我们很高兴地宣布 ClickHouse Cloud 在 Azure 上正式发布。
在这篇博文中,我们将详细讨论我们如何构建这项新服务,包括我们面临的挑战以及我们如何克服这些挑战。
ClickHouse Cloud 的简要历史
我们在 2022 年 12 月在 AWS 上推出了 ClickHouse Cloud。仅仅几个月后,我们扩展到支持在 GCP 上的 ClickHouse Cloud。我们在 Azure 上的发布对我们来说是一个重要的里程碑,因为 ClickHouse Cloud 现在已在所有三个主要的云提供商上提供。
ClickHouse Cloud 的架构
在接下来的几个部分中,我们将描述 ClickHouse Cloud 的架构和组件,然后再讨论 Azure 特有的差异。
在 ClickHouse Cloud 中,我们采用“共享一切”架构,并“分离存储和计算”。这意味着存储和计算是解耦的,可以单独扩展。我们使用对象存储(例如 Azure Blob 存储)作为分析数据的主要存储,本地磁盘仅用于缓存、元数据和临时存储。
该架构旨在尽可能地保持云服务提供商 (CSP) 中立,以便可以在不同的 CSP(例如 AWS、GCP 和 Azure)之间重用。
下图描述了这一点

ClickHouse Cloud 组件
ClickHouse Cloud 的组件最好描述为两个不同且独立的逻辑单元
- 控制平面 - “面向用户”的层:这是 UI 和 API 层,使用户能够在云上运行其操作,授予对其 ClickHouse 服务的访问权限,并使他们能够与数据交互。
- 数据平面 - “面向基础设施”的部分:用于管理和编排物理 ClickHouse 集群的功能,包括资源分配、配置、更新、扩展、负载均衡、将不同租户的服务隔离、备份和恢复、可观测性和计量(收集使用情况数据)。
下图说明了这些 ClickHouse Cloud 组件及其交互。

我们的控制平面构建在 AWS 中,并与我们在 AWS、GCP 和 Azure 中的数据平面交互。我们没有为每个 CSP 设置不同的控制平面。因此,在本博客的剩余部分,我们将重点关注数据平面架构。
多云 - Azure
我们设计 ClickHouse Cloud 时使其与 CSP 无关。从广义上讲,这适用于所有 3 个主要的 CSP (AWS/GCP/Azure)。但是,每个单独的 CSP 也有其自身的特性和差异。因此,在我们的架构中,有些地方我们必须适应底层的 CSP。在本节中,我们将讨论我们在使我们的架构适应 Azure 时面临的一些挑战。
ClickHouse Cloud 中的 CSP 组件
如上图所示,我们的数据平面由几个关键组件组成
- 计算:我们使用托管 Kubernetes,例如 AWS EKS/GCP GKE/Azure AKS 作为 ClickHouse 集群的计算层。我们使用 Kubernetes 命名空间 + Cilium 来确保为我们的客户提供适当的租户隔离。
