节获取结果。如果选择器的字节值大于 127,则结果的相应字节将填充为零。
这是一个例子
xmm0: abc.............
xmm1: 0120120120120120
pshufb %xmm1, %xmm0
xmm0: abcabcabcabcabca
结果的每个字节都填充了源数据的选定字节——这正是我们需要的!这是结果代码的样子
inline void copyOverlap16Shuffle(UInt8 * op, const UInt8 *& match, const size_t offset)
{
#ifdef __SSSE3__
static constexpr UInt8 __attribute__((__aligned__(16))) masks[] =
{
0, 1, 2, 1, 4, 1, 4, 2, 8, 7, 6, 5, 4, 3, 2, 1, /* offset = 0, not used as mask, but for shift amount instead */
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, /* offset = 1 */
0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1,
0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0,
0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3,
0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0,
0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7,
0, 1, 2, 3, 4, 5, 6, 7, 8, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 0, 1, 2, 3, 4,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, 3,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 0, 1, 2,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 0, 1,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 0,
};
_mm_storeu_si128(reinterpret_cast<__m128i *>(op),
_mm_shuffle_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(match)),
_mm_load_si128(reinterpret_cast<const __m128i *>(masks) + offset)));
match += masks[offset];
#else
copyOverlap16(op, match, offset);
#endif
}
这里的 _mm_shuffle_epi8 是一个 intrinsic,它编译为 pshufb CPU 指令。
我们可以使用更新的指令一次执行更多字节的此操作吗?毕竟,SSSE3 是一个非常旧的指令集,自 2006 年以来就已存在。AVX2 有一个指令可以一次对 32 个字节执行此操作,但分别用于各个 16 字节通道。这称为向量置换字节,而不是打包混洗字节——单词不同,但含义相同。AVX-512 VBMI 还有另一个指令,可以一次处理 64 个字节,但支持它的处理器最近才出现。ARM NEON 具有类似的指令,称为 vtbl(向量表查找),但它们只允许写入 8 个字节。
此外,还有一个带有 64 位 MMX 寄存器的 pshufb 指令版本,用于形成 8 个字节。它非常适合替换代码的原始版本。但是,我决定使用 16 字节选项(出于严重原因)。
在 Highload++ Siberia 会议上,一位与会者在我的演讲结束后走过来,提到对于 8 字节的情况,您只需使用乘以 специально selected constant(您还需要一个偏移量)——这甚至在我之前都没有发生过!
如何删除多余的 if 语句
假设我想使用复制 16 个字节的变体。如何避免必须进行额外的缓冲区溢出检查?
我决定我只是不做此检查。该函数的注释将说明开发人员应为指定的字节数多分配一个内存块,以便我们可以在那里读取和写入不必要的垃圾。该函数的接口将更难使用,但存在另一个问题。
实际上,可能会产生负面后果。假设我们需要解压缩的数据是从每个 65,536 字节的块形成的。然后用户为我们提供了一块 65,536 字节的内存用于解压缩数据。但是使用新的函数接口,将要求用户分配一个例如 65,551 字节的内存块。然后,分配器可能被迫实际分配 96 甚至 128 KB,具体取决于其实现。如果分配器非常糟糕,它可能会突然停止在“堆”中缓存内存,并开始每次使用 mmap 和 munmap 进行内存分配(或使用 madvice 释放内存)。由于页面错误,此过程将非常缓慢。结果,这一点点优化最终可能会减慢一切速度。
是否有任何加速?
所以我制作了一个使用三个优化的代码版本
- 复制 16 个字节而不是 8 个字节。
- 对于
offset < 16情况,使用混洗指令。 - 删除一个额外的 if。
我开始在不同的数据集上测试此代码,并获得了意想不到的结果。
Example 1:
Xeon E2650v2, Browser data, AppVersion column.
Reference: 1.67 GB/sec.
16 bytes, shuffle: 2.94 GB/sec (76% faster).
Example 2:
Xeon E2650v2, Direct data, ShowsSumPosition column.