- 存储:我们使用对象存储,例如 AWS S3/GCP Cloud Storage/Azure Blob Storage,来存储 ClickHouse 集群中的数据。每个 ClickHouse 集群都有其自己的专用存储,用于租户隔离。
- 网络:每个区域中的 ClickHouse Cloud 基础设施都在私有的、逻辑隔离的虚拟网络中运行,并且我们在该区域中的所有计算都通过此网络连接。在这里,我们也使用 CSP 特定的解决方案,例如 AWS VPC/GCP VPC/Azure VNET
- 身份和访问管理 (IAM):最后,为了使 ClickHouse Cloud 集群计算能够与相应的对象存储通信,我们使用 CSP IAM 来提供访问权限并确保正确的授权。每个 ClickHouse Cloud 集群都有其自己的身份,并且只有此身份可以访问数据。对于身份和访问管理,我们利用 CSP 产品,例如 AWS IAM/GCP IAM/Microsoft Entra(以前称为 Azure Active Directory)。
尽管每个 CSP 都有其自身的特定解决方案,但理想情况下,我们应该能够设计通用接口并抽象出大部分复杂性。然而,在现实中,虽然某些组件(例如计算 (Kubernetes))在 CSP 之间是无缝的,但并非所有组件都如此容易。
对象存储就是一个例子。Azure Blob Storage 在 API 和实现方面都与 AWS S3 有很大不同。Blob Storage 在存储桶上也有不同的基于权限的访问。这导致我们为每个集群组织存储的方式有所不同。这是比较容易解决的差异之一。更复杂的组件(如网络设置)将在下面详细讨论。
我们没有预料到的一个问题是云资源(例如,VM、身份和存储桶)在 Azure 中的组织方式。让我们讨论一下原因。
云资源组织
在 AWS 中,资源在账户下组织,账户充当所有资源的主要容器。在更高的层面上,AWS Organizations 允许您集中管理多个账户,提供统一的账单和集中的访问控制。这创建了一个两级层次结构:个人账户和组织。
类似地,GCP 采用三级层次结构,从顶层开始是组织,其中包含项目,并可选地包含文件夹以进行进一步组织。项目是资源的主要容器,代表计费实体,而文件夹允许项目的分层分组。
另一方面,Azure 具有更复杂的资源层次结构。在顶层是租户,代表专用的 Microsoft Entra ID(以前称为 Azure AD)实例,并在多个订阅中提供身份管理。在租户下,管理组管理多个订阅的访问、策略和合规性。订阅是计费和资源管理的容器,位于管理组下。此外,资源在每个订阅中组织到资源组中,资源组是相关资源的逻辑容器。这导致了一个四级层次结构:租户、管理组、订阅和资源组。
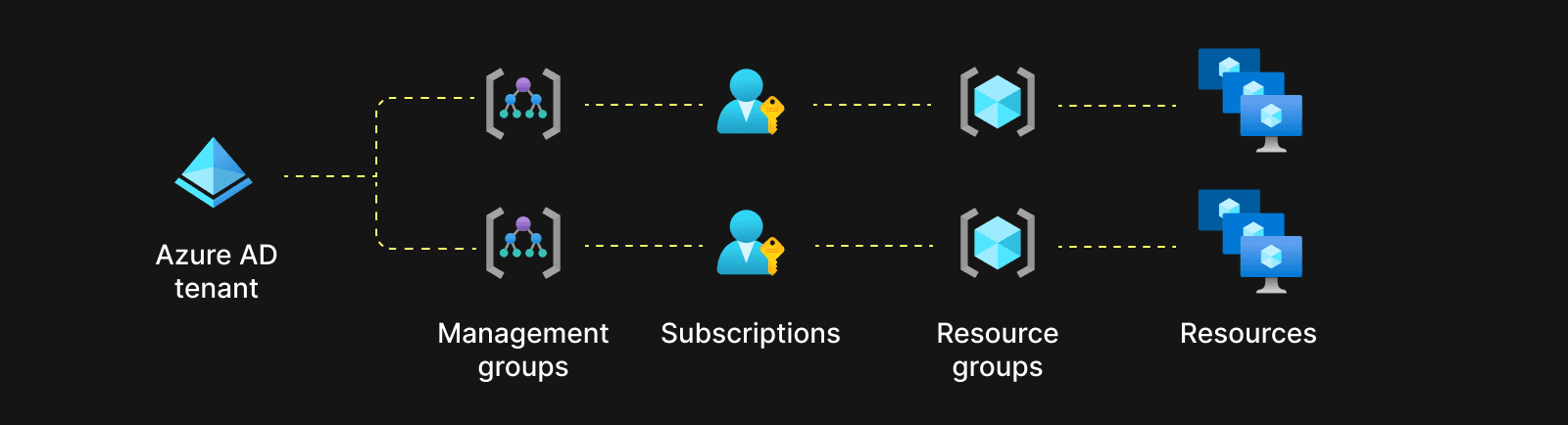
一位敏锐的读者可能会想知道我们是否在不必要地使事情复杂化。由于 Azure 中的资源组通常用于一起创建/删除的资源,因此在逻辑上,在不同的资源组中创建每个客户 ClickHouse 集群,并在 Azure 中为每个 ClickHouse Cloud 区域创建一个订阅,所有资源组都存在于该订阅下,这可能是合理的。然而,这并非如此简单,因为我们需要牢记资源限制。虽然 AWS/GCP 也有资源限制,但 Azure 资源限制更为广泛,并且适用于更广泛的资源。
例如,在 Azure 中,每个订阅的资源组数量限制为 980 个。假设我们每个区域有一个订阅,我们在一个区域中无法创建超过 980 个集群或拥有超过 980 个客户。鉴于我们的规模,我们很可能很快就会达到此限制。
同样,在 Azure 中,每个订阅的存储账户数量限制为 500 个(通过请求,默认值为 250 个)。如果我们在 Azure 中为每个 ClickHouse 实例创建一个单独的存储账户,那么在一个区域中我们无法支持超过 500 个客户。同样,这种设计不是面向未来的。因此,每个区域一个订阅行不通。
在我们的设计过程中,我们联系了来自 Microsoft Azure 和 AKS 团队的架构师和工程师,他们在解决这些差异方面提供了非常有益的帮助。我们与他们讨论了设计思路,以确保我们在扩展时不会遇到此类限制。我们与 Azure 团队的第一个讨论点之一是 - 我们是否应该为每个客户创建一个订阅,以避免遇到上述资源限制?然而,这种设计并非最佳,因为订阅旨在成为容纳资源的逻辑容器和帮助计费、使用情况等的分组。在同一租户下创建数千个订阅在 Azure 中是不可取的。
在与 Azure 团队的协作中,我们设计了一个解决方案,我们在其中创建了一个 Azure 订阅池,用于客户 ClickHouse 集群。每当客户创建一个新实例时,它都会随机分配给从池中选择的订阅,并在此订阅中创建一个新的资源组。随后,客户实例的存储账户、IAM 等都在此资源组中创建。
这种设计解决了我们之前提到的资源限制问题。由于我们现在有 #X 个订阅,因此上述所有限制都增加了 #X 倍,并且由于 X 由我们控制,因此这种设计非常可扩展。资源组和存储账户仍然存在资源限制,但它们在很大程度上符合我们的要求,因为这些限制是针对每个客户的,因此我们不太可能达到这些限制。

即使采用这种设计,资源仍然存在一些硬性限制,例如 Kubernetes 集群大小(节点数)、IP 限制等,这些限制可能会在大规模情况下导致问题。
下一节将解释我们如何使用蜂窝架构解决这些问题。
扩展 ClickHouse Cloud
每个公有云提供商都施加了各种限制,在构建服务时必须考虑到这些限制。此外,通常不建议依赖单个大型 Kubernetes 集群。
为了确保我们的云能够有效扩展,我们可以使用各种方法
- 在单个 VNET 中部署多个 AKS 集群。
- 为不同的 AKS 集群部署多个 VNET。
除了公有云级别的限制和配额之外,Kubernetes 也有其自身的 约束。
截至 Kubernetes v1.30,以下限制适用
- 集群最多可以有 5,000 个节点。
- 每个节点不超过 110 个 Pod。
- 总共不超过 150,000 个 Pod。
- 总共不超过 300,000 个容器。
至关重要的是,我们要做好扩展云基础设施以满足需求的准备。
为了应对这一挑战,我们在每个区域内使用称为“单元”的概念。这种方法对我们来说并不新鲜;我们已经使用它来规避 AWS 账户限制。
什么是单元?