Reference: 2.30 GB/sec.
16 bytes, shuffle: 1.91 GB/sec (20% slower).
我最初看到所有内容都加速了如此大的百分比时,真的很高兴。 但后来我发现,对于其他文件,速度并没有更快。 甚至有些文件速度还稍微慢了一些。 我得出的结论是,结果取决于压缩率。 文件压缩率越高,切换到 16 字节的优势就越大。 这感觉很自然:压缩率越高,要复制的片段的平均长度就越长。
为了进行调查,我使用了 C++ 模板为四种情况制作了代码变体:使用 8 字节或 16 字节块,以及是否使用 shuffle 指令。
template <size_t copy_amount, bool use_shuffle>
void NO_INLINE decompressImpl(
const char * const source,
char * const dest,
size_t dest_size)
完全不同的代码变体在不同的文件上表现更好,但在台式机上测试时,带有 shuffle 的版本总是胜出。 在台式机上进行测试很不方便,因为你必须这样做
sudo echo 'performance' | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
kill -STOP $(pidof firefox) $(pidof chromium)
然后我转到一台旧的“开发”服务器(使用 Xeon E5645 处理器),获取了更多数据集,并得到了几乎相反的结果,这完全让我困惑了。 事实证明,除了压缩率之外,最佳算法的选择还取决于处理器型号。 处理器决定何时最适合使用 shuffle 指令,以及何时开始使用 16 字节复制的阈值。
顺便说一句,在我们的服务器上进行测试时,这样做是有意义的
sudo kill -STOP $(pidof python) $(pidof perl) $(pgrep -u skynet) $(pidof cqudp-client)
否则,结果将不稳定。 还要注意热节流和功率限制。
如何选择最佳算法
因此,我们有四种算法变体,我们需要为这些条件选择最佳的一种。 我们可以创建一个具有代表性的数据集和硬件,然后执行认真的负载测试,并选择平均效果最好的方法。 但是我们没有具有代表性的数据集。 为了进行测试,我使用了 Web 分析数据 和 美国航班 的样本。 但这还不够,因为 ClickHouse 被全球数百家公司使用。 通过过度优化一个数据集,我们可能会导致其他数据的性能下降,甚至没有意识到。 而且,如果结果取决于处理器型号,我们将不得不在代码中显式地编写条件,并在每个型号上进行测试(或者查阅关于计时指令的参考手册,您认为呢?)。 无论哪种情况,这都太耗时了。
所以我决定使用另一种方法,这对在我们数据分析学院学习过的同事来说是很明显的:“多臂老虎机”。 关键在于随机选择算法的变体,然后我们使用统计数据逐步选择性能更好的变体。
需要解压缩许多数据块,因此我们需要用于解压缩数据的独立函数调用。 我们可以为每个块选择四种算法之一,并测量其执行时间。 像这样的操作与处理数据块相比通常不花费任何成本,并且在 ClickHouse 中,未压缩的数据块至少为 64 KB。 (阅读这篇关于测量时间的文章)。
为了更好地理解“多臂老虎机”算法的工作原理,让我们看看这个名称的由来。 这与赌场中的老虎机类似,老虎机有多个拉杆,玩家可以拉动这些拉杆以获得一些随机金额的钱。 玩家可以按任何顺序多次拉动拉杆。 每个拉杆对于给出的相应金额的钱都有固定的概率,但玩家不知道它是如何工作的,只能从玩游戏的经验中学习。 一旦他们弄清楚了,他们就可以最大化他们的奖金。
最大化奖励的一种方法是在每个步骤中根据先前步骤的游戏统计数据评估每个拉杆的概率分布。 然后,我们根据收到的分布,在脑海中“赢得”每个拉杆的随机奖励。 最后,我们拉动在我们脑海中的游戏中获得最佳结果的拉杆。 这种方法称为汤普森采样。
但是我们正在选择一种解压缩算法。 结果是每字节的执行时间(皮秒):越少越好。 我们将把执行时间视为随机变量,并使用数理统计评估其分布。 贝叶斯方法通常用于此类任务,但将复杂的公式插入 C++ 代码中会很麻烦。 我们可以使用参数化方法,并说随机变量属于随机变量的参数族,然后评估其参数。
我们如何选择随机变量族? 例如,我们可以假设代码执行时间呈正态分布。 但这绝对是错误的。 首先,执行时间不能为负,而正态分布在数轴上的任何地方都取值。 其次,我假设执行时间在右端会有沉重的“尾巴”。
然而,有一些因素可以使仅出于汤普森采样的目的而估计正态分布成为一个好主意(尽管目标变量的分布不一定是正态的)。 原因是很容易计算数学期望和方差,并且经过足够多的迭代后,正态分布会变得相当窄,类似于我们使用其他方法获得的分布。 如果我们不太关心第一步的收敛速度,则可以忽略这些细节。
这可能看起来有点像一种无知的方法。 经验告诉我们,查询执行、网站页面加载等的平均时间是“垃圾”,不值得计算。 最好计算中位数,这是一个稳健的统计量。 但这有点困难,正如我稍后将展示的那样,所描述的方法在实践中证明了其自身价值。
起初,我实现了数学期望和方差的计算,但后来我决定这太好了,我需要简化代码使其“更差”
/// For better convergence, we don't use proper estimate of stddev.
/// We want to eventually separate the two algorithms even in cases
/// when there is no statistical significant difference between them.
double sigma() const
{
return mean() / sqrt(adjustedCount());
}
double sample(pcg64 & rng) const
{
...
return std::normal_distribution<>(mean(), sigma())(rng);
}
我这样写是为了不考虑最初的几次迭代,以消除内存延迟的影响。
结果是一个测试程序,它可以为输入数据选择最佳算法,并具有使用 LZ4 参考实现或特定算法版本的可选模式。
因此有六个选项
- 参考(基线):原始 LZ4,没有我们的修改
- 变体 0:一次复制 8 个字节,不使用 shuffle。
- 变体 1:一次复制 8 个字节,使用 shuffle。
- 变体 2:一次复制 16 个字节,不使用 shuffle。
- 变体 3:一次复制 16 个字节,使用 shuffle。
- “bandit”选项,它选择四个优化变体中最好的一个。
在不同的 CPU 上进行测试
如果结果强烈依赖于 CPU 型号,那么找出它究竟是如何受到影响的将会很有趣。 在某些 CPU 上可能会有非常大的差异。
我准备了一组来自 ClickHouse 中不同表的真实数据的数据集,总共 256 个不同的文件,每个文件包含 100 MB 的未压缩数据(数字 256 是巧合)。 然后我查看了可以运行基准测试的服务器的 CPU。 我找到了具有以下 CPU 的服务器
- Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz
- Intel® Xeon® CPU E5-2660 v4 @ 2.00GHz