在 ClickHouse Cloud 中,单元是一个独立的环境,具有自己的网络和 Kubernetes 集群。单元自主运行,彼此不依赖。可以将它们视为一种分片机制。客户端连接使用 DNS 记录定向到适当的单元,这使得路由变得简单。

如有必要,我们始终可以在区域内部署一个新的单元,并在该单元中创建新的 ClickHouse Cloud 服务。此过程对最终客户是不可见的。
网络
任何云基础设施的基础都是其网络堆栈。在 Azure 中,这称为 VNET。与 AWS 不同,在 AWS 中,子网属于特定的可用区,而 Azure 的子网则不属于。这类似于 Google Cloud Platform (GCP) 的方法。
这种设计提供了一些好处。例如,它简化了 Azure Kubernetes 服务 (AKS) 节点组的配置。我们可以创建一个绑定到多个可用区的单个 AKS 节点组(我们使用三个可用区来运行 ClickHouse Cloud 服务)。然后,Kubernetes 管理跨这些区域的 Pod 分发。
然而,尽管有这些优势,但一些限制阻止我们充分利用这种优势,这将在下面解释。
AKS 网络
自 2022 年在 AWS 上启动我们的服务以来,我们一直使用 Cilium 作为我们的网络 CNI。我们使用 Cilium 是因为它利用了 eBPF,这确保了高吞吐量、降低的延迟和更低的资源消耗,尤其是在管理许多服务时。您可以在我们的博文“一年内从头开始构建 ClickHouse Cloud”中找到有关此选择的更多详细信息。” 从 Azure 项目开始,使用 Cilium 是不费吹灰之力的。我们唯一需要做出的决定是使用自管理版本 (BYOCNI) 还是 AKS 支持的托管版本。
Azure Kubernetes 服务 (AKS) 支持托管 Cilium,也可以使用 自带容器网络接口 (BYOCNI) 插件 安装自管理版本的 Cilium。
在我们的 GCP 实现期间,我们决定使用托管 Cilium,这有助于我们减轻维护负担。在 GCP 上运行 Cilium 一年后,我们选择在 Azure 中使用相同的方法。您可以在 Azure 此处 找到有关 Azure 中托管 Cilium 的详细信息。
关于我们在 Azure 中托管 Cilium 设置的另一个重要说明是,我们不使用覆盖网络。相反,部署在 AKS 中的 Pod 使用来自 VNET 的 IP 地址,这对于支持集群间通信是必要的。
NAT 网关故事
如前所述,Azure 中的子网未绑定到特定的可用区,从而简化了网络基础设施。我们开始研究 NAT 网关的实施,但后来意识到 Azure 提供的简单模型不适用于我们。由于 Azure 的 NAT 网关实施,我们需要采用类似于 AWS 子网划分策略的方法,每个 AZ 一个子网。
Azure NAT 网关处理来自 VNET 的出站连接。对于 ClickHouse Cloud,这是一个关键组件,因为我们的客户端从各种来源提取数据,例如
- Azure Blob Storage
- S3 存储桶
- GCS 存储桶
- HTTP 服务器
- MySQL/Postgres 数据库
- Kafka 集群
- 以及更多!