- Intel® Xeon® CPU E5-2660 0 @ 2.20GHz
- Intel® Xeon® CPU E5645 @ 2.40GHz
- Intel Xeon E312xx (Sandy Bridge)
- AMD Opteron(TM) Processor 6274
- AMD Opteron(tm) Processor 6380
- Intel® Xeon® CPU E5-2683 v4 @ 2.10GHz
- Intel® Xeon® CPU E5530 @ 2.40GHz
- Intel® Xeon® CPU E5440 @ 2.83GHz
- Intel® Xeon® CPU E5-2667 v2 @ 3.30GHz
接下来是最有趣的部分——以下处理器也可用
- AMD EPYC 7351 16 核处理器,当时是 AMD 的新型服务器处理器。
- Cavium ThunderX2,它是 AArch64,而不是 x86。 对于这些处理器,我的 SIMD 优化需要稍微修改一下。 该服务器有 224 个逻辑核心和 56 个物理核心。
总共有 13 台服务器,每台服务器都在 256 个文件上以 6 种变体(参考、0、1、2、3、自适应)运行测试。 测试运行十次,选项之间以随机顺序交替。 它输出了 199,680 个结果,我们可以进行比较。
例如,我们可以将不同的 CPU 相互比较。 但我们不应该从这些结果中得出结论,因为我们只在单核上测试 LZ4 解压缩算法(这是一个非常狭窄的案例,所以我们只得到一个微基准测试)。 例如,Cavium 的单核性能最低。 但我自己也在其上测试了 ClickHouse,由于核心数量更多,即使它缺少 ClickHouse 中专门为 x86 做的许多优化,它在繁重的查询中也胜过 Xeon E5-2650 v2。
┌─cpu───────────────────┬──ref─┬─adapt─┬──max─┬─best─┬─adapt_boost─┬─max_boost─┬─adapt_over_max─┐
│ E5-2667 v2 @ 3.30GHz │ 2.81 │ 3.19 │ 3.15 │ 3 │ 1.14 │ 1.12 │ 1.01 │
│ E5-2650 v2 @ 2.60GHz │ 2.5 │ 2.84 │ 2.81 │ 3 │ 1.14 │ 1.12 │ 1.01 │
│ E5-2683 v4 @ 2.10GHz │ 2.26 │ 2.63 │ 2.59 │ 3 │ 1.16 │ 1.15 │ 1.02 │
│ E5-2660 v4 @ 2.00GHz │ 2.15 │ 2.49 │ 2.46 │ 3 │ 1.16 │ 1.14 │ 1.01 │
│ AMD EPYC 7351 │ 2.03 │ 2.44 │ 2.35 │ 3 │ 1.20 │ 1.16 │ 1.04 │
│ E5-2660 0 @ 2.20GHz │ 2.13 │ 2.39 │ 2.37 │ 3 │ 1.12 │ 1.11 │ 1.01 │
│ E312xx (Sandy Bridge) │ 1.97 │ 2.2 │ 2.18 │ 3 │ 1.12 │ 1.11 │ 1.01 │
│ E5530 @ 2.40GHz │ 1.65 │ 1.93 │ 1.94 │ 3 │ 1.17 │ 1.18 │ 0.99 │
│ E5645 @ 2.40GHz │ 1.65 │ 1.92 │ 1.94 │ 3 │ 1.16 │ 1.18 │ 0.99 │
│ AMD Opteron 6380 │ 1.47 │ 1.58 │ 1.56 │ 1 │ 1.07 │ 1.06 │ 1.01 │