如果连接不属于“本地” Azure 存储账户,则将通过 NAT 网关路由。高效且容错的数据提取对于 ClickHouse Cloud 至关重要。
Azure NAT 网关是区域资源。如果我们在 AZ 1 中仅使用一个带有 NAT 网关的子网,则 AZ 1 中的中断将影响 ClickHouse Cloud 中的整个区域。

因此,我们决定部署区域 NAT 网关以确保 ClickHouse Cloud 的可靠性
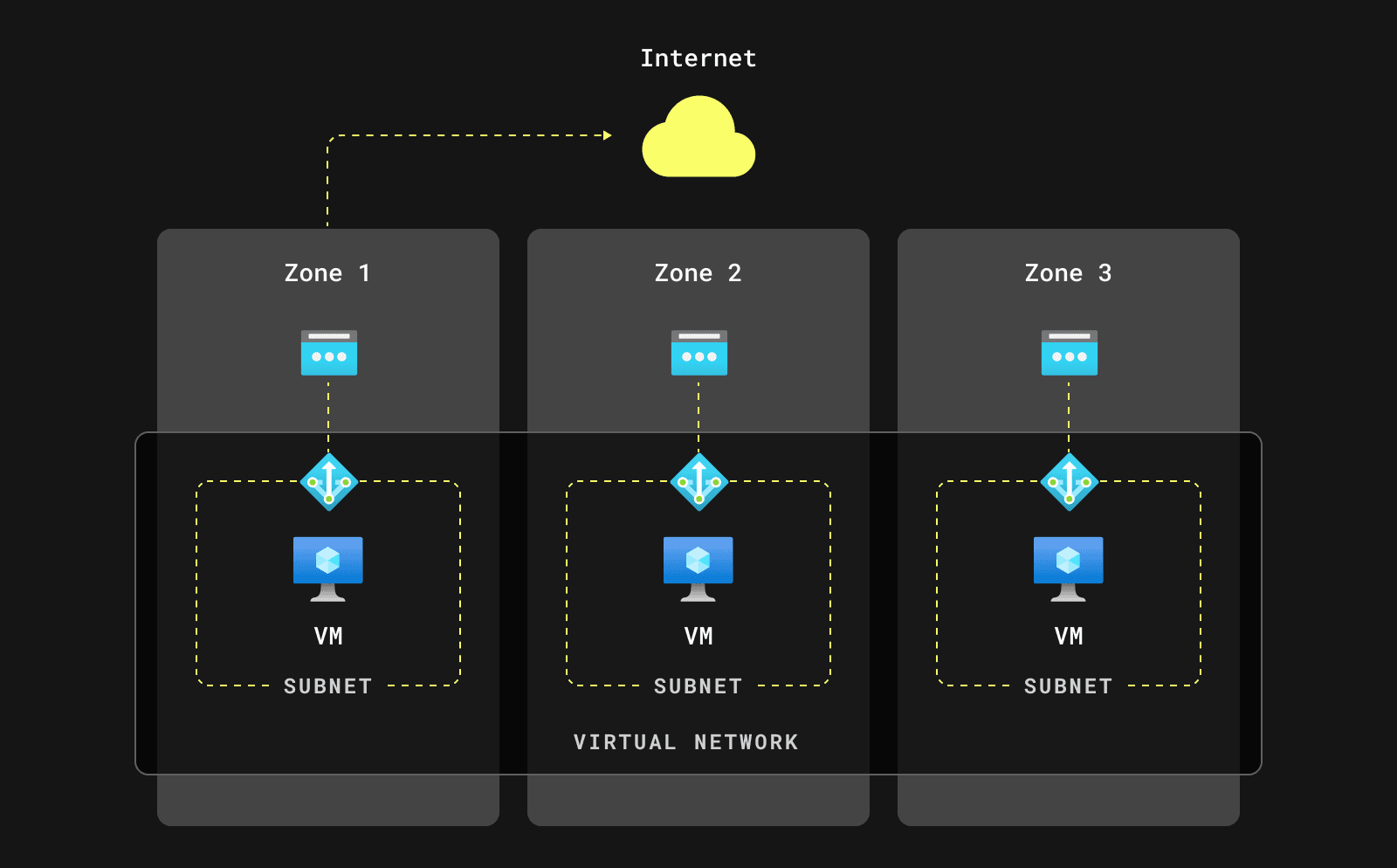
注意:您可以在 此处 找到有关 Azure NAT 网关部署模型的更多详细信息。
此设置使 AKS 节点组配置变得复杂:我们必须在 AKS 中创建三个节点组,而不是一个节点组。每个节点组都绑定到特定的可用区和子网。
更多子网
在 ClickHouse Cloud 中,我们在一个区域内运行多个 Kubernetes 集群
- 数据平面集群:托管 ClickHouse/ClickHouse Keeper 实例。
- 数据平面管理集群:托管管理 ClickHouse Cloud 的软件,并为控制平面团队公开 API 端点。
- 代理集群:托管 Istio 代理。所有入站客户连接都在此集群中终止,然后转发到数据平面集群。
在 AWS 和 GCP 中,使用安全组可以轻松控制集群之间的网络隔离。不幸的是,在设计 ClickHouse Cloud 时,Azure 的情况并非如此。
虽然 应用程序安全组 可能会有所帮助,但它们不适用于 AKS。为了实现集群之间的网络隔离,我们为每个 AKS 集群创建了三个子网(由于 NAT 网关限制,每个 AZ 一个子网)。这种方法增加了我们网络基础设施的复杂性,但允许我们使用 网络安全组 进行网络过滤。

总结一下
- AKS 集群之间的所有流量都由 VNET 防火墙规则过滤。
- 每个集群内的流量都由 Kubernetes 网络策略过滤。
托管 Kubernetes 入口
除了我们的代理集群之外,我们还为内部需求公开其他端点,例如数据平面 API 服务。
在 AWS 和 GCP 中,我们使用托管入口来终止 TLS 并过滤流量 (WAF)。Azure 中最接近的等效项是 Azure 应用程序网关 v2,但这需要基础设施更改,例如专用子网,这超出了我们的需求。因此,我们最初在 Azure 中选择了 NGINX 入口控制器。在我们开始实施高级流量过滤配置之前,这工作正常。使用 NGINX 管理这些配置很困难,而为此任务利用 Istio 则容易得多,尤其是在 ClickHouse 已经拥有 Istio 专业知识的情况下。
我们已将 API 服务器从 NGINX 迁移到 Istio 入口,并且它运行流畅。我们计划在 AWS 和 GCP 中也将托管入口解决方案迁移到 Istio。Istio 与 cert manager 和 external DNS 结合使用效果很好。
ClickHouse 中的 Azure 支持