│ AMD Opteron 6274 │ 1.15 │ 1.35 │ 1.35 │ 1 │ 1.17 │ 1.17 │ 1 │
│ E5440 @ 2.83GHz │ 1.35 │ 1.33 │ 1.42 │ 1 │ 0.99 │ 1.05 │ 0.94 │
│ Cavium ThunderX2 │ 0.84 │ 0.87 │ 0.87 │ 0 │ 1.04 │ 1.04 │ 1 │
└───────────────────────┴──────┴───────┴──────┴──────┴─────────────┴───────────┴────────────────┘
- ref, adapt, max - 以千兆字节/秒为单位的速度(对于所有数据集上的所有启动时间的算术平均值的倒数)。
- best - 优化变体中最佳算法的编号,从 0 到 3。
- adapt_boost - 自适应算法相对于基线的相对优势。
- max_boost - 非自适应变体中最佳变体相对于基线的相对优势。
- adapt_over_max - 自适应算法相对于最佳非自适应算法的相对优势。
结果表明,我们能够在现代 x86 处理器上将解压缩速度提高 12-20%。 即使在 ARM 上,我们也看到了 4% 的改进,尽管事实上我们并没有针对这种架构进行太多优化。 同样显而易见的是,对于不同的数据集,在所有处理器上(除了非常旧的 Intel CPU),“bandit”算法都领先于预先选择的最佳变体。
结论
在实践中,这项工作的用处值得怀疑。 是的,LZ4 解压缩平均加速了 12-20%,在某些数据集上,性能提高了一倍以上。 但总的来说,这对查询执行时间没有太大影响。 很难找到实际查询能够获得超过百分之几的速度提升。
当时,我们决定在用于执行长时间查询的几个集群上使用 ZStandard level 1 而不是 LZ4; 因为在冷数据上节省 IO 和磁盘空间更重要。 如果您的工作负载类似,请记住这一点。
我们观察到,在高度可压缩数据(例如,主要包含重复字符串值的列)中,解压缩优化带来的好处最大。 但是,我们已经专门针对这种情况开发了一个单独的解决方案,可以显着加快对此类数据的查询速度。
需要记住的另一点是,解压缩速度的优化通常受压缩数据格式的限制。 LZ4 使用了一种非常好的格式,但 Lizard、Density 和 LZSSE 具有其他可以更快工作的格式。 也许与其尝试加速 LZ4,不如直接将 LZSSE 集成到 ClickHouse 中会更好。
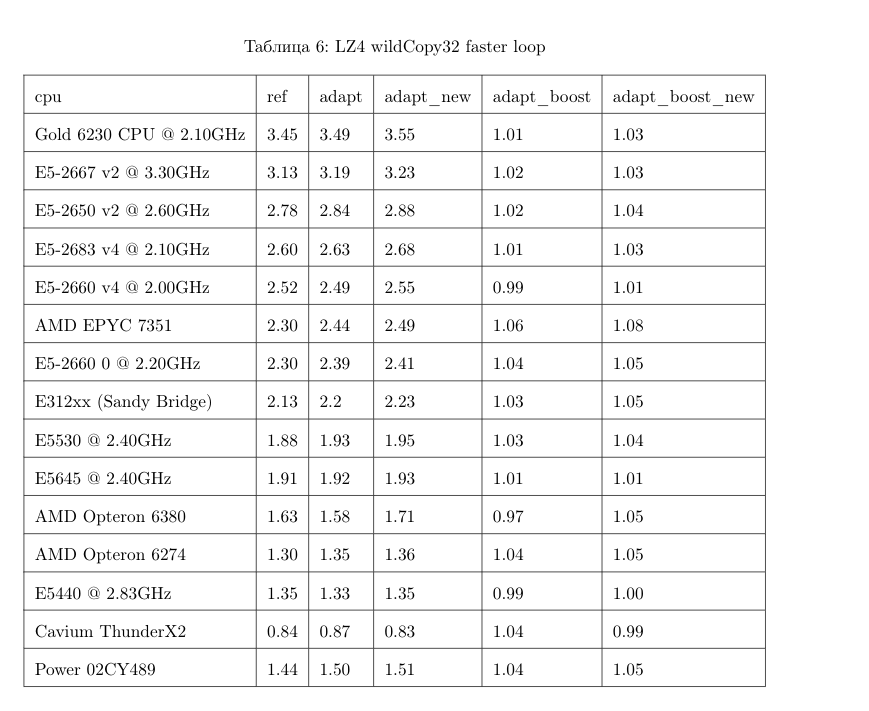
这些优化不太可能在主流 LZ4 库中实现:为了使用它们,必须修改库接口。 事实上,改进算法通常是这种情况——优化不适合旧的抽象,并且必须对其进行修改。 然而,变量名已经在原始实现中得到了纠正。 例如,inc 和 dec 表已被纠正。 此外,原始实现通过复制 32 字节而不是 16 字节(如上所述)将解压缩速度提高了相同的 12-15%。 我们自己尝试了 32 字节选项,结果没有那么好,但仍然更快。
如果您查看文章开头的配置文件,您可能会注意到我们可以从页面缓存中删除一个额外的复制操作到用户空间(可以使用 mmap,或者使用 O_DIRECT 和用户空间页面缓存,但这两种选项都有问题)。 我们还可以稍微改进校验和计算(目前使用 CityHash128,不带 CRC32-C,但我们可以使用 HighwayHash、FARSH 或 XXH3)。 加速这两个操作对于弱压缩数据很有用,因为它们是在压缩数据上执行的。
无论如何,这些更改已合并到 master 中,并且从这项研究中产生的想法已应用于其他任务。



{kind=link}