我们使用 Azure C++ SDK 在 ClickHouse 中处理 Azure Blob Storage,对于身份验证,我们使用 工作负载标识。工作负载标识是 Azure AD Pod 标识的下一个迭代版本,它使 Kubernetes 应用程序能够安全地访问 Azure 云资源。
为了从 Azure Blob Storage 读取文件,我们使用下载并从流中读取的方法。这使其非常高效,尤其是对于大型文件,因为我们不必下载整个文件,并且可以继续分部分或根据需要读取。在可行的情况下,我们还并行读取文件。
为了写入 Azure Blob Storage,我们对大型文件使用多部分上传,并在可能的情况下利用单部分上传以使其快速。结合我们的异步和并行写入,这意味着我们可以高效地写入文件。对于复制文件,我们可以将 ClickHouse 配置为使用本机复制,本机复制直接复制文件,而无需读取和写入文件。当使用读取 + 写入复制大型文件时,我们分部分读取文件并将其写入 Azure Blob Storage,以便有效地处理内存。
当我们调整重试次数时,看到了主要的性能提升之一。Azure SDK 具有较大的退避延迟,减少这些延迟提高了我们的性能。现在,我们添加了配置它们的选项。
OpenSSL
工作负载标识凭据仅受 Azure C++ SDK 1.8 及更高版本支持。由于 ClickHouse 当时使用了旧版本的 SDK(版本 1.3),我们开始升级 SDK。升级到 版本 1.7 一切正常。
也就是说,升级到版本 1.8 失败了。
这是因为 Azure SDK v1.8 引入了对 OpenSSL 作为加密库的依赖,我们无法轻易地将其修补掉。我们也不愿意在第三方代码中进行更改,尤其是在与安全相关的领域。在此之前,ClickHouse(和 Azure)是针对 boringssl(Google 的 OpenSSL 分支)编译的,boringssl 是在多年前 Heartbleed 漏洞 之后创建的。
因此,我们开始将 ClickHouse 从 boringssl 迁移到 OpenSSL。作为如此重要和基础的库,此迁移相当复杂。我们将重点介绍在此转换过程中突出的两个值得注意的问题
我们最初的迁移尝试涉及 OpenSSL 3.0 版本。在使 OpenSSL 在 ClickHouse 的平台(例如,x86、ARM、PPC、RISC-V 等)上构建之后,除了 ClickHouse 的 加密编解码器 的一项测试之外,所有功能测试都通过了。事实证明,编解码器基于现代的抗误用 AES-GCM-SIV 密码,而 OpenSSL 仅从 3.2 版本 开始支持这些密码。为了与使用加密编解码器编码的现有用户数据保持兼容,我们不得不从头开始使用 OpenSSL 3.2。
另一类问题与“代码清理”有关,“代码清理”是一种使用特殊检测执行代码以查找棘手且罕见的错误的技术。ClickHouse 以使用清理程序运行其大多数测试并经常在其使用的第三方库中发现错误而闻名。这次也不例外 - 测试揭示了历史悠久的 OpenSSL 代码库中的错误!我们向上游报告了这些问题,这些问题得到了快速修复,例如,此处 和 此处。这就是开源的力量!
性能基准测试
ClickHouse 是世界上最快的数据库之一。性能对我们来说至关重要。因此,自然而然地,一旦我们在 Azure 上构建了 ClickHouse Cloud,我们就迫不及待地想针对我们在 AWS/GCP 上的产品对其进行基准测试。您可能听说过我们方便的开源工具 ClickBench,该工具被广泛用于性能基准测试。使用此工具,我们进行了多轮改进,以调整 ClickHouse 以适应 Azure Blob Storage。上面部分提到了其中一些优化。查看最终结果,Azure 在 ClickBench 中表现非常出色。公共 ClickBench 结果可以在此处找到 - https://benchmark.clickhouse.com/。
在热运行时,Azure 在 ClickBench 中是所有 3 个云中最快的。

在冷运行时,Azure 比 GCP 快,比 AWS 慢,但总体而言,性能非常好。

这些结果让我们确信,我们的 Azure 产品在性能方面与其他云产品相当。
Azure 市场
最后但并非最不重要的一点,让我们讨论一下计费。您可以直接注册 ClickHouse Cloud,也可以通过 Azure 市场 注册。通过市场,您将拥有与所有其他 Azure 资源统一的计费 - 您的 ClickHouse Cloud 组织及其资源绑定到您的 Azure 订阅。我们与 Azure 市场的集成使您可以按 PAYG(按需付费)方式支付 Azure 消费,或者在指定期限内签订承诺合同。
如果您的组织与 Azure 签订了预先承诺的消费协议,您或许可以将部分承诺的消费应用于 Azure 上 ClickHouse Cloud 的消费。
要点和结论
当我们着手在 Azure 上构建 ClickHouse Cloud 时,我们预计,由于我们已经在 AWS/GCP 上构建了我们的服务,因此我们可以应用大量的学习和架构,使其更容易在 Azure 上构建。尽管其中许多确实适用,但在设置中仍然存在许多我们没有预料到的复杂性和差异。在本博客中,我们讨论了一些重要的方面,例如资源组织、资源限制、网络设置等。我们还得到了 Microsoft Azure 团队的大力帮助,以确保我们能够在遵循 Azure 最佳实践的同时进行扩展设计。
我们也很期待看到 Azure 平台的一些改进。为了可靠性,每个 ClickHouse Cloud 集群都在 3 个 AZ 中部署了 Pod。但是,并非 Azure 中的所有区域都支持 3 个 AZ。将来,这将是 Azure 的一项功能,将有助于提高可靠性。
最后,如果您觉得这篇博客有趣,请查看我们的产品副总裁 Tanya Bragin 在 Microsoft Build 上关于我们如何在 Azure 上将 AKS 用于 ClickHouse Cloud 的演讲。
本博客由 ClickHouse Cloud 团队的 Vinay Suryadevara、Timur Solodovnikov、Smita Kulkarni 和 Robert Schulze 撰写。


